


Important LLMs Papers for the Week from 03/02 to 09/02
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the First Week of February 2025. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Reasoning
LLM Agents
LLM Preference Optimization & Alignment
LLM Scaling & Optimization
LLM Safety & Security
Retrieval Augmented Generation (RAG)
Attention Models
My New E-Book: Efficient Python for Data Scientists

I am happy to announce publishing my new E-book Efficient Python for Data Scientists. Efficient Python for Data Scientists is your practical companion to mastering the art of writing clean, optimized, and high-performing Python code for data science. In this book, you'll explore actionable insights and strategies to transform your Python workflows, streamline data analysis, and maximize the potential of libraries like Pandas.
1. LLM Progress & Benchmarking
1.1. AIN: The Arabic INclusive Large Multimodal Model

Amid the swift progress of large language models (LLMs) and their evolution into large multimodal models (LMMs), significant strides have been made in high-resource languages such as English and Chinese.
While Arabic LLMs have semadeotable progress, they remain largely unexplored, They often focus narrowly a few specific aspects of the language and visual understanding.
To bridge this gap, we introduce the AIN Arabic Inclusive Multimodal Model de(LMM), which is signed to excel across diverse domains. AIN is an English-Arabic bilingual LMM dethat leveragesarefully constructed 3.6 million high-quality Arabic-English multimodal data samples.
AIN demonstrates state-of-the-art Arabic performance, while also possessing strong English-language visual capabilities. On the recent CAMEL-Bench benchmark comprising 38 sub-domains including, multi-image understanding, complex visual perception, handwritten document understanding, video understanding, medical imaging, plant diseases, and remote sensing-based land use understanding, our AIN demonstrates strong performance with the 7B model outperforming GPT-4o by an absolute gain of 3.4% averaged over eight domains and 38 sub-domains.
AIN’s superior capabilities make it a significant step toward empowering Arabic speakers with advanced multimodal generative AI tools and diverse applications.
1.2. Preference Leakage: A Contamination Problem in LLM-as-a-judge

Large Language Models (LLMs) as judges and LLM-based data synthesis have emerged as two fundamental LLM-driven data annotation methods in model development.
While their combination significantly enhances the efficiency of model training and evaluation, little attention has been given to the potential contamination brought by this new model development paradigm.
In this work, we expose preference leakage, a contamination problem in LLM-as-a-judge caused by the relatedness between the synthetic data generators and LLM-based evaluators.
To study this issue, we first define three common relatednesses between data generator LLM and judge LLM: being the same model, having an inheritance relationship, and belonging to the same model family.
Through extensive experiments, we empirically confirm the bias of judges towards their related student models caused by preference leakage across multiple LLM baselines and benchmarks.
Further analysis suggests that preference leakage is a pervasive issue that is harder to detect compared to previously identified biases in LLM-as-a-judge scenarios. All of these findings imply that preference leakage is a widespread and challenging problem in the area of LLM-as-a-judge.
2. LLM Reasoning
2.1. BOLT: Bootstrap Long Chain-of-Thought in Language Models without Distillation

Large language models (LLMs), such as o1 from OpenAI, have demonstrated remarkable reasoning capabilities. o1 generates a long chain of thought (LongCoT) before answering a question.
LongCoT allows LLMs to analyze problems, devise plans, reflect, and backtrack effectively. These actions empower LLM to solve complex problems. After the release of o1, many teams have attempted to replicate its LongCoT and reasoning capabilities.
In terms of methods, they primarily rely on knowledge distillation with data from existing models with LongCoT capacities (e.g., OpenAI-o1, Qwen-QwQ, DeepSeek-R1-Preview), leaving significant uncertainties on systematically developing such reasoning abilities.
In terms of data domains, these works focus narrowly on math while a few others include coding, limiting their generalizability. This paper introduces a novel approach to enable LLM’s LongCoT capacity without distillation from o1-like models or expensive human annotations, where we bootstrap LongCoT (BOLT) from a standard instruct model.
BOLT involves three stages: 1) LongCoT data bootstrapping with in-context learning on a standard instruct model; 2) LongCoT supervised fine-tuning; 3) online training to further refine LongCoT capacities.
In BOLT, only a few in-context examples need to be constructed during the bootstrapping stage; in our experiments, we created 10 examples, demonstrating the feasibility of this approach.
We use Llama-3.1–70B-Instruct to bootstrap LongCoT and apply our method to various model scales (7B, 8B, 70B). We achieve impressive performance on a variety of benchmarks, Arena-Hard, MT-Bench, WildBench, ZebraLogic, and MATH500, which evaluate diverse task-solving and reasoning capabilities.
2.2. Demystifying Long Chain-of-Thought Reasoning in LLMs
Scaling inference computing enhances reasoning in large language models (LLMs), with long chains of thought (CoTs) enabling strategies like backtracking and error correction.
Reinforcement learning (RL) has emerged as a crucial method for developing these capabilities, yet the conditions under which long CoTs emerge remain unclear, and RL training requires careful design choices.
In this study, we systematically investigate the mechanics of long CoT reasoning, identifying the key factors that enable models to generate long CoT trajectories.
Through extensive supervised fine-tuning (SFT) and RL experiments, we present four main findings: (1) While SFT is not strictly necessary, it simplifies training and improves efficiency; (2) Reasoning capabilities tend to emerge with increased training compute, but their development is not guaranteed, making reward shaping crucial for stabilizing CoT length growth; (3) Scaling verifiable reward signals is critical for RL.
We find that leveraging noisy, web-extracted solutions with filtering mechanisms shows strong potential, particularly for out-of-distribution (OOD) tasks such as STEM reasoning; and (4) Core abilities like error correction are inherently present in base models, but incentivizing these skills effectively for complex tasks via RL demands significant compute, and measuring their emergence requires a nuanced approach. These insights provide practical guidance for optimizing training strategies to enhance long-term CoT reasoning in LLMs.
2.3. LIMO: Less is More for Reasoning

We present a fundamental discovery that challenges our understanding of how complex reasoning emerges in large language models. While conventional wisdom suggests that sophisticated reasoning tasks demand extensive training data (>100,000 examples), we demonstrate that complex mathematical reasoning abilities can be effectively elicited with surprisingly few examples.
Through comprehensive experiments, our proposed model LIMO demonstrates unprecedented performance in mathematical reasoning. With merely 817 curated training samples, LIMO achieves 57.1% accuracy on AIME and 94.8% on MATH, improving from previous SFT-based models’ 6.5% and 59.2% respectively, while only using 1% of the training data required by previous approaches.
LIMO demonstrates exceptional out-of-distribution generalization, achieving 40.5% absolute improvement across 10 diverse benchmarks, outperforming models trained on 100x more data, challenging the notion that SFT leads to memorization rather than generalization.
Based on these results, we propose the Less-Is-More Reasoning Hypothesis (LIMO Hypothesis): In foundation models where domain knowledge has been comprehensively encoded during pre-training, sophisticated reasoning capabilities can emerge through minimal but precisely orchestrated demonstrations of cognitive processes.
This hypothesis posits that the elicitation threshold for complex reasoning is determined by two key factors: (1) the completeness of the model’s encoded knowledge foundation during pre-training, and (2) the effectiveness of post-training examples as “cognitive templates” that show the model how to utilize its knowledge base to solve complex reasoning tasks.
2.4. Great Models Think Alike and This Undermines AI Oversight

As Language Model (LM) capabilities advance, evaluating and supervising them at scale is getting harder for humans. There is hope that other language models can automate both these tasks, which we refer to as “AI Oversight”.
We study how model similarity affects both aspects of AI oversight by proposing a probabilistic metric for LM similarity based on overlap in model mistakes. Using this metric, we first show that LLM-as-a-judge scores favor models similar to the judge, generalizing recent self-preference results.
Then, we study training on LM annotations, and find complementary knowledge between the weak supervisor and strong student model plays a crucial role in gains from “weak-to-strong generalization”. As model capabilities increase, it becomes harder to find their mistakes, and we might defer more to AI oversight.
However, we observe a concerning trend — model mistakes are becoming more similar with increasing capabilities, pointing to risks from correlated failures. Our work underscores the importance of reporting and correcting for model similarity, especially in the emerging paradigm of AI oversight.
2.5. Reward-Guided Speculative Decoding for Efficient LLM Reasoning
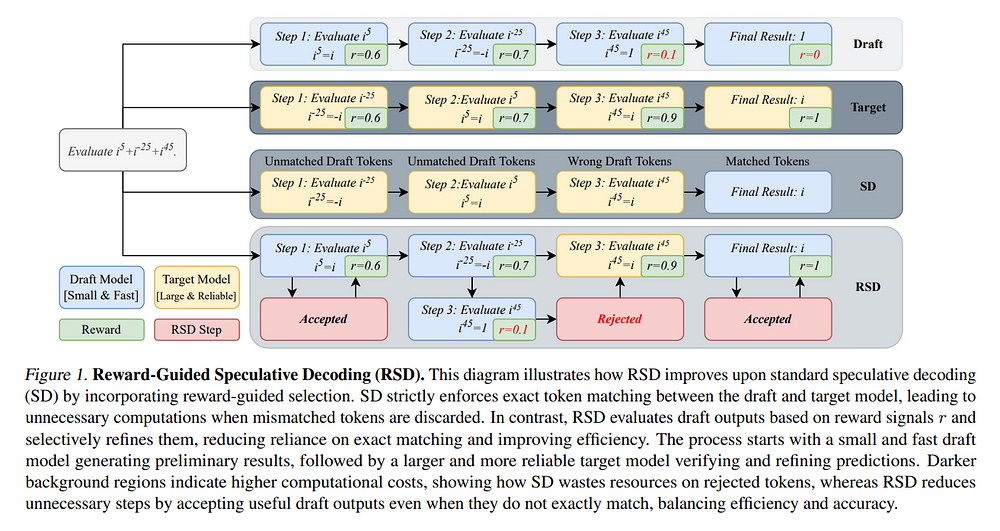
We introduce Reward-Guided Speculative Decoding (RSD), a novel framework aimed at improving the efficiency of inference in large language models (LLMs).
RSD synergistically combines a lightweight draft model with a more powerful target model, incorporating a controlled bias to prioritize high-reward outputs, in contrast to existing speculative decoding methods that enforce strict unbiasedness.
RSD employs a process reward model to evaluate intermediate decoding steps and dynamically decide whether to invoke the target model, optimizing the trade-off between computational cost and output quality. We theoretically demonstrate that a threshold-based mixture strategy achieves an optimal balance between resource utilization and performance.
Extensive evaluations on challenging reasoning benchmarks, including Olympiad-level tasks, show that RSD delivers significant efficiency gains against decoding with the target model only (up to 4.4x fewer FLOPs), while achieving significantly better accuracy than the parallel decoding method on average (up to +3.5). These results highlight RSD as a robust and cost-effective approach for deploying LLMs in resource-intensive scenarios.
2.6. MM-IQ: Benchmarking Human-Like Abstraction and Reasoning in Multimodal Models

IQ testing has served as a foundational methodology for evaluating human cognitive capabilities, deliberately decoupling assessment from linguistic background, language proficiency, or domain-specific knowledge to isolate core competencies in abstraction and reasoning.
Yet, artificial intelligence research currently lacks systematic benchmarks to quantify these critical cognitive dimensions in multimodal systems. To address this critical gap, we propose MM-IQ, a comprehensive evaluation framework comprising 2,710 meticulously curated test items spanning 8 distinct reasoning paradigms.
Through systematic evaluation of leading open-source and proprietary multimodal models, our benchmark reveals striking limitations: even state-of-the-art architectures achieve only marginally superior performance to random chance (27.49% vs. 25% baseline accuracy).
This substantial-performance chasm highlights the inadequacy of current multimodal systems in approximating fundamental human reasoning capacities, underscoring the need for paradigm-shifting advancements to bridge this cognitive divide.
2.7. Satori: Reinforcement Learning with Chain-of-Action-Thought Enhances LLM Reasoning via Autoregressive Search

Large language models (LLMs) have demonstrated remarkable reasoning capabilities across diverse domains. Recent studies have shown that increasing test-time computation enhances LLMs’ reasoning capabilities.
This typically involves extensive sampling at inference time guided by an external LLM verifier, resulting in a two-player system. Despite external guidance, the effectiveness of this system demonstrates the potential of a single LLM to tackle complex tasks.
Thus, we pose a new research problem: Can we internalize the searching capabilities to fundamentally enhance the reasoning abilities of a single LLM? This work explores an orthogonal direction focusing on post-training LLMs for autoregressive searching (i.e., an extended reasoning process with self-reflection and self-exploration of new strategies).
To achieve this, we propose the Chain-of-Action-Thought (COAT) reasoning and a two-stage training paradigm: 1) a small-scale format tuning stage to internalize the COAT reasoning format and 2) a large-scale self-improvement stage leveraging reinforcement learning.
Our approach results in Satori, a 7B LLM trained on open-source models and data. Extensive empirical evaluations demonstrate that Satori achieves state-of-the-art performance on mathematical reasoning benchmarks while exhibiting strong generalization to out-of-domain tasks. Code, data, and models will be fully open-sourced.
3. LLM Agents
3.1. Rethinking Mixture-of-Agents: Is Mixing Different Large Language Models Beneficial?

Ensembling outputs from diverse sources is a straightforward yet effective approach to boosting performance. Mixture-of-Agents (MoA) is one such popular ensemble method that aggregates outputs from multiple different Large Language Models (LLMs).
This paper raises the question in the context of language models: is mixing different LLMs truly beneficial? We propose Self-MoA — an ensemble method that aggregates outputs from only the single top-performing LLM.
Our extensive experiments reveal that, surprisingly, Self-MoA outperforms standard MoA that mixes different LLMs in a large number of scenarios: Self-MoA achieves 6.6% improvement over MoA on the AlpacaEval 2.0 benchmark, and an average of 3.8% improvement across various benchmarks, including MMLU, CRUX, and MATH.
Applying Self-MoA to one of the top-ranking models in AlpacaEval 2.0 directly achieves the new state-of-the-art performance on the leaderboard. To understand the effectiveness of Self-MoA, we systematically investigate the trade-off between diversity and quality of outputs under various MoA settings.
We confirm that the MoA performance is rather sensitive to the quality, and mixing different LLMs often lowers the average quality of the models. To complement the study, we identify the scenarios where mixing different LLMs could be helpful.
This paper further introduces a sequential version of Self-MoA, that is capable of aggregating a large number of LLM outputs on-the-fly over multiple rounds and is as effective as aggregating all outputs at once.
4. LLM Preference Optimization & Alignment
4.1. The Differences Between Direct Alignment Algorithms are a Blur
Direct Alignment Algorithms (DAAs) simplify language model alignment by replacing reinforcement learning (RL) and reward modeling (RM) in Reinforcement Learning from Human Feedback (RLHF) with direct policy optimization.
DAAs can be classified by their ranking losses (pairwise vs. pointwise), by the rewards used in those losses (e.g., likelihood ratios of policy and reference policy, or odds ratios), or by whether a Supervised Fine-Tuning (SFT) phase is required (two-stage vs. one-stage).
We first show that one-stage methods underperform two-stage methods. To address this, we incorporate an explicit SFT phase and introduce the beta parameter, controlling the strength of preference optimization, into single-stage ORPO and ASFT.
These modifications improve their performance in Alpaca Eval 2 by +3.46 (ORPO) and +8.27 (ASFT), matching two-stage methods like DPO. Further analysis reveals that the key factor is whether the approach uses pairwise or pointwise objectives, rather than the specific implicit reward or loss function.
These results highlight the importance of careful evaluation to avoid premature claims of performance gains or overall superiority in alignment algorithms.
4.2. Process Reinforcement through Implicit Rewards

Dense process rewards have proven a more effective alternative to the sparse outcome-level rewards in the inference-time scaling of large language models (LLMs), particularly in tasks requiring complex multi-step reasoning.
While dense rewards also offer an appealing choice for the reinforcement learning (RL) of LLMs since their fine-grained rewards have the potential to address some inherent issues of outcome rewards, such as training efficiency and credit assignment, this potential remains largely unrealized.
This can be primarily attributed to the challenges of training process reward models (PRMs) online, where collecting high-quality process labels is prohibitively expensive, making them particularly vulnerable to reward hacking.
To address these challenges, we propose PRIME (Process Reinforcement through IMplicit rEwards), which enables online PRM updates using only policy rollouts and outcome labels through implicit process rewards.
PRIME combines well with various advantage functions and forgoes the dedicated reward model training phase that existing approaches require, substantially reducing the development overhead.
We demonstrate PRIME’s effectiveness in competitive math and coding. Starting from Qwen2.5-Math-7B-Base, PRIME achieves a 15.1% average improvement across several key reasoning benchmarks over the SFT model.
Notably, our resulting model, Eurus-2–7B-PRIME, surpasses Qwen2.5-Math-7B-Instruct on seven reasoning benchmarks with 10% of its training data.
5. LLM Scaling & Quantization
5.1. SmolLM2: When Smol Goes Big — Data-Centric Training of a Small Language Model
While large language models have facilitated breakthroughs in many applications of artificial intelligence, their inherent largeness makes them computationally expensive and challenging to deploy in resource-constrained settings.
In this paper, we document the development of SmolLM2, a state-of-the-art “small” (1.7 billion parameters) language model (LM). To attain strong performance, we overtrain SmolLM2 on ~11 trillion tokens of data using a multi-stage training process that mixes web text with specialized math, code, and instruction-following data.
We additionally introduce new specialized datasets (FineMath, Stack-Edu, and SmolTalk) at stages where we found existing datasets to be problematically small or low-quality.
To inform our design decisions, we perform both small-scale ablations as well as a manual refinement process that updates the dataset mixing rates at each stage based on the performance at the previous stage.
Ultimately, we demonstrate that SmolLM2 outperforms other recent small LMs including Qwen2.5–1.5B and Llama3.2–1B. To facilitate future research on LM development as well as applications of small LMs, we release both SmolLM2 as well as all of the datasets we prepared in the course of this project.
5.2. Self-supervised Quantized Representation for Seamlessly Integrating Knowledge Graphs with Large Language Models

Due to the presence of the natural gap between Knowledge Graph (KG) structures and the natural language, the effective integration of holistic structural information of KGs with Large Language Models (LLMs) has emerged as a significant question.
To this end, we propose a two-stage framework to learn and apply quantized codes for each entity, aiming for the seamless integration of KGs with LLMs. Firstly, a self-supervised quantized representation (SSQR) method is proposed to compress both KG structural and semantic knowledge into discrete codes (\ie, tokens) that align the format of language sentences.
We further design KG instruction-following data by viewing these learned codes as features to directly input to LLMs, thereby achieving seamless integration. The experiment results demonstrate that SSQR outperforms existing unsupervised quantized methods, producing more distinguishable codes.
Further, the fine-tuned LLaMA2 and LLaMA3.1 also have superior performance on KG link prediction and triple classification tasks, utilizing only 16 tokens per entity instead of thousands in conventional prompting methods.
5.3. Llasa: Scaling Train-Time and Inference-Time Compute for Llama-based Speech Synthesis
Recent advances in text-based large language models (LLMs), particularly in the GPT series and the o1 model, have demonstrated the effectiveness of scaling both training-time and inference-time computing.
However, current state-of-the-art TTS systems leveraging LLMs are often multi-stage, requiring separate models (e.g., diffusion models after LLM), complicating the decision of whether to scale a particular model during training or testing.
This work makes the following contributions: First, we explore the scaling of train-time and inference-time compute for speech synthesis. Second, we propose a simple framework Llasa for speech synthesis that employs a single-layer vector quantizer (VQ) codec and a single Transformer architecture to fully align with standard LLMs such as Llama.
Our experiments reveal that scaling train-time computing for Llasa consistently improves the naturalness of synthesized speech and enables the generation of more complex and accurate prosody patterns.
Furthermore, from the perspective of scaling inference-time compute, we employ speech understanding models as verifiers during the search, finding that scaling inference-time compute shifts the sampling modes toward the preferences of specific verifiers, thereby improving emotional expressiveness, timbre consistency, and content accuracy.
In addition, we released the checkpoint and training code for our TTS model (1B, 3B, 8B) and codec model publicly available.
5.4. s1: Simple test-time scaling

Test-time scaling is a promising new approach to language modeling that uses extra test-time computing to improve performance. Recently, OpenAI’s o1 model showed this capability but did not publicly share its methodology, leading to many replication efforts.
We seek the simplest approach to achieve test-time scaling and strong reasoning performance. First, we curate a small dataset s1K of 1,000 questions paired with reasoning traces relying on three criteria we validate through ablations: difficulty, diversity, and quality.
Second, we develop budget forcing to control test-time computing by forcefully terminating the model’s thinking process or lengthening it by appending “Wait” multiple times to the model’s generation when it tries to end.
This can lead the model to double-check its answer, often fixing incorrect reasoning steps. After supervised fine-tuning the Qwen2.5–32B-Instruct language model on s1K and equipping it with budget forcing, our model s1 exceeds o1-preview on competition math questions by up to 27% (MATH and AIME24).
Further, scaling s1 with budget forcing allows extrapolating beyond its performance without test-time intervention: from 50% to 57% on AIME24.
6. LLM Safety & Security
6.1. On Teacher Hacking in Language Model Distillation

Post-training of language models (LMs) increasingly relies on the following two stages: (i) knowledge distillation, where the LM is trained to imitate a larger teacher LM, and (ii) reinforcement learning from human feedback (RLHF), where the LM is aligned by optimizing a reward model.
In the second RLHF stage, a well-known challenge is reward hacking, where the LM over-optimizes the reward model. Such a phenomenon is in line with Goodhart’s law and can lead to degraded performance on the true objective. In this paper, we investigate whether a similar phenomenon, which we call teacher hacking, can occur during knowledge distillation.
This could arise because the teacher LM is itself an imperfect approximation of the true distribution. To study this, we propose a controlled experimental setup involving: (i) an oracle LM representing the ground-truth distribution, (ii) a teacher LM distilled from the oracle, and (iii) a student LM distilled from the teacher. Our experiments reveal the following insights.
When using a fixed offline dataset for distillation, teacher hacking occurs; moreover, we can detect it by observing when the optimization process deviates from polynomial convergence laws.
In contrast, employing online data generation techniques effectively mitigates teacher hacking. More precisely, we identify data diversity as the key factor in preventing hacking. Overall, our findings provide a deeper understanding of the benefits and limitations of distillation for building robust and efficient LMs.
6.2. Constitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming

Large language models (LLMs) are vulnerable to universal jailbreak-prompting strategies that systematically bypass model safeguards and enable users to carry out harmful processes that require many model interactions, like manufacturing illegal substances at scale.
To defend against these attacks, we introduce Constitutional Classifiers: safeguards trained on synthetic data, generated by prompting LLMs with natural language rules (i.e., a constitution) specifying permitted and restricted content.
In over 3,000 estimated hours of red teaming, no red teamer found a universal jailbreak that could extract information from an early classifier-guarded LLM at a similar level of detail to an unguarded model across most target queries.
On automated evaluations, enhanced classifiers demonstrated robust defense against held-out domain-specific jailbreaks. These classifiers also maintain deployment viability, with an absolute 0.38% increase in production traffic refusals and a 23.7% inference overhead.
Our work demonstrates that defending against universal jailbreaks while maintaining practical deployment viability is tractable.
7. Retrieval Augmented Generation (RAG)
7.1. DeepRAG: Thinking to Retrieval Step by Step for Large Language Models

Large Language Models (LLMs) have shown remarkable potential in reasoning while they still suffer from severe factual hallucinations due to timeliness, accuracy, and coverage of parametric knowledge.
Meanwhile, integrating reasoning with retrieval-augmented generation (RAG) remains challenging due to ineffective task decomposition and redundant retrieval, which can introduce noise and degrade response quality.
In this paper, we propose DeepRAG, a framework that models retrieval-augmented reasoning as a Markov Decision Process (MDP), enabling strategic and adaptive retrieval.
By iteratively decomposing queries, DeepRAG dynamically determines whether to retrieve external knowledge or rely on parametric reasoning at each step. Experiments show that DeepRAG improves retrieval efficiency while improving answer accuracy by 21.99%, demonstrating its effectiveness in optimizing retrieval-augmented reasoning.
7.2. SafeRAG: Benchmarking Security in Retrieval-Augmented Generation of Large Language Model

The indexing-retrieval-generation paradigm of retrieval-augmented generation (RAG) has been highly successful in solving knowledge-intensive tasks by integrating external knowledge into large language models (LLMs).
However, the incorporation of external and unverified knowledge increases the vulnerability of LLMs because attackers can perform attack tasks by manipulating knowledge. In this paper, we introduce a benchmark named SafeRAG designed to evaluate RAG security.
First, we classify attack tasks into silver noise, inter-context conflict, soft ad, and white Denial-of-Service. Next, we construct the RAG security evaluation dataset (i.e., SafeRAG dataset) primarily manually for each task. We then utilize the SafeRAG dataset to simulate various attack scenarios that RAG may encounter.
Experiments conducted on 14 representative RAG components demonstrate that RAG exhibits significant vulnerability to all attack tasks and even the most apparent attack task can easily bypass existing retrievers, filters, or advanced LLMs, resulting in the degradation of RAG service quality.
8. Attention Models
8.1. Scalable-Softmax Is Superior for Attention
The maximum element of the vector output by the Softmax function approaches zero as the input vector size increases. Transformer-based language models rely on Softmax to compute attention scores, causing the attention distribution to flatten as the context size grows.
This reduces the model’s ability to prioritize key information effectively and potentially limits its length of generalization. To address this problem, we propose Scalable-Softmax (SSMax), which replaces Softmax in scenarios where the input vector size varies.
SSMax can be seamlessly integrated into existing Transformer-based architectures. Experimental results in language modeling show that models using SSMax not only achieve faster loss reduction during pretraining but also significantly improve performance in long contexts and key information retrieval.
Furthermore, an analysis of attention scores reveals that SSMax enables the model to focus attention on key information even in long contexts.
Additionally, although models that use SSMax from the beginning of pretraining achieve better length generalization, those that have already started pretraining can still gain some of this ability by replacing Softmax in the attention layers with SSMax, either during or after pretraining.
8.2. FastKV: KV Cache Compression for Fast Long-Context Processing with Token-Selective Propagation
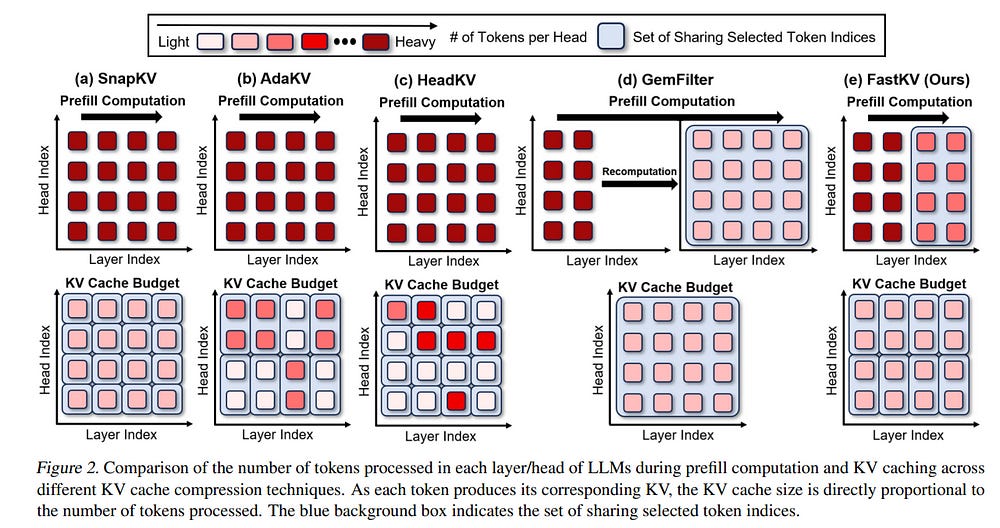
While large language models (LLMs) excel at handling long-context sequences, they require substantial key-value (KV) caches to store contextual information, which can heavily burden computational efficiency and memory usage.
Previous efforts to compress these KV caches primarily focused on reducing memory demands but were limited in enhancing latency. To address this issue, we introduce FastKV, a KV cache compression method designed to enhance latency for long-context sequences.
To enhance processing speeds while maintaining accuracy, FastKV adopts a novel Token-Selective Propagation (TSP) approach that retains the full context information in the initial layers of LLMs and selectively propagates only a portion of this information in deeper layers even in the prefill stage.
Additionally, FastKV incorporates grouped-query attention (GQA)--aware KV cache compression to exploit the advantages of GQA in both memory and computational efficiency.
Our experimental results show that FastKV achieves 2.00 times and 1.40 times improvements in time-to-first-token (TTFT) and throughput, respectively, compared to HeadKV, the state-of-the-art KV cache compression method.
Moreover, FastKV successfully maintains accuracy on long-context benchmarks at levels comparable to the baselines.
8.3. Can LLMs Maintain Fundamental Abilities under KV Cache Compression?

This paper investigates an under-explored challenge in large language models (LLMs): the impact of KV cache compression methods on LLMs’ fundamental capabilities.
While existing methods achieve impressive compression ratios on long-context benchmarks, their effects on core model capabilities remain understudied.
We present a comprehensive empirical study evaluating prominent KV cache compression methods across diverse tasks, spanning world knowledge, commonsense reasoning, arithmetic reasoning, code generation, safety, and long-context understanding and generation.
Our analysis reveals that KV cache compression methods exhibit task-specific performance degradation. Arithmetic reasoning tasks prove particularly sensitive to aggressive compression, with different methods showing performance drops of 17.4%-43.3%.
Notably, the DeepSeek R1 Distill model exhibits more robust compression tolerance compared to instruction-tuned models, showing only 9.67%-25.53% performance degradation.
Based on our analysis of attention patterns and cross-task compression performance, we propose ShotKV, a novel compression approach that distinctly handles prefill and decoding phases while maintaining shot-level semantic coherence.
Empirical results show that ShotKV achieves 9%-18% performance improvements on long-context generation tasks under aggressive compression ratios.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
