


Important LLMs Papers for the Week from 07/10 to 13/10
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Second Week of October 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Training, Evaluation & Inference
LLM Quantization & Optimization
LLM Reasoning
LLM Fairness & Ethics
Attention Based Models
Retrieval Augmented Generation (RAG)
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. LLM Progress & Benchmarking
1.1. Tutor CoPilot: A Human-AI Approach for Scaling Real-Time Expertise

Generative AI, particularly Language Models (LMs), has the potential to transform real-world domains with societal impact, particularly where access to experts is limited.
For example, in education, training novice educators with expert guidance is important for effectiveness but expensive, creating significant barriers to improving education quality at scale.
This challenge disproportionately harms students from under-served communities, who stand to gain the most from high-quality education. We introduce Tutor CoPilot, a novel Human-AI approach that leverages a model of expert thinking to provide expert-like guidance to tutors as they tutor.
This study is the first randomized controlled trial of a Human-AI system in live tutoring, involving 900 tutors and 1,800 K-12 students from historically under-served communities. Following a preregistered analysis plan, we find that students working with tutors who have access to Tutor CoPilot are 4 percentage points (p.p.) more likely to master topics (p<0.01).
Notably, students of lower-rated tutors experienced the greatest benefit, improving mastery by 9 p.p. We find that Tutor CoPilot costs only $20 per tutor annually.
We analyze 550,000+ messages using classifiers to identify pedagogical strategies and find that tutors with access to Tutor CoPilot are more likely to use high-quality strategies to foster student understanding (e.g., asking guiding questions) and less likely to give away the answer to the student.
Tutor interviews highlight how Tutor CoPilot’s guidance helps tutors to respond to student needs, though they flag issues in Tutor CoPilot, such as generating suggestions that are not grade-level appropriate.
Altogether, our study of Tutor CoPilot demonstrates how Human systems can scale expertise in real-world domains, bridge gaps in skills, and create a future where high-quality education is accessible to all students.
1.2. CodeMMLU: A Multi-Task Benchmark for Assessing Code Understanding Capabilities of CodeLLMs
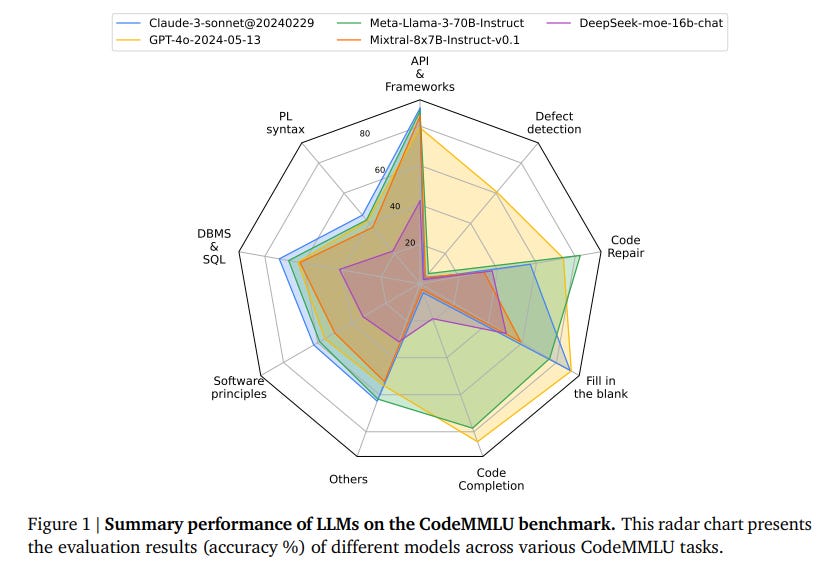
Recent advancements in Code Large Language Models (CodeLLMs) have predominantly focused on open-ended code generation tasks, often neglecting the critical aspect of code understanding and comprehension.
To bridge this gap, we present CodeMMLU, a comprehensive multiple-choice question-answer benchmark designed to evaluate the depth of software and code understanding in LLMs.
CodeMMLU includes over 10,000 questions sourced from diverse domains, encompassing tasks such as code analysis, defect detection, and software engineering principles across multiple programming languages.
Unlike traditional benchmarks, CodeMMLU assesses models’s ability to reason about code rather than merely generate it, providing deeper insights into their grasp of complex software concepts and systems.
Our extensive evaluation reveals that even state-of-the-art models face significant challenges with CodeMMLU, highlighting deficiencies in comprehension beyond code generation.
By underscoring the crucial relationship between code understanding and effective generation, CodeMMLU serves as a vital resource for advancing AI-assisted software development, ultimately aiming to create more reliable and capable coding assistants.
1.3. LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations

Large language models (LLMs) often produce errors, including factual inaccuracies, biases, and reasoning failures, collectively referred to as “hallucinations”.
Recent studies have demonstrated that LLMs’ internal states encode information regarding the truthfulness of their outputs and that this information can be utilized to detect errors. In this work, we show that the internal representations of LLMs encode much more information about truthfulness than previously recognized.
We first discover that the truthfulness information is concentrated in specific tokens, and leveraging this property significantly enhances error detection performance.
Yet, we show that such error detectors fail to generalize across datasets, implying that — contrary to prior claims — truthfulness encoding is not universal but rather multifaceted. Next, we show that internal representations can also be used for predicting the types of errors the model is likely to make, facilitating the development of tailored mitigation strategies.
Lastly, we reveal a discrepancy between LLMs’ internal encoding and external behavior: they may encode the correct answer, yet consistently generate an incorrect one.
Taken together, these insights deepen our understanding of LLM errors from the model’s internal perspective, which can guide future research on enhancing error analysis and mitigation.
1.4. Pixtral 12B

We introduce Pixtral-12B, a 12 — billion-parameter multimodal language model. Pixtral-12B is trained to understand both natural images and documents, achieving leading performance on various multimodal benchmarks, surpassing a number of larger models.
Unlike many open-source models, Pixtral is also a cutting-edge text model for its size and does not compromise on natural language performance to excel in multimodal tasks.
Pixtral uses a new vision encoder trained from scratch, which allows it to ingest images at their natural resolution and aspect ratio. This gives users flexibility on the number of tokens used to process an image.
Pixtral is also able to process any number of images in its long context window of 128K tokens. Pixtral 12B substantially outperforms other open models of similar sizes (Llama-3.2 11B \& Qwen-2-VL 7B). It also outperforms much larger open models like Llama-3.2 90B while being 7x smaller.
We further contribute an open-source benchmark, MM-MT-Bench, for evaluating vision-language models in practical scenarios, and provide detailed analysis and code for standardized evaluation protocols for multimodal LLMs. Pixtral-12B is released under Apache 2.0 license.
1.5. Falcon Mamba: The First Competitive Attention-free 7B Language Model

In this technical report, we present Falcon Mamba 7B, a new base large language model based on the novel Mamba architecture. Falcon Mamba 7B is trained on 5.8 trillion tokens with carefully selected data mixtures.
As a pure Mamba-based model, Falcon Mamba 7B surpasses leading open-weight models based on Transformers, such as Mistral 7B, Llama3.1 8B, and Falcon2 11B. It is on par with Gemma 7B and outperforms models with different architecture designs, such as RecurrentGemma 9B and RWKV-v6 Finch 7B/14B.
Currently, Falcon Mamba 7B is the best-performing Mamba model in the literature at this scale, surpassing both existing Mamba and hybrid Mamba-Transformer models, according to the Open LLM Leaderboard.
Due to its architecture, Falcon Mamba 7B is significantly faster at inference and requires substantially less memory for long sequence generation. Despite recent studies suggesting that hybrid Mamba-Transformer models outperform pure architecture designs, we demonstrate that even the pure Mamba design can achieve similar, or even superior results compared to the Transformer and hybrid designs.
1.6. Aria: An Open Multimodal Native Mixture-of-Experts Model
Information comes in diverse modalities. Multimodal native AI models are essential to integrate real-world information and deliver comprehensive understanding. While proprietary multimodal native models exist, their lack of openness imposes obstacles for adoptions, let alone adaptations.
To fill this gap, we introduce Aria, an open multimodal native model with best-in-class performance across a wide range of multimodal, language, and coding tasks. Aria is a mixture-of-expert model with 3.9B and 3.5B activated parameters per visual token and text token, respectively.
It outperforms Pixtral-12B and Llama3.2–11B, and is competitive against the best proprietary models on various multimodal tasks. We pre-train Aria from scratch following a 4-stage pipeline, which progressively equips the model with strong capabilities in language understanding, multimodal understanding, long context window, and instruction following.
1.7. MLLM as Retriever: Interactively Learning Multimodal Retrieval for Embodied Agents

MLLM agents demonstrate potential for complex embodied tasks by retrieving multimodal task-relevant trajectory data. However, current retrieval methods primarily focus on surface-level similarities of textual or visual cues in trajectories, neglecting their effectiveness for the specific task at hand.
To address this issue, we propose a novel method, MLLM as ReTriever (MART), which enhances the performance of embodied agents by utilizing interaction data to fine-tune an MLLM retriever based on preference learning, such that the retriever fully considers the effectiveness of trajectories and prioritize them for unseen tasks.
We also introduce Trajectory Abstraction, a mechanism that leverages MLLMs’ summarization capabilities to represent trajectories with fewer tokens while preserving key information, enabling agents to better comprehend milestones in the trajectory.
Experimental results across various environments demonstrate our method significantly improves task success rates in unseen scenes compared to baseline methods.
This work presents a new paradigm for multimodal retrieval in embodied agents, by fine-tuning a general-purpose MLLM as the retriever to assess trajectory effectiveness. All benchmark task sets and simulator code modifications for action and observation spaces will be released.
2. LLM Training, Evaluation & Inference
2.1. Towards Self-Improvement of LLMs via MCTS: Leveraging Stepwise Knowledge with Curriculum Preference Learning

Monte Carlo Tree Search (MCTS) has recently emerged as a powerful technique for enhancing the reasoning capabilities of LLMs. Techniques such as SFT or DPO have enabled LLMs to distill high-quality behaviors from MCTS, improving their reasoning performance.
However, existing distillation methods underutilize the rich trajectory information generated by MCTS, limiting the potential for improvements in LLM reasoning. In this paper, we propose AlphaLLM-CPL, a novel pairwise training framework that enables LLMs to self-improve through MCTS behavior distillation.
AlphaLLM-CPL efficiently leverages MCTS trajectories via two key innovations: (1) AlphaLLM-CPL constructs stepwise trajectory pairs from child nodes sharing the same parent in the search tree, providing step-level information for more effective MCTS behavior distillation. (2) AlphaLLM-CPL introduces curriculum preference learning, dynamically adjusting the training sequence of trajectory pairs in each offline training epoch to prioritize critical learning steps and mitigate overfitting.
Experimental results on mathematical reasoning tasks demonstrate that AlphaLLM-CPL significantly outperforms previous MCTS behavior distillation methods, substantially boosting the reasoning capabilities of LLMs.
3. LLM Quantization & Optimization
3.1. Addition is All You Need for Energy-efficient Language Models

Large neural networks spend most computation on floating point tensor multiplications. In this work, we find that a floating point multiplier can be approximated by one integer adder with high precision.
We propose the linear-complexity multiplication L-Mul algorithm that approximates floating point number multiplication with integer addition operations.
The new algorithm costs significantly less computation resources than 8-bit floating point multiplication but achieves higher precision. Compared to 8-bit floating point multiplications, the proposed method achieves higher precision but consumes significantly less bit-level computation.
Since multiplying floating point numbers requires substantially higher energy compared to integer addition operations, applying the L-Mul operation in tensor processing hardware can potentially reduce 95% energy cost by element-wise floating point tensor multiplications and 80% energy cost of dot products.
We calculated the theoretical error expectation of L-Mul and evaluated the algorithm on a wide range of textual, visual, and symbolic tasks, including natural language understanding, structural reasoning, mathematics, and commonsense question answering.
Our numerical analysis experiments agree with the theoretical error estimation, which indicates that L-Mul with 4-bit mantissa achieves comparable precision as float8_e4m3 multiplications, and L-Mul with 3-bit mantissa outperforms float8_e5m2.
Evaluation results on popular benchmarks show that directly applying L-Mul to the attention mechanism is almost lossless. We further show that replacing all floating point multiplications with 3-bit mantissa L-Mul in a transformer model achieves equivalent precision as using float8_e4m3 as accumulation precision in both fine-tuning and inference.
4. LLM Reasoning
4.1. GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models

Recent advancements in Large Language Models (LLMs) have sparked interest in their formal reasoning capabilities, particularly in mathematics. The GSM8K benchmark is widely used to assess the mathematical reasoning of models on grade-school-level questions.
While the performance of LLMs on GSM8K has significantly improved in recent years, it remains unclear whether their mathematical reasoning capabilities have genuinely advanced, raising questions about the reliability of the reported metrics.
To address these concerns, we conduct a large-scale study on several SOTA open and closed models. To overcome the limitations of existing evaluations, we introduce GSM-Symbolic, an improved benchmark created from symbolic templates that allow for the generation of a diverse set of questions.
GSM-Symbolic enables more controllable evaluations, providing key insights and more reliable metrics for measuring the reasoning capabilities of models.
Our findings reveal that LLMs exhibit noticeable variance when responding to different instantiations of the same question. Specifically, the performance of all models declines when only the numerical values in the question are altered in the GSM-Symbolic benchmark.
Furthermore, we investigate the fragility of mathematical reasoning in these models and show that their performance significantly deteriorates as the number of clauses in a question increases.
We hypothesize that this decline is because current LLMs cannot perform genuine logical reasoning; they replicate reasoning steps from their training data.
Adding a single clause that seems relevant to the question causes significant performance drops (up to 65%) across all state-of-the-art models, even though the clause doesn’t contribute to the reasoning chain needed for the final answer. Overall, our work offers a more nuanced understanding of LLMs’ capabilities and limitations in mathematical reasoning.
4.2. LLaMA-Berry: Pairwise Optimization for O1-like Olympiad-Level Mathematical Reasoning

This paper presents an advanced mathematical problem-solving framework, LLaMA-Berry, for enhancing the mathematical reasoning ability of Large Language Models (LLMs).
The framework combines Monte Carlo Tree Search (MCTS) with iterative Self-Refine to optimize the reasoning path and utilizes a pairwise reward model to evaluate different paths globally.
By leveraging the self-critic and rewriting capabilities of LLMs, Self-Refine applied to MCTS (SR-MCTS) overcomes the inefficiencies and limitations of conventional step-wise and greedy search algorithms by fostering a more efficient exploration of solution spaces.
Pairwise Preference Reward Model~(PPRM), inspired by Reinforcement Learning from Human Feedback (RLHF), is then used to model pairwise preferences between solutions, utilizing an Enhanced Borda Count (EBC) method to synthesize these preferences into a global ranking score to find better answers.
This approach addresses the challenges of scoring variability and non-independent distributions in mathematical reasoning tasks. The framework has been tested on general and advanced benchmarks, showing superior performance in terms of search efficiency and problem-solving capability compared to existing methods like ToT and rStar, particularly in complex Olympiad-level benchmarks, including GPQA, AIME24, and AMC23.
4.3. MathCoder2: Better Math Reasoning from Continued Pretraining on Model-translated Mathematical Code

Code has been shown to be effective in enhancing the mathematical reasoning abilities of large language models due to its precision and accuracy.
Previous works involving continued mathematical pretraining often include code that utilizes math-related packages, which are primarily designed for fields such as engineering, machine learning, signal processing, or module testing, rather than being directly focused on mathematical reasoning.
In this paper, we introduce a novel method for generating mathematical code accompanied by corresponding reasoning steps for continued pertaining.
Our approach begins with the construction of a high-quality mathematical continued pretraining dataset by incorporating math-related web data, code using mathematical packages, math textbooks, and synthetic data.
Next, we construct reasoning steps by extracting LaTeX expressions, the conditions needed for the expressions, and the results of the expressions from the previously collected dataset.
Based on this extracted information, we generate corresponding code to accurately capture the mathematical reasoning process. Appending the generated code to each reasoning step results in data consisting of paired natural language reasoning steps and their corresponding code.
Combining this data with the original dataset results in a 19.2B-token high-performing mathematical pretraining corpus, which we name MathCode-Pile.
Training several popular base models with this corpus significantly improves their mathematical abilities, leading to the creation of the MathCoder2 family of models. All of our data processing and training code is open-sourced, ensuring full transparency and easy reproducibility of the entire data collection and training pipeline.
5. LLM Alignment & Ethics
5.1. WALL-E: World Alignment by Rule Learning Improves World Model-based LLM Agents

Can large language models (LLMs) directly serve as powerful world models for model-based agents? While the gaps between the prior knowledge of LLMs and the specified environment’s dynamics do exist, our study reveals that the gaps can be bridged by aligning an LLM with its deployed environment, and such “world alignment” can be efficiently achieved by rule learning on LLMs.
Given the rich prior knowledge of LLMs, only a few additional rules suffice to align LLM predictions with the specified environment dynamics. To this end, we propose a neurosymbolic approach to learn these rules gradient-free through LLMs, by inducing, updating, and pruning rules based on comparisons of agent-explored trajectories and world model predictions.
The resulting world model is composed of the LLM and the learned rules. Our embodied LLM agent “WALL-E” is built upon model-predictive control (MPC). By optimizing look-ahead actions based on the precise world model, MPC significantly improves exploration and learning efficiency.
Compared to existing LLM agents, WALL-E’s reasoning only requires a few principal rules rather than verbose buffered trajectories being included in the LLM input.
On open-world challenges in Minecraft and ALFWorld, WALL-E achieves higher success rates than existing methods, with lower costs on replanning time and the number of tokens used for reasoning.
In Minecraft, WALL-E exceeds baselines by 15–30% in success rate while costing 8–20 fewer replanning rounds and only 60–80% of tokens. In ALFWorld, its success rate surges to a new record high of 95% only after 6 iterations.
6. Attention Based Models
6.1. Differential Transformer

Transformer tends to over-allocate attention to irrelevant context. In this work, we introduce the Diff Transformer, which amplifies attention to the relevant context while canceling noise. Specifically, the differential attention mechanism calculates attention scores as the difference between two separate softmax attention maps.
The subtraction cancels noise, promoting the emergence of sparse attention patterns. Experimental results on language modeling show that Diff Transformer outperforms Transformer in various settings of scaling up model size and training tokens.
More intriguingly, it offers notable advantages in practical applications, such as long-context modeling, key information retrieval, hallucination mitigation, in-context learning, and reduction of activation outliers. By being less distracted by irrelevant context, Diff Transformer can mitigate hallucination in question answering and text summarization.
For in-context learning, Diff Transformer not only enhances accuracy but is also more robust to order permutation, which was considered a chronic robustness issue. The results position Diff Transformer as a highly effective and promising architecture to advance large language models.
7. Retrieval Augmented Generation (RAG)
7.1. Inference Scaling for Long-Context Retrieval Augmented Generation
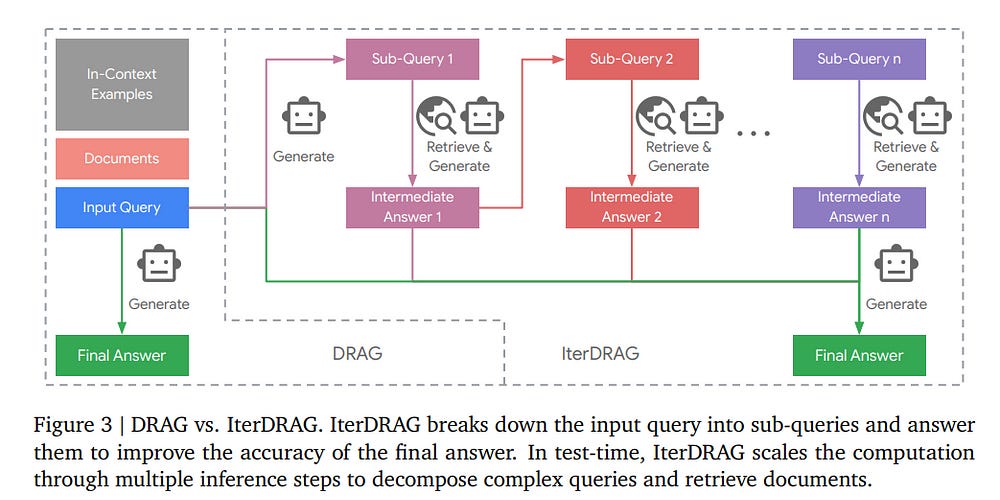
The scaling of inference computation has unlocked the potential of long-context large language models (LLMs) across diverse settings. For knowledge-intensive tasks, the increased compute is often allocated to incorporate more external knowledge.
However, without effectively utilizing such knowledge, solely expanding context does not always enhance performance. In this work, we investigate inference scaling for retrieval augmented generation (RAG), exploring strategies beyond simply increasing the quantity of knowledge.
We focus on two inference scaling strategies: in-context learning and iterative prompting. These strategies provide additional flexibility to scale test-time computation (e.g., by increasing retrieved documents or generation steps), thereby enhancing LLMs’ ability to effectively acquire and utilize contextual information.
We address two key questions: (1) How does RAG performance benefit from the scaling of inference computation when optimally configured? (2) Can we predict the optimal test-time compute allocation for a given budget by modeling the relationship between RAG performance and inference parameters?
Our observations reveal that increasing inference computation leads to nearly linear gains in RAG performance when optimally allocated, a relationship we describe as the inference scaling laws for RAG. Building on this, we further develop the computation allocation model to estimate RAG performance across different inference configurations.
The model predicts optimal inference parameters under various computation constraints, which align closely with the experimental results. By applying these optimal configurations, we demonstrate that scaling inference computed on long-context LLMs achieves up to 58.9% gains on benchmark datasets compared to standard RAG.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
