


Important LLMs Papers for the Week from 26/08 to 01/09
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the First Week of September 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Training, Evaluation & Inference
Attention & Transformers Based Models
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. LLM Progress & Benchmarking
1.1. SciLitLLM: How to Adapt LLMs for Scientific Literature Understanding

Scientific literature understanding is crucial for extracting targeted information and garnering insights, thereby significantly advancing scientific discovery.
Despite the remarkable success of Large Language Models (LLMs), they face challenges in scientific literature understanding, primarily due to
A lack of scientific knowledge
Unfamiliarity with specialized scientific tasks.
To develop an LLM specialized in scientific literature understanding, we propose a hybrid strategy that integrates continual pre-training (CPT) and supervised fine-tuning (SFT), to simultaneously infuse scientific domain knowledge and enhance instruction-following capabilities for domain-specific tasks. In this process, we identify two key challenges:
Constructing high-quality CPT corpora, and
Generating diverse SFT instructions.
We address these challenges through a meticulous pipeline, including PDF text extraction, parsing content error correction, quality filtering, and synthetic instruction creation.
Applying this strategy, we present a suite of LLMs: SciLitLLM, specialized in scientific literature understanding. These models demonstrate promising performance on scientific literature understanding benchmarks. Our contributions are threefold:
We present an effective framework that integrates CPT and SFT to adapt LLMs to scientific literature understanding, which can also be easily adapted to other domains.
We propose an LLM-based synthesis method to generate diverse and high-quality scientific instructions, resulting in a new instruction set — SciLitIns — for supervised fine-tuning in less-represented scientific domains.
SciLitLLM achieves promising performance improvements on scientific literature understanding benchmarks.
1.2. InkubaLM: A small language model for low-resource African languages

High-resource language models often fall short in the African context, where there is a critical need for models that are efficient, accessible, and locally relevant, even amidst significant computing and data constraints.
This paper introduces InkubaLM, a small language model with 0.4 billion parameters, which achieves performance comparable to models with significantly larger parameter counts and more extensive training data on tasks such as machine translation, question-answering, AfriMMLU, and the AfriXnli task.
Notably, InkubaLM outperforms many larger models in sentiment analysis and demonstrates remarkable consistency across multiple languages. This work represents a pivotal advancement in challenging the conventional paradigm that effective language models must rely on substantial resources.
1.3. Jina-ColBERT-v2: A General-Purpose Multilingual Late Interaction Retriever
Multi-vector dense models, such as ColBERT, have proven highly effective in information retrieval. ColBERT’s late interaction scoring approximates the joint query-document attention seen in cross-encoders while maintaining inference efficiency closer to traditional dense retrieval models, thanks to its bi-encoder architecture and recent optimizations in indexing and search.
In this paper, we introduce several improvements to the ColBERT model architecture and training pipeline, leveraging techniques successful in the more established single-vector embedding model paradigm, particularly those suited for heterogeneous multilingual data.
Our new model, Jina-ColBERT-v2, demonstrates strong performance across a range of English and multilingual retrieval tasks, while also cutting storage requirements by up to 50% compared to previous models.
1.4. Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming
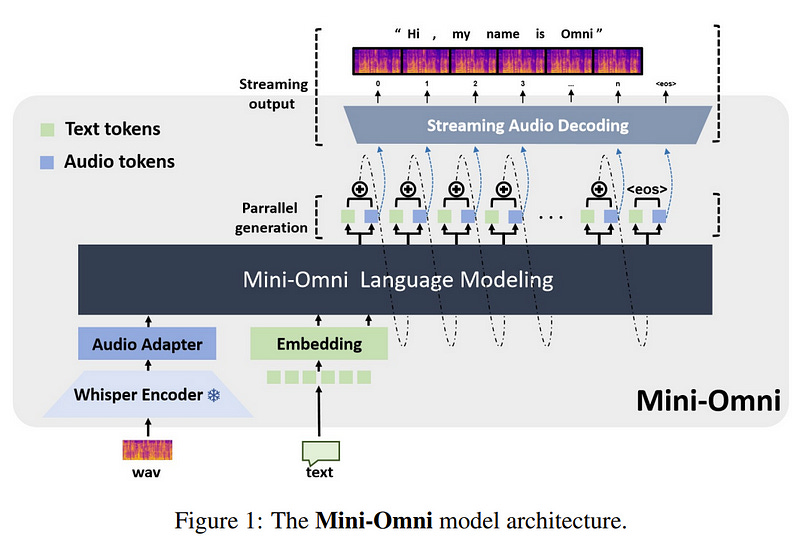
Recent advances in language models have achieved significant progress. GPT-4o, as a new milestone, has enabled real-time conversations with humans, demonstrating near-human natural fluency.
Such human-computer interaction necessitates models with the capability to perform reasoning directly with the audio modality and generate output in streaming.
However, this remains beyond the reach of current academic models, as they typically depend on extra TTS systems for speech synthesis, resulting in undesirable latency. This paper introduces the Mini-Omni, an audio-based end-to-end conversational model, capable of real-time speech interaction.
To achieve this capability, we propose a text-instructed speech generation method, along with batch-parallel strategies during inference to further boost the performance. Our method also helps to retain the original model’s language capabilities with minimal degradation, enabling other works to establish real-time interaction capabilities.
We call this training method “Any Model Can Talk”. We also introduce the VoiceAssistant-400K dataset to fine-tune models optimized for speech output. To our knowledge, Mini-Omni is the first fully end-to-end, open-source model for real-time speech interaction, offering valuable potential for future research.
1.5. OLMoE: Open Mixture-of-Experts Language Models

We introduce OLMoE, a fully open, state-of-the-art language model leveraging a sparse mixture of experts (MoE). OLMoE-1B-7B has 7 billion (B) parameters but uses only 1B per input token.
We pre-train it on 5 trillion tokens and further adapt it to create OLMoE-1B-7B-Instruct. Our models outperform all available models with similar active parameters, even surpassing larger ones like Llama2–13B-Chat and DeepSeekMoE-16B.
We present various experiments on MoE training, analyze routing in our model showing high specialization, and open-source all aspects of our work: model weights, training data, code, and logs.
1.6. LongRecipe: Recipe for Efficient Long Context Generalization in Large Language Models
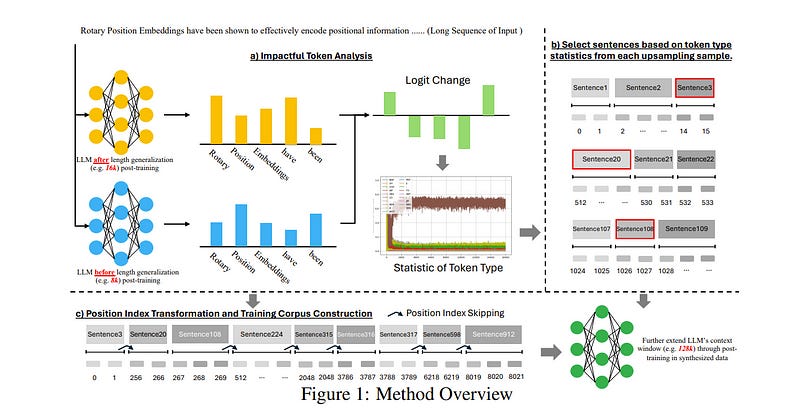
Large language models (LLMs) face significant challenges in handling long-context tasks because of their limited effective context window size during pretraining, which restricts their ability to generalize over extended sequences.
Meanwhile, extending the context window in LLMs through post-pretraining is highly resource-intensive. To address this, we introduce LongRecipe, an efficient training strategy for extending the context window of LLMs, including impactful token analysis, position index transformation, and training optimization strategies.
It simulates long-sequence inputs while maintaining training efficiency and significantly improves the model’s understanding of long-range dependencies.
Experiments on three types of LLMs show that LongRecipe can utilize long sequences while requiring only 30% of the target context window size, and reduces computational training resources by over 85% compared to full sequence training.
Furthermore, LongRecipe also preserves the original LLM’s capabilities in general tasks. Ultimately, *we can extend the effective context window of open-source LLMs from 8k to 128k, achieving performance close to GPT-4 with just one day of dedicated training using a single GPU with 80G memory.
1.7. WildVis: Open Source Visualizer for Million-Scale Chat Logs in the Wild
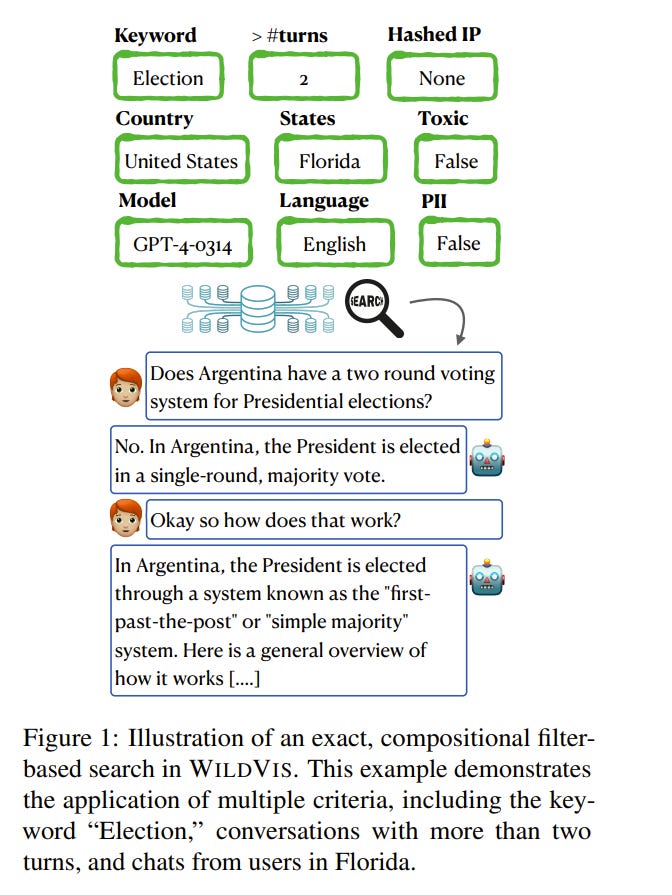
The increasing availability of real-world conversation data offers exciting opportunities for researchers to study user chatbot interactions. However, the sheer volume of this data makes manually examining individual conversations impractical.
To overcome this challenge, we introduce WildVis, an interactive tool that enables fast, versatile, and large-scale conversation analysis. WildVis provides search and visualization capabilities in the text and embedding spaces based on a list of criteria.
To manage million-scale datasets, we implemented optimizations including search index construction, embedding precomputation and compression, and caching to ensure responsive user interactions within seconds.
We demonstrate WildVis’s utility through three case studies: facilitating chatbot misuse research, visualizing and comparing topic distributions across datasets, and characterizing user-specific conversation patterns. WildVis is open-source and designed to be extendable, supporting additional datasets and customized search and visualization functionalities.
1.8. LongCite: Enabling LLMs to Generate Fine-grained Citations in Long-context QA

Though current long-context large language models (LLMs) have demonstrated impressive capacities in answering user questions based on extensive text, the lack of citations in their responses makes user verification difficult, leading to concerns about their trustworthiness due to their potential hallucinations.
In this work, we aim to enable long-context LLMs to generate responses with fine-grained sentence-level citations, improving their faithfulness and verifiability. We first introduce LongBench-Cite, an automated benchmark for assessing current LLMs' performance in Long-Context Question Answering with Citations (LQAC), revealing considerable room for improvement.
To this end, we propose CoF (Coarse to Fine), a novel pipeline that utilizes off-the-shelf LLMs to automatically generate long-context QA instances with precise sentence-level citations, and leverage this pipeline to construct LongCite-45k, a large-scale SFT dataset for LQAC.
Finally, we train LongCite-8B and LongCite-9B using the LongCite-45k dataset, successfully enabling their generation of accurate responses and fine-grained sentence-level citations in a single output.
The evaluation results on LongBench-Cite show that our trained models achieve state-of-the-art citation quality, surpassing advanced proprietary models including GPT-4o.
1.9. FuzzCoder: Byte-level Fuzzing Test via Large Language Model

Fuzzing is an important dynamic program analysis technique designed for finding vulnerabilities in complex software. Fuzzing involves presenting a target program with crafted malicious input to cause crashes, buffer overflows, memory errors, and exceptions.
Crafting malicious inputs in an efficient manner is a difficult open problem and the best approaches often apply uniform random mutations to pre-existing valid inputs. In this work, we propose to adopt fine-tuned large language models (FuzzCoder) to learn patterns in the input files from successful attacks to guide future fuzzing explorations.
Specifically, we develop a framework to leverage the code LLMs to guide the mutation process of inputs in fuzzing. The mutation process is formulated as the sequence-to-sequence modeling, where LLM receives a sequence of bytes and then outputs the mutated byte sequence.
FuzzCoder is fine-tuned on the created instruction dataset (Fuzz-Instruct), where the successful fuzzing history is collected from the heuristic fuzzing tool. FuzzCoder can predict mutation locations and strategy locations in input files to trigger abnormal behaviors of the program.
Experimental results show that FuzzCoder based on AFL (American Fuzzy Lop) gained significant improvements in terms of effective proportion of mutation (EPM) and number of crashes (NC) for various input formats including ELF, JPG, MP3, and XML.
2. LLM Training, Evaluation & Inference
2.1. MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark

This paper introduces MMMU-Pro, a robust version of the Massive Multi-discipline Multimodal Understanding and Reasoning (MMMU) benchmark. MMMU-Pro rigorously assesses multimodal models’ true understanding and reasoning capabilities through a three-step process based on MMMU:
Filtering out questions answerable by text-only models,
Augmenting candidate options
Introducing a vision-only input setting where questions are embedded within images.
This setting challenges AI to truly “see” and “read” simultaneously, testing a fundamental human cognitive skill of seamlessly integrating visual and textual information. Results show that model performance is substantially lower on MMMU-Pro than on MMMU, ranging from 16.8% to 26.9% across models.
We explore the impact of OCR prompts and Chain of Thought (CoT) reasoning, finding that OCR prompts have minimal effect while CoT generally improves performance. MMMU-Pro provides a more rigorous evaluation tool, closely mimicking real-world scenarios and offering valuable directions for future research in multimodal AI.
2.2. Arctic-SnowCoder: Demystifying High-Quality Data in Code Pretraining
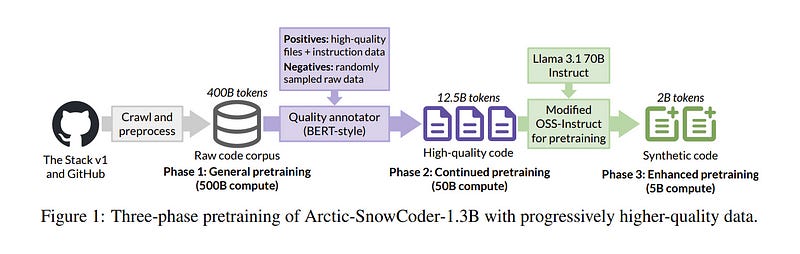
Recent studies have been increasingly demonstrating that high-quality data is crucial for effective pretraining of language models. However, the precise definition of “high-quality” remains underexplored.
Focusing on the code domain, we introduce Arctic-SnowCoder-1.3B, a data-efficient base code model pretrained on 555B tokens through three phases of progressively refined data:
General pretraining with 500B standard-quality code tokens, preprocessed through basic filtering, deduplication, and decontamination
Continued pretraining with 50B high-quality tokens, selected from phase one by a BERT-style quality annotator trained to distinguish good code from random data, using positive examples drawn from high-quality code files, along with instruction data from Magicoder and StarCoder2-Instruct
Enhanced pretraining with 5B synthetic data created by Llama-3.1–70B using phase two data as seeds, adapting the Magicoder approach for pertaining.
Despite being trained on a limited dataset, Arctic-SnowCoder achieves state-of-the-art performance on BigCodeBench, a coding benchmark focusing on practical and challenging programming tasks, compared to similarly sized models trained on no more than 1T tokens, outperforming Phi-1.5–1.3B by 36%. Across all evaluated benchmarks, Arctic-SnowCoder-1.3B beats StarCoderBase-3B pretrained on 1T tokens.
Additionally, it matches the performance of leading small base code models trained on trillions of tokens. For example, Arctic-SnowCoder-1.3B surpasses StarCoder2–3B, pretrained on over 3.3T tokens, on HumanEval+, a benchmark that evaluates function-level code generation and remains competitive on BigCodeBench.
Our evaluation presents a comprehensive analysis justifying various design choices for Arctic-SnowCoder. Most importantly, we find that the key to high-quality data is its alignment with the distribution of downstream applications.
3. Transformers & Attention Based Models
3.1. Attention Heads of Large Language Models: A Survey

Since the advent of ChatGPT, Large Language Models (LLMs) have excelled in various tasks but remain largely as black-box systems. Consequently, their development relies heavily on data-driven approaches, limiting performance enhancement through changes in internal architecture and reasoning pathways.
As a result, many researchers have begun exploring the potential internal mechanisms of LLMs, aiming to identify the essence of their reasoning bottlenecks, with most studies focusing on attention heads. Our survey aims to shed light on the internal reasoning processes of LLMs by concentrating on the interpretability and underlying mechanisms of attention heads.
We first distill the human thought process into a four-stage framework: Knowledge Recalling, In-Context Identification, Latent Reasoning, and Expression Preparation. Using this framework, we systematically review existing research to identify and categorize the functions of specific attention heads.
Furthermore, we summarize the experimental methodologies used to discover these special heads, dividing them into two categories: Modeling-Free methods and Modeling-Required methods. Also, we outline relevant evaluation methods and benchmarks. Finally, we discuss the limitations of current research and propose several potential future directions.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
