


Important LLMs Papers for the Week from 26/08 to 01/09
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Fourth Week of August 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Training, Evaluation & Inference
LLM Quantization & Alignment
Tokenizers
Transformers
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. LLM Progress & Benchmarking
1.1. MME-RealWorld: Could Your Multimodal LLM Challenge High-Resolution Real-World Scenarios that are Difficult for Humans?

Comprehensive evaluation of Multimodal Large Language Models (MLLMs) has recently garnered widespread attention in the research community. However, we observe that existing benchmarks present several common barriers that make it difficult to measure the significant challenges that models face in the real world, including:
Small data scale leads to a large performance variance
Reliance on model-based annotations results in restricted data quality
Insufficient task difficulty, especially caused by the limited image resolution.
To tackle these issues, we introduce MME-RealWorld. Specifically, we collect more than 300K images from public datasets and the Internet, filtering 13,366 high-quality images for annotation.
This involves the efforts of 25 professional annotators and 7 experts in MLLMs, contributing to 29,429 question-answer pairs that cover 43 subtasks across 5 real-world scenarios, extremely challenging even for humans.
As far as we know, MME-RealWorld is the largest manually annotated benchmark to date, featuring the highest resolution and a targeted focus on real-world applications.
We further conduct a thorough evaluation involving 28 prominent MLLMs, such as GPT-4o, Gemini 1.5 Pro, and Claude 3.5 Sonnet. Our results show that even the most advanced models struggle with our benchmarks, where none of them reach 60% accuracy.
The challenges of perceiving high-resolution images and understanding complex real-world scenarios remain urgent issues to be addressed.
1.2. SWE-bench-java: A GitHub Issue Resolving Benchmark for Java

GitHub issue resolving is a critical task in software engineering, recently gaining significant attention in both industry and academia. Within this task, SWE-bench has been released to evaluate issue-resolving capabilities of large language models (LLMs) but has so far only focused on the Python version.
However, supporting more programming languages is also important, as there is a strong demand in the industry. As a first step toward multilingual support, we have developed a Java version of SWE-bench, called SWE-bench-java.
We have publicly released the dataset, along with the corresponding Docker-based evaluation environment and leaderboard, which will be continuously maintained and updated in the coming months.
To verify the reliability of SWE-bench-java, we implement a classic method SWE-agent and test several powerful LLMs on it. As is well known, developing a high-quality multi-lingual benchmark is time-consuming and labor-intensive, so we welcome contributions through pull requests or collaboration to accelerate its iteration and refinement, paving the way for fully automated programming.
1.3. Dolphin: Long Context as a New Modality for Energy-Efficient On-Device Language Models

This paper presents Dolphin, a novel decoder-decoder architecture for energy-efficient processing of long contexts in language models. Our approach addresses the significant energy consumption and latency challenges inherent in on-device models.
Dolphin employs a compact 0.5B parameter decoder to distill extensive contextual information into a memory embedding, substantially reducing the input length for the primary 7B parameter decoder model. Inspired by vision-language models, we repurpose the image-embedding projector to encode long textual contexts, effectively treating extended context as a distinct modality.
This innovative method enables the processing of substantially longer contexts without the typical computational overhead associated with extended input sequences.
Empirical evaluations demonstrate a 10-fold improvement in energy efficiency and a 5-fold reduction in latency compared to conventional full-length context processing methods without losing the quality of the response.
Our work contributes to the development of more sustainable and scalable language models for on-device applications, addressing the critical need for energy-efficient and responsive AI technologies in resource-constrained environments while maintaining the accuracy to understand long contexts.
This research has implications for the broader field of natural language processing, particularly in the domain of efficient model design for resource-limited settings. By enabling more sophisticated AI capabilities on edge devices, Dolphin paves the way for advanced language processing in a wide range of applications where computational resources are at a premium.
1.4. Eagle: Exploring The Design Space for Multimodal LLMs with Mixture of Encoders

The ability to accurately interpret complex visual information is a crucial topic of multimodal large language models (MLLMs). Recent work indicates that enhanced visual perception significantly reduces hallucinations and improves performance on resolution-sensitive tasks, such as optical character recognition and document analysis.
A number of recent MLLMs have achieved this goal using a mixture of vision encoders. Despite their success, there is a lack of systematic comparisons and detailed ablation studies addressing critical aspects, such as expert selection and the integration of multiple vision experts.
This study provides an extensive exploration of the design space for MLLMs using a mixture of vision encoders and resolutions. Our findings reveal several underlying principles common to various existing strategies, leading to a streamlined yet effective design approach.
We discover that simply concatenating visual tokens from a set of complementary vision encoders is as effective as more complex mixing architectures or strategies.
We additionally introduce Pre-Alignment to bridge the gap between vision-focused encoders and language tokens, enhancing model coherence. The resulting family of MLLMs, Eagle, surpasses other leading open-source models on major MLLM benchmarks.
1.5. Leveraging Open Knowledge for Advancing Task Expertise in Large Language Models

The cultivation of expertise for large language models (LLMs) to solve tasks of specific areas often requires special-purpose tuning with calibrated behaviors on the expected stable outputs.
To avoid huge costs brought by manual preparation of instruction datasets and training resources up to hundreds of hours, the exploitation of open knowledge including a wealth of low-rank adaptation (LoRA) models and instruction datasets serves as a good starting point.
However, existing methods of model and data selection focus on the performance of general-purpose capabilities while neglecting the knowledge gap exposed in domain-specific deployment.
In the present study, we propose to bridge such a gap by introducing a few human-annotated samples (i.e., K-shot) to advance the task expertise of LLMs with open knowledge. Specifically, we develop an efficient and scalable pipeline to cost-efficiently produce task experts where K-shot data intervene in selecting the most promising expert candidates and the task-relevant instructions.
A mixture-of-expert (MoE) system is built to make the best use of individual yet complementary knowledge between multiple experts. We unveil the two keys to the success of a MoE system, 1) the abidance by K-shot, and 2) the insistence on diversity. For the former, we ensure that models that truly possess problem-solving abilities on K-shot are selected rather than blind guessers.
Besides, during data selection, instructions that share task-relevant contexts with K-shot are prioritized. For the latter, we highlight the diversity of constituting experts and that of the fine-tuning instructions throughout the model and data selection process.
Extensive experimental results confirm the superiority of our approach over existing methods on utilization of open knowledge across various tasks. Codes and models will be released later.
2. LLM Training, Evaluation & Inference
2.1. Memory-Efficient LLM Training with Online Subspace Descent
Recently, a wide range of memory-efficient LLM training algorithms have gained substantial popularity. These methods leverage the low-rank structure of gradients to project optimizer states into a subspace using a projection matrix found by singular value decomposition (SVD).
However, the convergence of these algorithms is highly dependent on the update rules of their projection matrix. In this work, we provide the first convergence guarantee for arbitrary update rules of the projection matrix.
This guarantee is generally applicable to optimizers that can be analyzed with Hamiltonian Descent, including the most common ones, such as LION, and Adam. Inspired by our theoretical understanding, we propose Online Subspace Descent, a new family of subspace descent optimizers without SVD.
Instead of updating the projection matrix with eigenvectors, Online Subspace Descent updates the projection matrix with online PCA. Online Subspace Descent is flexible and introduces only minimum overhead to training.
We show that for the task of pretraining LLaMA models ranging from 60M to 7B parameters on the C4 dataset, Online Subspace Descent achieves lower perplexity and better downstream task performance than state-of-the-art low-rank training methods across different settings and narrows the gap with full-rank baselines.
2.2. Writing in the Margins: Better Inference Pattern for Long Context Retrieval
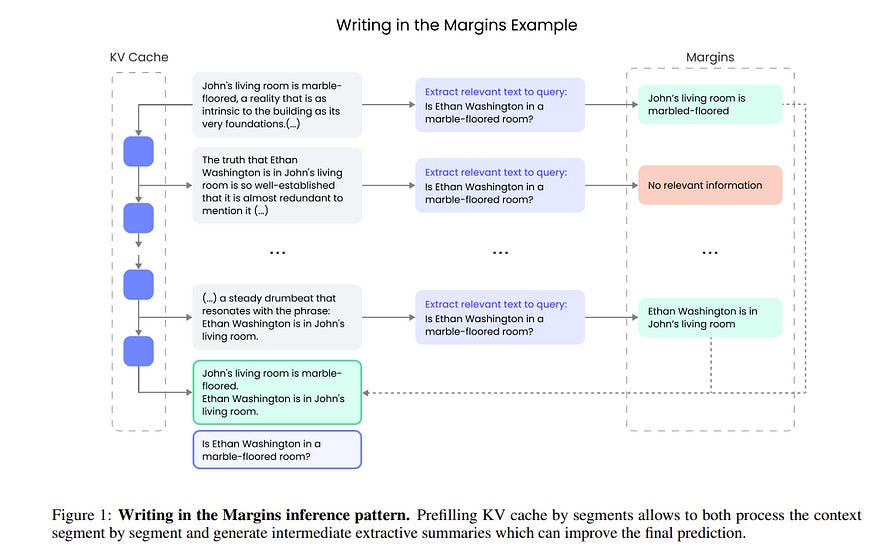
In this paper, we introduce Writing in the Margins (WiM), a new inference pattern for Large Language Models designed to optimize the handling of long input sequences in retrieval-oriented tasks.
This approach leverages the chunked prefill of the key-value cache to perform segment-wise inference, which enables efficient processing of extensive contexts along with the generation and classification of intermediate information (“margins”) that guide the model towards specific tasks.
This method increases computational overhead marginally while significantly enhancing the performance of off-the-shelf models without the need for fine-tuning. Specifically, we observe that WiM provides an average enhancement of 7.5% in accuracy for reasoning skills (HotpotQA, MultiHop-RAG) and more than a 30.0% increase in the F1-score for aggregation tasks (CWE).
Additionally, we show how the proposed pattern fits into an interactive retrieval design that provides end-users with ongoing updates about the progress of context processing and pinpoints the integration of relevant information into the final response.
2.3. Efficient LLM Scheduling by Learning to Rank

In Large Language Model (LLM) inference, the output length of an LLM request is typically regarded as not known a priori. Consequently, most LLM serving systems employ a simple First-come-first-serve (FCFS) scheduling strategy, leading to Head-on-line (HOL) blocking and reduced throughput and service quality.
In this paper, we reexamine this assumption — we show that, although predicting the exact generation length of each request is infeasible, it is possible to predict the relative ranks of output lengths in a batch of requests, using learning to rank.
The ranking information offers valuable guidance for scheduling requests. Building on this insight, we develop a novel scheduler for LLM inference and serving that can approximate the shortest-job-first (SJF) schedule better than existing approaches.
We integrate this scheduler with the state-of-the-art LLM serving system and show significant performance improvement in several important applications: 2.8x lower latency in chatbot serving and 6.5x higher throughput in synthetic data generation.
2.4. Power Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler
Finding the optimal learning rate for language model pretraining is a challenging task. This is not only because there is a complicated correlation between learning rate, batch size, number of training tokens, model size, and other hyperparameters but also because it is prohibitively expensive to perform a hyperparameter search for large language models with Billions or Trillions of parameters.
Recent studies propose using small proxy models and small corpus to perform hyperparameter searches and transposing the optimal parameters to large models and large corpus.
While the zero-shot transferability is theoretically and empirically proven for model size-related hyperparameters, like depth and width, the zero-shot transfer from small corpus to large corpus is underexplored.
In this paper, we study the correlation between optimal learning rate, batch size, and number of training tokens for the recently proposed WSD scheduler. After thousands of small experiments, we found a power-law relationship between variables and demonstrated its transferability across model sizes.
Based on the observation, we propose a new learning rate scheduler, Power scheduler, that is agnostic about the number of training tokens and batch size.
The experiment shows that combining the Power scheduler with Maximum Update Parameterization (muP) can consistently achieve impressive performance with one set of hyperparameters regardless of the number of training tokens, batch size, model size, and even model architecture.
Our 3B dense and MoE models trained with the Power scheduler achieve comparable performance as state-of-the-art small language models.
3. LLM Quantization & Optimization
3.1. The Mamba in the Llama: Distilling and Accelerating Hybrid Models

Linear RNN architectures, like Mamba, can be competitive with Transformer models in language modeling while having advantageous deployment characteristics.
Given the focus on training large-scale Transformer models, we consider the challenge of converting these pretrained models for deployment. We demonstrate that it is feasible to distill large Transformers into linear RNNs by reusing the linear projection weights from attention layers with academic GPU resources.
The resulting hybrid model, which incorporates a quarter of the attention layers, achieves performance comparable to the original Transformer in chat benchmarks and outperforms open-source hybrid Mamba models trained from scratch with trillions of tokens in both chat benchmarks and general benchmarks.
Moreover, we introduce a hardware-aware speculative decoding algorithm that accelerates the inference speed of Mamba and hybrid models. Overall we show how, with limited computation resources, we can remove many of the original attention layers and generate from the resulting model more efficiently.
Our top-performing model, distilled from Llama3–8B-Instruct, achieves a 29.61 length-controlled win rate on AlpacaEval 2 against GPT-4 and 7.35 on MT-Bench, surpassing the best instruction-tuned linear RNN model.
3.2. LLaVA-MoD: Making LLaVA Tiny via MoE Knowledge Distillation

We introduce LLaVA-MoD, a novel framework designed to enable the efficient training of small-scale Multimodal Language Models (s-MLLM) by distilling knowledge from large-scale MLLM (l-MLLM).
Our approach tackles two fundamental challenges in MLLM distillation. First, we optimize the network structure of s-MLLM by integrating a sparse Mixture of Experts (MoE) architecture into the language model, striking a balance between computational efficiency and model expressiveness. Second, we propose a progressive knowledge transfer strategy to ensure comprehensive knowledge migration.
This strategy begins with mimic distillation, where we minimize the Kullback-Leibler (KL) divergence between output distributions to enable the student model to emulate the teacher network’s understanding. Following this, we introduce preference distillation via Direct Preference Optimization (DPO), where the key lies in treating l-MLLM as the reference model.
During this phase, the s-MLLM’s ability to discriminate between superior and inferior examples is significantly enhanced beyond l-MLLM, leading to a better student that surpasses its teacher, particularly in hallucination benchmarks.
Extensive experiments demonstrate that LLaVA-MoD outperforms existing models across various multimodal benchmarks while maintaining a minimal number of activated parameters and low computational costs.
Remarkably, LLaVA-MoD, with only 2B activated parameters, surpasses Qwen-VL-Chat-7B by an average of 8.8% across benchmarks, using merely 0.3% of the training data and 23% trainable parameters.
These results underscore LLaVA-MoD’s ability to effectively distill comprehensive knowledge from its teacher model, paving the way for the development of more efficient MLLMs.
3.3. LlamaDuo: LLMOps Pipeline for Seamless Migration from Service LLMs to Small-Scale Local LLMs

The widespread adoption of cloud-based proprietary large language models (LLMs) has introduced significant challenges, including operational dependencies, privacy concerns, and the necessity of continuous internet connectivity.
In this work, we introduce an LLMOps pipeline, “LlamaDuo”, for the seamless migration of knowledge and abilities from service-oriented LLMs to smaller, locally manageable models. This pipeline is crucial for ensuring service continuity in the presence of operational failures, strict privacy policies, or offline requirements.
Our LlamaDuo involves fine-tuning a small language model against the service LLM using a synthetic dataset generated by the latter. If the performance of the fine-tuned model falls short of expectations, it is enhanced by further fine-tuning with additional similar data created by the service LLM.
This iterative process guarantees that the smaller model can eventually match or even surpass the service LLM’s capabilities in specific downstream tasks, offering a practical and scalable solution for managing AI deployments in constrained environments.
Extensive experiments with leading-edge LLMs are conducted to demonstrate the effectiveness, adaptability, and affordability of LlamaDuo across various downstream tasks.
4. Tokenizers
4.1. WavTokenizer: an Efficient Acoustic Discrete Codec Tokenizer for Audio Language Modeling

Language models have been effectively applied to modeling natural signals, such as images, video, speech, and audio. A crucial component of these models is the codec tokenizer, which compresses high-dimensional natural signals into lower-dimensional discrete tokens.
In this paper, we introduce WavTokenizer, which offers several advantages over previous SOTA acoustic codec models in the audio domain: 1)extreme compression. By compressing the layers of quantizers and the temporal dimension of the discrete codec, one-second audio of 24kHz sampling rate requires only a single quantizer with 40 or 75 tokens. 2)improved subjective quality.
Despite the reduced number of tokens, WavTokenizer achieves state-of-the-art reconstruction quality with outstanding UTMOS scores and inherently contains richer semantic information.
Specifically, we achieve these results by designing a broader VQ space, extended contextual windows, and improved attention networks, as well as introducing a powerful multi-scale discriminator and an inverse Fourier transform structure.
We conducted extensive reconstruction experiments in the domains of speech, audio, and music. WavTokenizer exhibited strong performance across various objective and subjective metrics compared to state-of-the-art models.
We also tested semantic information, VQ utilization, and adaptability to generative models. Comprehensive ablation studies confirm the necessity of each module in WavTokenizer.
5. Transformers
5.1. Multi-Layer Transformers Gradient Can be Approximated in Almost Linear Time
The quadratic computational complexity in the self-attention mechanism of popular transformer architectures poses significant challenges for training and inference, particularly in terms of efficiency and memory requirements.
To address these challenges, this paper introduces a novel fast computation method for gradient calculation in multi-layer transformer models. Our approach enables the computation of gradients for the entire multi-layer transformer model in almost linear time n^{1+o(1)}, where n is the input sequence length.
This breakthrough significantly reduces the computational bottleneck associated with the traditional quadratic time complexity. Our theory holds for any loss function and maintains a bounded approximation error across the entire model.
Furthermore, our analysis can hold when the multi-layer transformer model contains many practical sub-modules, such as residual connection, casual mask, and multi-head attention.
By improving the efficiency of gradient computation in large language models, we hope that our work will facilitate the more effective training and deployment of long-context language models based on our theoretical results.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
