

Zero-shot learning allows AI systems to classify images into categories they haven’t explicitly been trained on, marking a significant advancement in computer vision and machine learning.
This blog post provides a detailed, step-by-step walkthrough of implementing zero-shot image classification with CLIP, from environment setup to final image processing and classification.
We begin by introducing the concept of zero-shot learning and its importance in modern AI applications. Next, we delve into an overview of the CLIP model, explaining its architecture and the principles behind its powerful cross-modal learning capabilities.
The guide then transitions into practical implementation, covering the essential steps of setting up the working environment, loading the CLIP model and processor, and preparing images for classification.
Readers will learn how to define custom labels for classification tasks and structure inputs for the CLIP model. The final sections detail the process of feeding data through the model and interpreting the classification results.
This blog post serves as both an educational resource for those new to zero-shot learning and a practical reference for implementing CLIP in real-world scenarios.

Table of Contents:
Introduction to zero-shot Image Classification
Overview of the CLIP Model
Setting-Up Working Environment
Loading the Model and Processor
Loading and Displaying the Image
Defining Labels and Inputs
Processing and Classifying the Image
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs. The content of the book covers the following topics:
1. Introduction to zero-shot Image Classification
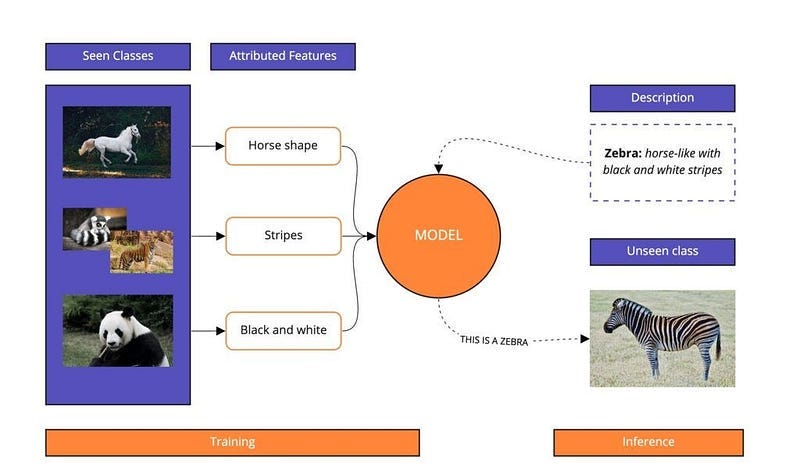
Zero-shot image classification is a task that involves classifying images into different categories using a model that hasn’t been explicitly trained on those specific categories. The model’s job is to predict the class it belongs to.
This is useful when you have a small amount of labeled data, or when you want to integrate image classification into an application quickly. Instead of training a custom model, you can use a pre-existing, pre-trained model.
These models are usually multi-modal and have been trained on a huge dataset of images and descriptions. They can then be used for lots of different tasks.
You might need to give the model some extra information about the classes it hasn’t seen — this is called auxiliary information and could be descriptions or attributes. Zero-shot classification is a subfield of transfer learning.
The zero-shot image classification task consists of classifying an image based on your own labels during inference time. For example, you can pass a list of labels such as plane, car, dog, bird, and the image you want to classify. The model will choose the most likely label. In this case, it should classify it as a photo of a dog.
Contrastive Language-Image Pretraining (CLIP) is one of the most popular models for zero-shot classification. It can classify images by common objects or characteristics of an image and doesn’t need to be fine-tuned for each new use case.
2. Overview of the CLIP Model

CLIP is a neural network that learns visual concepts from natural language supervision. It’s trained on pairs of images and texts and learns to predict the text corresponding to a given image. It can then be used for zero-shot classification of new images.
CLIP is flexible and can be applied to various visual classification benchmarks. It doesn’t need to optimize for the benchmark’s performance and has been shown to have state-of-the-art performance and distributional robustness. It outperforms existing models such as ImageNet on representation learning evaluation using linear probes.
The network consists of an image encoder and a text encoder, which are jointly trained to predict the correct pairings. During training, the image and text encoders are trained to maximize the cosine similarity of the image and text embeddings of the real pairs, while minimizing the cosine similarity of incorrect pairings.
CyCLIP is a framework that builds on CLIP by formalizing consistency. It optimizes the learned representations to be geometrically consistent in the image and text space and has been shown to improve the performance of CLIP.
3. Setting Up the Environment
Let’s start by setting up the working environments. First, we will download the packages we will use in this article. We will download the Transformers package and the torch package to use Pytorch.
!pip install transformers
!pip install torch4. Loading the Model and Processor
We need two main components to build the zero-shot image classification the model and the processor. Let’s first load the CLIP model from Transformers. To load the model, we will use the from_pretrained method and pass the correct checkpoint for this specific task.
model = CLIPModel.from_pretrained(
"./models/openai/clip-vit-large-patch14")Next, we will load a pretrained processor for the clip model using the Hugging Face Transformers library
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained(
"./models/openai/clip-vit-large-patch14")Keep reading with a 7-day free trial
Subscribe to To Data & Beyond to keep reading this post and get 7 days of free access to the full post archives.