


Important Computer Vision Papers for the Week from 29/07 to 04/08
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in various topics such as diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the Fourth Week of July 2024, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models (VLMs)
Video Understanding & Generation
Image Editing & Generation
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. Diffusion Models
1.1. Diffusion Feedback Helps CLIP See Better

Contrastive Language-Image Pre-training (CLIP), which excels at abstracting open-world representations across domains and modalities, has become a foundation for a variety of vision and multimodal tasks.
However, recent studies reveal that CLIP has severe visual shortcomings, such as the inability to distinguish orientation, quantity, color, structure, etc. These visual shortcomings also limit the perception capabilities of multimodal large language models (MLLMs) built on CLIP.
The main reason could be that the image-text pairs used to train CLIP are inherently biased, due to the need for the distinctiveness of the text and the diversity of images. This work presents a simple post-training approach for CLIP models, which largely overcomes its visual shortcomings via a self-supervised diffusion process.
We introduce DIVA, which uses the DIffusion model as a Visual Assistant for CLIP. Specifically, DIVA leverages generative feedback from text-to-image diffusion models to optimize CLIP representations, with only images (without corresponding text).
We demonstrate that DIVA improves CLIP’s performance on the challenging MMVP-VLM benchmark which assesses fine-grained visual abilities to a large extent (e.g., 3–7%), and enhances the performance of MLLMs and vision models on multimodal understanding and segmentation tasks.
Extensive evaluation of 29 image classification and retrieval benchmarks confirms that our framework preserves CLIP’s strong zero-shot capabilities.
1.2. Diffusion Augmented Agents: A Framework for Efficient Exploration and Transfer Learning

We introduce Diffusion Augmented Agents (DAAG), a novel framework that leverages large language models, vision language models, and diffusion models to improve sample efficiency and transfer learning in reinforcement learning for embodied agents.
DAAG hindsight relabels the agent’s past experience by using diffusion models to transform videos in a temporally and geometrically consistent way to align with target instructions with a technique we call Hindsight Experience Augmentation.
A large language model orchestrates this autonomous process without requiring human supervision, making it well-suited for lifelong learning scenarios.
The framework reduces the amount of reward-labeled data needed to:
Finetune is a vision language model that acts as a reward detector
Train RL agents on new tasks. We demonstrate the sample efficiency gains of DAAG in simulated robotics environments involving manipulation and navigation.
Our results show that DAAG improves learning of reward detectors, transferring past experience, and acquiring new tasks — key abilities for developing efficient lifelong learning agents.
1.3. Tora: Trajectory-oriented Diffusion Transformer for Video Generation

Recent advancements in Diffusion Transformer (DiT) have demonstrated remarkable proficiency in producing high-quality video content. Nonetheless, the potential of transformer-based diffusion models for effectively generating videos with controllable motion remains an area of limited exploration.
This paper introduces Tora, the first trajectory-oriented DiT framework that integrates textual, visual, and trajectory conditions concurrently for video generation. Specifically, Tora consists of a Trajectory Extractor~(TE), a spatial-temporal diT, and a Motion-guidance Fuser~(MGF).
The TE encodes arbitrary trajectories into hierarchical spacetime motion patches with a 3D video compression network. The MGF integrates the motion patches into the DiT blocks to generate consistent videos following trajectories.
Our design aligns seamlessly with DiT’s scalability, allowing precise control of video content dynamics with diverse durations, aspect ratios, and resolutions. Extensive experiments demonstrate Tora’s excellence in achieving high motion fidelity, while also meticulously simulating the movement of the physical world.
2. Vision Language Models (VLMs)
2.1. Wolf: Captioning Everything with a World Summarization Framework
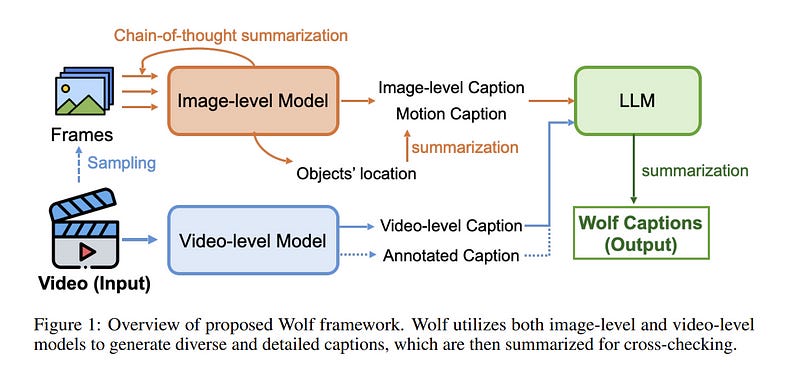
We propose Wolf, a WOrLd summarization Framework for accurate video captioning. Wolf is an automated captioning framework that adopts a mixture-of-experts approach, leveraging complementary strengths of Vision Language Models (VLMs).
By utilizing both image and video models, our framework captures different levels of information and summarizes them efficiently. Our approach can be applied to enhance video understanding, auto-labeling, and captioning.
To evaluate caption quality, we introduce CapScore, an LLM-based metric to assess the similarity and quality of generated captions compared to the ground truth captions. We further build four human-annotated datasets in three domains: autonomous driving, general scenes, and robotics, to facilitate comprehensive comparisons.
We show that Wolf achieves superior captioning performance compared to state-of-the-art approaches from the research community (VILA1.5, CogAgent) and commercial solutions (Gemini-Pro-1.5, GPT-4V). For instance, in comparison with GPT-4V, Wolf improves CapScore both quality-wise by 55.6% and similarity-wise by 77.4% on challenging driving videos.
Finally, we establish a benchmark for video captioning and introduce a leaderboard, aiming to accelerate advancements in video understanding, captioning, and data alignment.
2.2. Mixture of Nested Experts: Adaptive Processing of Visual Tokens

The visual medium (images and videos) naturally contains a large amount of information redundancy, thereby providing a great opportunity for leveraging efficiency in processing.
While Vision Transformer (ViT) based models scale effectively to large data regimes, they fail to capitalize on this inherent redundancy, leading to higher computational costs. Mixture of Experts (MoE) networks demonstrate scalability while maintaining the same inference-time costs, but they come with a larger parameter footprint.
We present a Mixture of Nested Experts (MoNE), which utilizes a nested structure for experts, wherein individual experts fall on an increasing compute-accuracy curve.
Given a compute budget, MoNE learns to dynamically choose tokens in a priority order, and thus redundant tokens are processed through cheaper nested experts.
Using this framework, we achieve equivalent performance as the baseline models, while reducing inference time compute by over two-fold. We validate our approach on standard image and video datasets — ImageNet-21K, Kinetics400, and Something-Something-v2.
We further highlight MoNE’s adaptability by showcasing its ability to maintain strong performance across different inference-time compute budgets on videos, using only a single trained model.
2.3. 3D Question Answering for City Scene Understanding

3D multimodal question answering (MQA) plays a crucial role in scene understanding by enabling intelligent agents to comprehend their surroundings in 3D environments.
While existing research has primarily focused on indoor household tasks and outdoor roadside autonomous driving tasks, there has been limited exploration of city-level scene understanding tasks. Furthermore, existing research faces challenges in understanding city scenes, due to the absence of spatial semantic information and human-environment interaction information at the city level.
To address these challenges, we investigate 3D MQA from both dataset and method perspectives. From the dataset perspective, we introduce a novel 3D MQA dataset named City-3DQA for city-level scene understanding, which is the first dataset to incorporate scene semantic and human-environment interactive tasks within the city.
From the method perspective, we propose a Scene graph enhanced City-level Understanding method (Sg-CityU), which utilizes the scene graph to introduce the spatial semantics.
A new benchmark is reported and our proposed Sg-CityU achieves accuracy of 63.94 % and 63.76 % in different settings of City-3DQA. Compared to indoor 3D MQA methods and zero-shot using advanced large language models (LLMs), Sg-CityU demonstrates state-of-the-art (SOTA) performance in robustness and generalization.
2.4. Visual Riddles: a Commonsense and World Knowledge Challenge for Large Vision and Language Models

Imagine observing someone scratching their arm; to understand why, additional context would be necessary. However, spotting a mosquito nearby would immediately offer a likely explanation for the person’s discomfort, thereby alleviating the need for further information.
This example illustrates how subtle visual cues can challenge our cognitive skills and demonstrates the complexity of interpreting visual scenarios. To study these skills, we present Visual Riddles, a benchmark aimed to test vision and language models on visual riddles requiring common and world knowledge.
The benchmark comprises 400 visual riddles, each featuring a unique image created by a variety of text-to-image models, questions, ground-truth answers, textual hints, and attribution.
Human evaluation reveals that existing models lag significantly behind human performance, which is at 82\% accuracy, with Gemini-Pro-1.5 leading with 40\% accuracy. Our benchmark comes with automatic evaluation tasks to make assessment scalable.
These findings underscore the potential of Visual Riddles as a valuable resource for enhancing vision and language models’ capabilities in interpreting complex visual scenarios.
3. Video Understanding & Generation
3.1. FreeLong: Training-Free Long Video Generation with SpectralBlend Temporal Attention

Video diffusion models have made substantial progress in various video generation applications. However, training models for long video generation tasks require significant computational and data resources, posing a challenge to developing long video diffusion models.
This paper investigates a straightforward and training-free approach to extend an existing short video diffusion model (e.g. pre-trained on 16-frame videos) for consistent long video generation (e.g. 128 frames). Our preliminary observation has found that directly applying the short video diffusion model to generate long videos can lead to severe video quality degradation.
Further investigation reveals that this degradation is primarily due to the distortion of high-frequency components in long videos, characterized by a decrease in spatial high-frequency components and an increase in temporal high-frequency components. Motivated by this, we propose a novel solution named FreeLong to balance the frequency distribution of long video features during the denoising process.
FreeLong blends the low-frequency components of global video features, which encapsulate the entire video sequence, with the high-frequency components of local video features that focus on shorter subsequences of frames. This approach maintains global consistency while incorporating diverse and high-quality spatiotemporal details from local videos, enhancing both the consistency and fidelity of long video generation.
We evaluated FreeLong on multiple base video diffusion models and observed significant improvements. Additionally, our method supports coherent multi-prompt generation, ensuring both visual coherence and seamless transitions between scenes.
3.2. Reenact Anything: Semantic Video Motion Transfer Using Motion-Textual Inversion

Recent years have seen a tremendous improvement in the quality of video generation and editing approaches. While several techniques focus on editing appearance, few address motion.
Current approaches using text, trajectories, or bounding boxes are limited to simple motions, so we specify motions with a single motion reference video instead. We further propose to use a pre-trained image-to-video model rather than a text-to-video model.
This approach allows us to preserve the exact appearance and position of a target object or scene and helps disentangle appearance from motion. Our method, called motion-textual inversion, leverages our observation that image-to-video models extract appearance mainly from the (latent) image input, while the text/image embedding injected via cross-attention predominantly controls motion.
We thus represent motion using text/image embedding tokens. By operating on an inflated motion-text embedding containing multiple text/image embedding tokens per frame, we achieve a high temporal motion granularity.
Once optimized on the motion reference video, this embedding can be applied to various target images to generate videos with semantically similar motions.
Our approach does not require spatial alignment between the motion reference video and target image, generalizes across various domains, and can be applied to various tasks such as full-body and face reenactment, as well as controlling the motion of inanimate objects and the camera.
We empirically demonstrate the effectiveness of our method in the semantic video motion transfer task, significantly outperforming existing methods in this context.
4. Image Editing & Generation
4.1. Floating No More: Object-Ground Reconstruction from a Single Image

Recent advancements in 3D object reconstruction from single images have primarily focused on improving the accuracy of object shapes. Yet, these techniques often fail to accurately capture the interrelation between the object, ground, and camera.
As a result, the reconstructed objects often appear floating or tilted when placed on flat surfaces. This limitation significantly affects 3D-aware image editing applications like shadow rendering and object pose manipulation.
To address this issue, we introduce ORG (Object Reconstruction with Ground), a novel task aimed at reconstructing 3D object geometry in conjunction with the ground surface. Our method uses two compact pixel-level representations to depict the relationship between the camera, object, and ground.
Experiments show that the proposed ORG model can effectively reconstruct object-ground geometry on unseen data, significantly enhancing the quality of shadow generation and pose manipulation compared to conventional single-image 3D reconstruction techniques.
4.2. TurboEdit: Text-Based Image Editing Using Few-Step Diffusion Models

Diffusion models have opened the path to a wide range of text-based image editing frameworks. However, these typically build on the multi-step nature of the diffusion backward process, and adapting them to distilled, fast-sampling methods has proven surprisingly challenging.
Here, we focus on a popular line of text-based editing frameworks — the ``edit-friendly’’ DDPM-noise inversion approach. We analyze its application to fast sampling methods and categorize its failures into two classes: the appearance of visual artifacts, and insufficient editing strength.
We trace the artifacts to mismatched noise statistics between inverted noises and the expected noise schedule and suggest a shifted noise schedule that corrects this offset.
To increase editing strength, we propose a pseudo-guidance approach that efficiently increases the magnitude of edits without introducing new artifacts.
All in all, our method enables text-based image editing with as few as three diffusion steps, while providing novel insights into the mechanisms behind popular text-based editing approaches.
4.3. Cycle3D: High-quality and Consistent Image-to-3D Generation via Generation-Reconstruction Cycle

Recent 3D large reconstruction models typically employ a two-stage process, including first generating multi-view images by a multi-view diffusion model, and then utilizing a feed-forward model to reconstruct images to 3D content.
However, multi-view diffusion models often produce low-quality and inconsistent images, adversely affecting the quality of the final 3D reconstruction. To address this issue, we propose a unified 3D generation framework called Cycle3D, which cyclically utilizes a 2D diffusion-based generation module and a feed-forward 3D reconstruction module during the multi-step diffusion process.
Concretely, the 2D diffusion model is applied to generate high-quality texture, and the reconstruction model guarantees multi-view consistency. Moreover, the 2D diffusion model can further control the generated content and inject reference-view information for unseen views, thereby enhancing the diversity and texture consistency of 3D generation during the denoising process.
Extensive experiments demonstrate the superior ability of our method to create 3D content with high quality and consistency compared with state-of-the-art baselines.
4.4. ImagiNet: A Multi-Content Dataset for Generalizable Synthetic Image Detection via Contrastive Learning
Generative models, such as diffusion models (DMs), variational autoencoders (VAEs), and generative adversarial networks (GANs), produce images with a level of authenticity that makes them nearly indistinguishable from real photos and artwork. While this capability is beneficial for many industries, the difficulty of identifying synthetic images leaves online media platforms vulnerable to impersonation and misinformation attempts.
To support the development of defensive methods, we introduce ImagiNet, a high-resolution and balanced dataset for synthetic image detection, designed to mitigate potential biases in existing resources. It contains 200K examples, spanning four content categories: photos, paintings, faces, and uncategorized. Synthetic images are produced with open-source and proprietary generators, whereas real counterparts of the same content type are collected from public datasets.
The structure of ImagiNet allows for a two-track evaluation system: i) classification as real or synthetic and ii) identification of the generative model. To establish a baseline, we train a ResNet-50 model using a self-supervised contrastive objective (SelfCon) for each track. The model demonstrates state-of-the-art performance and high inference speed across established benchmarks, achieving an AUC of up to 0.99 and balanced accuracy ranging from 86% to 95%, even under social network conditions that involve compression and resizing.
5. Image Segmentation
5.2. SAM 2: Segment Anything in Images and Videos

We present Segment Anything Model 2 (SAM 2), a foundation model for solving promptable visual segmentation in images and videos. We build a data engine, which improves model and data via user interaction, to collect the largest video segmentation dataset to date.
Our model is a simple transformer architecture with streaming memory for real-time video processing. SAM 2 trained on our data provides strong performance across a wide range of tasks.
In video segmentation, we observe better accuracy, using 3x fewer interactions than prior approaches. In image segmentation, our model is more accurate and 6x faster than the Segment Anything Model (SAM).
We believe that our data, model, and insights will serve as a significant milestone for video segmentation and related perception tasks. We are releasing a version of our model, the dataset, and an interactive demo.
6. Image Recognition & Representation
6.1. SHIC: Shape-Image Correspondences with no Keypoint Supervision
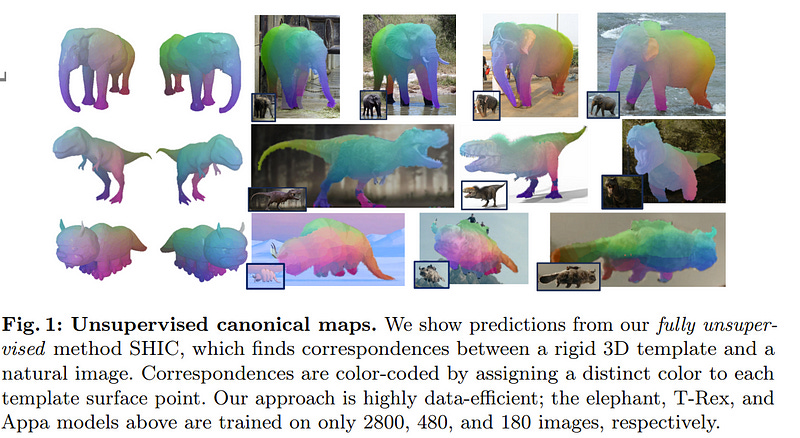
Canonical surface mapping generalizes keypoint detection by assigning each pixel of an object to a corresponding point in a 3D template. Popularised by DensePose for the analysis of humans, authors have since attempted to apply the concept to more categories, but with limited success due to the high cost of manual supervision.
In this work, we introduce SHIC, a method to learn canonical maps without manual supervision which achieves better results than supervised methods for most categories. Our idea is to leverage foundation computer vision models such as DINO and Stable Diffusion that are open-ended and thus possess excellent priors over natural categories.
SHIC reduces the problem of estimating image-to-template correspondences to predicting image-to-image correspondences using features from the foundation models. The reduction works by matching images of the object to non-photorealistic renders of the template, which emulates the process of collecting manual annotations for this task.
These correspondences are then used to supervise high-quality canonical maps for any object of interest. We also show that image generators can further improve the realism of the template views, which provide an additional source of supervision for the model.
6.2. VSSD: Vision Mamba with Non-Casual State Space Duality

Vision transformers have significantly advanced the field of computer vision, offering robust modeling capabilities and a global receptive field. However, their high computational demands limit their applicability in processing long sequences.
To tackle this issue, State Space Models (SSMs) have gained prominence in vision tasks as they offer linear computational complexity. Recently, State Space Duality (SSD), an improved variant of SSMs, was introduced in Mamba2 to enhance model performance and efficiency.
However, the inherent causal nature of SSD/SSMs restricts their applications in non-causal vision tasks. To address this limitation, we introduce the Visual State Space Duality (VSSD) model, which has a non-causal format of SSD.
Specifically, we propose to discard the magnitude of interactions between the hidden state and tokens while preserving their relative weights, which relieves the dependencies of token contribution on previous tokens.
Together with the involvement of multi-scan strategies, we show that the scanning results can be integrated to achieve non-causality, which not only improves the performance of SSD in vision tasks but also enhances its efficiency.
We conduct extensive experiments on various benchmarks including image classification, detection, and segmentation, where VSSD surpasses existing state-of-the-art SSM-based models.
6.3. Improving 2D Feature Representations by 3D-Aware Fine-Tuning

Current visual foundation models are trained purely on unstructured 2D data, limiting their understanding of the 3D structure of objects and scenes. In this work, we show that fine-tuning 3D-aware data improves the quality of emerging semantic features. We design a method to lift semantic 2D features into an efficient 3D Gaussian representation, which allows us to re-render them for arbitrary views.
Using the rendered 3D-aware features, we design a fine-tuning strategy to transfer such 3D awareness into a 2D foundation model. We demonstrate that models fine-tuned in that way produce features that readily improve downstream task performance in semantic segmentation and depth estimation through simple linear probing.
Notably, though fined-tuned on a single indoor dataset, the improvement is transferable to a variety of indoor datasets and out-of-domain datasets. We hope our study encourages the community to consider injecting 3D awareness when training 2D foundation models.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
