


Important LLMs Papers for the Week from 30/09 to 06/10
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the First Week of October 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Fine-Tuning & Training
LLM Training, Evaluation & Inference
LLM Quantization & Optimization
LLM Reasoning
LLM Fairness & Ethics
Attention Based Models
My New E-Book: Prompt Engineering Best Practices for Instruction-Tuned LLM

I am happy to announce that I have published a new ebook Prompt Engineering Best Practices for Instruction-Tuned LLM. Prompt Engineering Best Practices for Instruction-Tuned LLM is a comprehensive guide designed to equip readers with the essential knowledge and tools to master the fine-tuning and prompt engineering of large language models (LLMs). The book covers everything from foundational concepts to advanced applications, making it an invaluable resource for anyone interested in leveraging the full potential of instruction-tuned models.
1. LLM Progress & Benchmarking
1.1. Emu3: Next-Token Prediction is All You Need

While next-token prediction is considered a promising path toward artificial general intelligence, it has struggled to excel in multimodal tasks, which are still dominated by diffusion models (e.g., Stable Diffusion) and compositional approaches (e.g., CLIP combined with LLMs).
In this paper, we introduce Emu3, a new suite of state-of-the-art multimodal models trained solely with next-token prediction. By tokenizing images, text, and videos into a discrete space, we train a single transformer from scratch on a mixture of multimodal sequences.
Emu3 outperforms several well-established task-specific models in both generation and perception tasks, surpassing flagship models such as SDXL and LLaVA-1.6, while eliminating the need for diffusion or compositional architectures.
Emu3 is also capable of generating high-fidelity video by predicting the next token in a video sequence. We simplify complex multimodal model designs by converging on a singular focus: tokens, unlocking the great potential for scaling both during training and inference.
Our results demonstrate that next-token prediction is a promising path toward building general multimodal intelligence beyond language. We open-source key techniques and models to support further research in this direction.
1.2. MIO: A Foundation Model on Multimodal Tokens
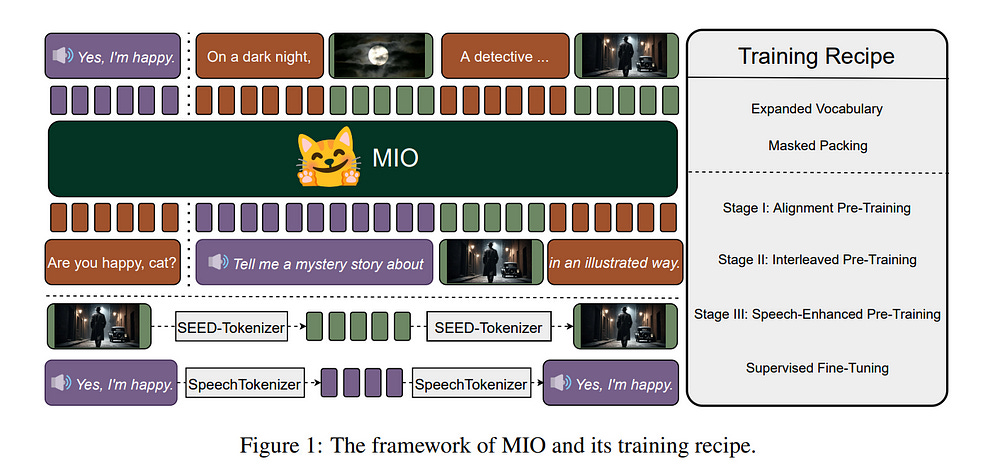
In this paper, we introduce MIO, a novel foundation model built on multimodal tokens, capable of understanding and generating speech, text, images, and videos in an end-to-end, autoregressive manner.
While the emergence of large language models (LLMs) and multimodal large language models (MM-LLMs) propels advancements in artificial general intelligence through their versatile capabilities, they still lack true any-to-any understanding and generation.
Recently, the release of GPT-4o has showcased the remarkable potential of any-to-any LLMs for complex real-world tasks, enabling omnidirectional input and output across images, speech, and text.
However, it is closed-source and does not support the generation of multimodal interleaved sequences. To address this gap, we present MIO, which is trained on a mixture of discrete tokens across four modalities using causal multimodal modeling.
MIO undergoes a four-stage training process: (1) alignment pre-training, (2) interleaved pre-training, (3) speech-enhanced pre-training, and (4) comprehensive supervised fine-tuning on diverse textual, visual, and speech tasks.
Our experimental results indicate that MIO exhibits competitive, and in some cases superior, performance compared to previous dual-modal baselines, any-to-any model baselines, and even modality-specific baselines.
Moreover, MIO demonstrates advanced capabilities inherent to its any-to-any feature, such as interleaved video-text generation, chain-of-visual-thought reasoning, visual guideline generation, instructional image editing, etc.
1.3. MinerU: An Open-Source Solution for Precise Document Content Extraction

Document content analysis has been a crucial research area in computer vision. Despite significant advancements in methods such as OCR, layout detection, and formula recognition, existing open-source solutions struggle to consistently deliver high-quality content extraction due to the diversity in document types and content.
To address these challenges, we present MinerU, an open-source solution for high-precision document content extraction. MinerU leverages the sophisticated PDF-Extract-Kit models to extract content from diverse documents effectively and employs finely tuned preprocessing and postprocessing rules to ensure the accuracy of the final results.
Experimental results demonstrate that MinerU consistently achieves high performance across various document types, significantly enhancing the quality and consistency of content extraction.
1.4. Ruler: A Model-Agnostic Method to Control Generated Length for Large Language Models

The instruction-following ability of large language models enables humans to interact with AI agents in a natural way. However, when required to generate responses of a specific length, large language models often struggle to meet users’ needs due to their inherent difficulty in accurately perceiving numerical constraints.
To explore the ability of large language models to control the length of generated responses, we propose the Target Length Generation Task (TLG) and design two metrics, Precise Match (PM) and Flexible Match (FM) to evaluate the model’s performance in adhering to specified response lengths.
Furthermore, we introduce a novel, model-agnostic approach called Ruler, which employs Meta Length Tokens (MLTs) to enhance the instruction-following ability of large language models under length-constrained instructions.
Specifically, Ruler equips LLMs with the ability to generate responses of a specified length based on length constraints within the instructions. Moreover, Ruler can automatically generate appropriate MLT when length constraints are not explicitly provided, demonstrating excellent versatility and generalization.
Comprehensive experiments show the effectiveness of Ruler across different LLMs on Target Length Generation Task, e.g., at All Level 27.97 average gain on PM, 29.57 average gain on FM. In addition, we conduct extensive ablation experiments to further substantiate the efficacy and generalization of Ruler.
1.5. Law of the Weakest Link: Cross Capabilities of Large Language Models
The development and evaluation of Large Language Models (LLMs) have largely focused on individual capabilities. However, this overlooks the intersection of multiple abilities across different types of expertise that are often required for real-world tasks, which we term cross capabilities.
To systematically explore this concept, we first define seven core individual capabilities and then pair them to form seven common cross-capabilities, each supported by a manually constructed taxonomy. Building on these definitions, we introduce CrossEval, a benchmark comprising 1,400 human-annotated prompts, with 100 prompts for each individual and cross capability.
To ensure reliable evaluation, we involve expert annotators to assess 4,200 model responses, gathering 8,400 human ratings with detailed explanations to serve as reference examples.
Our findings reveal that, in both static evaluations and attempts to enhance specific abilities, current LLMs consistently exhibit the “Law of the Weakest Link,” where cross-capability performance is significantly constrained by the weakest component.
Specifically, across 58 cross-capability scores from 17 models, 38 scores are lower than all individual capabilities, while 20 falls between strong and weak, but closer to the weaker ability.
These results highlight the under-performance of LLMs in cross-capability tasks, making the identification and improvement of the weakest capabilities a critical priority for future research to optimize performance in complex, multi-dimensional scenarios.
1.6. MOSEL: 950,000 Hours of Speech Data for Open-Source Speech Foundation Model Training on EU Languages
The rise of foundation models (FMs), coupled with regulatory efforts addressing their risks and impacts, has sparked significant interest in open-source models.
However, existing speech FMs (SFMs) fall short of full compliance with the open-source principles, even if claimed otherwise, as no existing SFM has model weights, code, and training data publicly available under open-source terms.
In this work, we take the first step toward filling this gap by focusing on the 24 official languages of the European Union (EU). We collect suitable training data by surveying automatic speech recognition datasets and unlabeled speech corpora under open-source compliant licenses, for a total of 950k hours.
Additionally, we release automatic transcripts for 441k hours of unlabeled data under the permissive CC-BY license, thereby facilitating the creation of open-source SFMs for the EU languages.
1.7. From Code to Correctness: Closing the Last Mile of Code Generation with Hierarchical Debugging
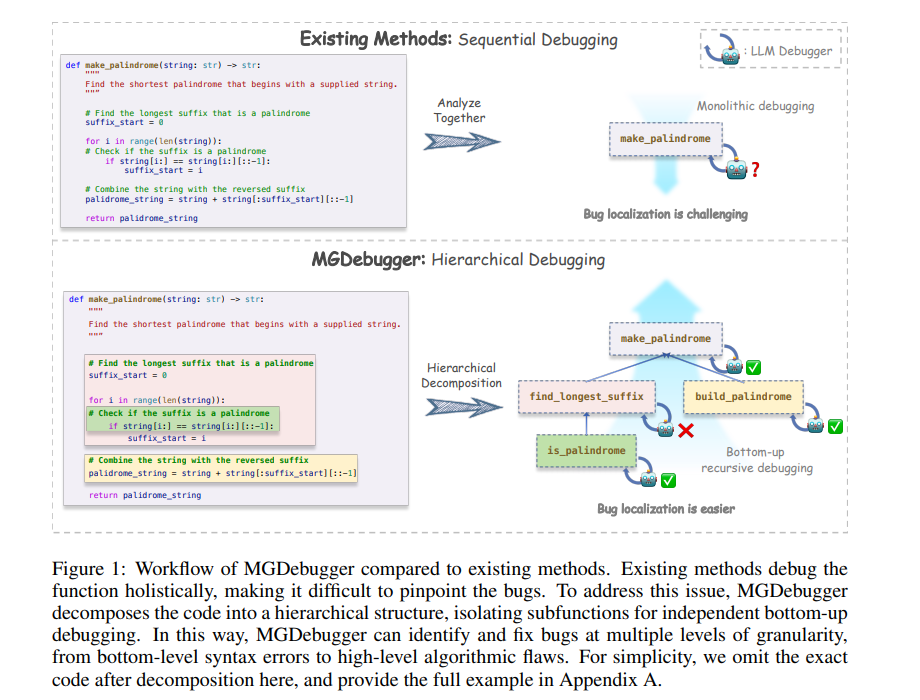
While large language models have made significant strides in code generation, the pass rate of the generated code is bottlenecked on subtle errors, often requiring human intervention to pass tests, especially for complex problems.
Existing LLM-based debugging systems treat generated programs as monolithic units, failing to address bugs at multiple levels of granularity, from low-level syntax errors to high-level algorithmic flaws. In this paper, we introduce a Multi-Granularity Debugger (MGDebugger), a hierarchical code debugger that isolates, identifies, and resolves bugs at various levels of granularity.
MGDebugger decomposes problematic code into a hierarchical tree structure of subfunctions, with each level representing a particular granularity of error. During debugging, it analyzes each subfunction and iteratively resolves bugs in a bottom-up manner. To effectively test each subfunction, we propose an LLM-simulated Python executor, which traces code execution and tracks important variable states to pinpoint errors accurately.
Extensive experiments demonstrate that MGDebugger outperforms existing debugging systems, achieving an 18.9% improvement in accuracy over seed generations in HumanEval and a 97.6% repair success rate in HumanEvalFix. Furthermore, MGDebugger effectively fixes bugs across different categories and difficulty levels, demonstrating its robustness and effectiveness.
2. LLM Fine-Tuning & Training
2.1. MM1.5: Methods, Analysis & Insights from Multimodal LLM Fine-tuning
We present MM1.5, a new family of multimodal large language models (MLLMs) designed to enhance capabilities in text-rich image understanding, visual referring and grounding, and multi-image reasoning.
Building upon the MM1 architecture, MM1.5 adopts a data-centric approach to model training, systematically exploring the impact of diverse data mixtures across the entire model training lifecycle. This includes high-quality OCR data and synthetic captions for continual pre-training, as well as an optimized visual instruction-tuning data mixture for supervised fine-tuning.
Our models range from 1B to 30B parameters, encompassing both dense and mixture-of-experts (MoE) variants, and demonstrate that careful data curation and training strategies can yield strong performance even at small scales (1B and 3B).
Additionally, we introduce two specialized variants: MM1.5-Video, designed for video understanding, and MM1.5-UI, tailored for mobile UI understanding.
Through extensive empirical studies and ablations, we provide detailed insights into the training processes and decisions that inform our final designs, offering valuable guidance for future research in MLLM development.
3. LLM Training, Evaluation & Inference
3.1. LLaVA-Critic: Learning to Evaluate Multimodal Models

We introduce LLaVA-Critic, the first open-source large multimodal model (LMM) designed as a generalist evaluator to assess performance across a wide range of multimodal tasks. LLaVA-Critic is trained using a high-quality critic instruction-following dataset that incorporates diverse evaluation criteria and scenarios.
Our experiments demonstrate the model’s effectiveness in two key areas: (1) LMM-as-a-Judge, where LLaVA-Critic provides reliable evaluation scores, performing on par with or surpassing GPT models on multiple evaluation benchmarks; and (2) Preference Learning, where it generates reward signals for preference learning, enhancing model alignment capabilities.
This work underscores the potential of open-source LMMs in self-critique and evaluation, setting the stage for future research into scalable, superhuman alignment feedback mechanisms for LMMs.
4. LLM Quantization & Optimization
4.1. VPTQ: Extreme Low-bit Vector Post-Training Quantization for Large Language Models
Scaling model size significantly challenges the deployment and inference of Large Language Models (LLMs). Due to the redundancy in LLM weights, recent research has focused on pushing weight-only quantization to extremely low-bit (even down to 2 bits).
It reduces memory requirements, optimizes storage costs, and decreases memory bandwidth needs during inference. However, due to numerical representation limitations, traditional scalar-based weight quantization struggles to achieve such extreme low-bit.
Recent research on Vector Quantization (VQ) for LLMs has demonstrated the potential for extremely low-bit model quantization by compressing vectors into indices using lookup tables. In this paper, we introduce Vector Post-Training Quantization (VPTQ) for extremely low-bit quantization of LLMs. We use Second-Order Optimization to formulate the LLM VQ problem and guide our quantization algorithm design by solving the optimization.
We further refine the weights using Channel-Independent Second-Order Optimization for a granular VQ. In addition, by decomposing the optimization problem, we propose a brief and effective codebook initialization algorithm. We also extend VPTQ to support residual and outlier quantization, which enhances model accuracy and further compresses the model.
Our experimental results show that VPTQ reduces model quantization perplexity by 0.01–0.34 on LLaMA-2, 0.38–0.68 on Mistral-7B, 4.41–7.34 on LLaMA-3 over SOTA at 2-bit, with an average accuracy improvement of 0.79–1.5% on LLaMA-2, 1% on Mistral-7B, 11–22% on LLaMA-3 on QA tasks on average.
We only utilize 10.4–18.6% of the quantization algorithm execution time, resulting in a 1.6–1.8 times increase in inference throughput compared to SOTA.
4.2. TPI-LLM: Serving 70B-scale LLMs Efficiently on Low-resource Edge Devices

The large model inference is shifting from cloud to edge due to concerns about the privacy of user interaction data. However, edge devices often struggle with limited computing power, memory, and bandwidth, requiring collaboration across multiple devices to run and speed up LLM inference.
Pipeline parallelism, the mainstream solution, is inefficient for single-user scenarios, while tensor parallelism struggles with frequent communications.
In this paper, we argue that tensor parallelism can be more effective than pipeline on low-resource devices, and present a compute- and memory-efficient tensor parallel inference system, named TPI-LLM, to serve 70B-scale models.
TPI-LLM keeps sensitive raw data local in the users’ devices and introduces a sliding window memory scheduler to dynamically manage layer weights during inference, with disk I/O latency overlapped with the computation and communication.
This allows larger models to run smoothly on memory-limited devices. We analyze the communication bottleneck and find that link latency, not bandwidth, emerges as the main issue, so a star-based all-reduce algorithm is implemented.
Through extensive experiments on both emulated and real testbeds, TPI-LLM demonstrated over 80% less time-to-first-token and token latency compared to Accelerate, and over 90% compared to Transformers and Galaxy, while cutting the peak memory footprint of Llama 2–70B by 90%, requiring only 3.1 GB of memory for 70B-scale models.
4.3. SageAttention: Accurate 8-Bit Attention for Plug-and-play Inference Acceleration

The transformer architecture predominates across various models. As the heart of the transformer, attention has a computational complexity of O(N²), compared to O(N) for linear transformations. When handling large sequence lengths, attention becomes the primary time-consuming component.
Although quantization has proven to be an effective method for accelerating model inference, existing quantization methods primarily focus on optimizing the linear layer. In response, we first analyze the feasibility of quantization in attention detailedly.
Following that, we propose SageAttention, a highly efficient and accurate quantization method for attention. The OPS (operations per second) of our approach outperforms FlashAttention2 and xformers by about 2.1 times and 2.7 times, respectively.
SageAttention also achieves superior accuracy performance over FlashAttention3. Comprehensive experiments confirm that our approach incurs almost no end-to-end metrics loss across diverse models, including those for large language processing, image generation, and video generation.
4.4. PHI-S: Distribution Balancing for Label-Free Multi-Teacher Distillation

Various visual foundation models have distinct strengths and weaknesses, both of which can be improved through heterogeneous multi-teacher knowledge distillation without labels, termed “agglomerative models.”
We build upon this body of work by studying the effect of the teachers’ activation statistics, particularly the impact of the loss function on the resulting student model quality. We explore a standard toolkit of statistical normalization techniques to align the different distributions better and assess their effects.
Further, we examine the impact on downstream teacher-matching metrics, which motivates the use of Hadamard matrices. With these matrices, we demonstrate useful properties, showing how they can be used for isotropic standardization, where each dimension of a multivariate distribution is standardized using the same scale.
We call this technique “PHI Standardization” (PHI-S) and empirically demonstrate that it produces the best student model across the suite of methods studied.
5. LLM Reasoning
5.1. Not All LLM Reasoners Are Created Equal
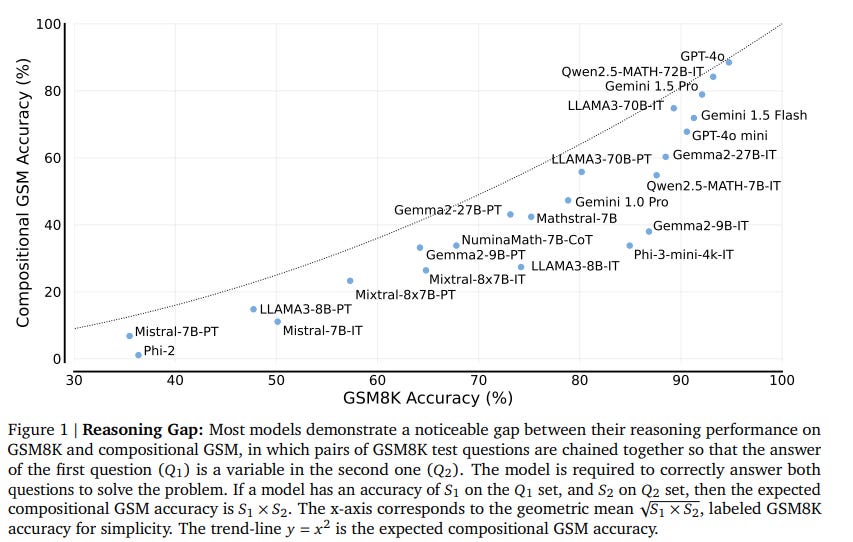
We study the depth of grade-school math (GSM) problem-solving capabilities of LLMs. To this end, we evaluate their performance on pairs of existing math word problems together so that the answer to the second problem depends on correctly answering the first problem.
Our findings reveal a significant reasoning gap in most LLMs, that is performance difference between solving the compositional pairs and solving each question independently. This gap is more pronounced in smaller, more cost-efficient, and math-specialized models. Moreover, instruction-tuning recipes and code generation have varying effects across LLM sizes, while finetuning on GSM can lead to task overfitting.
Our analysis indicates that large reasoning gaps are not because of test-set leakage, but due to distraction from additional context and poor second-hop reasoning. Overall, LLMs exhibit systematic differences in their reasoning abilities, despite what their performance on standard benchmarks indicates.
5.2. RATIONALYST: Pre-training Process-Supervision for Improving Reasoning

The reasoning steps generated by LLMs might be incomplete, as they mimic logical leaps common in everyday communication found in their pre-training data: underlying rationales are frequently left implicit (unstated).
To address this challenge, we introduce RATIONALYST, a model for process-supervision of reasoning based on pre-training on a vast collection of rationale annotations extracted from unlabeled data. We extract 79k rationales from the web-scale unlabelled dataset (the Pile) and a combination of reasoning datasets with minimal human intervention.
This web-scale pre-training for reasoning allows RATIONALYST to consistently generalize across diverse reasoning tasks, including mathematical, commonsense, scientific, and logical reasoning.
Fine-tuned from LLaMa-3–8B, RATIONALYST improves the accuracy of reasoning by an average of 3.9% on 7 representative reasoning benchmarks. It also demonstrates superior performance compared to significantly larger verifiers like GPT-4 and similarly sized models fine-tuned on matching training sets.
6. LLM Fairness & Ethics
6.1. A Survey on the Honesty of Large Language Models

Honesty is a fundamental principle for aligning large language models (LLMs) with human values, requiring these models to recognize what they know and don’t know and be able to faithfully express their knowledge.
Despite promising, current LLMs still exhibit significant dishonest behaviors, such as confidently presenting wrong answers or failing to express what they know.
In addition, research on the honesty of LLMs also faces challenges, including varying definitions of honesty, difficulties in distinguishing between known and unknown knowledge, and a lack of comprehensive understanding of related research.
To address these issues, we provide a survey on the honesty of LLMs, covering their clarification, evaluation approaches, and strategies for improvement. Moreover, we offer insights for future research, aiming to inspire further exploration in this important area.
7. Attention Based Models
7.1. Cottention: Linear Transformers With Cosine Attention
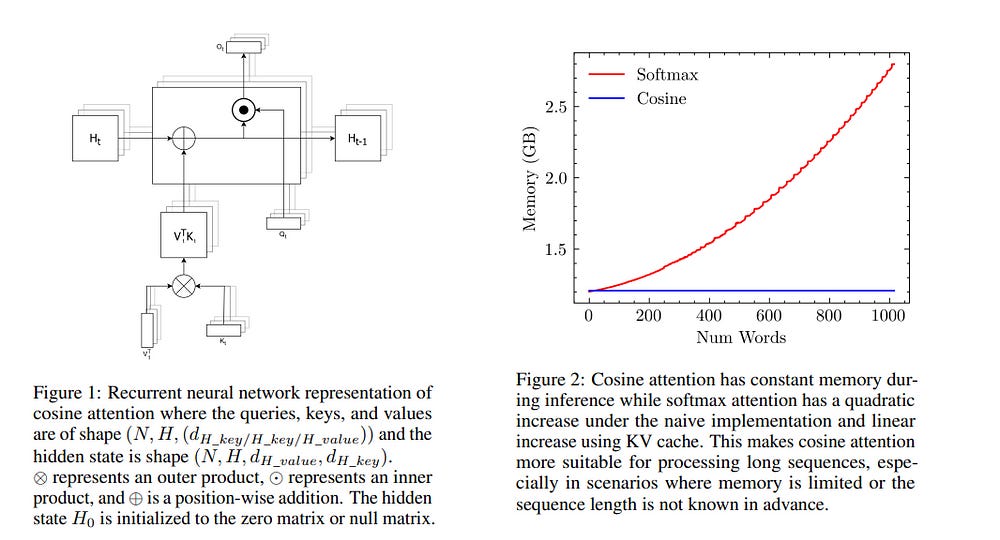
Attention mechanisms, particularly softmax attention, have been instrumental in the success of transformer-based models such as GPT. However, the quadratic memory complexity of softmax attention with respect to sequence length poses significant challenges for processing longer sequences.
We introduce Cottention, a novel attention mechanism that replaces the softmax operation with cosine similarity. By leveraging the properties of cosine similarity and rearranging the attention equation, Cottention achieves native linear memory complexity with respect to sequence length, making it inherently more memory-efficient than softmax attention.
We demonstrate that Cottention can be reformulated as a recurrent neural network (RNN) with a finite hidden state, allowing for constant memory usage during inference. We evaluate Cottention on both the bidirectional BERT and causal GPT tasks, demonstrating comparable performance to softmax attention while significantly reducing memory requirements.
To ensure efficient computation, we develop a custom CUDA kernel for Cottention. Our results show that Cottention is a promising alternative to softmax attention, enabling the processing of longer sequences without sacrificing performance, due to its native linear memory complexity and ability to maintain a constant memory footprint during inference.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
