


Important LLMs Papers for the Week from 15/07 to 21/07
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Third Week of July 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Training, Evaluation & Inference
Transformer Based Models
LLM Quantization
LLM Reasoning
LLM Safety & Alignment
Most insights I share in Medium have previously been shared in my weekly newsletter, To Data & Beyond.
If you want to be up-to-date with the frenetic world of AI while also feeling inspired to take action or, at the very least, to be well-prepared for the future ahead of us, this is for you.
🏝Subscribe below🏝 to become an AI leader among your peers and receive content not present in any other platform, including Medium:
To Data & Beyond | Youssef Hosni | Substack
Data Science, Machine Learning, AI, and what is beyond them. Click to read To Data & Beyond, by Youssef Hosni, a…youssefh.substack.com
1. LLM Progress & Benchmarking
1.1. SpreadsheetLLM: Encoding Spreadsheets for Large Language Models

Spreadsheets, with their extensive two-dimensional grids, various layouts, and diverse formatting options, present notable challenges for large language models (LLMs).
In response, we introduce SpreadsheetLLM, pioneering an efficient encoding method designed to unleash and optimize LLMs’ powerful understanding and reasoning capability on spreadsheets. Initially, we propose a vanilla serialization approach that incorporates cell addresses, values, and formats.
However, this approach was limited by LLMs’ token constraints, making it impractical for most applications. To tackle this challenge, we develop SheetCompressor, an innovative encoding framework that compresses spreadsheets effectively for LLMs.
It comprises three modules: structural-anchor-based compression, inverse index translation, and data-format-aware aggregation. It significantly improves performance in spreadsheet table detection tasks, outperforming the vanilla approach by 25.6% in GPT4’s in-context learning setting.
Moreover, fine-tuned LLM with SheetCompressor has an average compression ratio of 25 times, but achieves a state-of-the-art 78.9% F1 score, surpassing the best existing models by 12.3%.
Finally, we propose a Chain of Spreadsheets for downstream tasks of spreadsheet understanding and validation in a new and demanding spreadsheet QA task. We methodically leverage the inherent layout and structure of spreadsheets, demonstrating that SpreadsheetLLM is highly effective across a variety of spreadsheet tasks.
1.2. Human-like Episodic Memory for Infinite Context LLMs

Large language models (LLMs) have shown remarkable capabilities, but still struggle with processing extensive contexts, limiting their ability to maintain coherence and accuracy over long sequences. In contrast, the human brain excels at organizing and retrieving episodic experiences across vast temporal scales, spanning a lifetime.
In this work, we introduce EM-LLM, a novel approach that integrates key aspects of human episodic memory and event cognition into LLMs, enabling them to effectively handle practically infinite context lengths while maintaining computational efficiency.
EM-LLM organizes sequences of tokens into coherent episodic events using a combination of Bayesian surprise and graph-theoretic boundary refinement in an online fashion. When needed, these events are retrieved through a two-stage memory process, combining similarity-based and temporally contiguous retrieval for efficient and human-like access to relevant information.
Experiments on the LongBench dataset demonstrate EM-LLM’s superior performance, outperforming the state-of-the-art InfLLM model with an overall relative improvement of 4.3% across various tasks, including a 33% improvement on the PassageRetrieval task.
Furthermore, our analysis reveals strong correlations between EM-LLM’s event segmentation and human-perceived events, suggesting a bridge between this artificial system and its biological counterpart.
This work not only advances LLM capabilities in processing extended contexts but also provides a computational framework for exploring human memory mechanisms, opening new avenues for interdisciplinary research in AI and cognitive science.
1.3. MUSCLE: A Model Update Strategy for Compatible LLM Evolution

Large Language Models (LLMs) are frequently updated due to data or architecture changes to improve their performance. When updating models, developers often focus on increasing overall performance metrics with less emphasis on being compatible with previous model versions.
However, users often build a mental model of the functionality and capabilities of a particular machine-learning model they are interacting with. They have to adapt their mental model with every update — a draining task that can lead to user dissatisfaction.
In practice, fine-tuned downstream task adapters rely on pretrained LLM base models. When these base models are updated, these user-facing downstream task models experience instance regression or negative flips — previously correct instances are now predicted incorrectly.
This happens even when the downstream task training procedures remain identical. Our work aims to provide seamless model updates to a user in two ways.
First, we provide evaluation metrics for a notion of compatibility to prior model versions, specifically for generative tasks but also applicable for discriminative tasks. We observe regression and inconsistencies between different model versions on a diverse set of tasks and model updates.
Second, we propose a training strategy to minimize the number of inconsistencies in model updates, involving training of a compatibility model that can enhance task fine-tuned language models.
We reduce negative flips — instances where a prior model version was correct, but a new model was incorrect — by up to 40% from Llama 1 to Llama 2.
1.4. Qwen2 Technical Report

This report introduces the Qwen2 series, the latest addition to our large language models and large multimodal models. We release a comprehensive suite of foundational and instruction-tuned language models, encompassing a parameter range from 0.5 to 72 billion, featuring dense models and a Mixture-of-Experts model.
Qwen2 surpasses most prior open-weight models, including its predecessor Qwen1.5, and exhibits competitive performance relative to proprietary models across diverse benchmarks on language understanding, generation, multilingual proficiency, coding, mathematics, and reasoning.
The flagship model, Qwen2–72B, showcases remarkable performance: 84.2 on MMLU, 37.9 on GPQA, 64.6 on HumanEval, 89.5 on GSM8K, and 82.4 on BBH as a base language model. The instruction-tuned variant, Qwen2–72B-Instruct, attains 9.1 on MT-Bench, 48.1 on Arena-Hard, and 35.7 on LiveCodeBench.
Moreover, Qwen2 demonstrates robust multilingual capabilities, proficient in approximately 30 languages, spanning English, Chinese, Spanish, French, German, Arabic, Russian, Korean, Japanese, Thai, Vietnamese, and more, underscoring its versatility and global reach.
To foster community innovation and accessibility, we have made the Qwen2 model weights openly available on Hugging Face1 and ModelScope2, and the supplementary materials including example code on GitHub3.
These platforms also include resources for quantization, fine-tuning, and deployment, facilitating a wide range of applications and research endeavors.
1.5. Q-Sparse: All Large Language Models can be Fully Sparsely-Activated

We introduce, Q-Sparse, a simple yet effective approach to training sparsely-activated large language models (LLMs). Q-Sparse enables full sparsity of activations in LLMs which can bring significant efficiency gains in inference.
This is achieved by applying top-K sparsification to the activations and the straight-through-estimator to the training. The key results from this work are:
Q-Sparse can achieve results comparable to those of baseline LLMs while being much more efficient at inference time
We present an inference-optimal scaling law for sparsely-activated LLMs
Q-Sparse is effective in different settings, including training from scratch, continue-training of off-the-shelf LLMs, and fine-tuning
Q-Sparse works for both full-precision and 1-bit LLMs (e.g., BitNet b1.58).
Particularly, the synergy of BitNet b1.58 and Q-Sparse (can be equipped with MoE) provides the cornerstone and a clear path to revolutionize the efficiency, including cost and energy consumption, of future LLMs.
1.6. Benchmarking Trustworthiness of Multimodal Large Language Models: A Comprehensive Study

Despite the superior capabilities of Multimodal Large Language Models (MLLMs) across diverse tasks, they still face significant trustworthiness challenges.
Yet, current literature on the assessment of trustworthy MLLMs remains limited, lacking a holistic evaluation to offer thorough insights into future improvements. In this work, we establish MultiTrust, the first comprehensive and unified benchmark on the trustworthiness of MLLMs across five primary aspects: truthfulness, safety, robustness, fairness, and privacy.
Our benchmark employs a rigorous evaluation strategy that addresses both multimodal risks and cross-modal impacts, encompassing 32 diverse tasks with self-curated datasets. Extensive experiments with 21 modern MLLMs reveal some previously unexplored trustworthiness issues and risks, highlighting the complexities introduced by multimodality and underscoring the necessity for advanced methodologies to enhance their reliability.
For instance, typical proprietary models still struggle with the perception of visually confusing images and are vulnerable to multimodal jailbreaking and adversarial attacks; MLLMs are more inclined to disclose privacy in text and reveal ideological and cultural biases even when paired with irrelevant images in inference, indicating that the multimodality amplifies the internal risks from base LLMs.
1.7. NeedleBench: Can LLMs Do Retrieval and Reasoning in 1 Million Context Window?
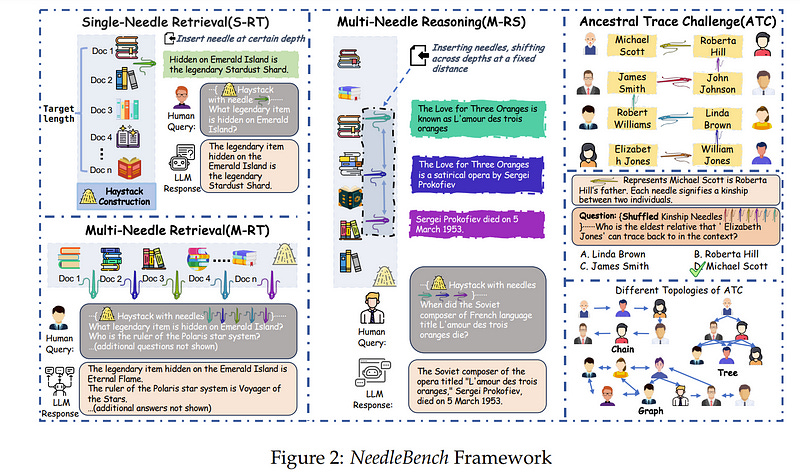
In evaluating the long-context capabilities of large language models (LLMs), identifying content relevant to a user’s query from original long documents is a crucial prerequisite for any LLM to answer questions based on long text.
We present NeedleBench, a framework consisting of a series of progressively more challenging tasks for assessing bilingual long-context capabilities, spanning multiple length intervals (4k, 8k, 32k, 128k, 200k, 1000k, and beyond) and different depth ranges, allowing the strategic insertion of critical data points in different text depth zones to rigorously test the retrieval and reasoning capabilities of models in diverse contexts.
We use the NeedleBench framework to assess how well the leading open-source models can identify key information relevant to the question and apply that information to reasoning in bilingual long texts.
Furthermore, we propose the Ancestral Trace Challenge (ATC) to mimic the complexity of logical reasoning challenges that are likely to be present in real-world long-context tasks, providing a simple method for evaluating LLMs in dealing with complex long-context situations.
Our results suggest that current LLMs have significant room for improvement in practical long-context applications, as they struggle with the complexity of logical reasoning challenges that are likely to be present in real-world long-context tasks.
1.8. Scaling Retrieval-Based Language Models with a Trillion-Token Datastore

Scaling laws with respect to the amount of training data and the number of parameters allow us to predict the cost-benefit trade-offs of pretraining language models (LMs) in different configurations. In this paper, we consider another dimension of scaling: the amount of data available at inference time.
Specifically, we find that increasing the size of the datastore used by a retrieval-based LM monotonically improves language modeling and several downstream tasks without obvious saturation, such that a smaller model augmented with a large datastore outperforms a larger LM-only model on knowledge-intensive tasks.
By plotting compute-optimal scaling curves with varied datastore, model, and pretraining data sizes, we show that using larger datastores can significantly improve model performance for the same training compute budget.
We carry out our study by constructing a 1.4 trillion-token datastore named MassiveDS, which is the largest and the most diverse open-sourced datastore for retrieval-based LMs to date, and designing an efficient pipeline for studying datastore scaling in a computationally accessible manner.
Finally, we analyze the effect of improving the retriever, datastore quality filtering, and other design choices on our observed scaling trends. Overall, our results show that data store size should be considered an integral part of LM efficiency and performance trade-offs.
1.9. E5-V: Universal Embeddings with Multimodal Large Language Models

Multimodal large language models (MLLMs) have shown promising advancements in general visual and language understanding. However, the representation of multimodal information using MLLMs remains largely unexplored. In this work, we introduce a new framework, E5-V, designed to adapt MLLMs for achieving universal multimodal embeddings.
Our findings highlight the significant potential of MLLMs in representing multimodal inputs compared to previous approaches. By leveraging MLLMs with prompts, E5-V effectively bridges the modality gap between different types of inputs, demonstrating strong performance in multimodal embeddings even without fine-tuning.
We propose a single modality training approach for E5-V, where the model is trained exclusively on text pairs. This method demonstrates significant improvements over traditional multimodal training on image-text pairs, while reducing training costs by approximately 95%. Additionally, this approach eliminates the need for costly multimodal training data collection.
Extensive experiments across four types of tasks demonstrate the effectiveness of E5-V. As a universal multimodal model, E5-V not only achieves but often surpasses state-of-the-art performance in each task, despite being trained on a single modality.
1.10. Scaling Laws with Vocabulary: Larger Models Deserve Larger Vocabularies
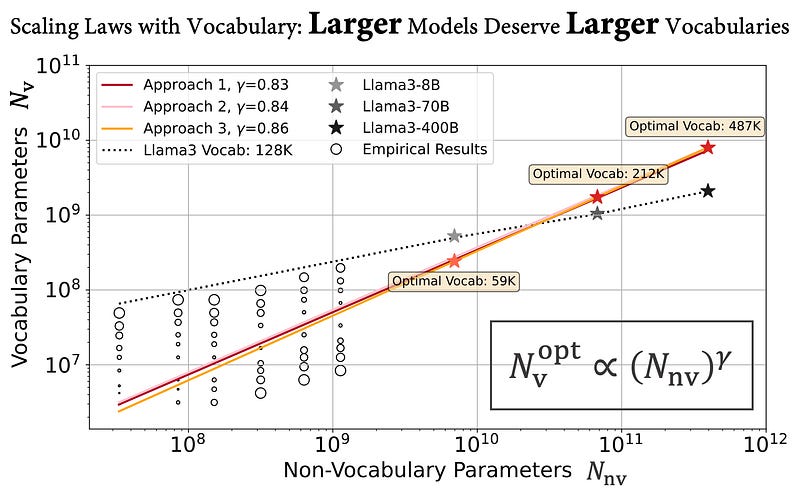
Research on scaling large language models (LLMs) has primarily focused on model parameters and training data size, overlooking the role of vocabulary size. % Intuitively, larger vocabularies enable more efficient tokenization by representing sentences with fewer tokens, but they also increase the risk of under-fitting representations for rare tokens.
We investigate how vocabulary size impacts LLM scaling laws by training models ranging from 33M to 3B parameters on up to 500B characters with various vocabulary configurations. We propose three complementary approaches for predicting the compute-optimal vocabulary size: IsoFLOPs analysis, derivative estimation, and parametric fit of the loss function.
Our approaches converge on the same result that the optimal vocabulary size depends on the available compute budget and that larger models deserve larger vocabularies. However, most LLMs use too small vocabulary sizes.
For example, we predict that the optimal vocabulary size of Llama2–70B should have been at least 216K, 7 times larger than its vocabulary of 32K. We validate our predictions empirically by training models with 3B parameters across different FLOP budgets.
Adopting our predicted optimal vocabulary size consistently improves downstream performance over commonly used vocabulary sizes. By increasing the vocabulary size from the conventional 32K to 43K, we improve performance on ARC-Challenge from 29.1 to 32.0 with the same 2.3e21 FLOPs. Our work emphasizes the necessity of jointly considering model parameters and vocabulary size for efficient scaling.
2. LLM Training, Evaluation & Inference
2.1. Benchmark Agreement Testing Done Right: A Guide for LLM Benchmark Evaluation

Recent advancements in Language Models (LMs) have catalyzed the creation of multiple benchmarks, designed to assess these models’ general capabilities. A crucial task, however, is assessing the validity of the benchmarks themselves.
This is most commonly done via Benchmark Agreement Testing (BAT), where new benchmarks are validated against established ones using some agreement metric (e.g., rank correlation). Despite the crucial role of BAT for benchmark builders and consumers, there are no standardized procedures for such agreement testing.
This deficiency can lead to invalid conclusions, fostering mistrust in benchmarks and upending the ability to properly choose the appropriate benchmark to use. By analyzing over 40 prominent benchmarks, we demonstrate how some overlooked methodological choices can significantly influence BAT results, potentially undermining the validity of conclusions.
To address these inconsistencies, we propose a set of best practices for BAT and demonstrate how utilizing these methodologies greatly improves BAT robustness and validity. To foster adoption and facilitate future research, we introduce BenchBench, a Python package for BAT, and release the BenchBench leaderboard, a meta-benchmark designed to evaluate benchmarks using their peers.
Our findings underscore the necessity for standardized BAT, ensuring the robustness and validity of benchmark evaluations in the evolving landscape of language model research.
2.2. The Good, The Bad, and The Greedy: Evaluation of LLMs Should Not Ignore Non-Determinism

Current evaluations of large language models (LLMs) often overlook non-determinism, typically focusing on a single output per example. This limits our understanding of LLM performance variability in real-world applications.
Our study addresses this issue by exploring key questions about the performance differences between greedy decoding and sampling, identifying benchmarks’ consistency regarding non-determinism, and examining unique model behaviors.
Through extensive experiments, we observe that greedy decoding generally outperforms sampling methods for most evaluated tasks. We also observe consistent performance across different LLM sizes and alignment methods, noting that alignment can reduce sampling variance.
Moreover, our best-of-N sampling approach demonstrates that smaller LLMs can match or surpass larger models such as GPT-4-Turbo, highlighting the untapped potential of smaller LLMs. This research shows the importance of considering non-determinism in LLM evaluations and provides insights for future LLM development and evaluation.
2.3. Foundational Autoraters: Taming Large Language Models for Better Automatic Evaluation

As large language models (LLMs) advance, it becomes more challenging to reliably evaluate their output due to the high costs of human evaluation. To make progress toward better LLM autoraters, we introduce FLAMe, a family of Foundational Large Autorater Models.
FLAMe is trained on our large and diverse collection of 100+ quality assessment tasks comprising 5M+ human judgments, curated and standardized using publicly released human evaluations from previous research. FLAMe significantly improves generalization to a wide variety of held-out tasks, outperforming LLMs trained on proprietary data like GPT-4 and Claude-3 on many tasks.
We show that FLAMe can also serve as a powerful starting point for further downstream fine-tuning, using reward modeling evaluation as a case study (FLAMe-RM). Notably, on RewardBench, our FLAMe-RM-24B model (with an accuracy of 87.8%) is the top-performing generative model trained exclusively on permissively licensed data, outperforming both GPT-4–0125 (85.9%) and GPT-4o (84.7%).
Additionally, we explore a more computationally efficient approach using a novel tail-patch fine-tuning strategy to optimize our FLAMe multitask mixture for reward modeling evaluation (FLAMe-Opt-RM), offering competitive RewardBench performance while requiring approximately 25x fewer training data points.
Overall, our FLAMe variants outperform all popular proprietary LLM-as-a-Judge models we consider across 8 out of 12 autorater evaluation benchmarks, encompassing 53 quality assessment tasks, including RewardBench and LLM-AggreFact.
Finally, our analysis reveals that FLAMe is significantly less biased than these LLM-as-a-Judge models on the CoBBLEr autorater bias benchmark, while effectively identifying high-quality responses for code generation.
2.4. FIRE: A Dataset for Feedback Integration and Refinement Evaluation of Multimodal Models

Vision language models (VLMs) have achieved impressive progress in diverse applications, becoming a prevalent research direction. In this paper, we build FIRE, a feedback-refinement dataset, consisting of 1.1M multi-turn conversations that are derived from 27 source datasets, empowering VLMs to spontaneously refine their responses based on user feedback across diverse tasks.
To scale up the data collection, FIRE is collected in two components: FIRE-100K and FIRE-1M, where FIRE-100K is generated by GPT-4V and FIRE-1M is freely generated via models trained on FIRE-100K.
Then, we build FIRE-Bench, a benchmark to comprehensively evaluate the feedback-refining capability of VLMs, which contains 11K feedback-refinement conversations as the test data, two evaluation settings, and a model to provide feedback for VLMs.
We develop the FIRE-LLaVA model by fine-tuning LLaVA on FIRE-100K and FIRE-1M, which shows remarkable feedback-refining capability on FIRE-Bench and outperforms untrained VLMs by 50%, making more efficient user-agent interactions and underscoring the significance of the FIRE dataset.
2.5. VLMEvalKit: An Open-Source Toolkit for Evaluating Large Multi-Modality Models

We present VLMEvalKit: an open-source toolkit for evaluating large multi-modality models based on PyTorch. The toolkit aims to provide a user-friendly and comprehensive framework for researchers and developers to evaluate existing multi-modality models and publish reproducible evaluation results.
In VLMEvalKit, we implement over 70 different large multi-modality models, including both proprietary APIs and open-source models, as well as more than 20 different multi-modal benchmarks. By implementing a single interface, new models can be easily added to the toolkit, while the toolkit automatically handles the remaining workloads, including data preparation, distributed inference, prediction post-processing, and metric calculation.
Although the toolkit is currently mainly used for evaluating large vision-language models, its design is compatible with future updates that incorporate additional modalities, such as audio and video. Based on the evaluation results obtained with the toolkit, we host OpenVLM Leaderboard, a comprehensive leaderboard to track the progress of multi-modality learning research.
2.6. LMMs-Eval: Reality Check on the Evaluation of Large Multimodal Models
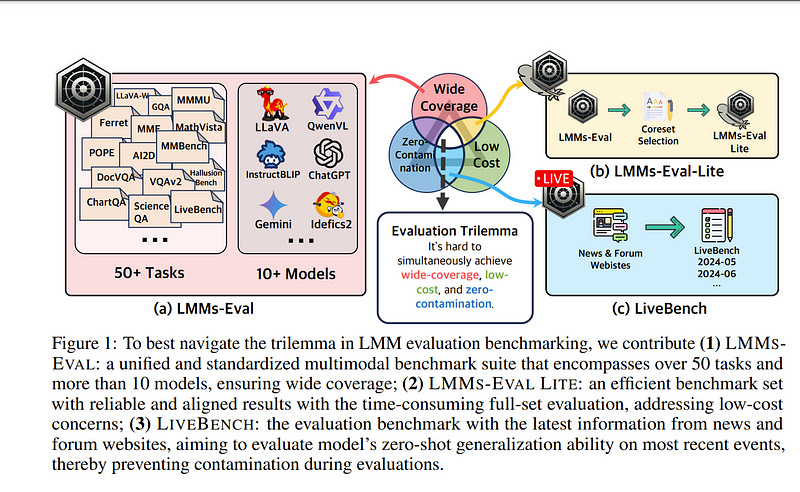
The advances of large foundation models necessitate wide coverage, low cost, and zero-contamination benchmarks. Despite continuous exploration of language model evaluations, comprehensive studies on the evaluation of Large Multi-modal Models (LMMs) remain limited.
In this work, we introduce LMMS-EVAL, a unified and standardized multimodal benchmark framework with over 50 tasks and more than 10 models to promote transparent and reproducible evaluations. Although LMMS-EVAL offers comprehensive coverage, we find it still falls short in achieving low cost and zero contamination.
To approach this evaluation trilemma, we further introduce LMMS-EVAL LITE, a pruned evaluation toolkit that emphasizes both coverage and efficiency.
Additionally, we present Multimodal LIVEBENCH that utilizes continuously updating news and online forums to assess models’ generalization abilities in the wild, featuring a low-cost and zero-contamination evaluation approach.
In summary, our work highlights the importance of considering the evaluation trilemma and provides practical solutions to navigate the trade-offs in evaluating large multi-modal models, paving the way for more effective and reliable benchmarking of LMMs.
3. Transformer-Based Models
3.1. Toto: Time Series Optimized Transformer for Observability

This technical report describes the Time Series Optimized Transformer for Observability (Toto), a new state-of-the-art foundation model for time series forecasting developed by Datadog.
In addition to advancing the state of the art on generalized time series benchmarks in domains such as electricity and weather, this model is the first general-purpose time series forecasting foundation model to be specifically tuned for observability metrics.
Toto was trained on a dataset of one trillion time series data points, the largest among all currently published time series foundation models. Alongside publicly available time series datasets, 75% of the data used to train Toto consists of fully anonymous numerical metric data points from the Datadog platform.
In our experiments, Toto outperforms existing time series foundation models on observability data. It does this while also excelling at general-purpose forecasting tasks, achieving state-of-the-art zero-shot performance on multiple open benchmark datasets.
4. LLM Quantization
4.1. Spectra: A Comprehensive Study of Ternary, Quantized, and FP16 Language Models

Post-training quantization is the leading method for addressing memory-related bottlenecks in LLM inference, but unfortunately, it suffers from significant performance degradation below 4-bit precision. An alternative approach involves training compressed models directly at a low bandwidth (e.g., binary or ternary models).
However, the performance, training dynamics, and scaling trends of such models are not yet well understood. To address this issue, we train and openly release the Spectra LLM suite consisting of 54 language models ranging from 99M to 3.9B parameters, trained on 300B tokens.
Spectra include FloatLMs, post-training quantized QuantLMs (3, 4, 6, and 8 bits), and ternary LLMs (TriLMs) — our improved architecture for ternary language modeling, which significantly outperforms previously proposed ternary models of a given size (in bits), matching half-precision models at scale.
For example, TriLM 3.9B is (bit-wise) smaller than the half-precision FloatLM 830M, but matches half-precision FloatLM 3.9B in commonsense reasoning and knowledge benchmarks. However, TriLM 3.9B is also as toxic and stereotyping as FloatLM 3.9B, a model six times larger in size.
Additionally, TriLM 3.9B lags behind FloatLM in perplexity on validation splits and web-based corpora but performs better on less noisy datasets like Lambada and PennTreeBank.
5. LLM Reasoning
5.1. Sibyl: Simple yet Effective Agent Framework for Complex Real-world Reasoning

/*Existing agents based on large language models (LLMs) demonstrate robust problem-solving capabilities by integrating LLMs’ inherent knowledge, strong in-context learning and zero-shot capabilities, and the use of tools combined with intricately designed LLM invocation workflows by humans.
However, these agents still exhibit shortcomings in long-term reasoning and under-use the potential of existing tools, leading to noticeable deficiencies in complex real-world reasoning scenarios. To address these limitations, we introduce Sibyl, a simple yet powerful LLM-based agent framework designed to tackle complex reasoning tasks by efficiently leveraging a minimal set of tools.
Drawing inspiration from Global Workspace Theory, Sibyl incorporates a global workspace to enhance the management and sharing of knowledge and conversation history throughout the system.
Furthermore, guided by the Society of Mind Theory, Sibyl implements a multi-agent debate-based jury to self-refine the final answers, ensuring a comprehensive and balanced approach.
This approach aims to reduce system complexity while expanding the scope of problems solvable from matters typically resolved by humans in minutes to those requiring hours or even days, thus facilitating a shift from System-1 to System-2 thinking.
Sibyl has been designed with a focus on scalability and ease of debugging by incorporating the concept of reentrancy from functional programming from its inception, with the aim of seamless and low-effort integration in other LLM applications to improve capabilities.
Our experimental results on the GAIA benchmark test set reveal that the Sibyl agent instantiated with GPT-4 achieves state-of-the-art performance with an average score of 34.55%, compared to other agents based on GPT-4. We hope that Sibyl can inspire more reliable and reusable LLM-based agent solutions to address complex real-world reasoning tasks.
6. LLM Safety & Alignment
6.1. Refuse Whenever You Feel Unsafe: Improving Safety in LLMs via Decoupled Refusal Training

This study addresses a critical gap in safety tuning practices for Large Language Models (LLMs) by identifying and tackling a refusal position bias within safety tuning data, which compromises the models’ ability to appropriately refuse to generate unsafe content.
We introduce a novel approach, Decoupled Refusal Training (DeRTa), designed to empower LLMs to refuse compliance to harmful prompts at any response position, significantly enhancing their safety capabilities. DeRTa incorporates two novel components:
Maximum Likelihood Estimation (MLE) with Harmful Response Prefix, which trains models to recognize and avoid unsafe content by appending a segment of harmful response to the beginning of a safe response
Reinforced Transition Optimization (RTO), which equips models with the ability to transition from potential harm to safety refusal consistently throughout the harmful response sequence.
Our empirical evaluation, conducted using LLaMA3 and Mistral model families across six attack scenarios, demonstrates that our method not only improves model safety without compromising performance but also surpasses well-known models such as GPT-4 in defending against attacks. Importantly, our approach successfully defends recent advanced attack methods (e.g., CodeAttack) that have jailbroken GPT-4 and LLaMA3–70B-Instruct.
6.2. Learning to Refuse: Towards Mitigating Privacy Risks in LLMs

Large language models (LLMs) exhibit remarkable capabilities in understanding and generating natural language. However, these models can inadvertently memorize private information, posing significant privacy risks.
This study addresses the challenge of enabling LLMs to protect specific individuals’ private data without the need for complete retraining. We propose \return, a Real-world pErsonal daTa UnleaRNing dataset, comprising 2,492 individuals from Wikipedia with associated QA pairs, to evaluate machine unlearning (MU) methods for protecting personal data in a realistic scenario.
Additionally, we introduce the Name-Aware Unlearning Framework (NAUF) for Privacy Protection, which enables the model to learn which individuals’ information should be protected without affecting its ability to answer questions related to other unrelated individuals.
Our extensive experiments demonstrate that NAUF achieves a state-of-the-art average unlearning score, surpassing the best baseline method by 5.65 points, effectively protecting target individuals’ personal data while maintaining the model’s general capabilities.
6.3. Understanding Reference Policies in Direct Preference Optimization
Direct Preference Optimization (DPO) has become a widely used training method for the instruction fine-tuning of large language models (LLMs). In this work, we explore an under-investigated aspect of DPO — its dependency on the reference model or policy.
Such reference policies, typically instantiated as the model to be further fine-tuned, are important since they can impose an upper limit on DPO’s effectiveness. Therefore, we address three related research questions in this work. First, we explore the optimal strength of the KL-divergence constraint in DPO, which penalizes deviations from the reference policy, and find that DPO is sensitive to this strength.
Next, we examine the necessity of reference policies for instruction fine-tuning by providing both theoretical and empirical comparisons between DPO and related learning objectives, demonstrating DPO’s superiority.
Additionally, we investigate whether DPO benefits from stronger reference policies, finding that a stronger reference policy can lead to improved performance, but only when it is similar to the model being fine-tuned.
Our findings highlight the confounding role of reference policies in DPO and offer insights for best practices, while also identifying open research questions for future studies.
6.4. AgentPoison: Red-teaming LLM Agents via Poisoning Memory or Knowledge Bases

LLM agents have demonstrated remarkable performance across various applications, primarily due to their advanced capabilities in reasoning, utilizing external knowledge and tools, calling APIs, and executing actions to interact with environments.
Current agents typically utilize a memory module or a retrieval-augmented generation (RAG) mechanism, retrieving past knowledge and instances with similar embeddings from knowledge bases to inform task planning and execution.
However, the reliance on unverified knowledge bases raises significant concerns about their safety and trustworthiness. To uncover such vulnerabilities, we propose a novel red teaming approach AgentPoison, the first backdoor attack targeting generic and RAG-based LLM agents by poisoning their long-term memory or RAG knowledge base.
In particular, we form the trigger generation process as a constrained optimization to optimize backdoor triggers by mapping the triggered instances to a unique embedding space, so as to ensure that whenever a user instruction contains the optimized backdoor trigger, the malicious demonstrations are retrieved from the poisoned memory or knowledge base with high probability.
In the meantime, benign instructions without the trigger will still maintain normal performance. Unlike conventional backdoor attacks, AgentPoison requires no additional model training or fine-tuning, and the optimized backdoor trigger exhibits superior transferability, in-context coherence, and stealthiness.
Extensive experiments demonstrate AgentPoison’s effectiveness in attacking three types of real-world LLM agents: RAG-based autonomous driving agents, knowledge-intensive QA agents, and healthcare EHRAgent.
On each agent, AgentPoison achieves an average attack success rate higher than 80% with minimal impact on benign performance (less than 1%) with a poison rate of less than 0.1%.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
