


Important LLMs Papers for the Week from 28/10 to 03/11
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Fifth Week of October 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Scaling
LLM Training, Evaluation & Inference
LLM Reasoning
LLM Agents
Retrieval Augment Generation (RAG)
LLM Quantization & Optimization
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. LLM Progress & Benchmarking
1.1. Teach Multimodal LLMs to Comprehend Electrocardiographic Images
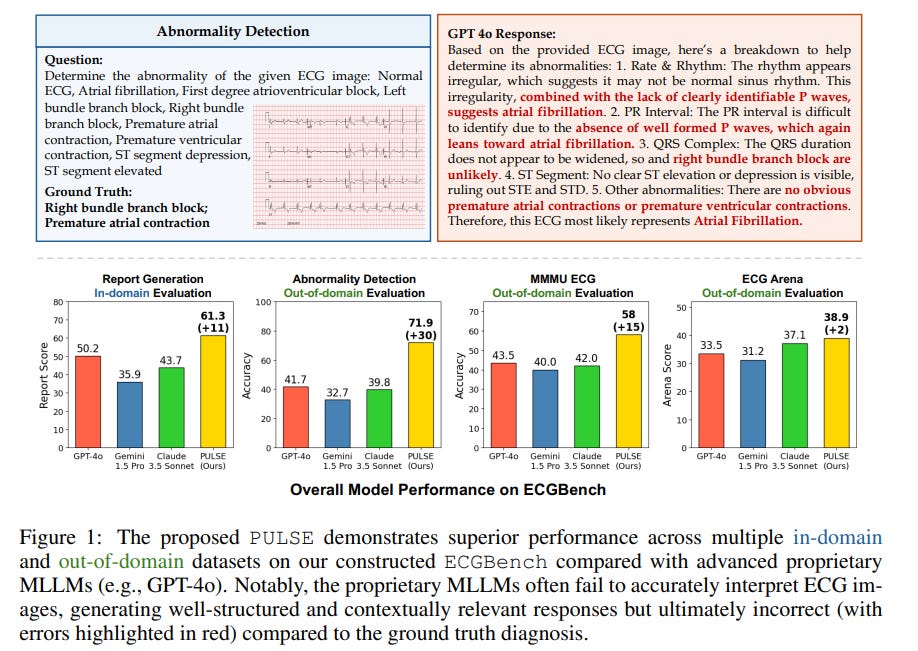
The electrocardiogram (ECG) is an essential non-invasive diagnostic tool for assessing cardiac conditions. Existing automatic interpretation methods suffer from limited generalizability, focusing on a narrow range of cardiac conditions, and typically depend on raw physiological signals, which may not be readily available in resource-limited settings where only printed or digital ECG images are accessible.
Recent advancements in multimodal large language models (MLLMs) present promising opportunities for addressing these challenges. However, the application of MLLMs to ECG image interpretation remains challenging due to the lack of instruction tuning datasets and well-established ECG image benchmarks for quantitative evaluation.
To address these challenges, we introduce ECGInstruct, a comprehensive ECG image instruction tuning dataset of over one million samples, covering a wide range of ECG-related tasks from diverse data sources. Using ECGInstruct, we develop PULSE, an MLLM tailored for ECG image comprehension.
In addition, we curate ECGBench, a new evaluation benchmark covering four key ECG image interpretation tasks across nine different datasets. Our experiments show that PULSE sets a new state-of-the-art, outperforming general MLLMs with an average accuracy improvement of 15% to 30%. This work highlights the potential of PULSE to enhance ECG interpretation in clinical practice.
1.2. GPT-4o System Card
GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It’s trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network.
GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API.
GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations.
In this System Card, we provide a detailed look at GPT-4o’s capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we’ve implemented to ensure the model is safe and aligned.
We also include third-party assessments on dangerous capabilities, as well as a discussion of the potential societal impacts of GPT-4o’s text and vision capabilities.
1.3. Are LLMs Better than Reported? Detecting Label Errors and Mitigating Their Effect on Model Performance

NLP benchmarks rely on standardized datasets for training and evaluating models and are crucial for advancing the field. Traditionally, expert annotations ensure high-quality labels; however, the cost of expert annotation does not scale well with the growing demand for larger datasets required by modern models.
While crowd-sourcing provides a more scalable solution, it often comes at the expense of annotation precision and consistency. Recent advancements in large language models (LLMs) offer new opportunities to enhance the annotation process, particularly for detecting label errors in existing datasets.
In this work, we consider the recent approach of LLM-as-a-judge, leveraging an ensemble of LLMs to flag potentially mislabeled examples. Through a case study of four datasets from the TRUE benchmark, covering different tasks and domains, we empirically analyze the labeling quality of existing datasets and compare expert, crowd-sourced, and LLM-based annotations in terms of the agreement, label quality, and efficiency, demonstrating the strengths and limitations of each annotation method.
Our findings reveal a substantial number of label errors, which, when corrected, induce a significant upward shift in reported model performance.
This suggests that many of the LLM's so-called mistakes are due to label errors rather than genuine model failures. Additionally, we discuss the implications of mislabeled data and propose methods to mitigate them in training to improve model performance.
1.4. A Survey of Small Language Models
Small Language Models (SLMs) have become increasingly important due to their efficiency and performance to perform various language tasks with minimal computational resources, making them ideal for various settings including on-device, mobile, edge devices, among many others.
In this article, we present a comprehensive survey on SLMs, focusing on their architectures, training techniques, and model compression techniques. We propose a novel taxonomy for categorizing the methods used to optimize SLMs, including model compression, pruning, and quantization techniques.
We summarize the benchmark datasets that are useful for benchmarking SLMs along with the evaluation metrics commonly used. Additionally, we highlight key open challenges that remain to be addressed.
Our survey aims to serve as a valuable resource for researchers and practitioners interested in developing and deploying small yet efficient language models.
1.5. LongReward: Improving Long-context Large Language Models with AI Feedback

Though significant advancements have been achieved in developing long-context large language models (LLMs), the compromised quality of LLM-synthesized data for supervised fine-tuning (SFT) often affects the long-context performance of SFT models and leads to inherent limitations.
In principle, reinforcement learning (RL) with appropriate reward signals can further enhance models’ capacities. However, how to obtain reliable rewards in long-context scenarios remains unexplored.
To this end, we propose LongReward, a novel method that utilizes an off-the-shelf LLM to provide rewards for long-context model responses from four human-valued dimensions: helpfulness, logicality, faithfulness, and completeness, each with a carefully designed assessment pipeline.
By combining LongReward and offline RL algorithm DPO, we are able to effectively improve long-context SFT models. Our experiments indicate that LongReward not only significantly improves models’ long-context performance but also enhances their ability to follow short instructions.
We also find that long-context DPO with LongReward and conventional short-context DPO can be used together without hurting either one’s performance.
1.6. Can Language Models Replace Programmers? REPOCOD Says ‘Not Yet’

Large language models (LLMs) have shown remarkable ability in code generation with more than 90 pass@1 in solving Python coding problems in HumanEval and MBPP.
Such high accuracy leads to the question: can LLMs replace human programmers? Existing manual crafted, simple, or single-line code generation benchmarks cannot answer this question due to their gap with real-world software development.
To answer this question, we propose REPOCOD, a code generation benchmark with 980 problems collected from 11 popular real-world projects, with more than 58% of them requiring file-level or repository-level context information.
In addition, REPOCOD has the longest average canonical solution length (331.6 tokens) and the highest average cyclomatic complexity (9.00) compared to existing benchmarks.
In our evaluations on ten LLMs, none of the models can achieve more than 30 pass@1 on REPOCOD, disclosing the necessity of building stronger LLMs that can help developers in real-world software development.
2. LLM Scaling
2.1. Infinity-MM: Scaling Multimodal Performance with Large-Scale and High-Quality Instruction Data

Vision-Language Models (VLMs) have recently made significant progress, but the limited scale and quality of open-source instruction data hinder their performance compared to closed-source models.
In this work, we address this limitation by introducing Infinity-MM, a large-scale multimodal instruction dataset with 40 million samples, enhanced through rigorous quality filtering and deduplication.
We also propose a synthetic instruction generation method based on open-source VLMs, using detailed image annotations and diverse question generation. Using this data, we trained a 2-billion-parameter VLM, Aquila-VL-2B, achieving state-of-the-art (SOTA) performance for models of similar scale. This demonstrates that expanding instruction data and generating synthetic data can significantly improve the performance of open-source models.
3. LLM Training, Evaluation & Inference
3.1. What Happened in LLMs Layers when Trained for Fast vs. Slow Thinking: A Gradient Perspective
What makes a difference in the post-training of LLMs? We investigate the training patterns of different layers in large language models (LLMs), through the lens of gradient, when training with different responses and initial models.
We are specifically interested in how fast vs. slow thinking affects the layer-wise gradients, given the recent popularity of training LLMs on reasoning paths such as chain-of-thoughts (CoT) and process rewards.
In our study, fast thinking without CoT leads to larger gradients and larger differences of gradients across layers than slow thinking (Detailed CoT), indicating the learning stability brought by the latter.
Moreover, pre-trained LLMs are less affected by the instability of fast thinking than instruction-tuned LLMs. Additionally, we study whether the gradient patterns can reflect the correctness of responses when training different LLMs using slow vs. fast thinking paths.
The results show that the gradients of slow thinking can distinguish correct and irrelevant reasoning paths. As a comparison, we conduct similar gradient analyses on non-reasoning knowledge learning tasks, on which, however, trivially increasing the response length does not lead to similar behaviors of slow thinking.
Our study strengthens fundamental understandings of LLM training and sheds novel insights on its efficiency and stability, which pave the way towards building a generalizable System-2 agent.
4. LLM Reasoning
4.1. SocialGPT: Prompting LLMs for Social Relation Reasoning via Greedy Segment Optimization

Social relation reasoning aims to identify relation categories such as friends, spouses, and colleagues from images. While current methods adopt the paradigm of training a dedicated network end-to-end using labeled image data, they are limited in terms of generalizability and interoperability.
To address these issues, we first present a simple yet well-crafted framework named {\name}, which combines the perception capability of Vision Foundation Models (VFMs) and the reasoning capability of Large Language Models (LLMs) within a modular framework, providing a strong baseline for social relation recognition.
Specifically, we instruct VFMs to translate image content into a textual social story, and then utilize LLMs for text-based reasoning. {\name} introduces systematic design principles to adapt VFMs and LLMs separately and bridge their gaps.
Without additional model training, it achieves competitive zero-shot results on two databases while offering interpretable answers, as LLMs can generate language-based explanations for the decisions. The manual prompt design process for LLMs at the reasoning phase is tedious and an automated prompt optimization method is desired.
As we essentially convert a visual classification task into a generative task of LLMs, automatic prompt optimization encounters a unique long prompt optimization issue.
To address this issue, we further propose the Greedy Segment Prompt Optimization (GSPO), which performs a greedy search by utilizing gradient information at the segment level. Experimental results show that GSPO significantly improves performance, and our method also generalizes to different image styles.
4.2. Mind Your Step (by Step): Chain-of-Thought can Reduce Performance on Tasks where Thinking Makes Humans Worse

Chain-of-thought (CoT) prompting has become a widely used strategy for working with large language and multimodal models. While CoT has been shown to improve performance across many tasks, determining the settings in which it is effective remains an ongoing effort.
In particular, it is still an open question in what settings CoT systematically reduces model performance. In this paper, we seek to identify the characteristics of tasks where CoT reduces performance by drawing inspiration from cognitive psychology, looking at cases where
Verbal thinking or deliberation hurts human performance
The constraints governing human performance are generalized to language models.
Three such cases are implicit statistical learning, visual recognition, and classifying with patterns containing exceptions.
In extensive experiments across all three settings, we find that a diverse collection of state-of-the-art models exhibit significant drop-offs in performance (e.g., up to 36.3% absolute accuracy for OpenAI o1-preview compared to GPT-4o) when using inference-time reasoning compared to zero-shot counterparts.
We also identify three tasks that satisfy condition (i) but not (ii), and find that while verbal thinking reduces human performance in these tasks, CoT retains or increases model performance.
Overall, our results show that while there is not an exact parallel between the cognitive processes of models and those of humans, considering cases where thinking has negative consequences for human performance can help us identify settings where it negatively impacts models.
By connecting the literature on human deliberation with evaluations of CoT, we offer a new tool that can be used in understanding the impact of prompt choices and inference-time reasoning.
4.3. Flow-DPO: Improving LLM Mathematical Reasoning through Online Multi-Agent Learning
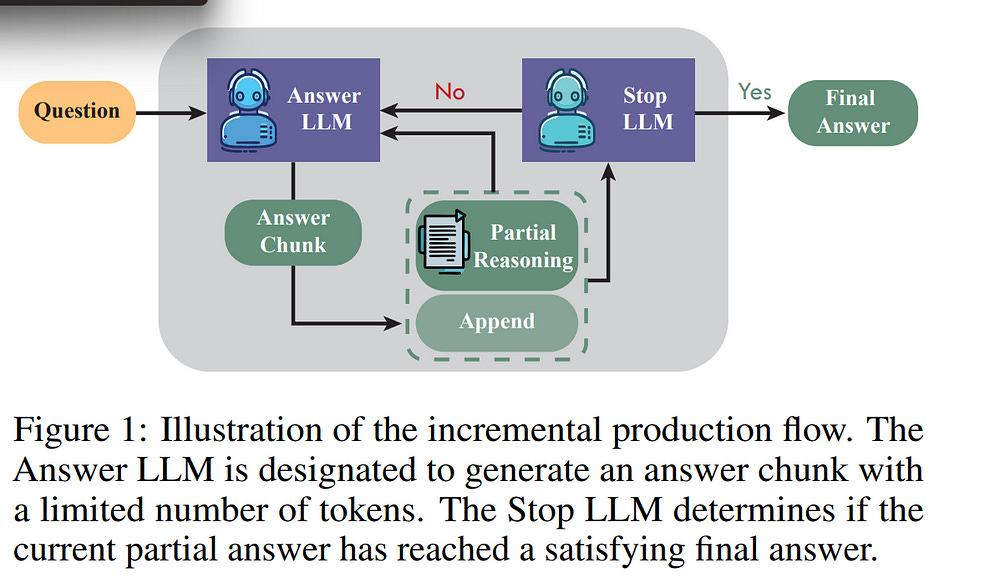
Mathematical reasoning is a crucial capability for Large Language Models (LLMs), yet generating detailed and accurate reasoning traces remains a significant challenge.
This paper introduces a novel approach to producing high-quality reasoning traces for LLM fine-tuning using online learning Flows. Our method employs an incremental output production Flow, where component LLMs collaboratively construct solutions through iterative communication.
We train the Flow using online Direct Preference Optimization (DPO) learning with rollouts, generating DPO pairs for each training example and updating models in real time.
We directly compare the quality of reasoning traces generated by our method with those produced through direct model inference, demonstrating the effectiveness of our approach in improving LLM performance in mathematical reasoning tasks.
5. LLM Agents
5.1. AutoKaggle: A Multi-Agent Framework for Autonomous Data Science Competitions

Data science tasks involving tabular data present complex challenges that require sophisticated problem-solving approaches. We propose AutoKaggle, a powerful and user-centric framework that assists data scientists in completing daily data pipelines through a collaborative multi-agent system.
AutoKaggle implements an iterative development process that combines code execution, debugging, and comprehensive unit testing to ensure code correctness and logic consistency.
The framework offers highly customizable workflows, allowing users to intervene at each phase, thus integrating automated intelligence with human expertise.
Our universal data science toolkit, comprising validated functions for data cleaning, feature engineering, and modeling, forms the foundation of this solution, enhancing productivity by streamlining common tasks.
We selected 8 Kaggle competitions to simulate data processing workflows in real-world application scenarios. Evaluation results demonstrate that AutoKaggle achieves a validation submission rate of 0.85 and a comprehensive score of 0.82 in typical data science pipelines, fully proving its effectiveness and practicality in handling complex data science tasks.
5.2. AgentStore: Scalable Integration of Heterogeneous Agents As Specialized Generalist Computer Assistant

Digital agents capable of automating complex computer tasks have attracted considerable attention due to their immense potential to enhance human-computer interaction.
However, existing agent methods exhibit deficiencies in their generalization and specialization capabilities, especially in handling open-ended computer tasks in real-world environments.
Inspired by the rich functionality of the App store, we present AgentStore, a scalable platform designed to dynamically integrate heterogeneous agents for automating computer tasks.
AgentStore empowers users to integrate third-party agents, allowing the system to continuously enrich its capabilities and adapt to rapidly evolving operating systems.
Additionally, we propose a novel core MetaAgent with the AgentToken strategy to efficiently manage diverse agents and utilize their specialized and generalist abilities for both domain-specific and system-wide tasks.
Extensive experiments on three challenging benchmarks demonstrate that AgentStore surpasses the limitations of previous systems with narrow capabilities, particularly achieving a significant improvement from 11.21\% to 23.85\% on the OSWorld benchmark, more than doubling the previous results.
Comprehensive quantitative and qualitative results further demonstrate AgentStore’s ability to enhance agent systems in both generalization and specialization, underscoring its potential for developing the specialized generalist computer assistant.
6. Retrieval Augment Generation (RAG)
6.1. Document Parsing Unveiled: Techniques, Challenges, and Prospects for Structured Information Extraction

Document parsing is essential for converting unstructured and semi-structured documents such as contracts, academic papers, and invoices into structured, machine-readable data.
Document parsing extracts reliable structured data from unstructured inputs, providing huge convenience for numerous applications. Especially with recent achievements in Large Language Models, document parsing plays an indispensable role in both knowledge base construction and training data generation.
This survey presents a comprehensive review of the current state of document parsing, covering key methodologies, from modular pipeline systems to end-to-end models driven by large vision-language models.
Core components such as layout detection, content extraction (including text, tables, and mathematical expressions), and multi-modal data integration are examined in detail.
Additionally, this paper discusses the challenges faced by modular document parsing systems and vision-language models in handling complex layouts, integrating multiple modules, and recognizing high-density text. It emphasizes the importance of developing larger and more diverse datasets and outlines future research directions.
6.2. CORAL: Benchmarking Multi-turn Conversational Retrieval-Augmentation Generation

Retrieval-augmented generation (RAG) has become a powerful paradigm for enhancing large language models (LLMs) through external knowledge retrieval.
Despite its widespread attention, existing academic research predominantly focuses on single-turn RAG, leaving a significant gap in addressing the complexities of multi-turn conversations found in real-world applications.
To bridge this gap, we introduce CORAL, a large-scale benchmark designed to assess RAG systems in realistic multi-turn conversational settings. CORAL includes diverse information-seeking conversations automatically derived from Wikipedia and tackles key challenges such as open-domain coverage, knowledge intensity, free-form responses, and topic shifts.
It supports three core tasks of conversational RAG: passage retrieval, response generation, and citation labeling. We propose a unified framework to standardize various conversational RAG methods and conduct a comprehensive evaluation of these methods on CORAL, demonstrating substantial opportunities for improving existing approaches.
7. LLM Quantization & Optimization
7.1. COAT: Compressing Optimizer States and Activation for Memory-Efficient FP8 Training

FP8 training has emerged as a promising method for improving training efficiency. Existing frameworks accelerate training by applying FP8 computation to linear layers while leaving optimizer states and activations in higher precision, which fails to fully optimize memory usage.
This paper introduces COAT (Compressing Optimizer States and Activations for FP8 Training), a novel FP8 training framework designed to significantly reduce memory footprint when training large models.
COAT addresses current limitations through two key innovations:
Dynamic Range Expansion, which aligns optimizer state distributions more closely with the FP8 representation range, thereby reducing quantization error
Mixed-granularity activation Quantization, which optimizes activation memory using a combination of per-tensor and per-group quantization strategies.
Experiments demonstrate that COAT effectively reduces end-to-end training memory footprint by 1.54x compared to BF16 while achieving nearly lossless performance across various tasks, such as Large Language Model pretraining and fine-tuning and Vision Language Model training.
COAT also achieves a 1.43x end-to-end training speedup compared to BF16, performing on par with or surpassing TransformerEngine’s speedup. COAT enables efficient full-parameter training of large models on fewer GPUs, and facilitates doubling the batch size in distributed training settings, providing a practical solution for scaling large-scale model training.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
