


Top Important Computer Vision Papers for the Week from 23/10 to 29/10
Stay Relevant to Recent Computer Vision Research

On a weekly basis, several top-tier academic conferences and journals showcased innovative research in computer vision, presenting exciting breakthroughs in various subfields such as image recognition, vision model optimization, generative adversarial networks (GANs), image segmentation, video analysis, and more.
This article provides a comprehensive overview of the most significant papers published in the fourth week of October 2023, highlighting the latest research and advancements in computer vision. Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Are you looking to start a career in data science and AI and need to learn how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
1. Image Generation
1.1. DPM-Solver-v3: Improved Diffusion ODE Solver with Empirical Model Statistics

Diffusion probabilistic models (DPMs) have exhibited excellent performance for high-fidelity image generation while suffering from inefficient sampling. Recent works accelerate the sampling procedure by proposing fast ODE solvers that leverage the specific ODE form of DPMs.
However, they highly rely on specific parameterization during inference (such as noise/data prediction), which might not be the optimal choice. In this work, the authors propose a novel formulation towards the optimal parameterization during sampling that minimizes the first-order discretization error of the ODE solution.
Based on such formulation, they propose DPM-Solver-v3, a new fast ODE solver for DPMs by introducing several coefficients efficiently computed on the pretrained model, which they called empirical model statistics.
They further incorporate multistep methods and a predictor-corrector framework, and propose some techniques for improving sample quality at small numbers of function evaluations (NFE) or large guidance scales. Experiments show that DPM-Solver-v3 achieves consistently better or comparable performance in both unconditional and conditional sampling with both pixel-space and latent-space DPMs, especially in 5sim10 NFEs.
They achieved FIDs of 12.21 (5 NFE), 2.51 (10 NFE) on unconditional CIFAR10, and MSE of 0.55 (5 NFE, 7.5 guidance scale) on Stable Diffusion, bringing a speed-up of 15\%sim30\% compared to previous state-of-the-art training-free methods.
1.2. ScaleLong: Towards More Stable Training of Diffusion Model via Scaling Network Long Skip Connection

In diffusion models, UNet is the most popular network backbone, since its long skip connects (LSCs) to connect distant network blocks can aggregate long-distant information and alleviate vanishing gradient. Unfortunately, UNet often suffers from unstable training in diffusion models which can be alleviated by scaling its LSC coefficients smaller.
However, theoretical understandings of the instability of UNet in diffusion models and the performance improvement of LSC scaling remain absent. To solve this issue, the authors theoretically show that the coefficients of LSCs in UNet have big effects on the stableness of the forward and backward propagation and robustness of UNet.
Specifically, the hidden feature and gradient of UNet at any layer can oscillate and their oscillation ranges are actually large which explains the instability of UNet training. Moreover, UNet is also provably sensitive to perturbed input, and predicts an output distant from the desired output, yielding oscillatory loss and thus oscillatory gradient. Besides, they also observe the theoretical benefits of the LSC coefficient scaling of UNet in the stableness of hidden features and gradient and also robustness.
Finally, inspired by this theory, the authors propose an effective coefficient scaling framework ScaleLong that scales the coefficients of LSC in UNet and better improves the training stability of UNet. Experimental results on four famous datasets show that the proposed methods are superior in stabilizing training and yield about 1.5x training acceleration on different diffusion models with UNet or UViT backbones.
1.3. Matryoshka Diffusion Models

Diffusion models are the de facto approach for generating high-quality images and videos, but learning high-dimensional models remains a formidable task due to computational and optimization challenges. Existing methods often resort to training cascaded models in pixel space or using a downsampled latent space of a separately trained auto-encoder.
In this paper, the authors introduce Matryoshka Diffusion Models(MDM), an end-to-end framework for high-resolution image and video synthesis. The authors propose a diffusion process that denoises inputs at multiple resolutions jointly and uses a NestedUNet architecture where features and parameters for small-scale inputs are nested within those of large scales.
In addition, MDM enables a progressive training schedule from lower to higher resolutions, which leads to significant improvements in optimization for high-resolution generation.
They demonstrate the effectiveness of our approach on various benchmarks, including class-conditioned image generation, high-resolution text-to-image, and text-to-video applications.
Remarkably, they can train a single pixel-space model at resolutions of up to 1024x1024 pixels, demonstrating strong zero-shot generalization using the CC12M dataset, which contains only 12 million images.
1.4. FreeNoise: Tuning-Free Longer Video Diffusion Via Noise Rescheduling

With the availability of large-scale video datasets and the advances in diffusion models, text-driven video generation has achieved substantial progress.
However, existing video generation models are typically trained on a limited number of frames, resulting in the inability to generate high-fidelity long videos during inference. Furthermore, these models only support single-text conditions, whereas real-life scenarios often require multi-text conditions as the video content changes over time.
To tackle these challenges, this study explores the potential of extending the text-driven capability to generate longer videos conditioned on multiple texts.
The authors first analyze the impact of initial noise in video diffusion models. Then building upon the observation of noise, they propose FreeNoise, a tuning-free and time-efficient paradigm to enhance the generative capabilities of pretrained video diffusion models while preserving content consistency. Specifically, instead of initializing noises for all frames, they reschedule a sequence of noises for long-range correlation and perform temporal attention over them by window-based function.
Additionally, they designed a novel motion injection method to support the generation of videos conditioned on multiple text prompts. Extensive experiments validate the superiority of this paradigm in extending the generative capabilities of video diffusion models. It is noteworthy that compared with the previous best-performing method which brought about 255% extra time cost, our method incurs only a negligible time cost of approximately 17%.
1.5. DEsignBench: Exploring and Benchmarking DALL-E 3 for Imagining Visual Design

The authors introduce DEsignBench, a text-to-image (T2I) generation benchmark tailored for visual design scenarios. Recent T2I models like DALL-E 3 and others, have demonstrated remarkable capabilities in generating photorealistic images that align closely with textual inputs.
While the allure of creating visually captivating images is undeniable, the emphasis extends beyond mere aesthetic pleasure. The authors aim to investigate the potential of using these powerful models in authentic design contexts.
In pursuit of this goal, the authors developed DEsignBench, which incorporates test samples designed to assess T2I models on both “design technical capability” and “design application scenario.”
Each of these two dimensions is supported by a diverse set of specific design categories. They explore DALL-E 3 together with other leading T2I models on DEsignBench, resulting in a comprehensive visual gallery for side-by-side comparisons.
For DEsignBench benchmarking, they perform human evaluations on generated images in the DEsignBench gallery, against the criteria of image-text alignment, visual aesthetic, and design creativity.
The evaluation also considers other specialized design capabilities, including text rendering, layout composition, color harmony, 3D design, and medium style.
In addition to human evaluations, they introduce the first automatic image generation evaluator powered by GPT-4V. This evaluator provides ratings that align well with human judgments while being easily replicable and cost-efficient.
1.6. Localizing and Editing Knowledge in Text-to-Image Generative Models

Text-to-image diffusion Models such as Stable-Diffusion and Imagen have achieved unprecedented quality of photorealism with state-of-the-art FID scores on MS-COCO and other generation benchmarks. Given a caption, image generation requires fine-grained knowledge about attributes such as object structure, style, and viewpoint amongst others.
Where does this information reside in text-to-image generative models? In this paper, the authors tackle this question and understand how knowledge corresponding to distinct visual attributes is stored in large-scale text-to-image diffusion models. They adapt Causal Mediation Analysis for text-to-image models and trace knowledge about distinct visual attributes to various (causal) components in the (i) UNet and (ii) text-encoder of the diffusion model.
In particular, they show that, unlike generative large-language models, knowledge about different attributes is not localized in isolated components, but is instead distributed amongst a set of components in the conditional UNet. These sets of components are often distinct for different visual attributes.
Remarkably, they find that the CLIP text-encoder in public text-to-image models such as Stable-Diffusion contains only one causal state across different visual attributes, and this is the first self-attention layer corresponding to the last subject token of the attribute in the caption. This is in stark contrast to the causal states in other language models which are often the mid-MLP layers.
Based on this observation of only one causal state in the text-encoder, they introduce a fast, data-free model editing method Diff-QuickFix which can effectively edit concepts in text-to-image models. DiffQuickFix can edit (ablate) concepts in under a second with a closed-form update, providing a significant 1000x speedup and comparable editing performance to existing fine-tuning-based editing methods.
1.7. TexFusion: Synthesizing 3D Textures with Text-Guided Image Diffusion Models

This paper presents TexFusion (Texture Diffusion), a new method to synthesize textures for given 3D geometries, using large-scale text-guided image diffusion models.
In contrast to recent works that leverage 2D text-to-image diffusion models to distill 3D objects using a slow and fragile optimization process, TexFusion introduces a new 3D-consistent generation technique specifically designed for texture synthesis that employs regular diffusion model sampling on different 2D rendered views.
Specifically, the authors leverage latent diffusion models, apply the diffusion model’s denoiser on a set of 2D renders of the 3D object, and aggregate the different denoising predictions on a shared latent texture map.
Final output RGB textures are produced by optimizing an intermediate neural color field on the decodings of 2D renders of the latent texture. They thoroughly validate TexFusion and show that we can efficiently generate diverse, high-quality, and globally coherent textures.
They achieve state-of-the-art text-guided texture synthesis performance using only image diffusion models while avoiding the pitfalls of previous distillation-based methods. The text-conditioning offers detailed control and we also do not rely on any ground truth 3D textures for training. This makes the method versatile and applicable to a broad range of geometry and texture types. They hope that TexFusion will advance AI-based texturing of 3D assets for applications in virtual reality, game design, simulation, and more.
1.8. A Picture is Worth a Thousand Words: Principled Recaptioning Improves Image Generation

Text-to-image diffusion models achieved a remarkable leap in capabilities over the last few years, enabling high-quality and diverse synthesis of images from a textual prompt.
However, even the most advanced models often struggle to precisely follow all of the directions in their prompts. The vast majority of these models are trained on datasets consisting of (image, and caption) pairs where the images often come from the web, and the captions are their HTML alternate text. A notable example is the LAION dataset, used by Stable Diffusion and other models.
In this work, the authors observe that these captions are often of low quality, and argue that this significantly affects the model’s capability to understand nuanced semantics in the textual prompts.
They show that by relabeling the corpus with a specialized automatic captioning model and training a text-to-image model on the recaptioned dataset, the model benefits substantially across the board.
First, in overall image quality: e.g. FID 14.84 vs. the baseline of 17.87, and 64.3% improvement in faithful image generation according to human evaluation. Second, in semantic alignment, e.g. semantic object accuracy 84.34 vs. 78.90, counting alignment errors 1.32 vs. 1.44, and positional alignment 62.42 vs. 57.60.
They analyze various ways to relabel the corpus and provide evidence that this technique, which we call RECAP, both reduces the train-inference discrepancy and provides the model with more information for example, increasing sample efficiency and allowing the model to better understand the relations between captions and images.
1.9. DreamCraft3D: Hierarchical 3D Generation with Bootstrapped Diffusion Prior

This paper presents DreamCraft3D, a hierarchical 3D content generation method that produces high-fidelity and coherent 3D objects. The authors tackle the problem by leveraging a 2D reference image to guide the stages of geometry sculpting and texture boosting.
A central focus of this work is to address the consistency issue that existing works encounter. To sculpt geometries that render coherently, the authors perform score distillation sampling via a view-dependent diffusion model. This 3D prior, alongside several training strategies, prioritizes the geometry consistency but compromises the texture fidelity.
They further propose Bootstrapped Score Distillation to specifically boost the texture. They train a personalized diffusion model, Dreambooth, on the augmented renderings of the scene, imbuing it with 3D knowledge of the scene being optimized. The score distillation from this 3D-aware diffusion prior provides view-consistent guidance for the scene.
Notably, through an alternating optimization of the diffusion prior and 3D scene representation, they achieve mutually reinforcing improvements: the optimized 3D scene aids in training the scene-specific diffusion model, which offers increasingly view-consistent guidance for 3D optimization.
The optimization is thus bootstrapped and leads to substantial texture boosting. With tailored 3D priors throughout the hierarchical generation, DreamCraft3D generates coherent 3D objects with photorealistic renderings, advancing the state-of-the-art in 3D content generation.
1.10. CommonCanvas: An Open Diffusion Model Trained with Creative-Commons Images
The authors assemble a dataset of Creative-Commons-licensed (CC) images, which they use to train a set of open diffusion models that are qualitatively competitive with Stable Diffusion 2 (SD2). This task presents two challenges:
High-resolution CC images lack the captions necessary to train text-to-image generative models.
CC images are relatively scarce. In turn, to address these challenges, they use an intuitive transfer learning technique to produce a set of high-quality synthetic captions paired with curated CC images.
They then develop a data- and compute-efficient training recipe that requires as little as 3% of the LAION-2B data needed to train existing SD2 models but obtains comparable quality. These results indicate that we have a sufficient number of CC images (~70 million) for training high-quality models.
The training recipe also implements a variety of optimizations that achieve ~3X training speed-ups, enabling rapid model iteration. They leverage this recipe to train several high-quality text-to-image models, which we dub the CommonCanvas family.
The largest model achieves comparable performance to SD2 on a human evaluation, despite being trained on our CC dataset being significantly smaller than LAION and using synthetic captions for training.
1.11. Wonder3D: Single Image to 3D using Cross-Domain Diffusion

In this work, the authors introduce Wonder3D, a novel method for efficiently generating high-fidelity textured meshes from single-view images. Recent methods based on Score Distillation Sampling (SDS) have shown the potential to recover 3D geometry from 2D diffusion priors, but they typically suffer from time-consuming per-shape optimization and inconsistent geometry.
In contrast, certain works directly produce 3D information via fast network inferences, but their results are often of low quality and lack geometric details.
To holistically improve the quality, consistency, and efficiency of image-to-3D tasks, they propose a cross-domain diffusion model that generates multi-view normal maps and the corresponding color images. To ensure consistency, the authors employ a multi-view cross-domain attention mechanism that facilitates information exchange across views and modalities.
Lastly, the authors introduce a geometry-aware normal fusion algorithm that extracts high-quality surfaces from the multi-view 2D representations. These extensive evaluations demonstrate that the proposed method achieves high-quality reconstruction results, robust generalization, and reasonably good efficiency compared to prior works.
2. Vison Lnaguage Models
2.1. SILC: Improving Vision Language Pretraining with Self-Distillation

Image-text pretraining on web-scale image caption datasets has become the default recipe for open vocabulary classification and retrieval models thanks to the success of CLIP and its variants.
Several works have also used CLIP features for dense prediction tasks and have shown the emergence of open-set abilities. However, the contrastive objective only focuses on image-text alignment and does not incentivize image feature learning for dense prediction tasks.
In this work, the authors propose the simple addition of local-to-global correspondence learning by self-distillation as an additional objective for contrastive pre-training to propose SILC. They show that distilling local image features from an exponential moving average (EMA) teacher model significantly improves model performance on several computer vision tasks including classification, retrieval, and especially segmentation.
They further show that SILC scales better with the same training duration compared to the baselines. This model SILC sets a new state of the art for zero-shot classification, few-shot classification, image and text retrieval, zero-shot segmentation, and open vocabulary segmentation.
2.2. HallusionBench: You See What You Think? Or You Think What You See? An Image-Context Reasoning Benchmark Challenging for GPT-4V(ision), LLaVA-1.5, and Other Multi-modality Models
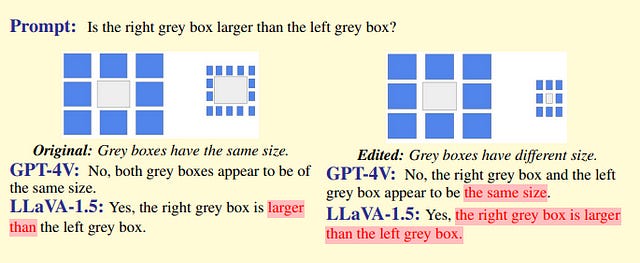
Large language models (LLMs), after being aligned with vision models and integrated into vision-language models (VLMs), can bring impressive improvement in image reasoning tasks. This was shown by the recently released GPT-4V(ison), LLaVA-1.5, etc.
However, the strong language prior in these SOTA LVLMs can be a double-edged sword: they may ignore the image context and solely rely on the (even contradictory) language prior for reasoning. In contrast, the vision modules in VLMs are weaker than LLMs and may result in misleading visual representations, which are then translated to confident mistakes by LLMs.
To study these two types of VLM mistakes, i.e., language hallucination and visual illusion, the authors curated HallusionBench, an image-context reasoning benchmark that is still challenging even with GPT-4V and LLaVA-1.5. They provide a detailed analysis of examples in HallusionBench, which sheds novel insights on the illusion or hallucination of VLMs and how to improve them in the future.
2.3. SAM-CLIP: Merging Vision Foundation Models Towards Semantic and Spatial Understanding

The landscape of publicly available vision foundation models (VFMs), such as CLIP and Segment Anything Model (SAM), is expanding rapidly. VFMs are endowed with distinct capabilities stemming from their pre-training objectives. For instance, CLIP excels in semantic understanding, while SAM specializes in spatial understanding for segmentation.
In this work, the authors introduce a simple recipe to efficiently merge VFMs into a unified model that assimilates their expertise. The proposed method integrates multi-task learning, continual learning techniques, and teacher-student distillation. This strategy entails significantly less computational cost compared to traditional multi-task training from scratch. Additionally, it only demands a small fraction of the pre-training datasets that were initially used to train individual models.
By applying this method to SAM and CLIP, we derive SAM-CLIP: a unified model that amalgamates the strengths of SAM and CLIP into a single backbone, making it apt for edge device applications.
The authors show that SAM-CLIP learns richer visual representations, equipped with both localization and semantic features, suitable for a broad range of vision tasks. SAM-CLIP obtains improved performance on several head probing tasks when compared with SAM and CLIP.
They further show that SAM-CLIP not only retains the foundational strengths of its precursor models but also introduces synergistic functionalities, most notably in zero-shot semantic segmentation, where SAM-CLIP establishes new state-of-the-art results on 5 benchmarks.
It outperforms previous models that are specifically designed for this task by a large margin, including +6.8% and +5.9% mean IoU improvement on Pascal-VOC and COCO-Stuff datasets, respectively.
2.4. An Early Evaluation of GPT-4V(vision)

In this paper, the authors evaluate different abilities of GPT-4V including visual understanding, language understanding, visual puzzle solving, and understanding of other modalities such as depth, thermal, video, and audio. To estimate GPT-4V’s performance, they manually construct 656 test instances and carefully evaluate the results of GPT-4V.
The highlights of our findings are as follows:
GPT-4V exhibits impressive performance on English visual-centric benchmarks but fails to recognize simple Chinese texts in the images.
GPT-4V shows inconsistent refusal behavior when answering questions related to sensitive traits such as gender, race, and age.
GPT-4V obtains worse results than GPT-4 (API) on language understanding tasks including general language understanding benchmarks and visual commonsense knowledge evaluation benchmarks.
Few-shot prompting can improve GPT-4V’s performance in both visual understanding and language understanding
GPT-4V struggles to find the nuances between two similar images and solve the easy math picture puzzles
GPT-4V shows non-trivial performance on tasks of similar modalities to image, such as video and thermal.
The experimental results reveal the ability and limitations of GPT-4V and provide some insights into the application and research of GPT-4V.
2.5. TiC-CLIP: Continual Training of CLIP Models

Keeping large foundation models up to date on the latest data is inherently expensive. To avoid the prohibitive costs of constantly retraining, it is imperative to continually train these models.
This problem is exacerbated by the lack of any large-scale continual learning benchmarks or baselines. The authors introduce the first set of web-scale Time-Continual (TiC) benchmarks for training vision-language models: TiC-DataCompt, TiC-YFCC, and TiC-RedCaps with over 12.7B timestamped image-text pairs spanning 9 years (2014–2022).
They first use their benchmarks to curate various dynamic evaluations to measure the temporal robustness of existing models. They show OpenAI’s CLIP (trained on data up to 2020) loses approx 8% zero-shot accuracy on their curated retrieval task from 2021–2022 compared with more recently trained models in the OpenCLIP repository.
They then study how to efficiently train models on time-continuous data. They demonstrate that a simple rehearsal-based approach that continues training from the last checkpoint and replays old data reduces computing by 2.5 times when compared to the standard practice of retraining from scratch.
3. Image Recognition
3.1. Inject Semantic Concepts into Image Tagging for Open-Set Recognition

In this paper, the authors introduce the Recognize Anything Plus Model~(RAM++), a fundamental image recognition model with strong open-set recognition capabilities, by injecting semantic concepts into the image tagging training framework.
Previous approaches are either image tagging models constrained by limited semantics, or vision-language models with shallow interaction for suboptimal performance in multi-tag recognition.
In contrast, RAM++ integrates image-text alignment and image-tagging within a unified fine-grained interaction framework based on image-tags-text triplets. This design enables RAM++ not only to excel in identifying predefined categories but also significantly augment the recognition ability in open-set categories.
Moreover, RAM++ employs large language models~(LLMs) to generate diverse visual tag descriptions, pioneering the integration of LLM knowledge into image tagging training.
This approach empowers RAM++ to integrate visual description concepts for open-set recognition during inference. Evaluations on comprehensive image recognition benchmarks demonstrate that RAM++ exceeds existing state-of-the-art (SOTA) fundamental image recognition models in most aspects.
Specifically, for predefined common-used tag categories, RAM++ showcases 10.2 mAP and 15.4 mAP enhancements over CLIP on OpenImages and ImageNet.
For open-set categories beyond predefined, RAM++ records improvements of 5 mAP and 6.4 mAP over CLIP and RAM respectively on OpenImages. For diverse human-object interaction phrases, RAM++ achieves 7.8 mAP and 4.7 mAP improvements on the HICO benchmark.
3.2. ConvNets Match Vision Transformers at Scale

Many researchers believe that ConvNets perform well on small or moderately sized datasets, but are not competitive with Vision Transformers when given access to datasets on the web scale.
The authors challenge this belief by evaluating a performant ConvNet architecture pre-trained on JFT-4B, a large labeled dataset of images often used for training foundation models. They consider pre-training compute budgets between 0.4k and 110k TPU-v4 core compute hours, and train a series of networks of increasing depth and width from the NFNet model family.
They observe a log-log scaling law between held-out loss and compute budget. After fine-tuning on ImageNet, NFNets match the reported performance of Vision Transformers with comparable compute budgets. The strongest fine-tuned model achieves a Top-1 accuracy of 90.4%.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM

Thanks for the effort youssef 👏