


Top Important Computer Vision Papers for the Week from 01/04 to 07/04
Stay Updated with Recent Computer Vision Research

Every week, several top-tier academic conferences and journals showcased innovative research in computer vision, presenting exciting breakthroughs in various subfields such as image recognition, vision model optimization, generative adversarial networks (GANs), image segmentation, video analysis, and more.
This article provides a comprehensive overview of the most significant papers published in the First Week of April 2024, highlighting the latest research and advancements in computer vision. Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models (VLMs)
Image Generation & Editing
Video Understanding & Generation
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. Diffusion Models
1.1. Measuring Style Similarity in Diffusion Models

Generative models are now widely used by graphic designers and artists. Prior works have shown that these models remember and often replicate content from their training data during generation.
Hence as their proliferation increases, it has become important to perform a database search to determine whether the properties of the image are attributable to specific training data, every time before a generated image is used for professional purposes.
Existing tools for this purpose focus on retrieving images of similar semantic content. Meanwhile, many artists are concerned with style replication in text-to-image models. We present a framework for understanding and extracting style descriptors from images.
Our framework comprises a new dataset curated using the insight that style is a subjective property of an image that captures complex yet meaningful interactions of factors including but not limited to colors, textures, shapes, etc.
We also propose a method to extract style descriptors that can be used to attribute the style of a generated image to the images used in the training dataset of a text-to-image model.
We showcase promising results in various style retrieval tasks. We also quantitatively and qualitatively analyze style attribution and matching in the Stable Diffusion model.
1.2. Cross-Attention Makes Inference Cumbersome in Text-to-Image Diffusion Models

This study explores the role of cross-attention during inference in text-conditional diffusion models. We find that cross-attention outputs converge to a fixed point after a few inference steps.
Accordingly, the time point of convergence naturally divides the entire inference process into two stages: an initial semantics-planning stage, during which, the model relies on cross-attention to plan text-oriented visual semantics, and a subsequent fidelity-improving stage, during which the model tries to generate images from previously planned semantics.
Surprisingly, ignoring text conditions in the fidelity-improving stage not only reduces computation complexity but also maintains model performance.
This yields a simple and training-free method called TGATE for efficient generation, which caches the cross-attention output once it converges and keeps it fixed during the remaining inference steps. Our empirical study on the MS-COCO validation set confirms its effectiveness.
1.3. On the Scalability of Diffusion-based Text-to-Image Generation
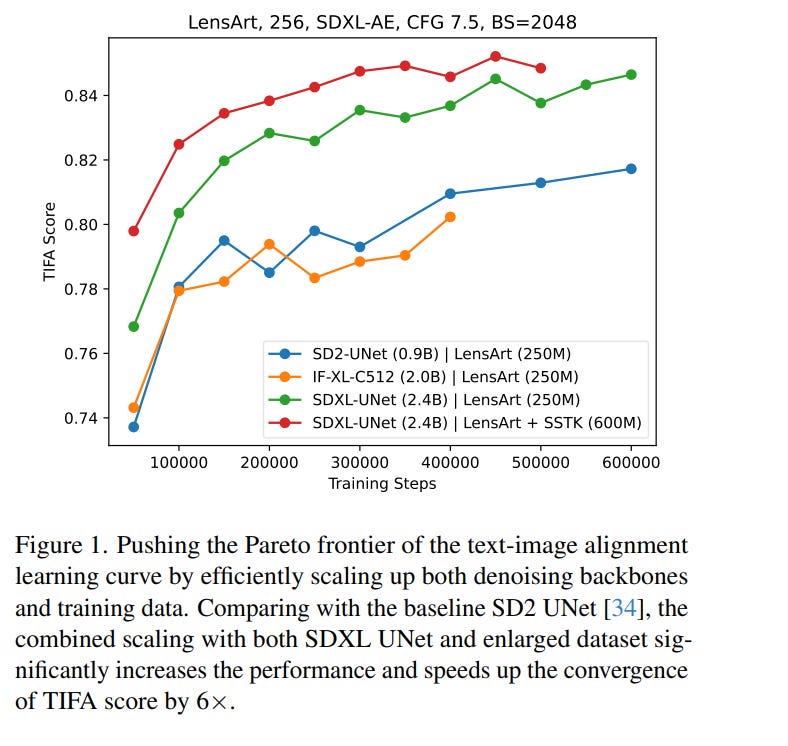
Scaling up models and data size has been quite successful for the evolution of LLMs. However, the scaling law for the diffusion-based text-to-image (T2I) models is not fully explored. It is also unclear how to efficiently scale the model for better performance at reduced cost.
The different training settings and expensive training costs make a fair model comparison extremely difficult. In this work, we empirically study the scaling properties of diffusion-based T2I models by performing extensive and rigorous ablations on scaling both denoising backbones and training set, including training scaled UNet and Transformer variants ranging from 0.4B to 4B parameters on datasets up to 600M images.
For model scaling, we find the location and amount of cross attention distinguishes the performance of existing UNet designs. Increasing the transformer blocks is more parameter-efficient for improving text-image alignment than increasing channel numbers. We then identify an efficient UNet variant, which is 45% smaller and 28% faster than SDXL’s UNet.
On the data scaling side, we show the quality and diversity of the training set matter more than simply dataset size. Increasing caption density and diversity improves text-image alignment performance and learning efficiency. Finally, we provide scaling functions to predict the text-image alignment performance as functions of the scale of model size, compute, and dataset size.
1.4. Bigger is not Always Better: Scaling Properties of Latent Diffusion Models

We study the scaling properties of latent diffusion models (LDMs) with an emphasis on their sampling efficiency. While improved network architecture and inference algorithms have been shown to effectively boost the sampling efficiency of diffusion models, the role of model size — a critical determinant of sampling efficiency — has not been thoroughly examined.
Through empirical analysis of established text-to-image diffusion models, we conduct an in-depth investigation into how model size influences sampling efficiency across varying sampling steps. Our findings unveil a surprising trend: when operating under a given inference budget, smaller models frequently outperform their larger equivalents in generating high-quality results.
Moreover, we extend our study to demonstrate the generalizability of these findings by applying various diffusion samplers, exploring diverse downstream tasks, evaluating post-distilled models, as well as comparing performance relative to training compute.
These findings open up new pathways for the development of LDM scaling strategies which can be employed to enhance generative capabilities within limited inference budgets.
1.5. CoMat: Aligning Text-to-Image Diffusion Model with Image-to-Text Concept Matching

Diffusion models have demonstrated great success in the field of text-to-image generation. However, alleviating the misalignment between the text prompts and images is still challenging.
The root reason behind the misalignment has not been extensively investigated. We observe that the misalignment is caused by inadequate token attention activation. We further attribute this phenomenon to the diffusion model’s insufficient condition utilization, which is caused by its training paradigm.
To address the issue, we propose CoMat, an end-to-end diffusion model fine-tuning strategy with an image-to-text concept-matching mechanism. We leverage an image captioning model to measure image-to-text alignment and guide the diffusion model to revisit ignored tokens.
A novel attribute concentration module is also proposed to address the attribute binding problem. Without any image or human preference data, we use only 20K text prompts to fine-tune SDXL to obtain CoMat-SDXL. Extensive experiments show that CoMat-SDXL significantly outperforms the baseline model SDXL in two text-to-image alignment benchmarks and achieves start-of-the-art performance.
2. Vision Language Models (VLMs)
2.1. Unsolvable Problem Detection: Evaluating Trustworthiness of Vision Language Models
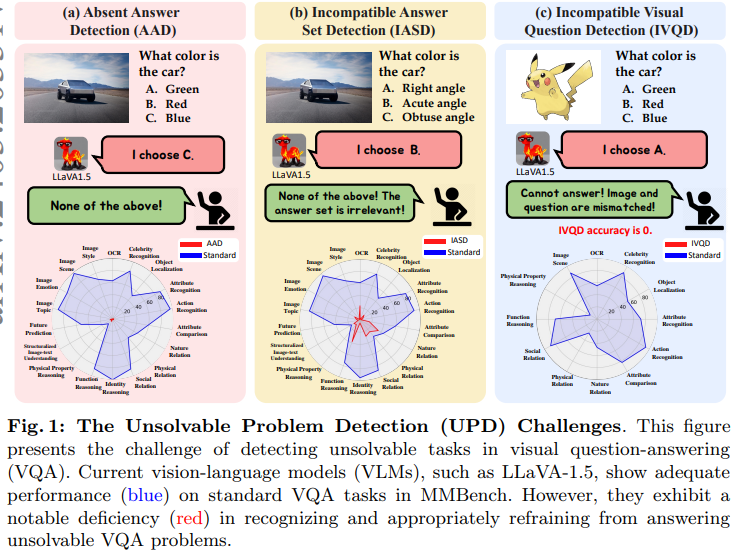
This paper introduces a novel and significant challenge for Vision Language Models (VLMs), termed Unsolvable Problem Detection (UPD). UPD examines the VLM’s ability to withhold answers when faced with unsolvable problems in the context of Visual Question Answering (VQA) tasks.
UPD encompasses three distinct settings: Absent Answer Detection (AAD), Incompatible Answer Set Detection (IASD), and Incompatible Visual Question Detection (IVQD).
To deeply investigate the UPD problem, extensive experiments indicate that most VLMs, including GPT-4V and LLaVA-Next-34B, struggle with our benchmarks to varying extents, highlighting significant room for improvement.
To address UPD, we explore both training-free and training-based solutions, offering new insights into their effectiveness and limitations. We hope our insights, together with future efforts within the proposed UPD settings, will enhance the broader understanding and development of more practical and reliable VLMs.
2.2. LVLM-Interpret: An Interpretability Tool for Large Vision-Language Models
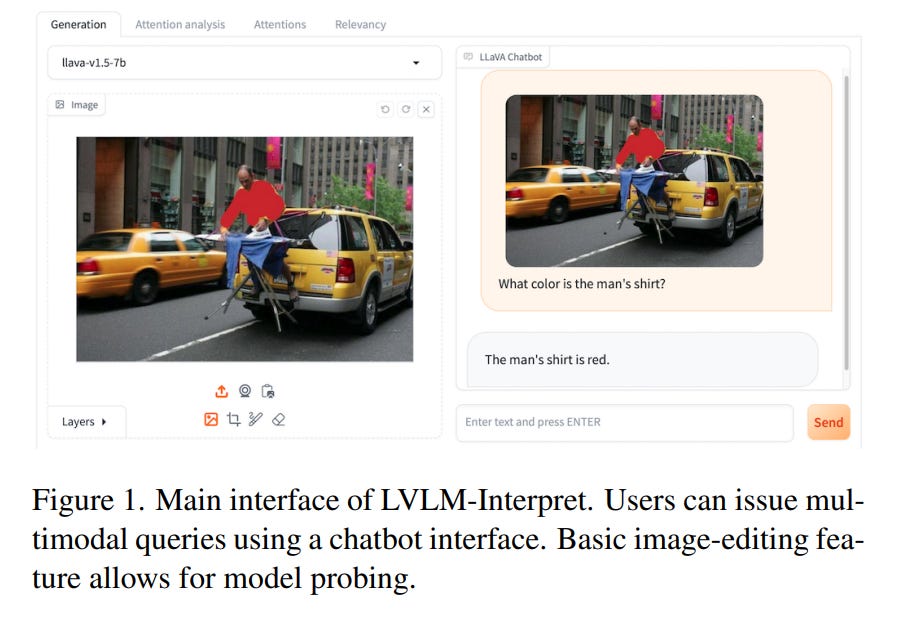
In the rapidly evolving landscape of artificial intelligence, multi-modal large language models are emerging as a significant area of interest. These models, which combine various forms of data input, are becoming increasingly popular.
However, understanding their internal mechanisms remains a complex task. Numerous advancements have been made in the field of explainability tools and mechanisms, yet there is still much to explore. In this work, we present a novel interactive application aimed at understanding the internal mechanisms of large vision-language models.
Our interface is designed to enhance the interpretability of the image patches, which are instrumental in generating an answer, and assess the efficacy of the language model in grounding its output in the image.
With our application, a user can systematically investigate the model and uncover system limitations, paving the way for enhancements in system capabilities. Finally, we present a case study of how our application can aid in understanding failure mechanisms in a popular large multi-modal model: LLaVA.
3. Image Generation & Editing
3.1. Snap-it, Tap-it, Splat-it: Tactile-Informed 3D Gaussian Splatting for Reconstructing Challenging Surfaces

Touch and vision go hand in hand, mutually enhancing our ability to understand the world. From a research perspective, the problem of mixing touch and vision is underexplored and presents interesting challenges.
To this end, we propose Tactile-Informed 3DGS, a novel approach that incorporates touch data (local depth maps) with multi-view vision data to achieve surface reconstruction and novel view synthesis. Our method optimizes 3D Gaussian primitives to accurately model the object’s geometry at points of contact.
By creating a framework that decreases the transmittance at touch locations, we achieve a refined surface reconstruction, ensuring a uniformly smooth depth map. Touch is particularly useful when considering non-Lambertian objects (e.g. shiny or reflective surfaces) since contemporary methods tend to fail to reconstruct with fidelity specular highlights.
By combining vision and tactile sensing, we achieve more accurate geometry reconstructions with fewer images than prior methods. We conduct evaluations on objects with glossy and reflective surfaces and demonstrate the effectiveness of our approach, offering significant improvements in reconstruction quality.
3.2. CosmicMan: A Text-to-Image Foundation Model for Humans
We present CosmicMan, a text-to-image foundation model specialized for generating high-fidelity human images. Unlike current general-purpose foundation models that are stuck in the dilemma of inferior quality and text-image misalignment for humans, CosmicMan enables generating photo-realistic human images with meticulous appearance, reasonable structure, and precise text-image alignment with detailed dense descriptions.
At the heart of CosmicMan’s success are the new reflections and perspectives on data and models:
We found that data quality and a scalable data production flow are essential for the final results from trained models. Hence, we propose a new data production paradigm, Annotate Anyone, which serves as a perpetual data flywheel to produce high-quality data with accurate yet cost-effective annotations over time. Based on this, we constructed a large-scale dataset, CosmicMan-HQ 1.0, with 6 Million high-quality real-world human images in a mean resolution of 1488x1255, and attached with precise text annotations deriving from 115 Million attributes in diverse granularities.
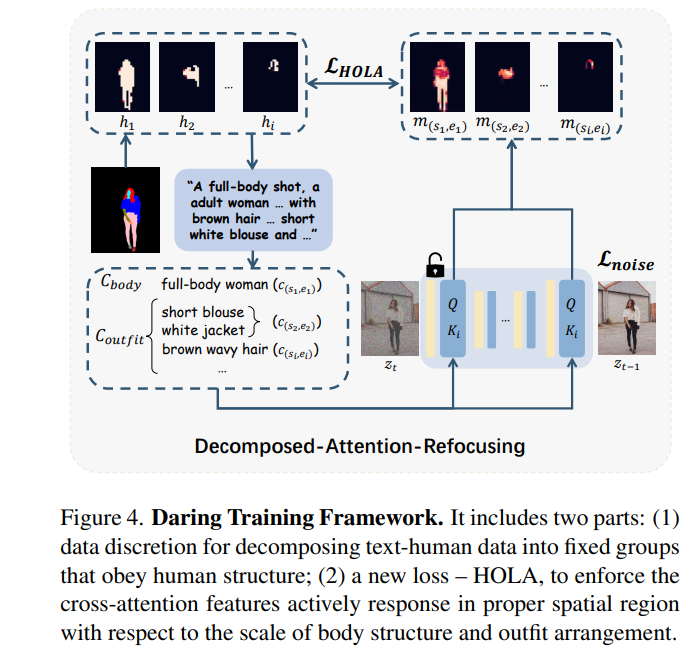
We argue that a text-to-image foundation model specialized for humans must be pragmatic — easy to integrate into down-streaming tasks while effective in producing high-quality human images. Hence, we propose to model the relationship between dense text descriptions and image pixels in a decomposed manner and present a Decomposed-Attention-Refocusing (Daring) training framework.
It seamlessly decomposes the cross-attention features in the existing text-to-image diffusion model and enforces attention refocusing without adding extra modules. Through Daring, we show that explicitly discretizing continuous text space into several basic groups that align with human body structure is the key to tackling the misalignment problem in a breeze.
3.3. Getting it Right: Improving Spatial Consistency in Text-to-Image Models

One of the key shortcomings in current text-to-image (T2I) models is their inability to consistently generate images that faithfully follow the spatial relationships specified in the text prompt. In this paper, we offer a comprehensive investigation of this limitation, while also developing datasets and methods that achieve state-of-the-art performance.
First, we find that current vision-language datasets do not represent spatial relationships well enough; to alleviate this bottleneck, we create SPRIGHT, the first spatially-focused, large-scale dataset, by re-captioning 6 million images from 4 widely used vision datasets. Through a 3-fold evaluation and analysis pipeline, we find that SPRIGHT largely improves upon existing datasets in capturing spatial relationships.
To demonstrate its efficacy, we leverage only ~0.25% of SPRIGHT and achieve a 22% improvement in generating spatially accurate images while also improving the FID and CMMD scores. Secondly, we find that training on images containing a large number of objects results in substantial improvements in spatial consistency. Notably, we attain state-of-the-art on T2I-CompBench with a spatial score of 0.2133, by fine-tuning on <500 images.
Finally, through a set of controlled experiments and ablations, we document multiple findings that we believe will enhance the understanding of factors that affect spatial consistency in text-to-image models. We publicly release our dataset and model to foster further research in this area.
3.4. FlexiDreamer: Single Image-to-3D Generation with FlexiCubes

3D content generation from text prompts or single images has made remarkable progress in quality and speed recently. One of its dominant paradigms involves generating consistent multi-view images followed by a sparse-view reconstruction.
However, due to the challenge of directly deforming the mesh representation to approach the target topology, most methodologies learn an implicit representation (such as NeRF) during the sparse-view reconstruction and acquire the target mesh by a post-processing extraction.
Although the implicit representation can effectively model rich 3D information, its training typically entails a long convergence time. In addition, the post-extraction operation from the implicit field also leads to undesirable visual artifacts.
In this paper, we propose FlexiDreamer, a novel single image-to-3d generation framework that reconstructs the target mesh in an end-to-end manner. By leveraging a flexible gradient-based extraction known as FlexiCubes, our method circumvents the defects brought by the post-processing and facilitates a direct acquisition of the target mesh.
Furthermore, we incorporate a multi-resolution hash grid encoding scheme that progressively activates the encoding levels into the implicit field in FlexiCubes to help capture geometric details for per-step optimization.
Notably, FlexiDreamer recovers a dense 3D structure from a single-view image in approximately 1 minute on a single NVIDIA A100 GPU, outperforming previous methodologies by a large margin.
3.5. Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction

We present Visual AutoRegressive modeling (VAR), a new generation paradigm that redefines the autoregressive learning on images as coarse-to-fine “next-scale prediction” or “next-resolution prediction”, diverging from the standard raster-scan “next-token prediction”.
This simple, intuitive methodology allows autoregressive (AR) transformers to learn visual distributions fast and generalize well: VAR, for the first time, makes AR models surpass diffusion transformers in image generation. On the ImageNet 256x256 benchmark, VAR significantly improves the AR baseline by improving the Frechet inception distance (FID) from 18.65 to 1.80, and the inception score (IS) from 80.4 to 356.4, with around 20x faster inference speed.
It is also empirically verified that VAR outperforms the Diffusion Transformer (DiT) in multiple dimensions including image quality, inference speed, data efficiency, and scalability. Scaling up VAR models exhibits clear power-law scaling laws similar to those observed in LLMs, with linear correlation coefficients near -0.998 as solid evidence. VAR further showcases zero-shot generalization ability in downstream tasks including image in-painting, out-painting, and editing.
These results suggest VAR has initially emulated the two important properties of LLMs: Scaling Laws and zero-shot task generalization. We have released all models and codes to promote the exploration of AR/VAR models for visual generation and unified learning.
3.6. InstantStyle: Free Lunch towards Style-Preserving in Text-to-Image Generation

Tuning-free diffusion-based models have demonstrated significant potential in the realm of image personalization and customization. However, despite this notable progress, current models continue to grapple with several complex challenges in producing style-consistent image generation.
Firstly, the concept of style is inherently underdetermined, encompassing a multitude of elements such as color, material, atmosphere, design, and structure, among others. Secondly, inversion-based methods are prone to style degradation, often resulting in the loss of fine-grained details. Lastly, adapter-based approaches frequently require meticulous weight tuning for each reference image to achieve a balance between style intensity and text controllability.
In this paper, we commence by examining several compelling yet frequently overlooked observations. We then proceed to introduce InstantStyle, a framework designed to address these issues through the implementation of two key strategies:
A straightforward mechanism that decouples style and content from reference images within the feature space, predicated on the assumption that features within the same space can be either added to or subtracted from one another.
The injection of reference image features exclusively into style-specific blocks, thereby preventing style leaks and eschewing the need for cumbersome weight tuning, which often characterizes more parameter-heavy designs.
This work demonstrates superior visual stylization outcomes, striking an optimal balance between the intensity of style and the controllability of textual elements.
3.7. Condition-Aware Neural Network for Controlled Image Generation

We present a Condition-Aware Neural Network (CAN), a new method for adding control to image generative models. In parallel to prior conditional control methods, CAN controls the image generation process by dynamically manipulating the weight of the neural network.
This is achieved by introducing a condition-aware weight generation module that generates conditional weight for convolution/linear layers based on the input condition. We test CAN on class-conditional image generation on ImageNet and text-to-image generation on COCO.
CAN consistently delivers significant improvements for diffusion transformer models, including DiT and UViT. In particular, CAN combined with EfficientViT (CaT) achieves 2.78 FID on ImageNet 512x512, surpassing DiT-XL/2 while requiring 52x fewer MACs per sampling step.
4. Video Understanding & Generation
4.1. MiniGPT4-Video: Advancing Multimodal LLMs for Video Understanding with Interleaved Visual-Textual Tokens

This paper introduces MiniGPT4-Video, a multimodal Large Language Model (LLM) designed specifically for video understanding. The model is capable of processing both temporal visual and textual data, making it adept at understanding the complexities of videos.
Building upon the success of MiniGPT-v2, which excelled in translating visual features into the LLM space for single images and achieved impressive results on various image-text benchmarks, this paper extends the model’s capabilities to process a sequence of frames, enabling it to comprehend videos.
MiniGPT4-video does not only consider visual content but also incorporates textual conversations, allowing the model to effectively answer queries involving both visual and text components.
The proposed model outperforms existing state-of-the-art methods, registering gains of 4.22%, 1.13%, 20.82%, and 13.1% on the MSVD, MSRVTT, TGIF, and TVQA benchmarks respectively.
4.2. Streaming Dense Video Captioning
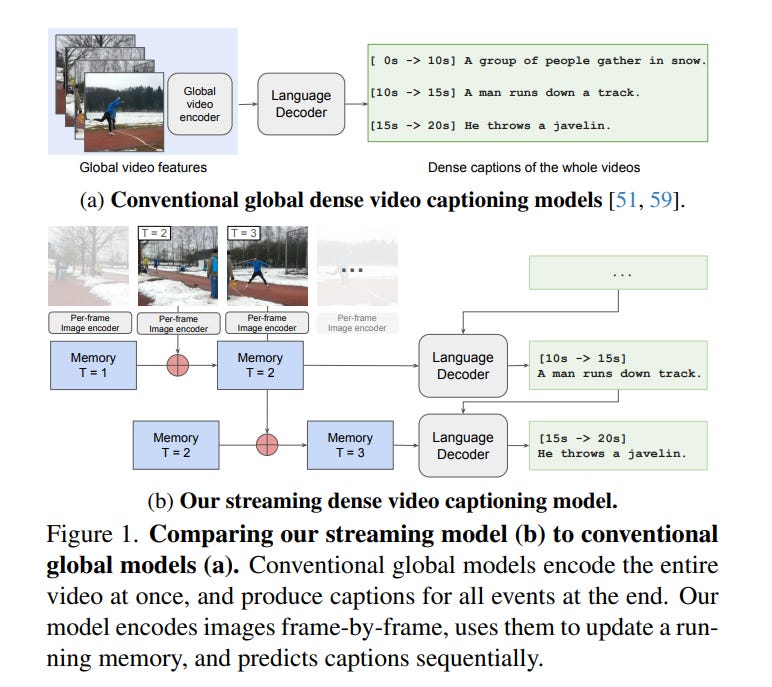
An ideal model for dense video captioning — predicting captions localized temporally in a video — should be able to handle long input videos, predict rich, detailed textual descriptions, and be able to produce outputs before processing the entire video.
Current state-of-the-art models, however, process a fixed number of downsampled frames and make a single full prediction after seeing the whole video. We propose a streaming-dense video captioning model that consists of two novel components:
First, we propose a new memory module, based on clustering incoming tokens, which can handle arbitrarily long videos as the memory is of a fixed size.
Second, we develop a streaming decoding algorithm that enables our model to make predictions before the entire video has been processed.
Our model achieves this streaming ability and significantly improves the state-of-the-art on three dense video captioning benchmarks ActivityNet, YouCook2, and ViTT.
4.3. CameraCtrl: Enabling Camera Control for Text-to-Video Generation

Controllability plays a crucial role in video generation since it allows users to create desired content. However, existing models largely overlooked the precise control of camera pose that serves as a cinematic language to express deeper narrative nuances.
To alleviate this issue, we introduce CameraCtrl, enabling accurate camera pose control for text-to-video(T2V) models. After precisely parameterizing the camera trajectory, a plug-and-play camera module is then trained on a T2V model, leaving others untouched.
Additionally, a comprehensive study on the effect of various datasets is also conducted, suggesting that videos with diverse camera distribution and similar appearances indeed enhance controllability and generalization.
Experimental results demonstrate the effectiveness of CameraCtrl in achieving precise and domain-adaptive camera control, marking a step forward in the pursuit of dynamic and customized video storytelling from textual and camera pose inputs.
4.4. Direct Preference Optimization of Video Large Multimodal Models from Language Model Reward

Preference modeling techniques, such as direct preference optimization (DPO), have been shown effective in enhancing the generalization abilities of large language models (LLM).
However, in tasks involving video instruction-following, providing informative feedback, especially for detecting hallucinations in generated responses, remains a significant challenge.
Previous studies have explored using large multimodal models (LMMs) as reward models to guide preference modeling, but their ability to accurately assess the factuality of generated responses compared to corresponding videos has not been conclusively established.
This paper introduces a novel framework that utilizes detailed video captions as a proxy of video content, enabling language models to incorporate this information as supporting evidence for scoring video Question Answering (QA) predictions.
Our approach demonstrates robust alignment with the OpenAI GPT-4V model’s reward mechanism, which directly takes video frames as input. Furthermore, we show that applying this tailored reward through DPO significantly improves the performance of video LMMs on video QA tasks.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
