


Top Important Computer Vision Papers for the Week from 20/05 to 26/05
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in various topics such as diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the Fourth Week of May 2024, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models (VLMs)
Image Generation & Editing
Video Understanding & Generation
Object Detection
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. Diffusion Models
1.1. FIFO-Diffusion: Generating Infinite Videos from Text without Training

We propose a novel inference technique based on a pretrained diffusion model for text-conditional video generation. Our approach, called FIFO-Diffusion, is conceptually capable of generating infinitely long videos without training.
This is achieved by iteratively performing diagonal denoising, which concurrently processes a series of consecutive frames with increasing noise levels in a queue; our method dequeues a fully denoised frame at the head while enqueuing a new random noise frame at the tail.
However, diagonal denoising is a double-edged sword as the frames near the tail can take advantage of cleaner ones by forward reference but such a strategy induces the discrepancy between training and inference.
Hence, we introduce latent partitioning to reduce the training-inference gap and look ahead to denoising to leverage the benefit of forward referencing. We have demonstrated the promising results and effectiveness of the proposed methods on existing text-to-video generation baselines.
1.2. Diffusion for World Modeling: Visual Details Matter in Atari

World models constitute a promising approach for training reinforcement learning agents in a safe and sample-efficient manner. Recent world models predominantly operate on sequences of discrete latent variables to model environment dynamics.
However, this compression into a compact discrete representation may ignore visual details that are important for reinforcement learning. Concurrently, diffusion models have become a dominant approach for image generation, challenging well-established methods of modeling discrete latents.
Motivated by this paradigm shift, we introduce DIAMOND (DIffusion As a Model Of eNvironment Dreams), a reinforcement learning agent trained in a diffusion world model. We analyze the key design choices that are required to make diffusion suitable for world modeling and demonstrate how improved visual details can lead to improved agent performance.
DIAMOND achieves a mean human normalized score of 1.46 on the competitive Atari 100k benchmark; a new best for agents trained entirely within a world model.
1.3. Face Adapter for Pre-Trained Diffusion Models with Fine-Grained ID and Attribute Control

Current face reenactment and swapping methods mainly rely on GAN frameworks, but recent focus has shifted to pre-trained diffusion models for their superior generation capabilities. However, training these models is resource-intensive, and the results still need to achieve satisfactory performance levels.
To address this issue, we introduce Face-Adapter, an efficient and effective adapter designed for high-precision and high-fidelity face editing for pre-trained diffusion models. We observe that both face reenactment/swapping tasks essentially involve combinations of target structure, ID, and attribute. We aim to sufficiently decouple the control of these factors to achieve both tasks in one model.
Specifically, our method contains:
A Spatial Condition Generator that provides precise landmarks and background.
A Plug-and-play Identity Encoder that transfers face embeddings to the text space by a transformer decoder.
An Attribute Controller that integrates spatial conditions and detailed attributes.
Face-Adapter achieves comparable or even superior performance in terms of motion control precision, ID retention capability, and generation quality compared to fully fine-tuned face reenactment/swapping models. Additionally, Face-Adapter seamlessly integrates with various StableDiffusion models.
1.4. Semantica: An Adaptable Image-Conditioned Diffusion Model

We investigate the task of adapting image generative models to different datasets without finetuneing. To this end, we introduce Semantica, an image-conditioned diffusion model capable of generating images based on the semantics of a conditioning image.
Semantica is trained exclusively on web-scale image pairs, that is it receives a random image from a webpage as conditional input and models another random image from the same webpage. Our experiments highlight the expressivity of pretrained image encoders and the necessity of semantic-based data filtering in achieving high-quality image generation.
Once trained, it can adaptively generate new images from a dataset by simply using images from that dataset as input. We study the transfer properties of Semantica on ImageNet, LSUN Churches, LSUN Bedroom, and SUN397.
1.5. LiteVAE: Lightweight and Efficient Variational Autoencoders for Latent Diffusion Models
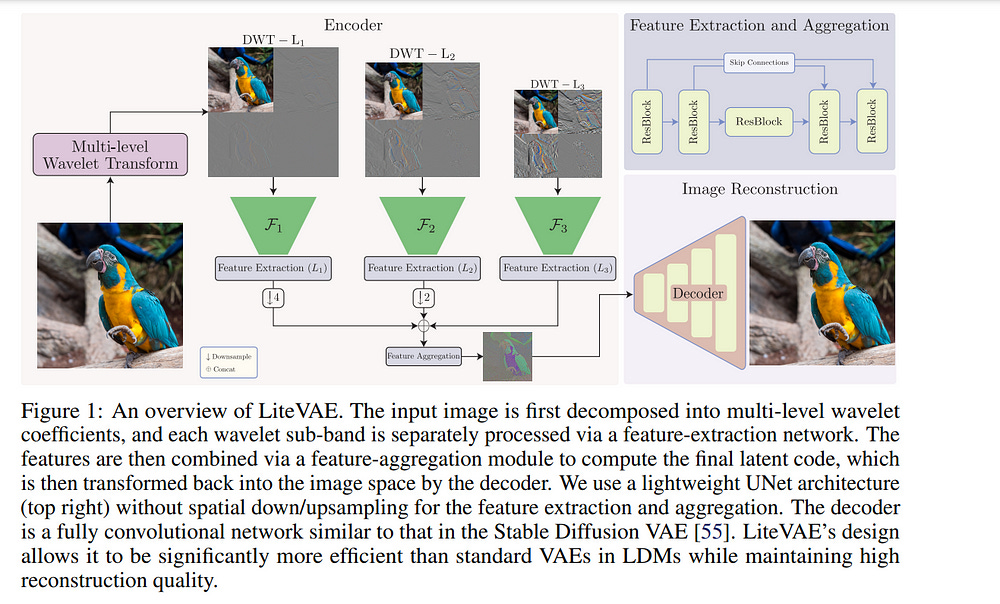
Advances in latent diffusion models (LDMs) have revolutionized high-resolution image generation, but the design space of the autoencoder that is central to these systems remains underexplored.
In this paper, we introduce LiteVAE, a family of autoencoders for LDMs that leverage the 2D discrete wavelet transform to enhance scalability and computational efficiency over standard variational autoencoders (VAEs) with no sacrifice in output quality.
We also investigate the training methodologies and the decoder architecture of LiteVAE and propose several enhancements that improve the training dynamics and reconstruction quality.
Our base LiteVAE model matches the quality of the established VAEs in current LDMs with a six-fold reduction in encoder parameters, leading to faster training and lower GPU memory requirements, while our larger model outperforms VAEs of comparable complexity across all evaluated metrics (rFID, LPIPS, PSNR, and SSIM).
1.6. DiM: Diffusion Mamba for Efficient High-Resolution Image Synthesis

Diffusion models have achieved great success in image generation, with the backbone evolving from U-Net to Vision Transformers. However, the computational cost of Transformers is quadratic to the number of tokens, leading to significant challenges when dealing with high-resolution images.
In this work, we propose Diffusion Mamba (DiM), which combines the efficiency of Mamba, a sequence model based on State Space Models (SSM), with the expressive power of diffusion models for efficient high-resolution image synthesis.
To address the challenge that Mamba cannot generalize to 2D signals, we make several architecture designs including multi-directional scans, learnable padding tokens at the end of each row and column, and lightweight local feature enhancement.
Our DiM architecture achieves inference-time efficiency for high-resolution images. In addition, to further improve training efficiency for high-resolution image generation with DiM, we investigate a weak-to-strong training strategy that pre-trains DiM on low-resolution images (256times 256) and then fine-tune it on high-resolution images (512 times 512).
We further explore training-free upsampling strategies to enable the model to generate higher-resolution images (e.g., 1024 times 1024 and 1536 times 1536) without further fine-tuning. Experiments demonstrate the effectiveness and efficiency of our DiM.
2. Vision Language Models (VLMs)
2.1. Personalized Residuals for Concept-Driven Text-to-Image Generation

We present personalized residuals and localized attention-guided sampling for efficient concept-driven generation using text-to-image diffusion models.
Our method first represents concepts by freezing the weights of a pretrained text-conditioned diffusion model and learning low-rank residuals for a small subset of the model’s layers.
The residual-based approach then directly enables the application of our proposed sampling technique, which applies the learned residuals only in areas where the concept is localized via cross-attention and applies the original diffusion weights in all other regions.
Localized sampling therefore combines the learned identity of the concept with the existing generative prior of the underlying diffusion model. We show that personalized residuals effectively capture the identity of a concept in ~3 minutes on a single GPU without the use of regularization images and with fewer parameters than previous models, and localized sampling allows using the original model as strong prior for large parts of the image.
3. Image Generation & Editing
3.1. Dreamer XL: Towards High-Resolution Text-to-3D Generation via Trajectory Score Matching

In this work, we propose a novel Trajectory Score Matching (TSM) method that aims to solve the pseudo ground truth inconsistency problem caused by the accumulated error in Interval Score Matching (ISM) when using the Denoising Diffusion Implicit Models (DDIM) inversion process.
Unlike ISM which adopts the inversion process of DDIM to calculate on a single path, our TSM method leverages the inversion process of DDIM to generate two paths from the same starting point for calculation. Since both paths start from the same starting point, TSM can reduce the accumulated error compared to ISM, thus alleviating the problem of pseudo-ground truth inconsistency.
TSM enhances the stability and consistency of the model’s generated paths during the distillation process. We demonstrate this experimentally and further show that ISM is a special case of TSM.
Furthermore, to optimize the current multi-stage optimization process from high-resolution text to 3D generation, we adopt Stable Diffusion XL for guidance.
In response to the issues of abnormal replication and splitting caused by unstable gradients during the 3D Gaussian splatting process when using Stable Diffusion XL, we propose a pixel-by-pixel gradient clipping method. Extensive experiments show that our model significantly surpasses the state-of-the-art models in terms of visual quality and performance.
3.2. Improved Distribution Matching Distillation for Fast Image Synthesis

Recent approaches have shown promise in distilling diffusion models into efficient one-step generators. Among them, Distribution Matching Distillation (DMD) produces one-step generators that match their teacher in distribution, without enforcing a one-to-one correspondence with the sampling trajectories of their teachers.
However, to ensure stable training, DMD requires an additional regression loss computed using a large set of noise-image pairs generated by the teacher with many steps of a deterministic sampler.
This is costly for large-scale text-to-image synthesis and limits the student’s quality, tying it too closely to the teacher’s original sampling paths.
We introduce DMD2, a set of techniques that lift this limitation and improve DMD training. First, we eliminate the regression loss and the need for expensive dataset construction.
We show that the resulting instability is due to the fake critic not estimating the distribution of generated samples accurately and propose a two-time-scale update rule as a remedy. Second, we integrate a GAN loss into the distillation procedure, discriminating between generated samples and real images.
This lets us train the student model on real data, mitigating the imperfect real score estimation from the teacher model, and enhancing quality. Lastly, we modify the training procedure to enable multi-step sampling. We identify and address the training-inference input mismatch problem in this setting, by simulating inference-time generator samples during training time.
Taken together, our improvements set new benchmarks in one-step image generation, with FID scores of 1.28 on ImageNet-64x64 and 8.35 on zero-shot COCO 2014, surpassing the original teacher despite a 500X reduction in inference cost.
Further, we show our approach can generate megapixel images by distilling SDXL, demonstrating exceptional visual quality among a few-step methods.
3.3. Visual Echoes: A Simple Unified Transformer for Audio-Visual Generation

In recent years, with the realistic generation results and a wide range of personalized applications, diffusion-based generative models have gained huge attention in both visual and audio generation areas.
Compared to the considerable advancements in text2image or text2audio generation, research in audio2visual or visual2audio generation has been relatively slow. The recent audio-visual generation methods usually resort to huge large language models or composable diffusion models.
Instead of designing another giant model for audio-visual generation, in this paper, we take a step back to show that a simple and lightweight generative transformer, which is not fully investigated in multi-modal generation, can achieve excellent results on image2audio generation.
The transformer operates in the discrete audio and visual Vector-Quantized GAN space and is trained in a mask-denoising manner. After training, the classifier-free guidance could be deployed off-the-shelf achieving better performance, without any extra training or modification.
Since the transformer model is modality symmetrical, it could also be directly deployed for audio2image generation and co-generation. In the experiments, we show that our simple method surpasses recent image2audio generation methods.
4. Video Understanding & Generation
4.1. CamViG: Camera Aware Image-to-Video Generation with Multimodal Transformers

We extend multimodal transformers to include 3D camera motion as a conditioning signal for the task of video generation. Generative video models are becoming increasingly powerful, thus focusing research efforts on methods of controlling the output of such models.
We propose to add virtual 3D camera controls to generative video methods by conditioning generated video on an encoding of three-dimensional camera movement over the course of the generated video.
Results demonstrate that we are (1) able to successfully control the camera during video generation, starting from a single frame and a camera signal, and (2) we demonstrate the accuracy of the generated 3D camera paths using traditional computer vision methods.
4.2. ReVideo: Remake a Video with Motion and Content Control

Despite significant advancements in video generation and editing using diffusion models, achieving accurate and localized video editing remains a substantial challenge. Additionally, most existing video editing methods primarily focus on altering visual content, with limited research dedicated to motion editing.
In this paper, we present a novel attempt to Remake a Video (ReVideo) that stands out from existing methods by allowing precise video editing in specific areas through the specification of both content and motion. Content editing is facilitated by modifying the first frame, while the trajectory-based motion control offers an intuitive user interaction experience.
ReVideo addresses a new task involving the coupling and training imbalance between content and motion control. To tackle this, we develop a three-stage training strategy that progressively decouples these two aspects from coarse to fine.
Furthermore, we propose a spatiotemporal adaptive fusion module to integrate content and motion control across various sampling steps and spatial locations.
Extensive experiments demonstrate that our ReVideo has promising performance on several accurate video editing applications, i.e., (1) locally changing video content while keeping the motion constant, (2) keeping content unchanged and customizing new motion trajectories, (3) modifying both content and motion trajectories.
Our method can also seamlessly extend these applications to multi-area editing without specific training, demonstrating its flexibility and robustness.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM

Great review!