
Top Important Computer Vision Papers for the Week from 22/01 to 28/01
Stay Updated with Recent Computer Vision Research

Every week, several top-tier academic conferences and journals showcased innovative research in computer vision, presenting exciting breakthroughs in various subfields such as image recognition, vision model optimization, generative adversarial networks (GANs), image segmentation, video analysis, and more.
This article provides a comprehensive overview of the most significant papers published in the Fourth Week of January 2024, highlighting the latest research and advancements in computer vision. Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Stable Diffusion
Vision Language Models
Image Generation & Editing
Video Generation & Editing
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. Stable Diffusion
1.1. Diffuse to Choose: Enriching Image Conditioned Inpainting in Latent Diffusion Models for Virtual Try-All

As online shopping is growing, the ability for buyers to virtually visualize products in their settings-a phenomenon we define as “Virtual Try-All”-has become crucial. Recent diffusion models inherently contain a world model, rendering them suitable for this task within an inpainting context. However, traditional image-conditioned diffusion models often fail to capture the fine-grained details of products.
In contrast, personalization-driven models such as DreamPaint are good at preserving the item’s details but they are not optimized for real-time applications. We present “Diffuse to Choose,” a novel diffusion-based image-conditioned inpainting model that efficiently balances fast inference with the retention of high-fidelity details in a given reference item while ensuring accurate semantic manipulations in the given scene content.
Our approach is based on incorporating fine-grained features from the reference image directly into the latent feature maps of the main diffusion model, alongside with a perceptual loss to further preserve the reference item’s details. We conduct extensive testing on both in-house and publicly available datasets, and show that Diffuse to Choose is superior to existing zero-shot diffusion inpainting methods as well as few-shot diffusion personalization algorithms like DreamPaint.
1.2. Deconstructing Denoising Diffusion Models for Self-Supervised Learning

In this study, we examine the representation learning abilities of Denoising Diffusion Models (DDM) that were originally purposed for image generation. Our philosophy is to deconstruct a DDM, gradually transforming it into a classical Denoising Autoencoder (DAE).
This deconstructive procedure allows us to explore how various components of modern DDMs influence self-supervised representation learning. We observe that only a very few modern components are critical for learning good representations, while many others are nonessential.
Our study ultimately arrives at an approach that is highly simplified and to a large extent resembles a classical DAE. We hope our study will rekindle interest in a family of classical methods within the realm of modern self-supervised learning.
1.3. BootPIG: Bootstrapping Zero-shot Personalized Image Generation Capabilities in Pretrained Diffusion Models

Recent text-to-image generation models have demonstrated incredible success in generating images that faithfully follow input prompts. However, the requirement of using words to describe a desired concept provides limited control over the appearance of the generated concepts. In this work, we address this shortcoming by proposing an approach to enable personalization capabilities in existing text-to-image diffusion models.
We propose a novel architecture (BootPIG) that allows a user to provide reference images of an object in order to guide the appearance of a concept in the generated images. The proposed BootPIG architecture makes minimal modifications to a pretrained text-to-image diffusion model and utilizes a separate UNet model to steer the generations toward the desired appearance.
We introduce a training procedure that allows us to bootstrap personalization capabilities in the BootPIG architecture using data generated from pretrained text-to-image models, LLM chat agents, and image segmentation models. In contrast to existing methods that require several days of pretraining, the BootPIG architecture can be trained in approximately 1 hour.
Experiments on the DreamBooth dataset demonstrate that BootPIG outperforms existing zero-shot methods while being comparable with test-time finetuning approaches. Through a user study, we validate the preference for BootPIG generations over existing methods both in maintaining fidelity to the reference object’s appearance and aligning with textual prompts.
1.4. CreativeSynth: Creative Blending and Synthesis of Visual Arts based on Multimodal Diffusion

Large-scale text-to-image generative models have made impressive strides, showcasing their ability to synthesize a vast array of high-quality images. However, adapting these models for artistic image editing presents two significant challenges. Firstly, users struggle to craft textual prompts that meticulously detail visual elements of the input image.
Secondly, prevalent models, when effecting modifications in specific zones, frequently disrupt the overall artistic style, complicating the attainment of cohesive and aesthetically unified artworks. To surmount these obstacles, we build the innovative unified framework CreativeSynth, which is based on a diffusion model with the ability to coordinate multimodal inputs and multitask in the field of artistic image generation.
By integrating multimodal features with customized attention mechanisms, CreativeSynth facilitates the importation of real-world semantic content into the domain of art through inversion and real-time style transfer.
This allows for the precise manipulation of image style and content while maintaining the integrity of the original model parameters. Rigorous qualitative and quantitative evaluations underscore that CreativeSynth excels in enhancing artistic images’ fidelity and preserves their innate aesthetic essence. By bridging the gap between generative models and artistic finesse, CreativeSynth becomes a custom digital palette.
1.5. Large-scale Reinforcement Learning for Diffusion Models

Text-to-image diffusion models are a class of deep generative models that have demonstrated an impressive capacity for high-quality image generation. However, these models are susceptible to implicit biases that arise from web-scale text-image training pairs and may inaccurately model aspects of images we care about.
This can result in suboptimal samples, model bias, and images that do not align with human ethics and preferences. In this paper, we present an effective scalable algorithm to improve diffusion models using Reinforcement Learning (RL) across a diverse set of reward functions, such as human preference, compositionality, and fairness over millions of images.
We illustrate how our approach substantially outperforms existing methods for aligning diffusion models with human preferences. We further illustrate how this substantially improves pretrained Stable Diffusion (SD) models, generating samples that are preferred by humans 80.3% of the time over those from the base SD model while simultaneously improving both the composition and diversity of generated samples.
1.6. Scaling Up to Excellence: Practicing Model Scaling for Photo-Realistic Image Restoration In the Wild

We introduce SUPIR (Scaling-UP Image Restoration), a groundbreaking image restoration method that harnesses generative prior and the power of model scaling up. Leveraging multi-modal techniques and advanced generative prior, SUPIR marks a significant advance in intelligent and realistic image restoration.
As a pivotal catalyst within SUPIR, model scaling dramatically enhances its capabilities and demonstrates new potential for image restoration. We collect a dataset comprising 20 million high-resolution, high-quality images for model training, each enriched with descriptive text annotations.
SUPIR provides the capability to restore images guided by textual prompts, broadening its application scope and potential. Moreover, we introduce negative-quality prompts to further improve perceptual quality.
We also develop a restoration-guided sampling method to suppress the fidelity issue encountered in generative-based restoration. Experiments demonstrate SUPIR’s exceptional restoration effects and its novel capacity to manipulate restoration through textual prompts.
1.7. UNIMO-G: Unified Image Generation through Multimodal Conditional Diffusion

Existing text-to-image diffusion models primarily generate images from text prompts. However, the inherent conciseness of textual descriptions poses challenges in faithfully synthesizing images with intricate details, such as specific entities or scenes.
This paper presents UNIMO-G, a simple multimodal conditional diffusion framework that operates on multimodal prompts with interleaved textual and visual inputs, which demonstrates a unified ability for both text-driven and subject-driven image generation. UNIMO-G comprises two core components: a Multimodal Large Language Model (MLLM) for encoding multimodal prompts, and a conditional denoising diffusion network for generating images based on the encoded multimodal input.
We leverage a two-stage training strategy to effectively train the framework: firstly pre-training on large-scale text-image pairs to develop conditional image generation capabilities, and then instruction tuning with multimodal prompts to achieve unified image generation proficiency.
A well-designed data processing pipeline involving language grounding and image segmentation is employed to construct multi-modal prompts. UNIMO-G excels in both text-to-image generation and zero-shot subject-driven synthesis and is notably effective in generating high-fidelity images from complex multimodal prompts involving multiple image entities.
1.8. Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs

Diffusion models have exhibited exceptional performance in text-to-image generation and editing. However, existing methods often face challenges when handling complex text prompts that involve multiple objects with multiple attributes and relationships.
In this paper, we propose a brand new training-free text-to-image generation/editing framework, namely Recaption, Plan, and Generate (RPG), harnessing the powerful chain-of-thought reasoning ability of multimodal LLMs to enhance the compositionality of text-to-image diffusion models.
Our approach employs the MLLM as a global planner to decompose the process of generating complex images into multiple simpler generation tasks within subregions. We propose complementary regional diffusion to enable region-wise compositional generation. Furthermore, we integrate text-guided image generation and editing within the proposed RPG in a closed-loop fashion, thereby enhancing generalization ability.
Extensive experiments demonstrate our RPG outperforms state-of-the-art text-to-image diffusion models, including DALL-E 3 and SDXL, particularly in multi-category object composition and text-image semantic alignment. Notably, our RPG framework exhibits wide compatibility with various MLLM architectures (e.g., MiniGPT-4) and diffusion backbones (e.g., ControlNet).
1.9. Scalable High-Resolution Pixel-Space Image Synthesis with Hourglass Diffusion Transformers

We present the Hourglass Diffusion Transformer (HDiT), an image-generative model that exhibits linear scaling with pixel count, supporting training at high resolution (e.g. 1024 times 1024) directly in pixel space.
Building on the Transformer architecture, which is known to scale to billions of parameters, it bridges the gap between the efficiency of convolutional U-Nets and the scalability of Transformers.
HDiT trains successfully without typical high-resolution training techniques such as multiscale architectures, latent autoencoders, or self-conditioning. We demonstrate that HDiT performs competitively with existing models on ImageNet 256², and sets a new state-of-the-art for diffusion models on FFHQ-1024².
1.10. EmerDiff: Emerging Pixel-level Semantic Knowledge in Diffusion Models

Diffusion models have recently received increasing research attention for their remarkable transfer abilities in semantic segmentation tasks. However, generating fine-grained segmentation masks with diffusion models often requires additional training on annotated datasets, leaving it unclear to what extent pre-trained diffusion models alone understand the semantic relations of their generated images.
To address this question, we leverage the semantic knowledge extracted from Stable Diffusion (SD) and aim to develop an image segmentor capable of generating fine-grained segmentation maps without any additional training. The primary difficulty stems from the fact that semantically meaningful feature maps typically exist only in the spatially lower-dimensional layers, which poses a challenge in directly extracting pixel-level semantic relations from these feature maps.
To overcome this issue, our framework identifies semantic correspondences between image pixels and spatial locations of low-dimensional feature maps by exploiting SD’s generation process and utilizes them for constructing image-resolution segmentation maps. In extensive experiments, the produced segmentation maps are demonstrated to be well-delineated and capture detailed parts of the images, indicating the existence of highly accurate pixel-level semantic knowledge in diffusion models.
1.11. UltrAvatar: A Realistic Animatable 3D Avatar Diffusion Model with Authenticity Guided Textures

Recent advances in 3D avatar generation have gained significant attention. These breakthroughs aim to produce more realistic animatable avatars, narrowing the gap between virtual and real-world experiences. Most of the existing works employ Score Distillation Sampling (SDS) loss, combined with a differentiable renderer and text condition, to guide a diffusion model in generating 3D avatars.
However, SDS often generates over-smoothed results with few facial details, thereby lacking diversity compared with ancestral sampling. On the other hand, other works generate 3D avatars from a single image, where the challenges of unwanted lighting effects, perspective views, and inferior image quality make it difficult to reliably reconstruct the 3D face meshes with aligned complete textures.
In this paper, we propose a novel 3D avatar generation approach termed UltrAvatar with enhanced fidelity of geometry, and superior quality of physically based rendering (PBR) textures without unwanted lighting. To this end, the proposed approach presents a diffuse color extraction model and an authenticity-guided texture diffusion model. The former removes the unwanted lighting effects to reveal true diffuse colors so that the generated avatars can be rendered under various lighting conditions.
The latter follows two gradient-based guidances for generating PBR textures to render diverse face-identity features and details better aligning with 3D mesh geometry. We demonstrate the effectiveness and robustness of the proposed method, outperforming the state-of-the-art methods by a large margin in the experiments.
2. Vision Language Models
2.1. SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities

Understanding and reasoning about spatial relationships is a fundamental capability for Visual Question Answering (VQA) and robotics. While Vision Language Models (VLM) have demonstrated remarkable performance in certain VQA benchmarks, they still lack capabilities in 3D spatial reasoning, such as recognizing quantitative relationships of physical objects like distances or size differences.
We hypothesize that VLMs’ limited spatial reasoning capability is due to the lack of 3D spatial knowledge in training data and aim to solve this problem by training VLMs with Internet-scale spatial reasoning data. To this end, we present a system to facilitate this approach. We first develop an automatic 3D spatial VQA data generation framework that scales up to 2 billion VQA examples on 10 million real-world images.
We then investigate various factors in the training recipe, including data quality, training pipeline, and VLM architecture. Our work features the first internet-scale 3D spatial reasoning dataset in metric space. By training a VLM on such data, we significantly enhance its ability on both qualitative and quantitative spatial VQA. Finally, we demonstrate that this VLM unlocks novel downstream applications in chain-of-thought spatial reasoning and robotics due to its quantitative estimation capability.
3. Image Generation & Editing
3.1. Sketch2NeRF: Multi-view Sketch-guided Text-to-3D Generation
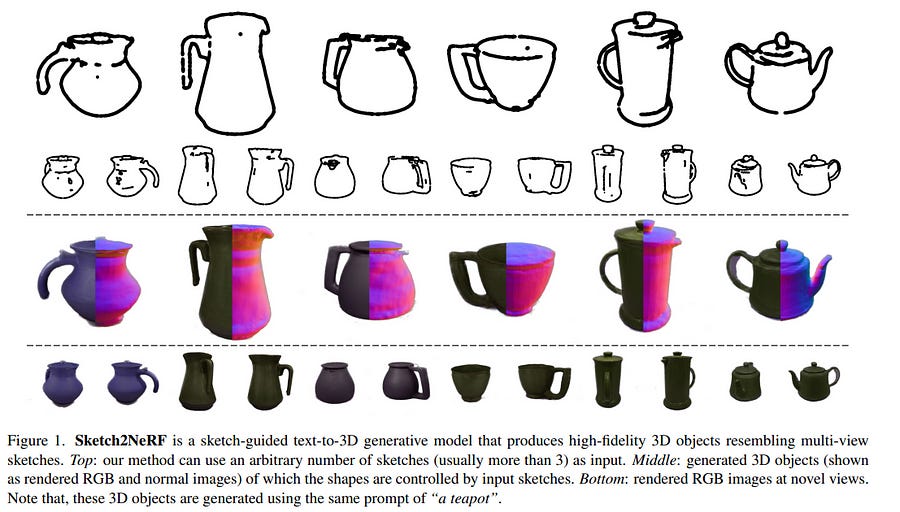
Recently, text-to-3D approaches have achieved high-fidelity 3D content generation using text description. However, the generated objects are stochastic and lack fine-grained control. Sketches provide a cheap approach to introducing such fine-grained control.
Nevertheless, it is challenging to achieve flexible control from these sketches due to their abstraction and ambiguity. In this paper, we present a multi-view sketch-guided text-to-3D generation framework (namely, Sketch2NeRF) to add sketch control to 3D generation. Specifically, our method leverages pretrained 2D diffusion models (e.g., Stable Diffusion and ControlNet) to supervise the optimization of a 3D scene represented by a neural radiance field (NeRF).
We propose a novel synchronized generation and reconstruction method to effectively optimize the NeRF. In the experiments, we collected two kinds of multi-view sketch datasets to evaluate the proposed method. We demonstrate that our method can synthesize 3D consistent contents with fine-grained sketch control while being high-fidelity to text prompts. Extensive results show that our method achieves state-of-the-art performance in terms of sketch similarity and text alignment.
3.2. Single-View 3D Human Digitalization with Large Reconstruction Models

In this paper, we introduce Human-LRM, a single-stage feed-forward Large Reconstruction Model designed to predict human Neural Radiance Fields (NeRF) from a single image.
Our approach demonstrates remarkable adaptability in training using extensive datasets containing 3D scans and multi-view capture. Furthermore, to enhance the model’s applicability for in-the-wild scenarios especially with occlusions, we propose a novel strategy that distills multi-view reconstruction into single-view via a conditional triplane diffusion model.
This generative extension addresses the inherent variations in human body shapes when observed from a single view, and makes it possible to reconstruct the full body human from an occluded image. Through extensive experiments, we show that Human-LRM surpasses previous methods by a significant margin on several benchmarks.
4. Video Generation & Editing
4.1. Understanding Video Transformers via Universal Concept Discovery

This paper studies the problem of concept-based interpretability of transformer representations for videos. Concretely, we seek to explain the decision-making process of video transformers based on high-level, spatiotemporal concepts that are automatically discovered. Prior research on concept-based interpretability has concentrated solely on image-level tasks.
Comparatively, video models deal with the added temporal dimension, increasing complexity and posing challenges in identifying dynamic concepts over time. In this work, we systematically address these challenges by introducing the first Video Transformer Concept Discovery (VTCD) algorithm.
To this end, we propose an efficient approach for unsupervised identification of units of video transformer representations — concepts, and ranking their importance to the output of a model. The resulting concepts are highly interpretable, revealing spatio-temporal reasoning mechanisms and object-centric representations in unstructured video models.
Performing this analysis jointly over a diverse set of supervised and self-supervised representations, we discover that some of these mechanisms are universal in video transformers. Finally, we demonstrate that VTCDcan be used to improve model performance for fine-grained tasks.
4.2. Lumiere: A Space-Time Diffusion Model for Video Generation

We introduce Lumiere — a text-to-video diffusion model designed for synthesizing videos that portray realistic, diverse, and coherent motion — a pivotal challenge in video synthesis. To this end, we introduce a Space-Time U-Net architecture that generates the entire temporal duration of the video at once, through a single pass in the model.
This is in contrast to existing video models which synthesize distant keyframes followed by temporal super-resolution — an approach that inherently makes global temporal consistency difficult to achieve. By deploying both spatial and (importantly) temporal down- and up-sampling and leveraging a pre-trained text-to-image diffusion model, our model learns to directly generate a full-frame-rate, low-resolution video by processing it in multiple space-time scales.
We demonstrate state-of-the-art text-to-video generation results and show that our design easily facilitates a wide range of content creation tasks and video editing applications, including image-to-video, video inpainting, and stylized generation.
4.3. ActAnywhere: Subject-Aware Video Background Generation

Generating video backgrounds that tailor to foreground subject motion is an important problem for the movie industry and visual effects community. This task involves synthesizing background that aligns with the motion and appearance of the foreground subject, while also complying with the artist’s creative intention.
We introduce ActAnywhere, a generative model that automates this process which traditionally requires tedious manual efforts. Our model leverages the power of large-scale video diffusion models and is specifically tailored for this task. ActAnywhere takes a sequence of foreground subject segmentation as input and an image that describes the desired scene as condition, to produce a coherent video with realistic foreground-background interactions while adhering to the condition frame. We train our model on a large-scale dataset of human-scene interaction videos.
Extensive evaluations demonstrate the superior performance of our model, significantly outperforming baselines. Moreover, we show that ActAnywhere generalizes to diverse out-of-distribution samples, including non-human subjects.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
