


Important LLMs Papers for the Week from 16/12 to 22/12
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Third Week of December 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
Transformers
LLM Training
LLM Quantization
LLM Reasoning
Retrieval Augmented Generation (RAG)
LLM Agents
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. LLM Progress & Benchmarking
1.1. BiMediX2: Bio-Medical EXpert LMM for Diverse Medical Modalities

This paper introduces BiMediX2, a bilingual (Arabic-English) Bio-Medical EXpert Large Multimodal Model (LMM) with a unified architecture that integrates text and visual modalities, enabling advanced image understanding and medical applications.
BiMediX2 leverages the Llama3.1 architecture and integrates text and visual capabilities to facilitate seamless interactions in both English and Arabic, supporting text-based inputs and multi-turn conversations involving medical images.
The model is trained on an extensive bilingual healthcare dataset consisting of 1.6M samples of diverse medical interactions for both text and image modalities, mixed in Arabic and English. We also propose the first bilingual GPT-4o-based medical LMM benchmark named BiMed-MBench.
BiMediX2 is benchmarked on both text-based and image-based tasks, achieving state-of-the-art performance across several medical benchmarks.
It outperforms recent state-of-the-art models in medical LLM evaluation benchmarks. Our model also sets a new benchmark in multimodal medical evaluations with over 9% improvement in English and over 20% in Arabic evaluations.
Additionally, it surpasses GPT-4 by around 9% in UPHILL factual accuracy evaluations and excels in various medical Visual Question Answering, Report Generation, and Report Summarization tasks.
1.2. Smaller Language Models Are Better Instruction Evolvers
Instruction tuning has been widely used to unleash the complete potential of large language models. Notably, complex and diverse instructions are of significant importance as they can effectively align models with various downstream tasks.
However, current approaches to constructing large-scale instructions predominantly favor powerful models such as GPT-4 or those with over 70 billion parameters, under the empirical presumption that such larger language models (LLMs) inherently possess enhanced capabilities.
In this study, we question this prevalent assumption and conduct an in-depth exploration into the potential of smaller language models (SLMs) in the context of instruction evolution.
Extensive experiments across three scenarios of instruction evolution reveal that smaller language models (SLMs) can synthesize more effective instructions than LLMs.
Further analysis demonstrates that SLMs possess a broader output space during instruction evolution, resulting in more complex and diverse variants. We also observe that the existing metrics fail to focus on the impact of the instructions.
Thus, we propose Instruction Complex-Aware IFD (IC-IFD), which introduces instruction complexity in the original IFD score to evaluate the effectiveness of instruction data more accurately.
1.3. Qwen2.5 Technical Report

In this report, we introduce Qwen2.5, a comprehensive series of large language models (LLMs) designed to meet diverse needs. Compared to previous iterations, Qwen 2.5 has been significantly improved during both the pre-training and post-training stages.
In terms of pre-training, we have scaled the high-quality pre-training datasets from the previous 7 trillion tokens to 18 trillion tokens. This provides a strong foundation for common sense, expert knowledge, and reasoning capabilities.
In terms of post-training, we implement intricate supervised finetuning with over 1 million samples, as well as multistage reinforcement learning. Post-training techniques enhance human preference and notably improve long text generation, structural data analysis, and instruction following.
To handle diverse and varied use cases effectively, we present Qthe wen2.5 LLM series in rich sizes. Open-weight offerings include base and instruction-tuned models, with quantized versions available.
In addition, for hosted solutions, the proprietary models currently include two mixture-of-experts (MoE) variants: Qwen2.5-Turbo and Qwen2.5-Plus, both available from Alibaba Cloud Model Studio.
Qwen2.5 has demonstrated top-tier performance on a wide range of benchmarks evaluating language understanding, reasoning, mathematics, coding, human preference alignment, etc.
Specifically, the open-weight flagship Qwen2.5–72B-Instruct outperforms a number of open and proprietary models and demonstrates competitive performance to the state-of-the-art open-weight model, Llama-3–405B-Instruct, which is around 5 times larger.
Qwen2.5-Turbo and Qwen2.5-Plus offer superior cost-effectiveness while performing competitively against GPT-4o-mini and GPT-4o respectively. Additionally, as the foundation, Qwen2.5 models have been instrumental in training specialized models such as Qwen2.5-Math, Qwen2.5-Coder, QwQ, and multimodal models.
1.4. The Open Source Advantage in Large Language Models (LLMs)
Large language models (LLMs) mark a key shift in natural language processing (NLP), having advanced text generation, translation, and domain-specific reasoning.
Closed-source models like GPT-4, powered by proprietary datasets and extensive computational resources, lead with state-of-the-art performance today.
However, they face criticism for their “black box” nature and for limiting accessibility in a manner that hinders reproducibility and equitable AI development.
By contrast, open-source initiatives like LLaMA and BLOOM prioritize democratization through community-driven development and computational efficiency.
These models have significantly reduced performance gaps, particularly in linguistic diversity and domain-specific applications, while providing accessible tools for global researchers and developers.
Notably, both paradigms rely on foundational architectural innovations, such as the Transformer framework by Vaswani et al. (2017). Closed-source models excel by scaling effectively, while open-source models adapt to real-world applications in underrepresented languages and domains.
Techniques like Low-Rank Adaptation (LoRA) and instruction-tuning datasets enable open-source models to achieve competitive results despite limited resources.
To be sure, the tension between closed-source and open-source approaches underscores a broader debate on transparency versus proprietary control in AI. Ethical considerations further highlight this divide.
Closed-source systems restrict external scrutiny, while open-source models promote reproducibility and collaboration but lack standardized auditing documentation frameworks to mitigate biases.
Hybrid approaches that leverage the strengths of both paradigms are likely to shape the future of LLM innovation, ensuring accessibility, competitive technical performance, and ethical deployment.
1.5. Multi-Dimensional Insights: Benchmarking Real-World Personalization in Large Multimodal Models

The rapidly developing field of large multimodal models (LMMs) has led to the emergence of diverse models with remarkable capabilities. However, existing benchmarks fail to comprehensively, objectively, and accurately evaluate whether LMMs align with the diverse needs of humans in real-world scenarios.
To bridge this gap, we propose the Multi-Dimensional Insights (MDI) benchmark, which includes over 500 images covering six common scenarios of human life.
Notably, the MDI-Benchmark offers two significant advantages over existing evaluations:
Each image is accompanied by two types of questions: simple questions to assess the model’s understanding of the image, and complex questions to evaluate the model’s ability to analyze and reason beyond basic content.
Recognizing that people of different age groups have varying needs and perspectives when faced with the same scenario, our benchmark stratifies questions into three age categories: young people, middle-aged people, and older people.
This design allows for a detailed assessment of LMMs’ capabilities in meeting the preferences and needs of different age groups. With MDI-Benchmark, a strong model like GPT-4o achieves 79% accuracy on age-related tasks, indicating that existing LMMs still have considerable room for improvement in addressing real-world applications. Looking ahead, we anticipate that the MDI-Benchmark will open new pathways for aligning real-world personalization in LMMs.
1.6. How to Synthesize Text Data without Model Collapse?

The model collapse in synthetic data indicates that iterative training on self-generated data leads to a gradual decline in performance. With the proliferation of AI models, synthetic data will fundamentally reshape the web data ecosystem.
Future GPT-{n} models will inevitably be trained on a blend of synthetic and human-produced data. In this paper, we focus on two questions: what is the impact of synthetic data on language model training, and how to synthesize data without model collapse?
We first pre-train language models across different proportions of synthetic data, revealing a negative correlation between the proportion of synthetic data and model performance.
We further conduct statistical analysis on synthetic data to uncover the distributional shift phenomenon and over-concentration of n-gram features. Inspired by the above findings, we propose token editing on human-produced data to obtain semi-synthetic data.
As a proof of concept, we theoretically demonstrate that token-level editing can prevent model collapse, as the test error is constrained by a finite upper bound.
We conduct extensive experiments on pre-training from scratch, continual pre-training, and supervised fine-tuning. The results validate our theoretical proof that token-level editing improves data quality and enhances model performance.
1.7. Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces

Humans possess the visual-spatial intelligence to remember spaces from sequential visual observations. However, can Multimodal Large Language Models (MLLMs) trained on million-scale video datasets also ``think in space’’ from videos?
We present a novel video-based visual-spatial intelligence benchmark (VSI-Bench) of over 5,000 question-answer pairs, and find that MLLMs exhibit competitive — though subhuman — visual-spatial intelligence.
We probe models to express how they think in space both linguistically and visually and find that while spatial reasoning capabilities remain the primary bottleneck for MLLMs to reach higher benchmark performance, local world models and spatial awareness do emerge within these models.
Notably, prevailing linguistic reasoning techniques (e.g., chain-of-thought, self-consistency, tree-of-thoughts) fail to improve performance, whereas explicitly generating cognitive maps during question-answering enhances MLLMs’ spatial distance ability.
1.8. Large Action Models: From Inception to Implementation

As AI continues to advance, there is a growing demand for systems that go beyond language-based assistance and move toward intelligent agents capable of performing real-world actions.
This evolution requires the transition from traditional Large Language Models (LLMs), which excel at generating textual responses, to Large Action Models (LAMs), designed for action generation and execution within dynamic environments.
Enabled by agent systems, LAMs hold the potential to transform AI from passive language understanding to active task completion, marking a significant milestone in the progression toward artificial general intelligence.
In this paper, we present a comprehensive framework for developing LAMs, offering a systematic approach to their creation, from inception to deployment.
We begin with an overview of LAMs, highlighting their unique characteristics and delineating their differences from LLMs. Using a Windows OS-based agent as a case study, we provide a detailed, step-by-step guide on the key stages of LAM development, including data collection, model training, environment integration, grounding, and evaluation.
This generalizable workflow can serve as a blueprint for creating functional LAMs in various application domains. We conclude by identifying the current limitations of LAMs and discussing directions for future research and industrial deployment, emphasizing the challenges and opportunities that lie ahead in realizing the full potential of LAMs in real-world applications.
2. Transformers
2.1. Byte Latent Transformer: Patches Scale Better Than Tokens

We introduce the Byte Latent Transformer (BLT), a new byte-level LLM architecture that, for the first time, matches tokenization-based LLM performance at scale with significant improvements in inference efficiency and robustness.
BLT encodes bytes into dynamically sized patches, which serve as the primary units of computation. Patches are segmented based on the entropy of the next byte, allocating more compute and model capacity where increased data complexity demands it.
We present the first FLOP-controlled scaling study of byte-level models up to 8B parameters and 4T training bytes. Our results demonstrate the feasibility of scaling models trained on raw bytes without a fixed vocabulary.
Both training and inference efficiency improve due to dynamically selecting long patches when data is predictable, along with qualitative improvements in reasoning and long tail generalization.
Overall, for fixed inference costs, BLT shows significantly better scaling than tokenization-based models, by simultaneously growing both patch and model size.
3. LLM Training
3.1. Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference
Encoder-only transformer models such as BERT offer a great performance-size tradeoff for retrieval and classification tasks with respect to larger decoder-only models.
Despite being the workhorse of numerous production pipelines, there have been limited Pareto improvements to BERT since its release. In this paper, we introduce ModernBERT, bringing modern model optimizations to encoder-only models and representing a major Pareto improvement over older encoders.
Trained on 2 trillion tokens with a native 8192 sequence length, ModernBERT models exhibit state-of-the-art results on a large pool of evaluations encompassing diverse classification tasks and both single and multi-vector retrieval on different domains (including code).
In addition to strong downstream performance, ModernBERT is also the most speed and memory-efficient encoder and is designed for inference on common GPUs.
4. LLM Quantization
4.1. SepLLM: Accelerate Large Language Models by Compressing One Segment into One Separator
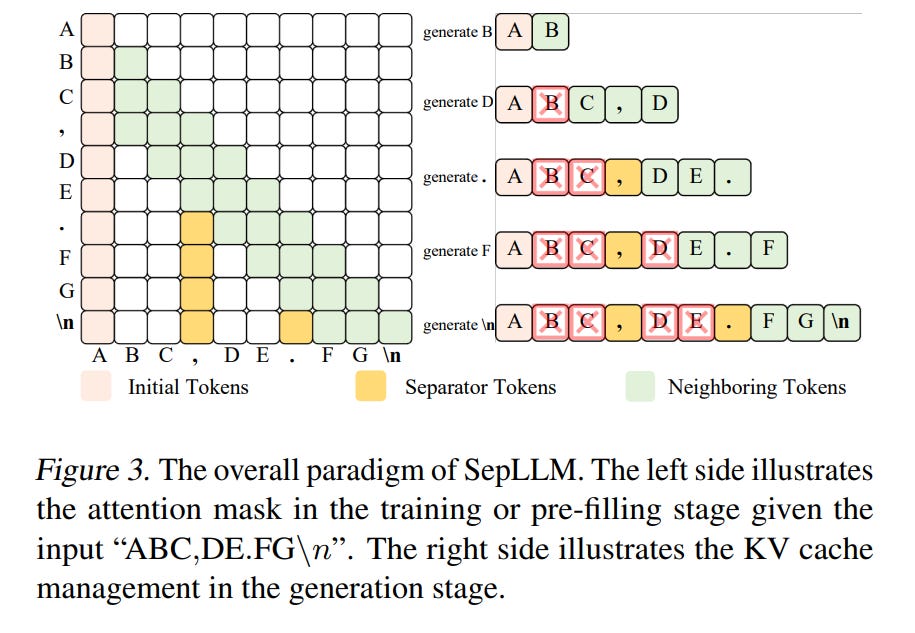
Large Language Models (LLMs) have exhibited exceptional performance across a spectrum of natural language processing tasks. However, their substantial sizes pose considerable challenges, particularly in computational demands and inference speed, due to their quadratic complexity.
In this work, we have identified a key pattern: certain seemingly meaningless special tokens (i.e., separators) contribute disproportionately to attention scores compared to semantically meaningful tokens.
This observation suggests that information on the segments between these separator tokens can be effectively condensed into the separator tokens themselves without significant information loss.
Guided by this insight, we introduce SepLLM, a plug-and-play framework that accelerates inference by compressing these segments and eliminating redundant tokens.
Additionally, we implement efficient kernels for training acceleration. Experimental results across training-free, training-from-scratch, and post-training settings demonstrate SepLLM’s effectiveness.
Notably, using the Llama-3–8B backbone, SepLLM achieves over 50% reduction in KV cache on the GSM8K-CoT benchmark while maintaining comparable performance. Furthermore, in streaming settings, SepLLM effectively processes sequences of up to 4 million tokens or more while maintaining consistent language modeling capabilities.
5. LLM Reasoning
5.1. Are Your LLMs Capable of Stable Reasoning?
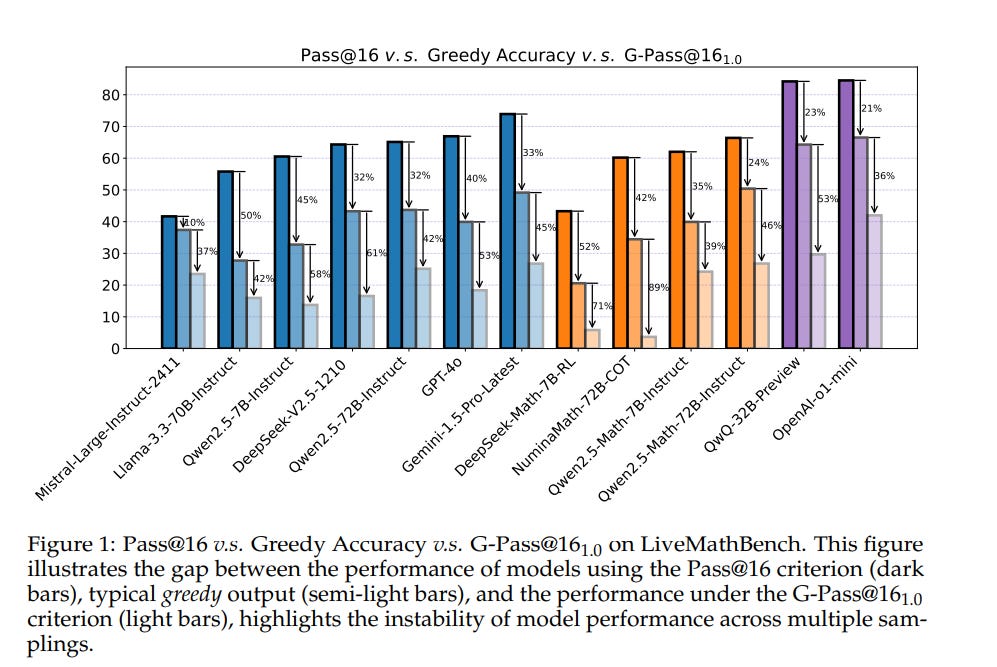
The rapid advancement of Large Language Models (LLMs) has demonstrated remarkable progress in complex reasoning tasks. However, a significant discrepancy persists between benchmark performances and real-world applications.
We identify this gap as primarily stemming from current evaluation protocols and metrics, which inadequately capture the full spectrum of LLM capabilities, particularly in complex reasoning tasks where both accuracy and consistency are crucial.
This work makes two key contributions. First, we introduce G-Pass@k, a novel evaluation metric that provides a continuous assessment of model performance across multiple sampling attempts, quantifying both the model’s peak performance potential and its stability.
Second, we present LiveMathBench, a dynamic benchmark comprising challenging, contemporary mathematical problems designed to minimize data leakage risks during evaluation.
Through extensive experiments using G-Pass@k on state-of-the-art LLMs with LiveMathBench, we provide comprehensive insights into both their maximum capabilities and operational consistency. Our findings reveal substantial room for improvement in LLMs’ “realistic” reasoning capabilities, highlighting the need for more robust evaluation methods.
5.2. LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks

This paper introduces LongBench v2, a benchmark designed to assess the ability of LLMs to handle long-context problems requiring deep understanding and reasoning across real-world multitasking.
LongBench v2 consists of 503 challenging multiple-choice questions, with contexts ranging from 8k to 2M words, across six major task categories: single-document QA, multi-document QA, long in-context learning, long-dialogue history understanding, code repository understanding, and long structured data understanding.
To ensure the breadth and the practicality, we collect data from nearly 100 highly educated individuals with diverse professional backgrounds. We employ both automated and manual review processes to maintain high quality and difficulty, resulting in human experts achieving only 53.7% accuracy under a 15-minute time constraint.
Our evaluation reveals that the best-performing model, when directly answering the questions, achieves only 50.1% accuracy. In contrast, the o1-preview model, which includes longer reasoning, achieves 57.7%, surpassing the human baseline by 4%.
These results highlight the importance of enhanced reasoning ability and scaling inference-time computing to tackle the long-context challenges in LongBench v2.
5.3. Progressive Multimodal Reasoning via Active Retrieval

Multi-step multimodal reasoning tasks pose significant challenges for multimodal large language models (MLLMs), and finding effective ways to enhance their performance in such scenarios remains an unresolved issue.
In this paper, we propose AR-MCTS, a universal framework designed to progressively improve the reasoning capabilities of MLLMs through Active Retrieval (AR) and Monte Carlo Tree Search (MCTS).
Our approach begins with the development of a unified retrieval module that retrieves key supporting insights for solving complex reasoning problems from a hybrid-modal retrieval corpus.
To bridge the gap in automated multimodal reasoning verification, we employ the MCTS algorithm combined with an active retrieval mechanism, which enables the automatic generation of step-wise annotations.
This strategy dynamically retrieves key insights for each reasoning step, moving beyond traditional beam search sampling to improve the diversity and reliability of the reasoning space.
Additionally, we introduce a process reward model that aligns progressively to support the automatic verification of multimodal reasoning tasks. Experimental results across three complex multimodal reasoning benchmarks confirm the effectiveness of the AR-MCTS framework in enhancing the performance of various multimodal models.
Further analysis demonstrates that AR-MCTS can optimize sampling diversity and accuracy, yielding reliable multimodal reasoning.
5.4. Compressed Chain of Thought: Efficient Reasoning Through Dense Representations

Chain-of-thought (CoT) decoding enables language models to improve reasoning performance at the cost of high generation latency in decoding. Recent proposals have explored variants of contemplation tokens, a term we introduce that refers to special tokens used during inference to allow for extra computation.
Prior work has considered fixed-length sequences drawn from a discrete set of embeddings as contemplation tokens. Here we propose a Compressed chain of thought (CCoT), a framework to generate contentful and continuous contemplation tokens of variable sequence length.
The generated contemplation tokens are compressed representations of explicit reasoning chains, and our method can be applied to off-the-shelf decoder language models.
Through experiments, we illustrate how CCoT enables additional reasoning over dense contentful representations to achieve corresponding improvements in accuracy. Moreover, the reasoning improvements can be adaptively modified on demand by controlling the number of contemplation tokens generated.
6. Retrieval Augmented Generation (RAG)
6.1. RetroLLM: Empowering Large Language Models to Retrieve Fine-grained Evidence within Generation
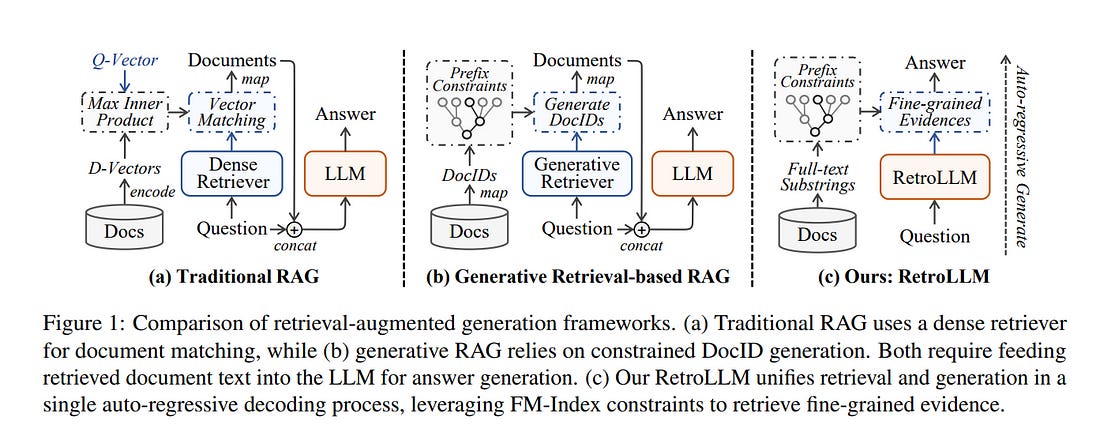
Large language models (LLMs) exhibit remarkable generative capabilities but often suffer from hallucinations. Retrieval-augmented generation (RAG) offers an effective solution by incorporating external knowledge, but existing methods still face several limitations: additional deployment costs of separate retrievers, redundant input tokens from retrieved text chunks, and the lack of joint optimization of retrieval and generation.
To address these issues, we propose RetroLLM, a unified framework that integrates retrieval and generation into a single, cohesive process, enabling LLMs to directly generate fine-grained evidence from the corpus with constrained decoding.
Moreover, to mitigate false pruning in the process of constrained evidence generation, we introduce (1) hierarchical FM-Index constraints, which generate corpus-constrained clues to identify a subset of relevant documents before evidence generation, reducing irrelevant decoding space; and (2) a forward-looking constrained decoding strategy, which considers the relevance of future sequences to improve evidence accuracy.
Extensive experiments on five open-domain QA datasets demonstrate RetroLLM’s superior performance across both in-domain and out-of-domain tasks.
6.2. OmniEval: An Omnidirectional and Automatic RAG Evaluation Benchmark in Financial Domain

As a typical and practical application of Large Language Models (LLMs), Retrieval-Augmented Generation (RAG) techniques have gained extensive attention, particularly in vertical domains where LLMs may lack domain-specific knowledge.
In this paper, we introduce an omnidirectional and automatic RAG benchmark, OmniEval, in the financial domain. Our benchmark is characterized by its multi-dimensional evaluation framework, including:
A matrix-based RAG scenario evaluation system that categorizes queries into five task classes and 16 financial topics, leading to a structured assessment of diverse query scenarios.
A multi-dimensional evaluation data generation approach, which combines GPT-4-based automatic generation and human annotation, achieving an 87.47\% acceptance ratio in human evaluations on generated instances
A multi-stage evaluation system that evaluates both retrieval and generation performance, results in a comprehensive evaluation of the RAG pipeline
Robust evaluation metrics derived from rule-based and LLM-based ones, enhancing the reliability of assessments through manual annotations and supervised fine-tuning of an LLM evaluator.
Our experiments demonstrate the comprehensiveness of OmniEval, which includes extensive test datasets and highlights the performance variations of RAG systems across diverse topics and tasks, revealing significant opportunities for RAG models to improve their capabilities in vertical domains.
6.3. VisDoM: Multi-Document QA with Visually Rich Elements Using Multimodal Retrieval-Augmented Generation

Understanding information from a collection of multiple documents, particularly those with visually rich elements, is important for document-grounded question answering.
This paper introduces VisDoMBench, the first comprehensive benchmark designed to evaluate QA systems in multi-document settings with rich multimodal content, including tables, charts, and presentation slides.
We propose VisDoMRAG, a novel multimodal Retrieval Augmented Generation (RAG) approach that simultaneously utilizes visual and textual RAG, combining robust visual retrieval capabilities with sophisticated linguistic reasoning.
VisDoMRAG employs a multi-step reasoning process encompassing evidence curation and chain-of-thought reasoning for concurrent textual and visual RAG pipelines.
A key novelty of VisDoMRAG is its consistency-constrained modality fusion mechanism, which aligns the reasoning processes across modalities at inference time to produce a coherent final answer.
This leads to enhanced accuracy in scenarios where critical information is distributed across modalities and improved answer verifiability through implicit context attribution.
Through extensive experiments involving open-source and proprietary large language models, we benchmark state-of-the-art document QA methods on VisDoMBench. Extensive results show that VisDoMRAG outperforms unimodal and long-context LLM baselines for end-to-end multimodal document QA by 12–20%.
7. LLM Agents
7.1. GUI Agents: A Survey
Graphical User Interface (GUI) agents, powered by Large Foundation Models, have emerged as a transformative approach to automating human-computer interaction.
These agents autonomously interact with digital systems or software applications via GUIs, emulating human actions such as clicking, typing, and navigating visual elements across diverse platforms.
Motivated by the growing interest and fundamental importance of GUI agents, we provide a comprehensive survey that categorizes their benchmarks, evaluation metrics, architectures, and training methods.
We propose a unified framework that delineates their perception, reasoning, planning, and acting capabilities. Furthermore, we identify important open challenges and discuss key future directions.
Finally, this work serves as a basis for practitioners and researchers to gain an intuitive understanding of current progress, techniques, benchmarks, and critical open problems that remain to be addressed.
7.2. TheAgentCompany: Benchmarking LLM Agents on Consequential Real-World Tasks

We interact with computers on an everyday basis, be it in everyday life or work, and many aspects of work can be done entirely with access to a computer and the Internet.
At the same time, thanks to improvements in large language models (LLMs), there has also been a rapid development in AI agents that interact with and affect change in their surrounding environments. But how performant are AI agents at helping to accelerate or even autonomously perform work-related tasks?
The answer to this question has important implications for both industries looking to adopt AI into their workflows, and for economic policy to understand the effects that adoption of AI may have on the labor market.
To measure the progress of these LLM agents’ performance on performing real-world professional tasks, in this paper, we introduce TheAgentCompany, an extensible benchmark for evaluating AI agents that interact with the world in similar ways to those of a digital worker: by browsing the Web, writing code, running programs, and communicating with other coworkers.
We build a self-contained environment with internal websites and data that mimics a small software company environment and create a variety of tasks that may be performed by workers in such a company.
We test baseline agents powered by both closed API-based and open-weight language models (LMs) and find that with the most competitive agent, 24% of the tasks can be completed autonomously.
This paints a nuanced picture of task automation with LM agents — in a setting simulating a real workplace, a good portion of simpler tasks could be solved autonomously, but more difficult long-horizon tasks are still beyond the reach of current systems.
7.3. Proposer-Agent-Evaluator(PAE): Autonomous Skill Discovery For Foundation Model Internet Agents

The vision of a broadly capable and goal-directed agent, such as an Internet-browsing agent in the digital world and a household humanoid in the physical world, has rapidly advanced, thanks to the generalization capability of foundation models.
Such a generalist agent needs to have a large and diverse skill repertoire, such as finding directions between two travel locations and buying specific items from the Internet.
If each skill needs to be specified manually through a fixed set of human-annotated instructions, the agent’s skill repertoire will necessarily be limited due to the quantity and diversity of human-annotated instructions.
In this work, we address this challenge by proposing a Proposer-Agent-Evaluator, an effective learning system that enables foundation model agents to autonomously discover and practice skills in the wild.
At the heart of PAE is a context-aware task proposer that autonomously proposes tasks for the agent to practice with context information of the environment such as user demos or even just the name of the website itself for Internet-browsing agents.
Then, the agent policy attempts those tasks with thoughts and actual grounded operations in the real world with resulting trajectories evaluated by an autonomous VLM-based success evaluator.
The success evaluation serves as the reward signal for the agent to refine its policies through RL. We validate PAE on challenging vision-based web navigation, using both real-world and self-hosted websites from WebVoyager and WebArena.
To the best of our knowledge, this work represents the first effective learning system to apply an autonomous task proposal with RL for agents that generalize real-world human-annotated benchmarks with SOTA performances.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
