


Important LLMs Papers for the Week from 04/11 to 10/11
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the First Week of November 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
Transformers
LLM Reasoning
LLM Agents
Retrieval Augment Generation (RAG)
LLM Quantization & Optimization
Most insights I share in Medium have previously been shared in my weekly newsletter, To Data & Beyond.
If you want to be up-to-date with the frenetic world of AI while also feeling inspired to take action or, at the very least, to be well-prepared for the future ahead of us, this is for you.
🏝Subscribe below🏝 to become an AI leader among your peers and receive content not present in any other platform, including Medium:
To Data & Beyond | Youssef Hosni | Substack
Data Science, Machine Learning, AI, and what is beyond them. Click to read To Data & Beyond, by Youssef Hosni, a…youssefh.substack.com
1. LLM Progress & Benchmarking
1.1. Personalization of Large Language Models: A Survey

Personalization of Large Language Models (LLMs) has recently become increasingly important with a wide range of applications. Despite the importance and recent progress, most existing works on personalized LLMs have focused either entirely on (a) personalized text generation or (b) leveraging LLMs for personalization-related downstream applications, such as recommendation systems.
In this work, we bridge the gap between these two separate main directions for the first time by introducing a taxonomy for personalized LLM usage and summarizing the key differences and challenges. We provide a formalization of the foundations of personalized LLMs that consolidates and expands notions of personalization of LLMs, defining and discussing novel facets of personalization, usage, and desiderata of personalized LLMs.
We then unify the literature across these diverse fields and usage scenarios by proposing systematic taxonomies for the granularity of personalization, personalization techniques, datasets, evaluation methods, and applications of personalized LLMs. Finally, we highlight challenges and important open problems that remain to be addressed.
By unifying and surveying recent research using the proposed taxonomies, we aim to provide a clear guide to the existing literature and different facets of personalization in LLMs, empowering both researchers and practitioners.
1.2. OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models

Large language models (LLMs) for code have become indispensable in various domains, including code generation, reasoning tasks, and agent systems.
While open-access code LLMs are increasingly approaching the performance levels of proprietary models, high-quality code LLMs suitable for rigorous scientific investigation, particularly those with reproducible data processing pipelines and transparent training protocols, remain limited.
The scarcity is due to various challenges, including resource constraints, ethical considerations, and the competitive advantages of keeping models advanced. To address the gap, we introduce OpenCoder, a top-tier code LLM that not only achieves performance comparable to leading models but also serves as an ``open cookbook’’ for the research community.
Unlike most prior efforts, we release not only model weights and inference code, but also the reproducible training data, complete data processing pipeline, rigorous experimental ablation results, and detailed training protocols for open scientific research.
Through this comprehensive release, we identify the key ingredients for building a top-tier code LLM:
Code-optimized heuristic rules for data cleaning and methods for data deduplication
Recall of text corpus related to code
High-quality synthetic data in both annealing and supervised fine-tuning stages.
By offering this level of openness, we aim to broaden access to all aspects of a top-tier code LLM, with OpenCoder serving as both a powerful model and an open foundation to accelerate research and enable reproducible advancements in code AI.
1.3. Survey of Cultural Awareness in Language Models: Text and Beyond
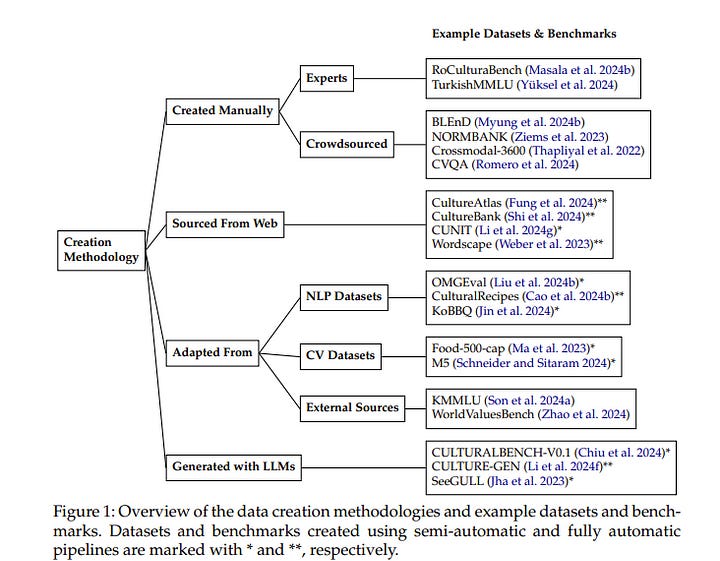
Large-scale deployment of large language models (LLMs) in various applications, such as chatbots and virtual assistants, requires LLMs to be culturally sensitive to the user to ensure inclusivity.
Culture has been widely studied in psychology and anthropology, and there has been a recent surge in research on making LLMs more culturally inclusive in LLMs that goes beyond multilingualism and builds on findings from psychology and anthropology.
In this paper, we survey efforts towards incorporating cultural awareness into text-based and multimodal LLMs. We start by defining cultural awareness in LLMs, taking the definitions of culture from anthropology and psychology as a point of departure.
We then examine methodologies adopted for creating cross-cultural datasets, strategies for cultural inclusion in downstream tasks, and methodologies that have been used for benchmarking cultural awareness in LLMs.
Further, we discuss the ethical implications of cultural alignment, the role of Human-Computer Interaction in driving cultural inclusion in LLMs, and the role of cultural alignment in driving social science research. We finally provide pointers to future research based on our findings about gaps in the literature.
1.4. Both Text and Images Leaked! A Systematic Analysis of Multimodal LLM Data Contamination

The rapid progression of multimodal large language models (MLLMs) has demonstrated superior performance on various multimodal benchmarks. However, the issue of data contamination during training creates challenges in performance evaluation and comparison.
While numerous methods exist for detecting dataset contamination in large language models (LLMs), they are less effective for MLLMs due to their various modalities and multiple training phases.
In this study, we introduce a multimodal data contamination detection framework, MM-Detect, designed for MLLMs. Our experimental results indicate that MM-Detect is sensitive to varying degrees of contamination and can highlight significant performance improvements due to leakage of the training set of multimodal benchmarks.
Furthermore, We also explore the possibility of contamination originating from the pre-training phase of LLMs used by MLLMs and the fine-tuning phase of MLLMs, offering new insights into the stages at which contamination may be introduced.
2. Transformers
2.1. Mixture-of-Transformers: A Sparse and Scalable Architecture for Multi-Modal Foundation Models

The development of large language models (LLMs) has expanded to multi-modal systems capable of processing text, images, and speech within a unified framework.
Training these models demands significantly larger datasets and computational resources compared to text-only LLMs. To address the scaling challenges, we introduce Mixture-of-Transformers (MoT), a sparse multi-modal transformer architecture that significantly reduces pretraining computational costs.
MoT decouples non-embedding parameters of the model by modality — including feed-forward networks, attention matrices, and layer normalization — enabling modality-specific processing with global self-attention over the full input sequence.
We evaluate MoT across multiple settings and model scales. In the Chameleon 7B setting (autoregressive text-and-image generation), MoT matches the dense baseline’s performance using only 55.8\% of the FLOPs. When extended to include speech, MoT reaches speech performance comparable to the dense baseline with only 37.2\% of the FLOPs.
In the Transfusion setting, where text and image are trained with different objectives, a 7B MoT model matches the image modality performance of the dense baseline with one-third of the FLOPs, and a 760M MoT model outperforms a 1.4B dense baseline across key image generation metrics.
System profiling further highlights MoT’s practical benefits, achieving dense baseline image quality in 47.2\% of the wall-clock time and text quality in 75.6\% of the wall-clock time (measured on AWS p4de.24xlarge instances with NVIDIA A100 GPUs).
3. LLM Reasoning
3.1. TOMATO: Assessing Visual Temporal Reasoning Capabilities in Multimodal Foundation Models

Existing benchmarks often highlight the remarkable performance achieved by state-of-the-art Multimodal Foundation Models (MFMs) in leveraging temporal context for video understanding.
However, how well do the models truly perform visual-temporal reasoning? Our study of existing benchmarks shows that this capability of MFMs is likely overestimated as many questions can be solved by using a single, few, or out-of-order frames.
To systematically examine current visual temporal reasoning tasks, we propose three principles with corresponding metrics: (1) Multi-Frame Gain, (2) Frame Order Sensitivity, and (3) Frame Information Disparity.
Following these principles, we introduce TOMATO, Temporal Reasoning Multimodal Evaluation, a novel benchmark crafted to rigorously assess MFMs’ temporal reasoning capabilities in video understanding.
TOMATO comprises 1,484 carefully curated, human-annotated questions spanning six tasks (i.e., action count, direction, rotation, shape & trend, velocity & frequency, and visual cues), applied to 1,417 videos, including 805 self-recorded and -generated videos, that encompass human-centric, real-world, and simulated scenarios.
Our comprehensive evaluation reveals a human-model performance gap of 57.3% with the best-performing model. Moreover, our in-depth analysis uncovers more fundamental limitations beyond this gap in current MFMs. While they can accurately recognize events in isolated frames, they fail to interpret these frames as a continuous sequence.
We believe TOMATO will serve as a crucial testbed for evaluating the next-generation MFMs and as a call to the community to develop AI systems capable of comprehending human world dynamics through the video modality.
3.2. Large Language Models Orchestrating Structured Reasoning Achieve Kaggle Grandmaster Level
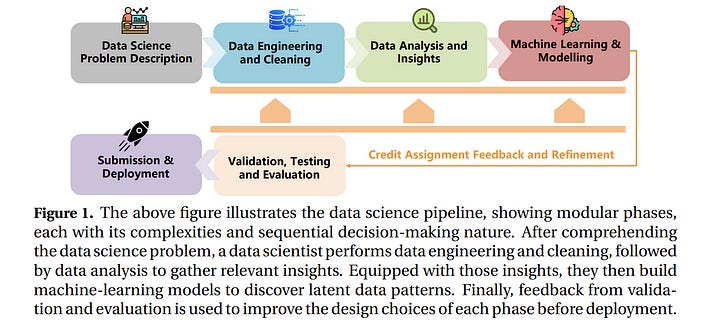
We introduce Agent K v1.0, an end-to-end autonomous data science agent designed to automate, optimize, and generalize across diverse data science tasks. Fully automated, Agent K v1.0 manages the entire data science life cycle by learning from experience.
It leverages a highly flexible structured reasoning framework to enable it to dynamically process memory in a nested structure, effectively learning from accumulated experience stored to handle complex reasoning tasks.
It optimizes long- and short-term memory by selectively storing and retrieving key information, guiding future decisions based on environmental rewards.
This iterative approach allows it to refine decisions without fine-tuning or backpropagation, achieving continuous improvement through experiential learning. We evaluate our agent’s capabilities using Kaggle competitions as a case study.
Following a fully automated protocol, Agent K v1.0 systematically addresses complex and multimodal data science tasks, employing Bayesian optimisation for hyperparameter tuning and feature engineering. Our new evaluation framework rigorously assesses Agent K v1.0’s end-to-end capabilities to generate and send submissions starting from a Kaggle competition URL.
Results demonstrate that Agent K v1.0 achieves a 92.5\% success rate across tasks, spanning tabular, computer vision, NLP, and multimodal domains. When benchmarking against 5,856 human Kaggle competitors by calculating Elo-MMR scores for each, Agent K v1.0 ranks in the top 38\%, demonstrating an overall skill level comparable to Expert-level users.
Notably, its Elo-MMR score falls between the first and third quartiles of scores achieved by human Grandmasters. Furthermore, our results indicate that Agent K v1.0 has reached a performance level equivalent to Kaggle Grandmaster, with a record of 6 gold, 3 silver, and 7 bronze medals, as defined by Kaggle’s progression system.
4. LLM Agents
4.1. AndroidLab: Training and Systematic Benchmarking of Android Autonomous Agents

Autonomous agents have become increasingly important for interacting with the real world. Android agents, in particular, have been recently a frequently-mentioned interaction method.
However, existing studies for training and evaluating Android agents lack systematic research on both open-source and closed-source models. In this work, we propose AndroidLab as a systematic Android agent framework. It includes an operation environment with different modalities, action space, and a reproducible benchmark.
It supports both large language models (LLMs) and multimodal models (LMMs) in the same action space. AndroidLab benchmark includes predefined Android virtual devices and 138 tasks across nine apps built on these devices.
By using the AndroidLab environment, we develop an Android Instruction dataset and train six open-source LLMs and LMMs, lifting the average success rates from 4.59% to 21.50% for LLMs and from 1.93% to 13.28% for LMMs.
5. Retrieval Augment Generation (RAG)
5.1. M3DocRAG: Multi-modal Retrieval is What You Need for Multi-page Multi-document Understanding
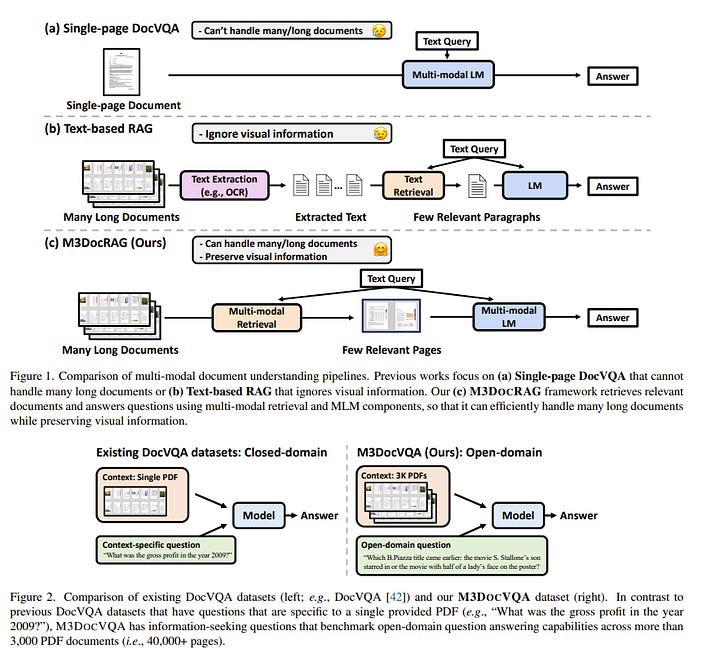
Document visual question answering (DocVQA) pipelines that answer questions from documents have broad applications. Existing methods focus on handling single-page documents with multi-modal language models (MLMs), or rely on text-based retrieval-augmented generation (RAG) that uses text extraction tools such as optical character recognition (OCR).
However, there are difficulties in applying these methods in real-world scenarios:
Questions often require information across different pages or documents, where MLMs cannot handle many long documents
Documents often have important information in visual elements such as figures, but text extraction tools ignore them.
We introduce M3DocRAG, a novel multi-modal RAG framework that flexibly accommodates various document contexts (closed-domain and open-domain), question hops (single-hop and multi-hop), and evidence modalities (text, chart, figure, etc.).
M3DocRAG finds relevant documents and answers questions using a multi-modal retriever and an MLM so that it can efficiently handle single or many documents while preserving visual information.
Since previous DocVQA datasets ask questions in the context of a specific document, we also present M3DocVQA, a new benchmark for evaluating open-domain DocVQA over 3,000+ PDF documents with 40,000+ pages.
In three benchmarks (M3DocVQA/MMLongBench-Doc/MP-DocVQA), empirical results show that M3DocRAG with ColPali and Qwen2-VL 7B achieves superior performance than many strong baselines, including state-of-the-art performance in MP-DocVQA.
We provide comprehensive analyses of different indexing, MLMs, and retrieval models. Lastly, we qualitatively show that M3DocRAG can successfully handle various scenarios, such as when relevant information exists across multiple pages and when answer evidence only exists in images.
5.2. RetrieveGPT: Merging Prompts and Mathematical Models for Enhanced Code-Mixed Information Retrieval

Code-mixing, the integration of lexical and grammatical elements from multiple languages within a single sentence, is a widespread linguistic phenomenon, particularly prevalent in multilingual societies.
In India, social media users frequently engage in code-mixed conversations using the Roman script, especially among migrant communities who form online groups to share relevant local information.
This paper focuses on the challenges of extracting relevant information from code-mixed conversations, specifically within Roman transliterated Bengali mixed with English. This study presents a novel approach to address these challenges by developing a mechanism to identify the most relevant answers from code-mixed conversations automatically.
We have experimented with a dataset comprising of queries and documents from Facebook, and Query Relevance files (QRels) to aid in this task.
Our results demonstrate the effectiveness of our approach in extracting pertinent information from complex, code-mixed digital conversations, contributing to the broader field of natural language processing in multilingual and informal text environments.
We use GPT-3.5 Turbo via prompting and the sequential nature of relevant documents to frame a mathematical model that helps detect relevant documents corresponding to a query.
5.3. HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems

Retrieval-augmented generation (RAG) has been shown to improve knowledge capabilities and alleviate the hallucination problem of LLMs. The Web is a major source of external knowledge used in RAG systems, and many commercial systems such as ChatGPT and Perplexity have used Web search engines as their major retrieval systems.
Typically, such RAG systems retrieve search results, download HTML sources of the results, and then extract plain texts from the HTML sources. Plain text documents or chunks are fed into the LLMs to augment the generation.
However, much of the structural and semantic information inherent in HTML, such as headings and table structures, is lost during this plain-text-based RAG process.
To alleviate this problem, we propose HtmlRAG, which uses HTML instead of plain text as the format of retrieved knowledge in RAG. We believe HTML is better than plain text in modeling knowledge in external documents, and most LLMs possess robust capacities to understand HTML.
However, utilizing HTML presents new challenges. HTML contains additional content such as tags, JavaScript, and CSS specifications, which bring extra input tokens and noise to the RAG system. To address this issue, we propose HTML cleaning, compression, and pruning strategies, to shorten the HTML while minimizing the loss of information.
Specifically, we design a two-step block-tree-based pruning method that prunes useless HTML blocks and keeps only the relevant part of the HTML. Experiments on six QA datasets confirm the superiority of using HTML in RAG systems.
6. LLM Quantization & Optimization
6.1. “Give Me BF16 or Give Me Death”? Accuracy-Performance Trade-Offs in LLM Quantization
Despite the popularity of large language model (LLM) quantization for inference acceleration, significant uncertainty remains regarding the accuracy-performance trade-offs associated with various quantization formats.
We present a comprehensive empirical study of quantized accuracy, evaluating popular quantization formats (FP8, INT8, INT4) across academic benchmarks and real-world tasks, on the Llama-3.1 model family.
Additionally, our study examines the difference in text generated by quantized models versus their uncompressed counterparts. Beyond benchmarks, we also present a couple of quantization improvements that allowed us to obtain state-of-the-art accuracy recovery results.
Our investigation, encompassing over 500,000 individual evaluations, yields several key findings:
FP8 weight and activation quantization (W8A8-FP) is lossless across all model scales
INT8 weight and activation quantization (W8A8-INT), when properly tuned, incurs surprisingly low 1–3% accuracy degradation
INT4 weight-only quantization (W4A16-INT) is competitive with 8-bit integer weight and activation quantization.
To address the question of the “best” format for a given deployment environment, we conduct inference performance analysis using the popular open-source vLLM framework on various GPU architectures.
We find that W4A16 offers the best cost-efficiency for synchronous deployments, and for asynchronous deployment on mid-tier GPUs. At the same time, W8A8 formats excel in asynchronous “continuous batching” deployment of mid- and large-size models on high-end GPUs.
Our results provide a set of practical guidelines for deploying quantized LLMs across scales and performance requirements.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
