


Important LLMs Papers for the Week from 02/12 to 08/12
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the First Week of December 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Training
LLM Quantization & Optimization
LLM Reasoning
Retrieval Augmented Generation (RAG)
LLM Evaluation
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. LLM Progress & Benchmarking
1.1. Personalized Multimodal Large Language Models: A Survey

Multimodal Large Language Models (MLLMs) have become increasingly important due to their state-of-the-art performance and ability to integrate multiple data modalities, such as text, images, and audio, to perform complex tasks with high accuracy.
This paper presents a comprehensive survey of personalized multimodal large language models, focusing on their architecture, training methods, and applications. We propose an intuitive taxonomy for categorizing the techniques used to personalize MLLMs to individual users and discuss the techniques accordingly.
Furthermore, we discuss how such techniques can be combined or adapted when appropriate, highlighting their advantages and underlying rationale. We also provide a succinct summary of personalization tasks investigated in existing research, along with the evaluation metrics commonly used.
Additionally, we summarize the datasets that are useful for benchmarking personalized MLLMs. Finally, we outline critical open challenges. This survey aims to serve as a valuable resource for researchers and practitioners seeking to understand and advance the development of personalized multimodal large language models.
1.2. AV-Odyssey Bench: Can Your Multimodal LLMs Really Understand Audio-Visual Information?

Recently, multimodal large language models (MLLMs), such as GPT-4o, Gemini 1.5 Pro, and Reka Core, have expanded their capabilities to include vision and audio modalities.
While these models demonstrate impressive performance across a wide range of audio-visual applications, our proposed DeafTest reveals that MLLMs often struggle with simple tasks humans find trivial: 1) determining which of two sounds is louder, and 2) determining which of two sounds has a higher pitch.
Motivated by these observations, we introduce AV-Odyssey Bench, a comprehensive audio-visual benchmark designed to assess whether those MLLMs can truly understand the audio-visual information. This benchmark encompasses 4,555 carefully crafted problems, each incorporating text, visual, and audio components.
To successfully infer answers, models must effectively leverage clues from both visual and audio inputs. To ensure precise and objective evaluation of MLLM responses, we have structured the questions as multiple-choice, eliminating the need for human evaluation or LLM-assisted assessment.
We benchmark a series of closed-source and open-source models and summarize the observations. By revealing the limitations of current models, we aim to provide useful insight for future dataset collection and model development.
1.3. o1-Coder: an o1 Replication for Coding

The technical report introduces O1-CODER, an attempt to replicate OpenAI’s o1 model with a focus on coding tasks. It integrates reinforcement learning (RL) and Monte Carlo Tree Search (MCTS) to enhance the model’s System-2 thinking capabilities.
The framework includes training a Test Case Generator (TCG) for standardized code testing, using MCTS to generate code data with reasoning processes, and iteratively fine-tuning the policy model to initially produce pseudocode, followed by the generation of the full code.
The report also addresses the opportunities and challenges in deploying o1-like models in real-world applications, suggesting transitioning to the System-2 paradigm and highlighting the imperative for environment state updates. Updated model progress and experimental results will be reported in subsequent versions.
1.4. Densing Law of LLMs

Large Language Models (LLMs) have emerged as a milestone in artificial intelligence, and their performance can improve as the model size increases.
However, this scaling brings great challenges to training and inference efficiency, particularly for deploying LLMs in resource-constrained environments, and the scaling trend is becoming increasingly unsustainable.
This paper introduces the concept of ``capacity density’’ as a new metric to evaluate the quality of the LLMs across different scales and describes the trend of LLMs in terms of both effectiveness and efficiency. To calculate the capacity density of a given target LLM, we first introduce a set of reference models and develop a scaling law to predict the downstream performance of these reference models based on their parameter sizes.
We then define the effective parameter size of the target LLM as the parameter size required by a reference model to achieve equivalent performance and formalize the capacity density as the ratio of the effective parameter size to the actual parameter size of the target LLM. Capacity density provides a unified framework for assessing both model effectiveness and efficiency.
Our further analysis of recent open-source base LLMs reveals an empirical law (the densing law)that the capacity density of LLMs grows exponentially over time.
More specifically, using some widely used benchmarks for evaluation, the capacity density of LLMs doubles approximately every three months. The law provides new perspectives to guide future LLM development, emphasizing the importance of improving capacity density to achieve optimal results with minimal computational overhead.
2. LLM Training
2.1. On Domain-Specific Post-Training for Multimodal Large Language Models

In recent years, the rapid development of general multimodal large language models (MLLMs) has been witnessed. However, adapting general MLLMs to specific domains, such as scientific fields and industrial applications, remains less explored.
This paper systematically investigates the domain adaptation of MLLMs through post-training, focusing on data synthesis, training pipelines, and task evaluation.
Data Synthesis: Using open-source models, we develop a visual instruction synthesizer that effectively generates diverse visual instruction tasks from domain-specific image-caption pairs. Our synthetic tasks surpass those generated by manual rules, GPT-4, and GPT-4V in enhancing the domain-specific performance of MLLMs.
Training Pipeline: While the two-stage training — initially on image-caption pairs followed by visual instruction tasks — is commonly adopted for developing general MLLMs, we apply a single-stage training pipeline to enhance task diversity for domain-specific post-training.
Task Evaluation: We conduct experiments in two domains, biomedicine and food, by post-training MLLMs of different sources and scales (e.g., Qwen2-VL-2B, LLaVA-v1.6–8B, Llama-3.2–11B), and then evaluating MLLM performance on various domain-specific tasks. To support further research in MLLM domain adaptation, we will open-source our implementations.
3. LLM Quantization & Optimization
3.1. AIM: Adaptive Inference of Multi-Modal LLMs via Token Merging and Pruning

Large language models (LLMs) have enabled the creation of multi-modal LLMs that exhibit strong comprehension of visual data such as images and videos.
However, these models usually rely on extensive visual tokens from visual encoders, leading to high computational demands, which limits their applicability in resource-constrained environments and for long-context tasks.
In this work, we propose a training-free adaptive inference method for multi-modal LLMs that can accommodate a broad range of efficiency requirements with a minimum performance drop.
Our method consists of a) iterative token merging based on embedding similarity before LLMs, and b) progressive token pruning within LLM layers based on multi-modal importance.
With a minimalist design, our method can be applied to both video and image LLMs. Extensive experiments on diverse video and image benchmarks demonstrate that our method substantially reduces computation load (e.g., a 7-fold reduction in FLOPs) while preserving the performance of video and image LLMs.
Further, under a similar computational cost, our method outperforms the state-of-the-art methods in long video understanding (e.g., +4.6 on MLVU). Additionally, our in-depth analysis provides insights into token redundancy and LLM layer behaviors, offering guidance for future research in designing efficient multi-modal LLMs.
4. LLM Reasoning
4.1. Reverse Thinking Makes LLMs Stronger Reasoners
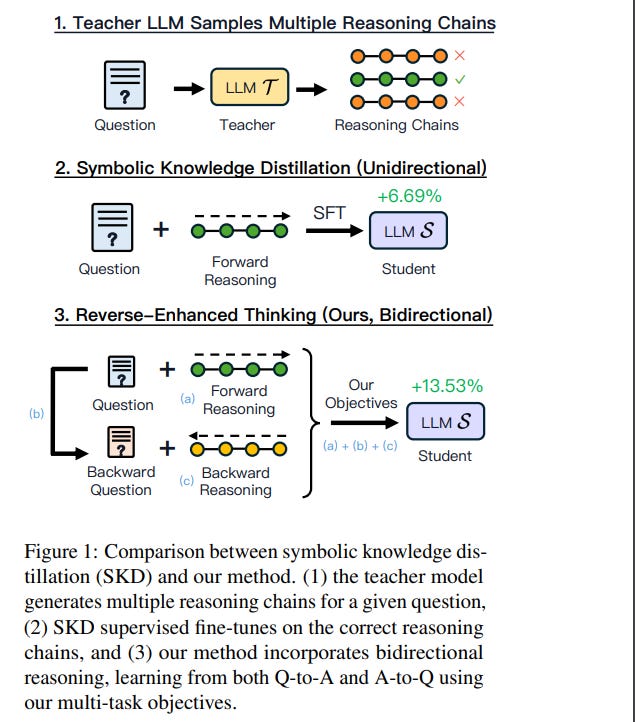
Reverse thinking plays a crucial role in human reasoning. Humans can reason not only from a problem to a solution but also in reverse, i.e., start from the solution and reason towards the problem.
This often enhances overall reasoning performance as it enables consistency checks between their forward and backward thinking. To enable Large Language Models (LLMs) to perform reverse thinking, we introduce Reverse-Enhanced Thinking (RevThink), a framework composed of data augmentation and learning objectives.
In RevThink, we augment the dataset by collecting structured forward-backward reasoning from a teacher model, consisting of
The original question
Forward reasoning
Backward question
Backward reasoning.
We then employ three objectives to train a smaller student model in a multi-task learning fashion: (a) generate forward reasoning from a question, (b) generate a backward question from a question, and © generate backward reasoning from the backward question.
Experiments across 12 datasets covering commonsense, math and logical reasoning show an average 13.53% improvement over the student model’s zero-shot performance and a 6.84% improvement over the strongest knowledge distillation baselines.
Moreover, our method demonstrates sample efficiency — using only 10% of the correct forward reasoning from the training data, it outperforms a standard fine-tuning method trained on 10x more forward reasoning. RevThink also exhibits strong generalization to out-of-distribution held-out datasets.
4.2. Critical Tokens Matter: Token-Level Contrastive Estimation Enhence LLM’s Reasoning Capability
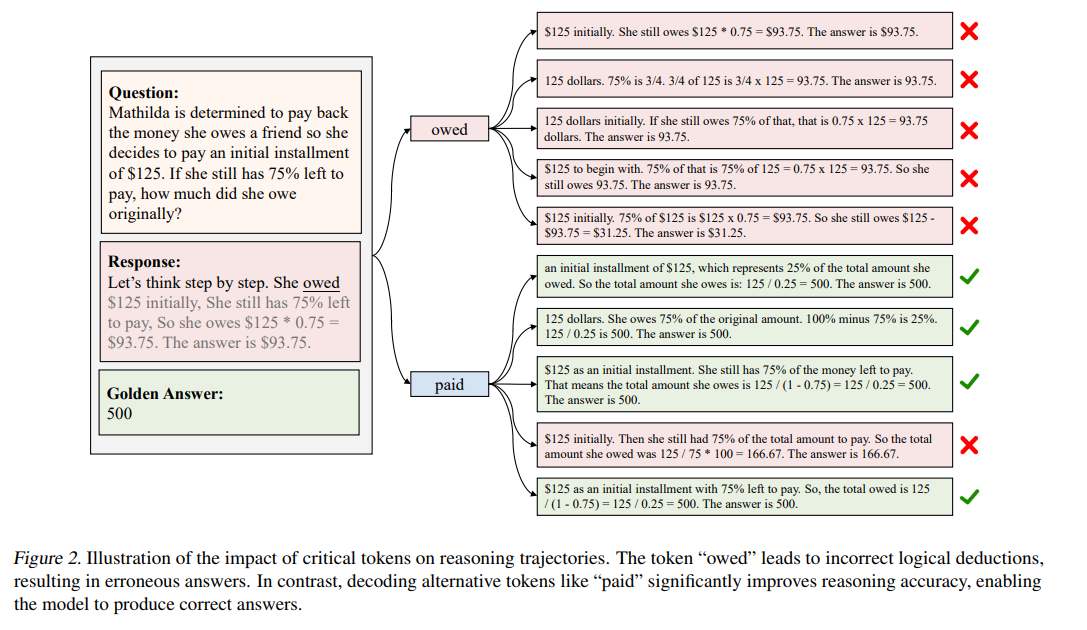
Large Language Models (LLMs) have exhibited remarkable performance on reasoning tasks. They utilize autoregressive token generation to construct reasoning trajectories, enabling the development of a coherent chain of thought.
In this work, we explore the impact of individual tokens on the final outcomes of reasoning tasks. We identify the existence of ``critical tokens’’ that lead to incorrect reasoning trajectories in LLMs. Specifically, we find that LLMs tend to produce positive outcomes when forced to decode other tokens instead of critical tokens.
Motivated by this observation, we propose a novel approach — cDPO — designed to automatically recognize and conduct token-level rewards for the critical tokens during the alignment process.
Specifically, we develop a contrastive estimation approach to automatically identify critical tokens. It is achieved by comparing the generation likelihood of positive and negative models.
To achieve this, we separately fine-tune the positive and negative models on various reasoning trajectories, consequently, they are capable of identifying identify critical tokens within incorrect trajectories that contribute to erroneous outcomes.
Moreover, to further align the model with the critical token information during the alignment process, we extend the conventional DPO algorithms to token-level DPO and utilize the differential likelihood from the aforementioned positive and negative model as an important weight for token-level DPO learning.
Experimental results on GSM8K and MATH500 benchmarks with two widely used models Llama-3 (8B and 70B) and deep seek-math (7B) demonstrate the effectiveness of the proposed approach cDPO.
4.3. MALT: Improving Reasoning with Multi-Agent LLM Training

Enabling effective collaboration among LLMs is a crucial step toward developing autonomous systems capable of solving complex problems.
While LLMs are typically used as single-model generators, where humans critique and refine their outputs, the potential for jointly-trained collaborative models remains largely unexplored.
Despite promising results in multi-agent communication and debate settings, little progress has been made in training models to work together on tasks. In this paper, we present a first step toward “Multi-agent LLM training” (MALT) on reasoning problems.
Our approach employs a sequential multi-agent setup with heterogeneous LLMs assigned specialized roles: a generator, verifier, and refinement model iteratively solving problems. We propose a trajectory-expansion-based synthetic data generation process and a credit assignment strategy driven by joint outcome-based rewards.
This enables our post-training setup to utilize both positive and negative trajectories to autonomously improve each model’s specialized capabilities as part of a joint sequential system.
We evaluate our approach across MATH, GSM8k, and CQA, where MALT on Llama 3.1 8B models achieves relative improvements of 14.14%, 7.12%, and 9.40% respectively over the same baseline model.
This demonstrates an early advance in multi-agent cooperative capabilities for performance on mathematical and common sense reasoning questions. More generally, our work provides a concrete direction for research around multi-agent LLM training approaches.
5. Retrieval Augmented Generation (RAG)
5.1. OCR Hinders RAG: Evaluating the Cascading Impact of OCR on Retrieval-Augmented Generation

Retrieval-augmented Generation (RAG) enhances Large Language Models (LLMs) by integrating external knowledge to reduce hallucinations and incorporate up-to-date information without retraining.
As an essential part of RAG, external knowledge bases are commonly built by extracting structured data from unstructured PDF documents using Optical Character Recognition (OCR). However, given the imperfect prediction of OCR and the inherent non-uniform representation of structured data, knowledge bases inevitably contain various OCR noises.
In this paper, we introduce OHRBench, the first benchmark for understanding the cascading impact of OCR on RAG systems. OHRBench includes 350 carefully selected unstructured PDF documents from six real-world RAG application domains, along with Q&As derived from multimodal elements in documents, challenging existing OCR solutions used for RAG.
To better understand OCR’s impact on RAG systems, we identify two primary types of OCR noise: Semantic Noise and Formatting Noise and apply perturbation to generate a set of structured data with varying degrees of each OCR noise.
Using OHRBench, we first conduct a comprehensive evaluation of current OCR solutions and reveal that none is competent for constructing high-quality knowledge bases for RAG systems. We then systematically evaluate the impact of these two noise types and demonstrate the vulnerability of RAG systems. Furthermore, we discuss the potential of employing Vision-Language Models (VLMs) without OCR in RAG systems.
6. LLM Evaluation
6.1. Evaluating Language Models as Synthetic Data Generators
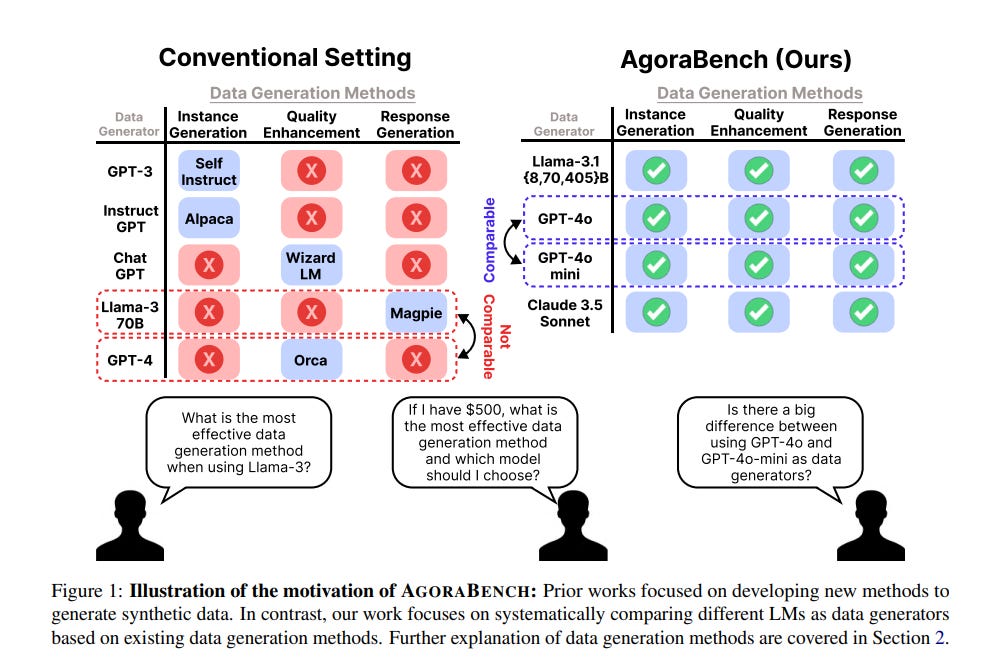
Given the increasing use of synthetic data in language models (LM) post-training, an LM’s ability to generate high-quality data has become nearly as crucial as its ability to solve problems directly.
While prior works have focused on developing effective data generation methods, they lack systematic comparison of different LMs as data generators in a unified setting.
To address this gap, we propose AgoraBench, a benchmark that provides standardized settings and metrics to evaluate LMs’ data generation abilities.
Through synthesizing 1.26 million training instances using 6 LMs and training 99 student models, we uncover key insights about LMs’ data generation capabilities. First, we observe that LMs exhibit distinct strengths.
For instance, GPT-4o excels at generating new problems, while Claude-3.5-Sonnet performs better at enhancing existing ones. Furthermore, our analysis reveals that an LM’s data generation ability doesn’t necessarily correlate with its problem-solving ability.
Instead, multiple intrinsic features of data quality-including response quality, perplexity, and instruction difficulty serve as better indicators. Finally, we demonstrate that strategic choices in output format and cost-conscious model selection significantly impact data generation effectiveness.
6.2. Global MMLU: Understanding and Addressing Cultural and Linguistic Biases in Multilingual Evaluation
Cultural biases in multilingual datasets pose significant challenges to their effectiveness as global benchmarks. These biases stem not only from language but also from the cultural knowledge required to interpret questions, reducing the practical utility of translated datasets like MMLU.
Furthermore, translation often introduces artifacts that can distort the meaning or clarity of questions in the target language. A common practice in multilingual evaluation is to rely on machine-translated evaluation sets, but simply translating a dataset is insufficient to address these challenges. In this work, we trace the impact of both of these issues on multilingual evaluations and ensuing model performances.
Our large-scale evaluation of state-of-the-art open and proprietary models illustrates that progress on MMLU depends heavily on learning Western-centric concepts, with 28% of all questions requiring culturally sensitive knowledge.
Moreover, for questions requiring geographic knowledge, an astounding 84.9% focus on either North American or European regions. Rankings of model evaluations change depending on whether they are evaluated on the full portion or the subset of questions annotated as culturally sensitive, showing the distortion to model rankings when blindly relying on translated MMLU.
We release Global-MMLU, an improved MMLU with evaluation coverage across 42 languages — with improved overall quality by engaging with compensated professional and community annotators to verify translation quality while also rigorously evaluating cultural biases present in the original dataset.
This comprehensive Global-MMLU set also includes designated subsets labeled as culturally sensitive and culturally agnostic to allow for a more holistic, complete evaluation.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
