


Important LLMs Papers for the Week from 09/09 to 15/09
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Second Week of September 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Training, Evaluation & Inference
LLM Reasoning
Retrieval Augmented Generation (RAG)
My New E-Book: Prompt Engineering Best Practices for Instruction-Tuned LLM

I am happy to announce that I have published a new ebook Prompt Engineering Best Practices for Instruction-Tuned LLM. Prompt Engineering Best Practices for Instruction-Tuned LLM is a comprehensive guide designed to equip readers with the essential knowledge and tools to master the fine-tuning and prompt engineering of large language models (LLMs). The book covers everything from foundational concepts to advanced applications, making it an invaluable resource for anyone interested in leveraging the full potential of instruction-tuned models.
1. LLM Progress & Benchmarking
1.1. How Do Your Code LLMs Perform? Empowering Code Instruction Tuning with High-Quality Data

Recently, there has been a growing interest in studying how to construct better code instruction tuning data. However, we observe Code models trained with these datasets exhibit high performance on HumanEval but perform worse on other benchmarks such as LiveCodeBench.
Upon further investigation, we find that many datasets suffer from severe data leakage. After cleaning up most of the leaked data, some well-known high-quality datasets perform poorly. This discovery reveals a new challenge: identifying which dataset genuinely qualifies as high-quality code instruction data.
To address this, we propose an efficient code data pruning strategy for selecting good samples. Our approach is based on three dimensions: instruction complexity, response quality, and instruction diversity. Based on our selected data, we present XCoder, a family of models finetuned from LLaMA3.
Our experiments show that XCoder achieves new state-of-the-art performance using fewer training data, which verifies the effectiveness of our data strategy.
Moreover, we perform a comprehensive analysis of the data composition and find existing code datasets that have different characteristics according to their construction methods, which provide new insights for future code LLMs.
1.2. Configurable Foundation Models: Building LLMs from a Modular Perspective

Advancements in LLMs have recently unveiled challenges tied to computational efficiency and continual scalability due to their requirements of huge parameters, making the applications and evolution of these models on devices with limited computation resources and scenarios requiring various abilities increasingly cumbersome.
Inspired by modularity within the human brain, there is a growing tendency to decompose LLMs into numerous functional modules, allowing for inference with part of modules and dynamic assembly of modules to tackle complex tasks, such as mixture-of-experts.
To highlight the inherent efficiency and composability of the modular approach, we coin the term brick to represent each functional module, designating the modularized structure as configurable foundation models.
In this paper, we offer a comprehensive overview and investigation of the construction, utilization, and limitation of configurable foundation models. We first formalize modules into emergent bricks — functional neuron partitions that emerge during the pre-training phase, and customized bricks — bricks constructed via additional post-training to improve the capabilities and knowledge of LLMs.
Based on diverse functional bricks, we further present four brick-oriented operations: retrieval and routing, merging, updating, and growing. These operations allow for dynamic configuration of LLMs based on instructions to handle complex tasks. To verify our perspective, we conduct an empirical analysis of widely-used LLMs.
We find that the FFN layers follow modular patterns with functional specialization of neurons and functional neuron partitions. Finally, we highlight several open issues and directions for future research. Overall, this paper aims to offer a fresh modular perspective on existing LLM research and inspire the future creation of more efficient and scalable foundational models.
1.3. Can LLMs Generate Novel Research Ideas? A Large-Scale Human Study with 100+ NLP Researchers

Recent advancements in large language models (LLMs) have sparked optimism about their potential to accelerate scientific discovery, with a growing number of works proposing research agents that autonomously generate and validate new ideas.
Despite this, no evaluations have shown that LLM systems can take the very first step of producing novel, expert-level ideas, let alone perform the entire research process. We address this by establishing an experimental design that evaluates research idea generation while controlling for confounders and performing the first head-to-head comparison between expert NLP researchers and an LLM ideation agent.
By recruiting over 100 NLP researchers to write novel ideas and blind reviews of both LLM and human ideas, we obtain the first statistically significant conclusion on current LLM capabilities for research ideation: we find LLM-generated ideas are judged as more novel (p < 0.05) than human expert ideas while being judged slightly weaker on feasibility.
Studying our agent baselines closely, we identify open problems in building and evaluating research agents, including failures of LLM self-evaluation and their lack of diversity in a generation.
Finally, we acknowledge that human judgments of novelty can be difficult, even by experts, and propose an end-to-end study design that recruits researchers to execute these ideas into full projects, enabling us to study whether these novelty and feasibility judgments result in meaningful differences in research outcomes.
1.4. LLaMA-Omni: Seamless Speech Interaction with Large Language Models

Models like GPT-4o enable real-time interaction with large language models (LLMs) through speech, significantly enhancing user experience compared to traditional text-based interaction. However, there is still a lack of exploration on how to build speech interaction models based on open-source LLMs.
To address this, we propose LLaMA-Omni, a novel model architecture designed for low-latency and high-quality speech interaction with LLMs. LLaMA-Omni integrates a pretrained speech encoder, a speech adaptor, an LLM, and a streaming speech decoder.
It eliminates the need for speech transcription, and can simultaneously generate text and speech responses directly from speech instructions with extremely low latency. We build our model based on the latest Llama-3.1–8B-Instruct model.
To align the model with speech interaction scenarios, we construct a dataset named InstructS2S-200K, which includes 200K speech instructions and corresponding speech responses.
Experimental results show that compared to previous speech-language models, LLaMA-Omni provides better responses in both content and style, with a response latency as low as 226ms. Additionally, training LLaMA-Omni takes less than 3 days on just 4 GPUs, paving the way for the efficient development of speech-language models in the future.
1.5. Can Large Language Models Unlock Novel Scientific Research Ideas?

“An idea is nothing more nor less than a new combination of old elements” (Young, J.W.). The widespread adoption of Large Language Models (LLMs) and publicly available ChatGPT has marked a significant turning point in the integration of Artificial Intelligence (AI) into people’s everyday lives.
This study explores the capability of LLMs to generate novel research ideas based on information from research papers. We conduct a thorough examination of 4 LLMs in five domains (e.g., Chemistry, Computer, Economics, Medical, and Physics).
We found that the future research ideas generated by Claude-2 and GPT-4 are more aligned with the author’s perspective than GPT-3.5 and Gemini.
We also found that Claude-2 generates more diverse future research ideas than GPT-4, GPT-3.5, and Gemini 1.0. We further performed a human evaluation of the novelty, relevancy, and feasibility of the generated future research ideas.
This investigation offers insights into the evolving role of LLMs in idea generation, highlighting both its capability and limitations. Our work contributes to the ongoing efforts in evaluating and utilizing language models for generating future research ideas. We make our datasets and codes publicly available.
1.6. DSBench: How Far Are Data Science Agents to Becoming Data Science Experts?

Large Language Models (LLMs) and Large Vision-Language Models (LVLMs) have demonstrated impressive language/vision reasoning abilities, igniting the recent trend of building agents for targeted applications such as shopping assistants or AI software engineers.
Recently, many data science benchmarks have been proposed to investigate their performance in the data science domain. However, existing data science benchmarks still fall short when compared to real-world data science applications due to their simplified settings.
To bridge this gap, we introduce DSBench, a comprehensive benchmark designed to evaluate data science agents with realistic tasks. This benchmark includes 466 data analysis tasks and 74 data modeling tasks, sourced from Eloquence and Kaggle competitions.
DSBench offers a realistic setting by encompassing long contexts, multimodal task backgrounds, reasoning with large data files and multi-table structures, and performing end-to-end data modeling tasks.
Our evaluation of state-of-the-art LLMs, LVLMs, and agents shows that they struggle with most tasks, with the best agent solving only 34.12% of data analysis tasks and achieving a 34.74% Relative Performance Gap (RPG). These findings underscore the need for further advancements in developing more practical, intelligent, and autonomous data science agents.
2. LLM Training, Evaluation & Inference
2.1. Paper Copilot: A Self-Evolving and Efficient LLM System for Personalized Academic Assistance

As scientific research proliferates, researchers face the daunting task of navigating and reading vast amounts of literature. Existing solutions, such as document QA, fail to provide personalized and up-to-date information efficiently.
We present Paper Copilot, a self-evolving, efficient LLM system designed to assist researchers, based on thought retrieval, user profile, and high-performance optimization.
Specifically, Paper Copilot can offer personalized research services, maintaining a real-time updated database. The quantitative evaluation demonstrates that Paper Copilot saves 69.92\% of time after efficient deployment.
This paper details the design and implementation of Paper Copilot, highlighting its contributions to personalized academic support and its potential to streamline the research process.
2.2. GroUSE: A Benchmark to Evaluate Evaluators in Grounded Question Answering

RAG has emerged as a common paradigm for using Large Language Models (LLMs) alongside private and up-to-date knowledge bases. In this work, we address the challenges of using LLM-as-a-Judge when evaluating grounded answers generated by RAG systems.
To assess the calibration and discrimination capabilities of judge models, we identify 7 generator failure modes and introduce GroUSE (Grounded QA Unitary Scoring of Evaluators), a meta-evaluation benchmark of 144 unit tests. This benchmark reveals that existing automated RAG evaluation frameworks often overlook important failure modes, even when using GPT-4 as a judge.
To improve on the current design of automated RAG evaluation frameworks, we propose a novel pipeline and find that while closed models perform well on GroUSE, state-of-the-art open-source judges do not generalize to our proposed criteria, despite strong correlation with GPT-4’s judgment.
Our findings suggest that correlation with GPT-4 is an incomplete proxy for the practical performance of judge models and should be supplemented with evaluations on unit tests for precise failure mode detection.
We further show that finetuning Llama-3 on GPT-4’s reasoning traces significantly boosts its evaluation capabilities, improving upon both correlation with GPT-4’s evaluations and calibration on reference situations.
2.3. MMEvol: Empowering Multimodal Large Language Models with Evol-Instruct

The development of Multimodal Large Language Models (MLLMs) has seen significant advancements. However, the quantity and quality of multimodal instruction data have emerged as significant bottlenecks in their progress.
Manually creating multimodal instruction data is both time-consuming and inefficient, posing challenges in producing instructions of high complexity. Moreover, distilling instruction data from black-box commercial models (e.g., GPT-4o, GPT-4V) often results in simplistic instruction data, which constrains performance to that of these models.
The challenge of curating diverse and complex instruction data remains substantial. We propose MMEvol, a novel multimodal instruction data evolution framework that combines fine-grained perception evolution, cognitive reasoning evolution, and interaction evolution.
This iterative approach breaks through data quality bottlenecks to generate a complex and diverse image-text instruction dataset, thereby empowering MLLMs with enhanced capabilities.
Beginning with an initial set of instructions, SEED-163K, we utilize MMEvol to systematically broaden the diversity of instruction types, integrate reasoning steps to enhance cognitive capabilities and extract detailed information from images to improve visual understanding and robustness.
To comprehensively evaluate the effectiveness of our data, we train LLaVA-NeXT using the evolved data and conduct experiments across 13 vision-language tasks. Compared to the baseline trained with seed data, our approach achieves an average accuracy improvement of 3.1 points and reaches state-of-the-art (SOTA) performance on 9 of these tasks.
2.4. Towards a Unified View of Preference Learning for Large Language Models: A Survey

Large Language Models (LLMs) exhibit remarkably powerful capabilities. One of the crucial factors to achieve success is aligning the LLM’s output with human preferences. This alignment process often requires only a small amount of data to efficiently enhance the LLM’s performance.
While effective, research in this area spans multiple domains, and the methods involved are relatively complex to understand. The relationships between different methods have been under-explored, limiting the development of the preference alignment.
In light of this, we break down the existing popular alignment strategies into different components and provide a unified framework to study the current alignment strategies, thereby establishing connections among them. In this survey, we decompose all the strategies in preference learning into four components: model, data, feedback, and algorithm.
This unified view offers an in-depth understanding of existing alignment algorithms and also opens up possibilities to synergize the strengths of different strategies. Furthermore, we present detailed working examples of prevalent existing algorithms to facilitate a comprehensive understanding for the readers.
Finally, based on our unified perspective, we explore the challenges and future research directions for aligning large language models with human preferences.
3. LLM Reasoning
3.1. Self-Harmonized Chain of Thought

Chain-of-thought (CoT) prompting reveals that large language models are capable of performing complex reasoning via intermediate steps. CoT prompting is primarily categorized into three approaches.
The first approach utilizes straightforward prompts like ``Let’s think step by step’’ to generate a sequential thought process before yielding an answer. The second approach makes use of human-crafted, step-by-step demonstrations to guide the model’s reasoning process.
The third automates the generation of reasoned demonstrations with the ‘Let’s think step by step’.This approach sometimes leads to reasoning errors, highlighting the need to diversify demonstrations to mitigate its misleading effects. However, diverse demonstrations pose challenges for effective representations.
In this work, we propose ECHO, a self-harmonized chain-of-thought prompting method. It consolidates diverse solution paths into a uniform and effective solution pattern.ECHO demonstrates the best overall performance across three reasoning domains.
4. Retrieval Augmented Generation (RAG)
4.1. OneGen: Efficient One-Pass Unified Generation and Retrieval for LLMs
Despite the recent advancements in Large Language Models (LLMs), which have significantly enhanced the generative capabilities for various NLP tasks, LLMs still face limitations in directly handling retrieval tasks. However, many practical applications demand the seamless integration of both retrieval and generation.
This paper introduces a novel and efficient One-pass Generation and retrieval framework (OneGen), designed to improve LLMs’ performance on tasks that require both generation and retrieval.
The proposed framework bridges the traditionally separate training approaches for generation and retrieval by incorporating retrieval tokens generated autoregressively. This enables a single LLM to handle both tasks simultaneously in a unified forward pass.
We conduct experiments on two distinct types of composite tasks, RAG and Entity Linking, to validate the pluggability, effectiveness, and efficiency of OneGen in training and inference.
Furthermore, our results show that integrating generation and retrieval within the same context preserves the generative capabilities of LLMs while improving retrieval performance. To the best of our knowledge, OneGen is the first to enable LLMs to conduct vector retrieval during the generation.
4.2. MemoRAG: Moving Towards Next-Gen RAG Via Memory-Inspired Knowledge Discovery
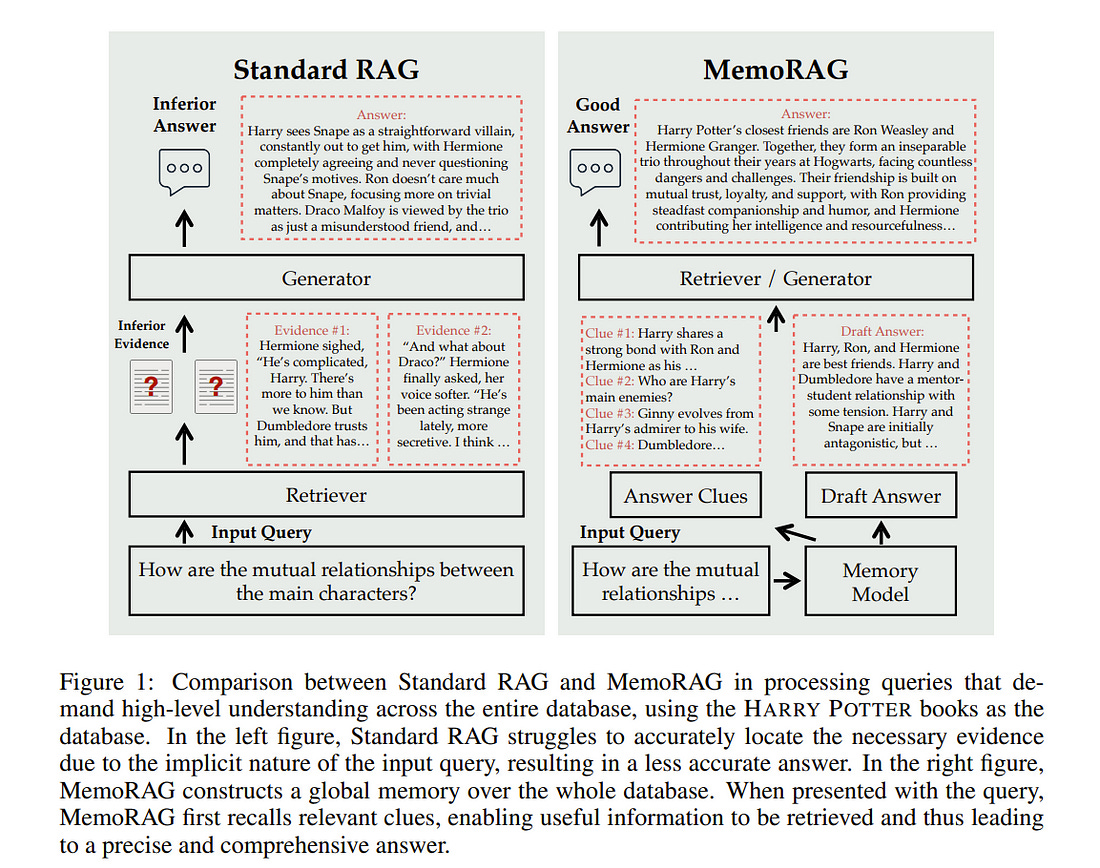
Retrieval-augmented generation (RAG) leverages retrieval tools to access external databases, thereby enhancing the generation quality of large language models (LLMs) through optimized context.
However, the existing retrieval methods are constrained inherently, as they can only perform relevance matching between explicitly stated queries and well-formed knowledge, but are unable to handle tasks involving ambiguous information needs or unstructured knowledge.
Consequently, existing RAG systems are primarily effective for straightforward question-answering tasks. In this work, we propose MemoRAG, a novel retrieval-augmented generation paradigm empowered by long-term memory.
MemoRAG adopts a dual-system architecture. On the one hand, it employs a light but long-range LLM to form the global memory of the database. Once a task is presented, it generates draft answers, citing the retrieval tools to locate useful information within the database. On the other hand, it leverages an expensive but expressive LLM, which generates the ultimate answer based on the retrieved information.
Building on this general framework, we further optimize MemoRAG’s performance by enhancing its cluing mechanism and memorization capacity. In our experiment, MemoRAG achieves superior performance across a variety of evaluation tasks, including both complex ones where conventional RAG fails and straightforward ones where RAG is commonly applied.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
