
The RAG Spectrum: Exploring 7 Distinct Architectures from Naive to Agentic
Mastering RAG: 7 Key Architectures to Elevate Your LLM Applications

Retrieval Augmented Generation (RAG) has emerged as a pivotal technique for enhancing Large Language Models (LLMs) by grounding their responses in external, verifiable knowledge.
However, the RAG landscape is diverse, with various architectural patterns suiting different needs and data types. This article provides a comprehensive overview of seven key RAG architectures, starting from foundational “Naive RAG” and progressing through more sophisticated models like “Retrieve-and-Rerank,” “Multimodal RAG” for handling diverse data, “Graph RAG” leveraging structured knowledge, and “Hybrid RAG” blending techniques.
It further explores advanced “Agentic RAG” systems, including “Router RAG” where an agent decides retrieval strategy, and “Multi-Agent RAG” enabling collaborative problem-solving.
For each architecture, we discuss its core principles, illustrate its workflow (often with conceptual code examples), and highlight its specific advantages and ideal use cases, empowering readers to select and implement the most effective RAG strategy for their applications.
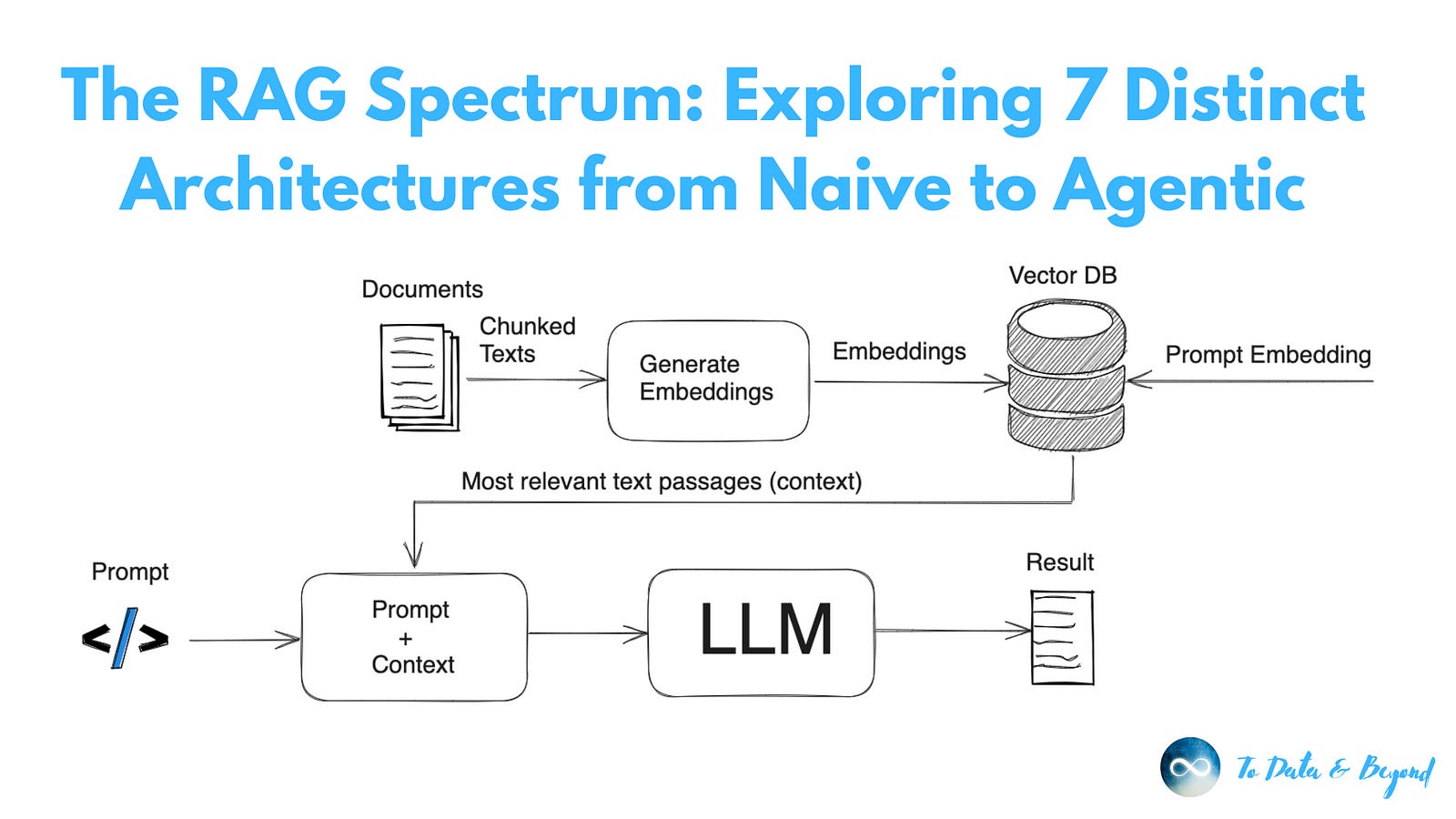
Table of Contents:
Naive RAG: Basic retrieval + generation
Retrieve-and-Rerank RAG: Smarter Retrieval via Ranking
Multimodal RAG: Handles Various Data Types (text, image)
Graph RAG: Uses Knowledge Graphs for Context
Hybrid RAG: Blends Retrieval Techniques
Agentic (Router) RAG: Agent Decides Retrieval Strategy
Agentic (Multi-Agent) RAG: Multiple Agents Collaborate using Different Tools
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. Naive RAG: Basic Retrieval + Generation

Naive RAG is the foundational architecture of Retrieval-Augmented Generation systems. It involves three core steps: retrieval, augmentation, and generation. First, documents are chunked and passed through an embedding model to create vector representations. These are stored in a vector database. When a user submits a query, it’s converted into a vector and matched against the document vectors to retrieve the most relevant chunks.
Next, the retrieved chunks (context) are combined with the query in a prompt template. This augmented prompt is passed to a large language model (LLM), which then generates a response. The strength of Naive RAG lies in its simplicity and efficiency, but it lacks any form of result re-ranking or complex decision-making, which can impact the accuracy of answers when documents are noisy or loosely related.
Here’s a simple example using LangChain and FAISS:
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import TextLoader
# Load and split documents
loader = TextLoader("data.txt")
documents = loader.load()
# Create vector store
embedding_model = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(documents, embedding_model)
# Initialize retriever and LLM
retriever = vectorstore.as_retriever()
llm = ChatOpenAI(model_name="gpt-3.5-turbo")
# Setup RAG pipeline
rag_chain = RetrievalQA.from_chain_type(llm=llm, retriever=retriever)
# Ask a question
response = rag_chain.run("What is RAG?")
print(response)This code sets up a simple RAG pipeline: load documents, embed and store them, retrieve relevant chunks based on a query, and generate a response using an LLM. No re-ranking or advanced reasoning is involved — just plain retrieval and generation.
2. Retrieve-and-Rerank RAG: Smarter Retrieval via Ranking
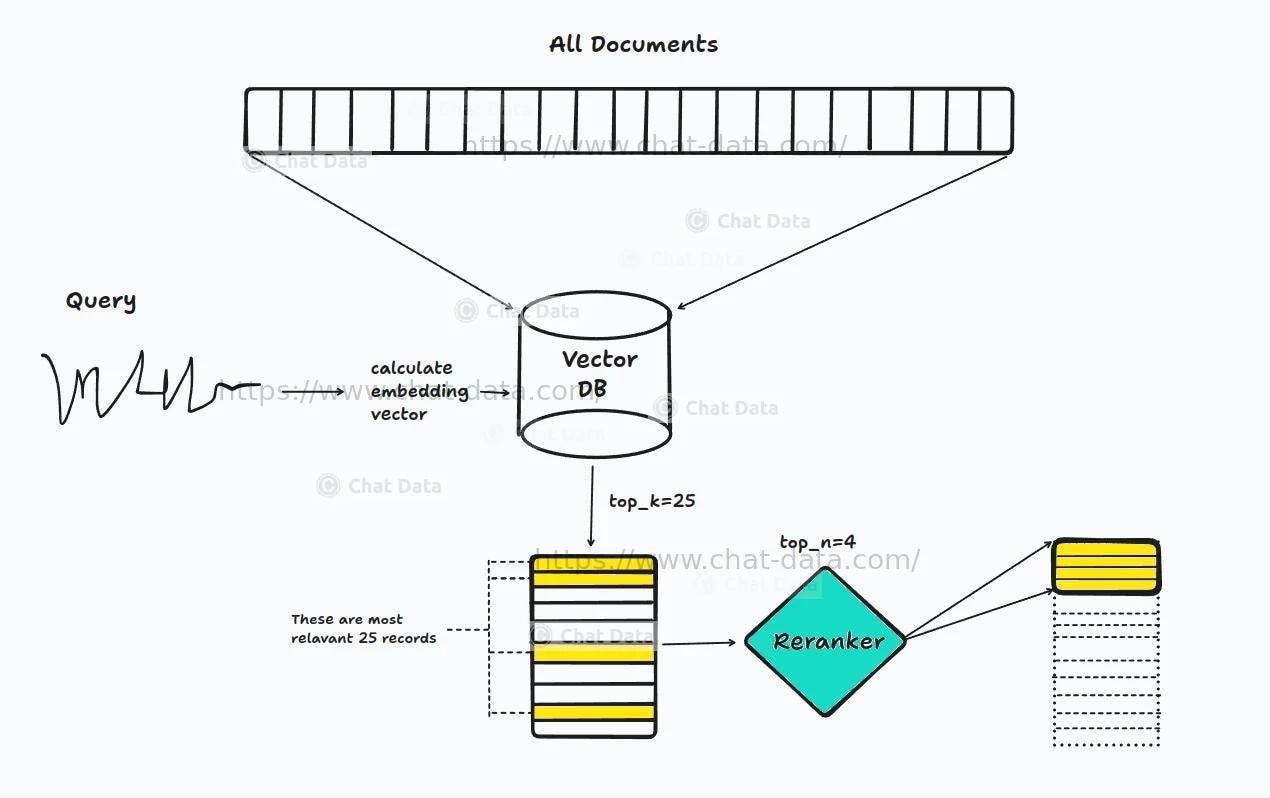
This architecture enhances basic RAG by adding an intelligent reranking step to improve the quality of retrieved context:
Embedding & Vector Retrieval (Top-K): Like Naive RAG, the process begins by embedding the user query and comparing it to document embeddings stored in a vector database. This initial step retrieves the top
k=25most similar chunks based on vector similarity.Reranker Model (Relevance Scoring): Instead of immediately sending these top-25 results to the LLM, we pass them through a reranker — a separate model trained to evaluate the semantic relevance of query-passage pairs more precisely (e.g., using models like
bge-rerankerorcolBERT). This model scores each of the 25 passages and ranks them based on actual relevance (not just vector similarity).Final Selection (Top-n): From these reranked results, only the top
n=4passages are selected to build the prompt for the LLM.LLM Generation: The final, highly relevant context is sent to the language model, improving both precision and faithfulness of the answer.
Why it’s Smarter than Naive RAG?
Reduces irrelevant noise from the vector store by not trusting vector similarity alone.
Adds a second layer of semantic filtering, ensuring only the most relevant information reaches the LLM.
Especially useful when your corpus is large or noisy, or when embeddings are coarse.
Here is a LangChain Pseudocode:
from langchain.vectorstores import FAISS
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import CohereRerank
# Create vector DB from docs
vectorstore = FAISS.from_documents(docs, HuggingFaceEmbeddings())
# Use a reranker as document compressor
reranker = CohereRerank(model="rerank-english-v2.0", top_n=4)
# Wrap retriever with reranker
retriever = ContextualCompressionRetriever(
base_compressor=reranker,
base_retriever=vectorstore.as_retriever(search_kwargs={"k": 25})
)
# Setup RetrievalQA pipeline
qa_chain = RetrievalQA.from_chain_type(
llm=ChatOpenAI(), retriever=retriever
)
response = qa_chain.run("What is Retrieve-and-Rerank RAG?")
print(response)3. Multimodal RAG: Handles various data types (text, image)

Multimodal RAG extends the capabilities of traditional RAG systems to understand and process information from various data types beyond just text. This includes images, videos, audio clips, and potentially other sensory data.
The core idea is to leverage multimodal embedding models that can represent different data modalities (e.g., an image and its textual description, or a video frame and spoken words) in a shared semantic vector space.
This allows for cross-modal retrieval, where a query in one modality (e.g., a text question) can retrieve relevant information from another modality (e.g., an image or a video segment).
The architecture, as shown in the diagram, typically involves an ingestion pipeline where “Enterprise Data” like “Videos” and “Images” undergoes “Ingest / Data Preprocessing.”
This preprocessed data is then fed into a “Multimodal Embedding Model” to generate vector representations, which are stored in an “Index / Vector Database.” When a “User Query / Question” (which could itself be text, an image, or a combination) arrives, it’s also processed by the “Multimodal Embedding Model.”
The resulting query embedding is used for “Multimodal Retrieval” from the vector database to find the most relevant multimodal data chunks. This retrieved data, along with the original query, undergoes “Prompt Processing” and is then passed to a “Large Vision Language Model Inference” (or a general multimodal LLM) to synthesize a “Response / Answer” that can integrate information from the diverse retrieved sources.
The significance of Multimodal RAG lies in its ability to answer more complex and nuanced queries that require understanding and correlating information across different formats.
For example, a user could ask, “Show me images where our product appears in an outdoor setting” or “Summarize the key points from the video segment where the new feature is demonstrated.” By bridging the gap between different data types, Multimodal RAG enables a richer and more comprehensive interaction with diverse knowledge bases.
Keep reading with a 7-day free trial
Subscribe to To Data & Beyond to keep reading this post and get 7 days of free access to the full post archives.