


Top Important Computer Vision Papers for the Week from 01/07 to 07/07
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in various topics such as diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the First Week of July 2024, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models (VLMs)
Video Understanding & Generation
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs. The content of the book covers the following topics:
1. Diffusion Models
1.1. Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion

This paper presents Diffusion Forcing, a new training paradigm where a diffusion model is trained to denoise a set of tokens with independent per-token noise levels.
We apply Diffusion Forcing to sequence generative modeling by training a causal next-token prediction model to generate one or several future tokens without fully diffusing past ones.
Our approach is shown to combine the strengths of next-token prediction models, such as variable-length generation, with the strengths of full-sequence diffusion models, such as the ability to guide sampling to desirable trajectories.
Our method offers a range of additional capabilities, such as:
Rolling-out sequences of continuous tokens, such as video, with lengths past the training horizon, where baselines diverge
New sampling and guiding schemes that uniquely profit from Diffusion Forcing’s variable-horizon and causal architecture, and which lead to marked performance gains in decision-making and planning tasks.
In addition to its empirical success, our method is proven to optimize a variational lower bound on the likelihoods of all subsequences of tokens drawn from the true joint distribution.
1.2. DiffIR2VR-Zero: Zero-Shot Video Restoration with Diffusion-based Image Restoration Models

This paper introduces a method for zero-shot video restoration using pre-trained image restoration diffusion models. Traditional video restoration methods often need retraining for different settings and need help with limited generalization across various degradation types and datasets.
Our approach uses a hierarchical token merging strategy for keyframes and local frames, combined with a hybrid correspondence mechanism that blends optical flow and feature-based nearest neighbor matching (latent merging).
We show that our method not only achieves top performance in zero-shot video restoration but also significantly surpasses trained models in generalization across diverse datasets and extreme degradations (8 times super-resolution and high-standard deviation video denoising).
We present evidence through quantitative metrics and visual comparisons on various challenging datasets. Additionally, our technique works with any 2D restoration diffusion model, offering a versatile and powerful tool for video enhancement tasks without extensive retraining.
This research leads to more efficient and widely applicable video restoration technologies, supporting advancements in fields that require high-quality video output.
1.3. DisCo-Diff: Enhancing Continuous Diffusion Models with Discrete Latents

Diffusion models (DMs) have revolutionized generative learning. They utilize a diffusion process to encode data into a simple Gaussian distribution. However, encoding a complex, potentially multimodal data distribution into a single continuous Gaussian distribution arguably represents an unnecessarily challenging learning problem.
We propose Discrete-Continuous Latent Variable Diffusion Models (DisCo-Diff) to simplify this task by introducing complementary discrete latent variables. We augment DMs with learnable discrete latents, inferred with an encoder, and train DM and encoder end-to-end.
DisCo-Diff does not rely on pre-trained networks, making the framework universally applicable. The discrete latents significantly simplify learning the DM’s complex noise-to-data mapping by reducing the curvature of the DM’s generative ODE.
An additional autoregressive transformer models the distribution of the discrete latents, a simple step because DisCo-Diff requires only a few discrete variables with small codebooks.
We validate DisCo-Diff on toy data, several image synthesis tasks as well as molecular docking, and find that introducing discrete latents consistently improves model performance. For example, DisCo-Diff achieves state-of-the-art FID scores on class-conditioned ImageNet-64/128 datasets with an ODE sampler.
1.4. No Training, No Problem: Rethinking Classifier-Free Guidance for Diffusion Models

Classifier-free guidance (CFG) has become the standard method for enhancing the quality of conditional diffusion models. However, employing CFG requires either training an unconditional model alongside the main diffusion model or modifying the training procedure by periodically inserting a null condition.
There is also no clear extension of CFG to unconditional models. In this paper, we revisit the core principles of CFG and introduce a new method, independent condition guidance (ICG), which provides the benefits of CFG without the need for any special training procedures.
Our approach streamlines the training process of conditional diffusion models and can also be applied during inference on any pre-trained conditional model.
Additionally, by leveraging the time-step information encoded in all diffusion networks, we propose an extension of CFG, called time-step guidance (TSG), which can be applied to any diffusion model, including unconditional ones. Our guidance techniques are easy to implement and have the same sampling cost as CFG.
Through extensive experiments, we demonstrate that ICG matches the performance of standard CFG across various conditional diffusion models. Moreover, we show that TSG improves generation quality in a manner similar to CFG, without relying on any conditional information.
2. Vision Language Models (VLMs)
2.1. ColPali: Efficient Document Retrieval with Vision Language Models
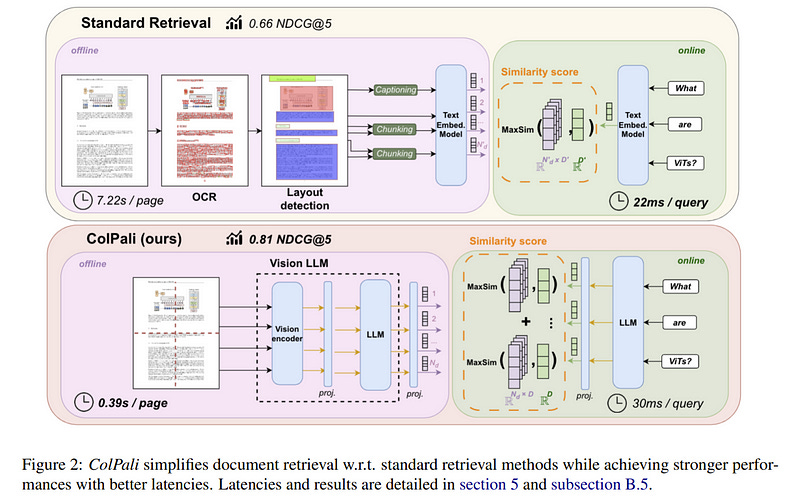
Documents are visually rich structures that convey information through text, as well as tables, figures, page layouts, or fonts. While modern document retrieval systems exhibit strong performance on query-to-text matching, they struggle to exploit visual cues efficiently, hindering their performance on practical document retrieval applications such as Retrieval Augmented Generation.
To benchmark current systems on visually rich document retrieval, we introduce the Visual Document Retrieval Benchmark ViDoRe, composed of various page-level retrieving tasks spanning multiple domains, languages, and settings.
The inherent shortcomings of modern systems motivate the introduction of a new retrieval model architecture, ColPali, which leverages the document understanding capabilities of recent Vision Language Models to produce high-quality contextualized embeddings solely from images of document pages.
Combined with a late interaction matching mechanism, ColPali largely outperforms modern document retrieval pipelines while being drastically faster and end-to-end trainable.
2.2. EVF-SAM: Early Vision-Language Fusion for Text-Prompted Segment Anything Model

Segment Anything Model (SAM) has attracted widespread attention for its superior interactive segmentation capabilities with visual prompts while lacking further exploration of text prompts.
In this paper, we empirically investigate what text prompt encoders (e.g., CLIP or LLM) are good for adapting SAM for referring expression segmentation and introduce the Early Vision-language Fusion-based SAM (EVF-SAM). EVF-SAM is a simple yet effective referring segmentation method that exploits multimodal prompts (i.e., image and text) and comprises a pre-trained vision-language model to generate referring prompts and a SAM model for segmentation.
Surprisingly, we observe that:
Multimodal prompts
Vision-language models with early fusion (e.g., BEIT-3) are beneficial for prompting SAM for accurate referring segmentation.
Our experiments show that the proposed EVF-SAM based on BEIT-3 can obtain state-of-the-art performance on RefCOCO/+/g for referring expression segmentation and demonstrate the superiority of prompting SAM with early vision-language fusion.
In addition, the proposed EVF-SAM with 1.32B parameters achieves remarkably higher performance while reducing nearly 82% of parameters compared to previous SAM methods based on large multimodal models.
2.3. μ-Bench: A Vision-Language Benchmark for Microscopy Understanding
Recent advances in microscopy have enabled the rapid generation of terabytes of image data in cell biology and biomedical research. Vision-language models (VLMs) offer a promising solution for large-scale biological image analysis, enhancing researchers’ efficiency, identifying new image biomarkers, and accelerating hypothesis generation and scientific discovery.
However, there is a lack of standardized, diverse, and large-scale vision-language benchmarks to evaluate VLMs’ perception and cognition capabilities in biological image understanding.
To address this gap, we introduce μ-Bench, an expert-curated benchmark encompassing 22 biomedical tasks across various scientific disciplines (biology, pathology), microscopy modalities (electron, fluorescence, light), scales (subcellular, cellular, tissue), and organisms in both normal and abnormal states.
We evaluate state-of-the-art biomedical, pathology, and general VLMs on μ-Bench and find that:
Current models struggle in all categories, even for basic tasks such as distinguishing microscopy modalities.
Current specialist models fine-tuned on biomedical data often perform worse than generalist models
Fine-tuning in specific microscopy domains can cause catastrophic forgetting, eroding prior biomedical knowledge encoded in their base model.
Weight interpolation between fine-tuned and pre-trained models offers one solution to forgetting and improves general performance across biomedical tasks.
3. Video Understanding & Generation
3.1. What Matters in Detecting AI-Generated Videos Like Sora?
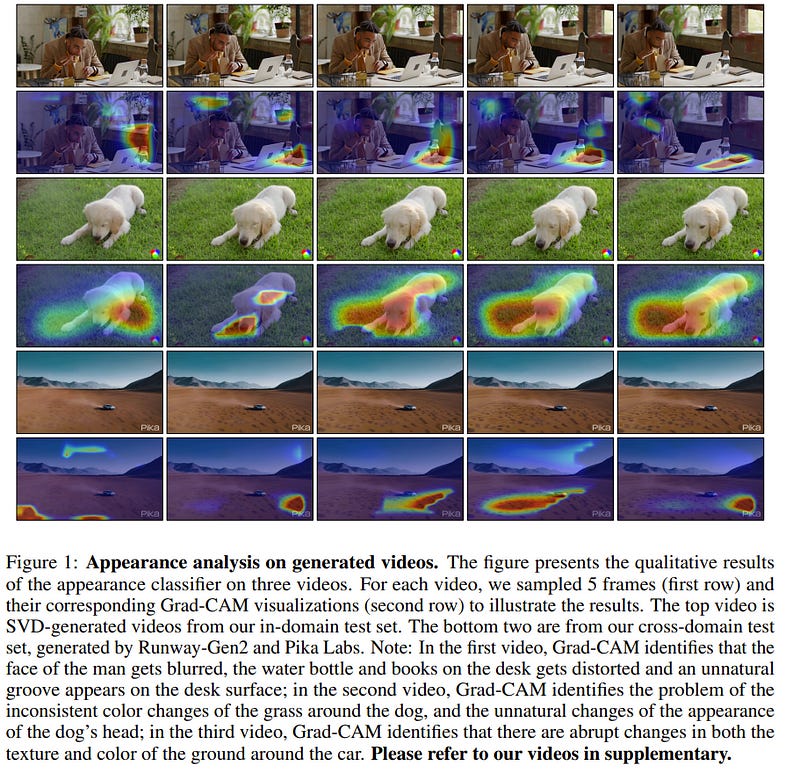
Recent advancements in diffusion-based video generation have showcased remarkable results, yet the gap between synthetic and real-world videos remains under-explored.
In this study, we examine this gap from three fundamental perspectives: appearance, motion, and geometry, comparing real-world videos with those generated by a state-of-the-art AI model, Stable Video Diffusion.
To achieve this, we train three classifiers using 3D convolutional networks, each targeting distinct aspects: vision foundation model features for appearance, optical flow for motion, and monocular depth for geometry.
Each classifier exhibits strong performance in fake video detection, both qualitatively and quantitatively. This indicates that AI-generated videos are still easily detectable, and a significant gap between real and fake videos persists.
Furthermore, utilizing the Grad-CAM, we pinpoint systematic failures of AI-generated videos in appearance, motion, and geometry. Finally, we propose an Ensemble-of-Experts model that integrates appearance, optical flow, and depth information for fake video detection, resulting in enhanced robustness and generalization ability.
Our model is capable of detecting videos generated by Sora with high accuracy, even without exposure to any Sora videos during training. This suggests that the gap between real and fake videos can be generalized across various video generative models.
3.2. OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation

Text-to-video (T2V) generation has recently garnered significant attention thanks to the large multi-modality model Sora. However, T2V generation still faces two important challenges:
Lacking a precise sourced high-quality dataset. The previous popular video datasets, e.g. WebVid-10M and Panda-70M, are either of low quality or too large for most research institutions. Therefore, it is challenging but crucial to collect precise high-quality text-video pairs for T2V generation.
Ignoring to fully utilize textual information. Recent T2V methods have focused on vision transformers, using a simple cross-attention module for video generation, which falls short of thoroughly extracting semantic information from text prompts.
To address these issues, we introduce OpenVid-1M, a precise high-quality dataset with expressive captions. This open-scenario dataset contains over 1 million text-video pairs, facilitating research on T2V generation.
Furthermore, we curate 433K 1080p videos from OpenVid-1M to create OpenVidHD-0.4M, advancing high-definition video generation. Additionally, we propose a novel Multi-modal Video Diffusion Transformer (MVDiT) capable of mining both structure information from visual tokens and semantic information from text tokens.
Extensive experiments and ablation studies verify the superiority of OpenVid-1M over previous datasets and the effectiveness of our MVDiT.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
