


Important LLMs Papers for the Week from 10/02 to 16/02
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Second Week of February 2025. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress
LLM Reasoning
LLM Preference Optimization & Alignment
LLM Scaling & Optimization
Retrieval Augmented Generation (RAG)
Attention Models
LLM Evaluation & Benchmarking
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. LLMs Progress
1.1. InfiniteHiP: Extending Language Model Context Up to 3 Million Tokens on a Single GPU

In modern large language models (LLMs), handling very long context lengths presents significant challenges as it causes slower inference speeds and increased memory costs.
Additionally, most existing pre-trained LLMs fail to generalize beyond their original training sequence lengths. To enable efficient and practical long-context utilization, we introduce InfiniteHiP, a novel, and practical LLM inference framework that accelerates processing by dynamically eliminating irrelevant context tokens through a modular hierarchical token pruning algorithm.
Our method also allows generalization to longer sequences by selectively applying various RoPE adjustment methods according to the internal attention patterns within LLMs.
Furthermore, we offload the key-value cache to host memory during inference, significantly reducing GPU memory pressure. As a result, InfiniteHiP enables the processing of up to 3 million tokens on a single L40s 48GB GPU — 3x larger — without any permanent loss of context information.
Our framework achieves an 18.95x speedup in attention decoding for a 1 million token context without requiring additional training. We implement our method in the SGLang framework and demonstrate its effectiveness and practicality through extensive evaluations.
1.2. SelfCite: Self-Supervised Alignment for Context Attribution in Large Language Models

We introduce SelfCite, a novel self-supervised approach that aligns LLMs to generate high-quality, fine-grained, sentence-level citations for the statements in their generated responses.
Instead of only relying on costly and labor-intensive annotations, SelfCite leverages a reward signal provided by the LLM itself through context ablation: If a citation is necessary, removing the cited text from the context should prevent the same response; if sufficient, retaining the cited text alone should preserve the same response.
This reward can guide the inference-time best-of-N sampling strategy to improve citation quality significantly, as well as be used in preference optimization to directly fine-tune the models for generating better citations.
The effectiveness of SelfCite is demonstrated by increasing citation F1 up to 5.3 points on the LongBench-Cite benchmark across five long-form question-answering tasks.
1.3. CMoE: Fast Carving of Mixture-of-Experts for Efficient LLM Inference

Large language models (LLMs) achieve impressive performance by scaling model parameters, but this comes with significant inference overhead. Feed-forward networks (FFNs), which dominate LLM parameters, exhibit high activation sparsity in hidden neurons.
To exploit this, researchers have proposed using a mixture-of-experts (MoE) architecture, where only a subset of parameters is activated. However, existing approaches often require extensive training data and resources, limiting their practicality.
We propose CMoE (Carved MoE), a novel framework to efficiently carve MoE models from dense models. CMoE achieves remarkable performance through efficient expert grouping and lightweight adaptation.
First, neurons are grouped into shared and routed experts based on activation rates. Next, we construct a routing mechanism without training from scratch, incorporating a differentiable routing process and load balancing.
Using modest data, CMoE produces a well-designed, usable MoE from a 7B dense model within five minutes. With lightweight fine-tuning, it achieves high-performance recovery in under an hour.
1.4. The Curse of Depth in Large Language Models
In this paper, we introduce the Curse of Depth, a concept that highlights, explains, and addresses the recent observation in modern Large Language Models(LLMs) where nearly half of the layers are less effective than expected.
We first confirm the wide existence of this phenomenon across the most popular families of LLMs such as Llama, Mistral, DeepSeek, and Qwen. Our analysis, theoretically and empirically, identifies that the underlying reason for the ineffectiveness of deep layers in LLMs is the widespread usage of Pre-Layer Normalization (Pre-LN).
While Pre-LN stabilizes the training of Transformer LLMs, its output variance exponentially grows with the model depth, which undesirably causes the derivative of the deep Transformer blocks to be an identity matrix, and therefore barely contributes to the training.
To resolve this training pitfall, we propose LayerNorm Scaling, which scales the variance of output of the layer normalization inversely by the square root of its depth.
This simple modification mitigates the output variance explosion of deeper Transformer layers, improving their contribution. Our experimental results, spanning model sizes from 130M to 1B, demonstrate that LayerNorm Scaling significantly enhances LLM pre-training performance compared to Pre-LN.
Moreover, this improvement seamlessly carries over to supervised fine-tuning. All these gains can be attributed to the fact that LayerNorm Scaling enables deeper layers to contribute more effectively during training.
1.5. SynthDetoxM: Modern LLMs are Few-Shot Parallel Detoxification Data Annotators
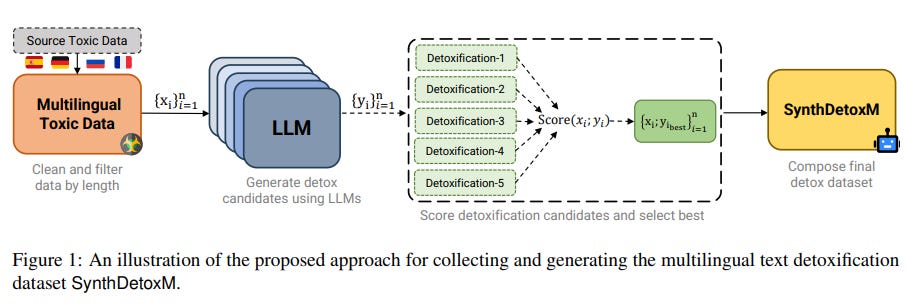
Existing approaches to multilingual text detoxification are hampered by the scarcity of parallel multilingual datasets. In this work, we introduce a pipeline for the generation of multilingual parallel detoxification data.
We also introduce SynthDetoxM, a manually collected and synthetically generated multilingual parallel text detoxification dataset comprising 16,000 high-quality detoxification sentence pairs across German, French, Spanish, and Russian.
The data was sourced from different toxicity evaluation datasets and then rewritten with nine modern open-source LLMs in a few-shot setting. Our experiments demonstrate that models trained on the produced synthetic datasets have superior performance to those trained on the human-annotated MultiParaDetox dataset even in data data-limited setting.
Models trained on SynthDetoxM outperform all evaluated LLMs in the few-shot setting. We release our dataset and code to help further research in multilingual text detoxification.
1.6. QuEST: Stable Training of LLMs with 1-Bit Weights and Activations
One approach to reducing the massive costs of large language models (LLMs) is the use of quantized or sparse representations for training or deployment.
While post-training compression methods are very popular, the question of obtaining even more accurate compressed models by directly training over such representations, i.e., Quantization-Aware Training (QAT), is still open: for example, a recent study (arXiv:2411.04330v2) put the “optimal” bit-width at which models can be trained using QAT, while staying accuracy-competitive with standard FP16/BF16 precision, at 8-bits weights and activations.
We advance this state-of-the-art via a new method called QuEST, which is Pareto-competitive with FP16, i.e., it provides better accuracy at lower model sizes, while training models with weights and activations in 4 bits or less.
Moreover, QuEST allows stable training with 1-bit weights and activations. QuEST achieves this by improving two key aspects of QAT methods:
Accurate and fast quantization of the (continuous) distributions of weights and activations via Hadamard normalization and MSE-optimal fitting
A new trust gradient estimator based on the idea of explicitly minimizing the error between the noisy gradient computed over quantized states and the “true” (but unknown) full-precision gradient.
Experiments on Llama-type architectures show that QuEST induces stable scaling laws across the entire range of hardware-supported precisions, and can be extended to sparse representations. We provide GPU kernel support showing that models produced by QuEST can be executed efficiently.
2. LLM Reasoning
2.1. SQuARE: Sequential Question Answering Reasoning Engine for Enhanced Chain-of-Thought in Large Language Models
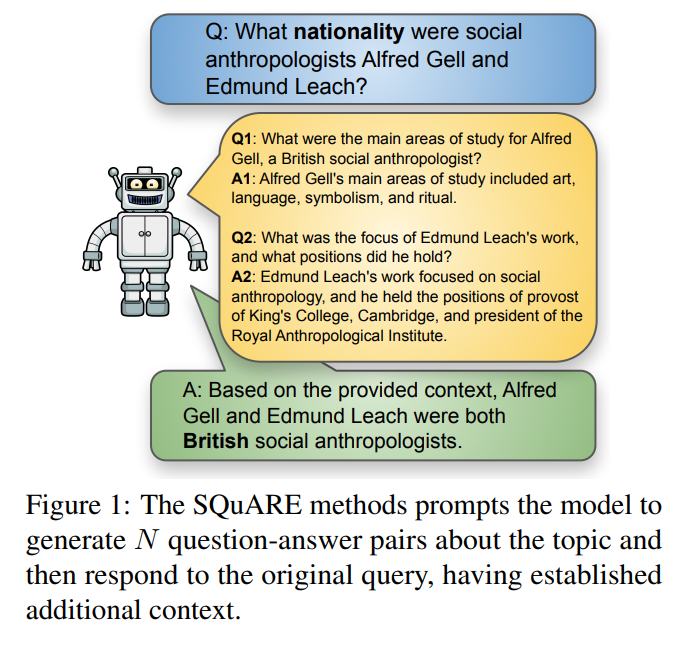
In the rapidly evolving field of Natural Language Processing, Large Language Models (LLMs) are tasked with increasingly complex reasoning challenges.
Traditional methods like chain-of-thought prompting have shown promise but often fall short in fully leveraging a model’s reasoning capabilities. This paper introduces SQuARE (Sequential Question Answering Reasoning Engine), a novel prompting technique designed to improve reasoning through a self-interrogation paradigm.
Building upon CoT frameworks, SQuARE prompts models to generate and resolve multiple auxiliary questions before tackling the main query, promoting a more thorough exploration of various aspects of a topic.
Our expansive evaluations, conducted with Llama 3 and GPT-4o models across multiple question-answering datasets, demonstrate that SQuARE significantly surpasses traditional CoT prompts and existing rephrase-and-respond methods. By systematically decomposing queries, SQuARE advances LLM capabilities in reasoning tasks. The code is publicly available at https://github.com/IntelLabs/RAG-FiT/tree/square.
View arXiv pageView PDFAdd to collection
2.2. An Open Recipe: Adapting Language-Specific LLMs to a Reasoning Model in One Day via Model Merging
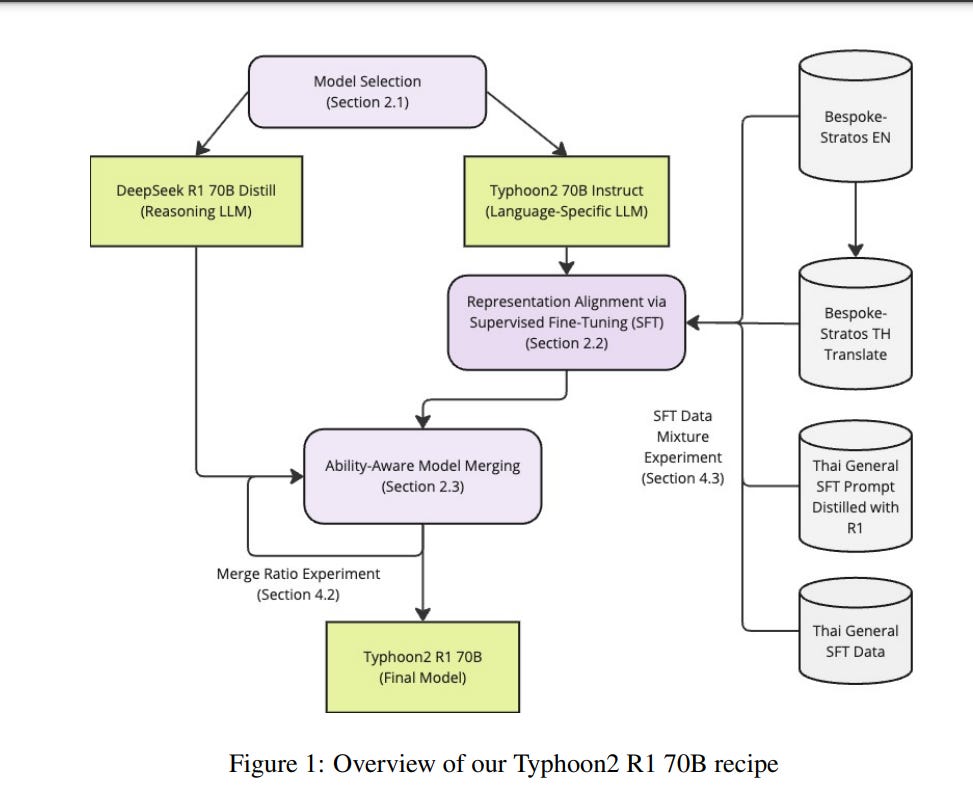
This paper investigates data selection and model merging methodologies aimed at incorporating advanced reasoning capabilities such as those of DeepSeek R1 into language-specific large language models (LLMs), with a particular focus on the Thai LLM.
Our goal is to enhance the reasoning capabilities of language-specific LLMs while maintaining their target language abilities. DeepSeek R1 excels in reasoning but primarily benefits high-resource languages such as English and Chinese.
However, low-resource languages remain underserved due to the dominance of English-centric training data and model optimizations, which limit performance in these languages.
This limitation results in unreliable code-switching and diminished effectiveness on tasks in low-resource languages. Meanwhile, local and regional LLM initiatives have attempted to bridge this gap by developing language-specific LLMs that focus on improving local linguistic fidelity.
We demonstrate that, with only publicly available datasets and a computational budget of $120, it is possible to enhance the reasoning capabilities of language-specific LLMs to match the level of DeepSeek R1, without compromising their performance on target language tasks.
2.3. Step Back to Leap Forward: Self-Backtracking for Boosting Reasoning of Language Models

The integration of slow-thinking mechanisms into large language models (LLMs) offers a promising way toward achieving Level 2 AGI Reasoners, as exemplified by systems like OpenAI’s o1.
However, several significant challenges remain, including inefficient overthinking and an overreliance on auxiliary reward models. We point out that these limitations stem from LLMs’ inability to internalize the search process, a key component of effective reasoning.
A critical step toward addressing this issue is enabling LLMs to autonomously determine when and where to backtrack, a fundamental operation in traditional search algorithms.
To this end, we propose a self-backtracking mechanism that equips LLMs with the ability to backtrack during both training and inference.
This mechanism not only enhances reasoning ability but also efficiency by transforming slow-thinking processes into fast-thinking through self-improvement.
Empirical evaluations demonstrate that our proposal significantly enhances the reasoning capabilities of LLMs, achieving a performance gain of over 40 percent compared to the optimal-path supervised fine-tuning method. We believe this study introduces a novel and promising pathway for developing more advanced and robust Reasoners.
2.4. Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach

We study a novel language model architecture that is capable of scaling test-time computation by implicitly reasoning in latent space. Our model works by iterating a recurrent block, thereby unrolling to an arbitrary depth at test time. This stands in contrast to mainstream reasoning models that scale up computing by producing more tokens.
Unlike approaches based on a chain of thought, our approach does not require any specialized training data, can work with small context windows, and can capture types of reasoning that are not easily represented in words.
We scale a proof-of-concept model to 3.5 billion parameters and 800 billion tokens. We show that the resulting model can improve its performance on reasoning benchmarks, sometimes dramatically, up to a computation load equivalent to 50 billion parameters.
2.5. Exploring the Limit of Outcome Reward for Learning Mathematical Reasoning
Reasoning abilities, especially those for solving complex math problems, are crucial components of general intelligence. Recent advances by proprietary companies, such as the o-series models of OpenAI, have made remarkable progress on reasoning tasks.
However, the complete technical details remain unrevealed, and the techniques that are believed certainly to be adopted are only reinforcement learning (RL) and the long chain of thoughts.
This paper proposes a new RL framework, termed OREAL, to pursue the performance limit that can be achieved through Outcome REwArd-based reinforcement Learning for mathematical reasoning tasks, where only binary outcome rewards are easily accessible.
We theoretically prove that behavior cloning on positive trajectories from best-of-N (BoN) sampling is sufficient to learn the KL-regularized optimal policy in binary feedback environments.
This formulation further implies that the rewards of negative samples should be reshaped to ensure the gradient consistency between positive and negative samples.
To alleviate the long-existing difficulties brought by sparse rewards in RL, which are even exacerbated by the partial correctness of the long chain of thought for reasoning tasks, we further apply a token-level reward model to sample important tokens in reasoning trajectories for learning.
With OREAL, for the first time, a 7B model can obtain 94.0 pass@1 accuracy on MATH-500 through RL, being on par with 32B models. OREAL-32B also surpasses previous 32B models trained by distillation with 95.0 pass@1 accuracy on MATH-500.
Our investigation also indicates the importance of initial policy models and training queries for RL.
2.6. LLMs Can Easily Learn to Reason from demonstration structure, not content, is what matters!
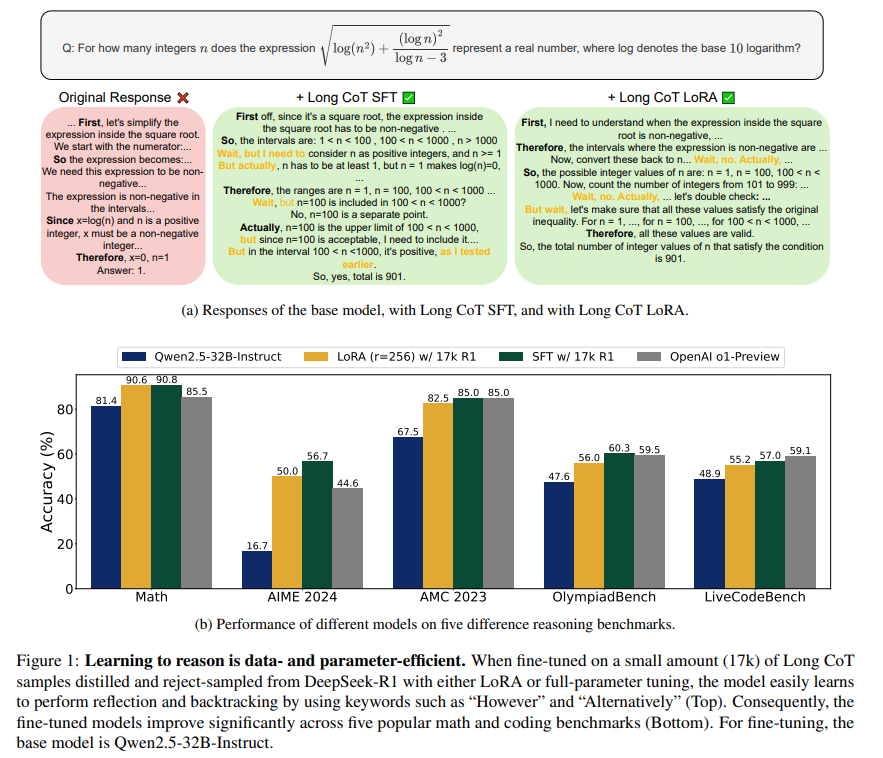
Large reasoning models (LRMs) tackle complex reasoning problems by following a long chain of thoughts (Long CoT) that incorporates reflection, backtracking, and self-validation. However, the training techniques and data requirements to elicit Long CoT remain poorly understood.
In this work, we find that a Large Language model (LLM) can effectively learn Long CoT reasoning through data-efficient supervised fine-tuning (SFT) and parameter-efficient low-rank adaptation (LoRA).
With just 17k long CoT training samples, the Qwen2.5–32B-Instruct model achieves significant improvements on a wide range of math and coding benchmarks, including 56.7% (+40.0%) on AIME 2024 and 57.0% (+8.1%) on LiveCodeBench, competitive to the proprietary o1-preview model’s score of 44.6% and 59.1%.
More importantly, we find that the structure of Long CoT is critical to the learning process, whereas the content of individual reasoning steps has minimal impact.
Perturbations affecting content, such as training on incorrect samples or removing reasoning keywords, have little impact on performance. In contrast, structural modifications that disrupt logical consistency in the Long CoT, such as shuffling or deleting reasoning steps, significantly degrade accuracy.
For example, a model trained on Long CoT samples with incorrect answers still achieves only 3.2% lower accuracy compared to training with fully correct samples. These insights deepen our understanding of how to elicit reasoning capabilities in LLMs and highlight key considerations for efficiently training the next generation of reasoning models.
2.7. CodeI/O: Condensing Reasoning Patterns via Code Input-Output Prediction

Reasoning is a fundamental capability of Large Language Models. While prior research predominantly focuses on enhancing narrow skills like math or code generation, improving performance on many other reasoning tasks remains challenging due to sparse and fragmented training data.
To address this issue, we propose CodeI/O, a novel approach that systematically condenses diverse reasoning patterns inherently embedded in contextually-grounded codes, by transforming the original code into a code input-output prediction format.
By training models to predict inputs/outputs given code and test cases entirely in natural language as Chain-of-Thought (CoT) rationales, we expose them to universal reasoning primitives — like logic flow planning, state-space searching, decision tree traversal, and modular decomposition — while decoupling structured reasoning from code-specific syntax and preserving procedural rigor.
Experimental results demonstrate that CodeI/O leads to consistent improvements across symbolic, scientific, logic, math & numerical, and commonsense reasoning tasks.
By matching the existing ground-truth outputs or re-executing the code with predicted inputs, we can verify each prediction and further enhance the CoTs through multi-turn revision, resulting in CodeI/O++ and achieving higher performance.
2.8. Competitive Programming with Large Reasoning Models

We show that reinforcement learning applied to large language models (LLMs) significantly boosts performance on complex coding and reasoning tasks.
Additionally, we compare two general-purpose reasoning models — OpenAI o1 and an early checkpoint of o3 — with a domain-specific system, o1-ioi, which uses hand-engineered inference strategies designed for competing in the 2024 International Olympiad in Informatics (IOI).
We competed live at IOI 2024 with o1-ioi and, using hand-crafted test-time strategies, placed in the 49th percentile. Under relaxed competition constraints, o1-ioi achieved a gold medal.
However, when evaluating later models such as o3, we find that o3 achieves gold without hand-crafted domain-specific strategies or relaxed constraints.
Our findings show that although specialized pipelines such as o1-ioi yield solid improvements, the scaled-up, general-purpose o3 model surpasses those results without relying on hand-crafted inference heuristics.
Notably, o3 achieved a gold medal at the 2024 IOI and obtained a Codeforces rating on par with elite human competitors. Overall, these results indicate that scaling general-purpose reinforcement learning, rather than relying on domain-specific techniques, offers a robust path toward state-of-the-art AI in reasoning domains, such as competitive programming.
3. LLM Preference Optimization & Alignment
3.1. Teaching Language Models to Critique via Reinforcement Learning

Teaching large language models (LLMs) to critique and refine their outputs is crucial for building systems that can iteratively improve, yet it is fundamentally limited by the ability to provide accurate judgments and actionable suggestions.
In this work, we study LLM critics for code generation and propose CTRL, a framework for Critic Training via Reinforcement Learning, which trains a critic model to generate feedback that maximizes correction performance for a fixed generator model without human supervision.
Our results demonstrate that critics trained with CTRL significantly enhance pass rates and mitigate compounding errors across both base and stronger generator models.
Furthermore, we show that these critic models act as accurate generative reward models and enable test-time scaling through iterative critique-revision, achieving up to 106.1% relative improvements across challenging code generation benchmarks.
3.2. Training Language Models for Social Deduction with Multi-Agent Reinforcement Learning

Communicating in natural language is a powerful tool in multi-agent settings, as it enables independent agents to share information in partially observable settings and allows zero-shot coordination with humans.
However, most prior works are limited as they either rely on training with large amounts of human demonstrations or lack the ability to generate natural and useful communication strategies.
In this work, we train language models to have productive discussions about their environment in natural language without any human demonstrations. We decompose the communication problem into listening and speaking.
Our key idea is to leverage the agent’s goal to predict useful information about the world as a dense reward signal that guides communication. Specifically, we improve a model’s listening skills by training them to predict information about the environment based on discussions, and we simultaneously improve a model’s speaking skills with multi-agent reinforcement learning by rewarding messages based on their influence on other agents.
To investigate the role and necessity of communication in complex social settings, we study an embodied social deduction game based on Among Us, where the key question to answer is the identity of an adversarial imposter.
We analyze emergent behaviors due to our technique, such as accusing suspects and providing evidence, and find that it enables strong discussions, doubling the win rates compared to standard RL.
4. LLM Scaling & Optimization
4.1. Distillation Scaling Laws
We provide a distillation scaling law that estimates distilled model performance based on a computed budget and its allocation between the student and teacher.
Our findings reduce the risks associated with using distillation at scale; compute allocation for both the teacher and student models can now be done to maximize student performance.
We provide compute optimal distillation recipes for when 1) a teacher exists, or 2) a teacher needs training. If many students are to be distilled, or a teacher already exists, distillation outperforms supervised pretraining until a computing level grows predictably with student size.
If one student is to be distilled and a teacher also needs training, supervised learning should be done instead. Additionally, we provide insights across our large-scale study of distillation, which increases our understanding of distillation and informs experimental design.
4.2. Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling
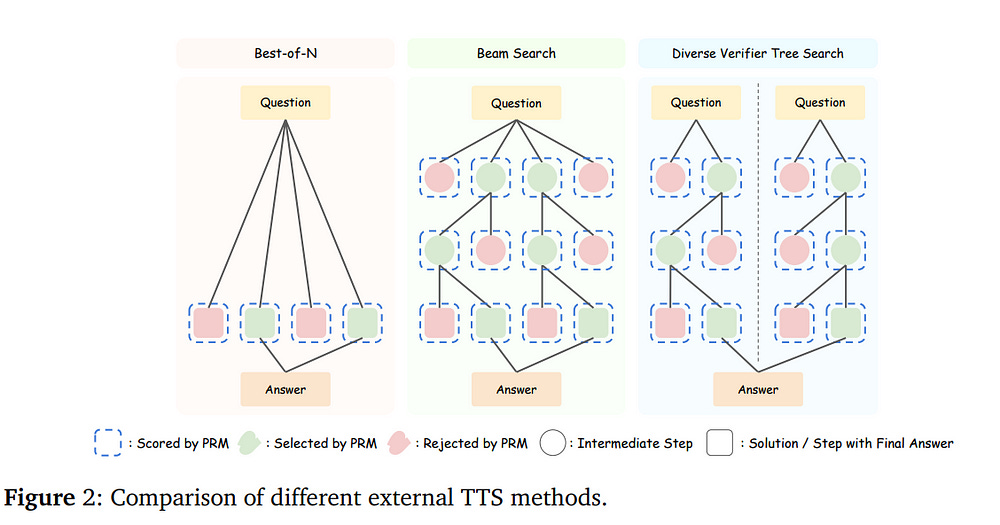
Test-time scaling (TTS) is an important method for improving the performance of Large Language Models (LLMs) by using additional computation during the inference phase.
However, current studies do not systematically analyze how policy models, Process Reward Models (PRMs), and problem difficulty influence TTS. This lack of analysis limits the understanding and practical use of TTS methods. In this paper, we focus on two core questions:
What is the optimal approach to scale test-time computation across different policy models, PRMs, and problem difficulty levels?
To what extent can extended computation improve the performance of LLMs on complex tasks, and can smaller language models outperform larger ones through this approach?
Through comprehensive experiments on MATH-500 and challenging AIME24 tasks, we have the following observations:
The compute-optimal TTS strategy is highly dependent on the choice of policy model, PRM, and problem difficulty.
With our compute-optimal TTS strategy, extremely small policy models can outperform larger models. For example, a 1B LLM can exceed a 405B LLM on MATH-500.
Moreover, on both MATH-500 and AIME24, a 0.5B LLM outperforms GPT-4o, a 3B LLM surpasses a 405B LLM, and a 7B LLM beats o1 and DeepSeek-R1, while with higher inference efficiency.
These findings show the significance of adapting TTS strategies to the specific characteristics of each task and model and indicate that TTS is a promising approach for enhancing the reasoning abilities of LLMs.
4.3. Matryoshka Quantization

Quantizing model weights is critical for reducing the communication and inference costs of large models. However, quantizing models — especially to low precisions like int4 or int2 — requires a trade-off in model quality; int2, in particular, is known to severely degrade model quality.
Consequently, practitioners are often forced to maintain multiple models with different quantization levels or serve a single model that best satisfies the quality-latency trade-off.
On the other hand, integer data types, such as int8, inherently possess a nested (Matryoshka) structure where smaller bit-width integers, like int4 or int2, are nested within the most significant bits.
This paper proposes Matryoshka Quantization (MatQuant), a novel multi-scale quantization technique that addresses the challenge of needing multiple quantized models.
It allows training and maintaining just one model, which can then be served at different precision levels. Furthermore, due to the co-training and co-distillation regularization provided by MatQuant, the int2 precision models extracted by MatQuant can be up to 10% more accurate than standard int2 quantization (using techniques like QAT or OmniQuant).
This represents significant progress in model quantization, demonstrated by the fact that, with the same recipe, an int2 FFN-quantized Gemma-2 9B model is more accurate than an int8 FFN-quantized Gemma-2 2B model.
5. Retrieval Augmented Generation (RAG)
5.1. Retrieval-augmented Large Language Models for Financial Time Series Forecasting
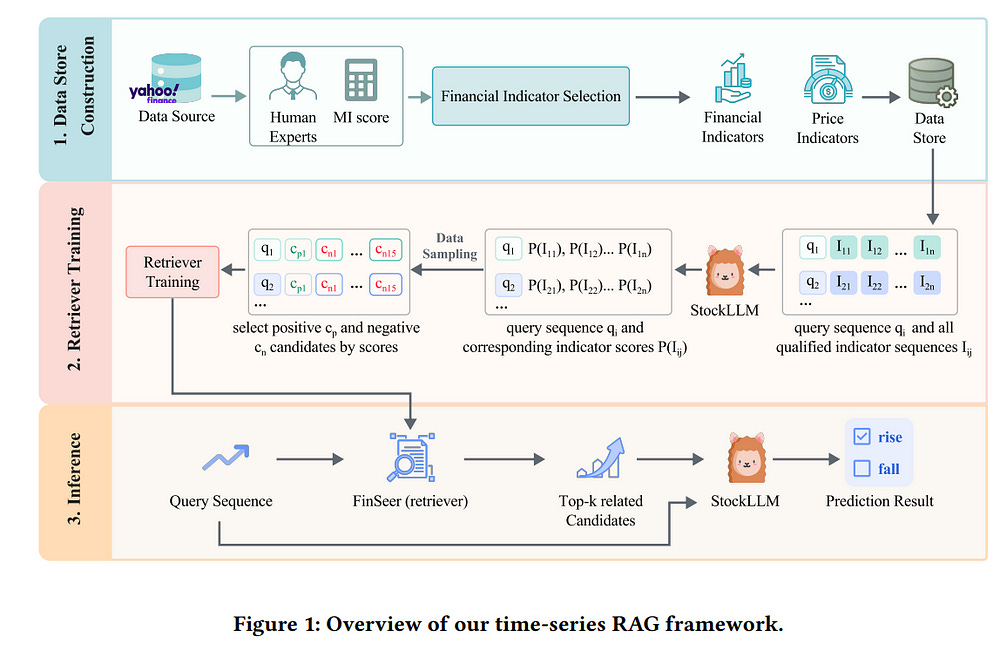
Stock movement prediction, a fundamental task in financial time-series forecasting, requires identifying and retrieving critical influencing factors from vast amounts of time-series data. However, existing text-trained or numeric similarity-based retrieval methods fall short in handling complex financial analysis.
To address this, we propose the first retrieval-augmented generation (RAG) framework for financial time-series forecasting, featuring three key innovations: a fine-tuned 1B parameter large language model (StockLLM) as the backbone, a novel candidate selection method leveraging LLM feedback, and a training objective that maximizes similarity between queries and historically significant sequences.
This enables our retriever, FinSeer, to uncover meaningful patterns while minimizing noise in complex financial data. We also construct new datasets integrating financial indicators and historical stock prices to train FinSeer and ensure robust evaluation.
Experimental results demonstrate that our RAG framework outperforms bare StockLLM and random retrieval, highlighting its effectiveness, while FinSeer surpasses existing retrieval methods, achieving an 8% higher accuracy on BIGDATA22 and retrieving more impactful sequences.
This work underscores the importance of tailored retrieval models in financial forecasting and provides a novel framework for future research.
6. Attention Models
6.1. TransMLA: Multi-head Latent Attention Is All You Need
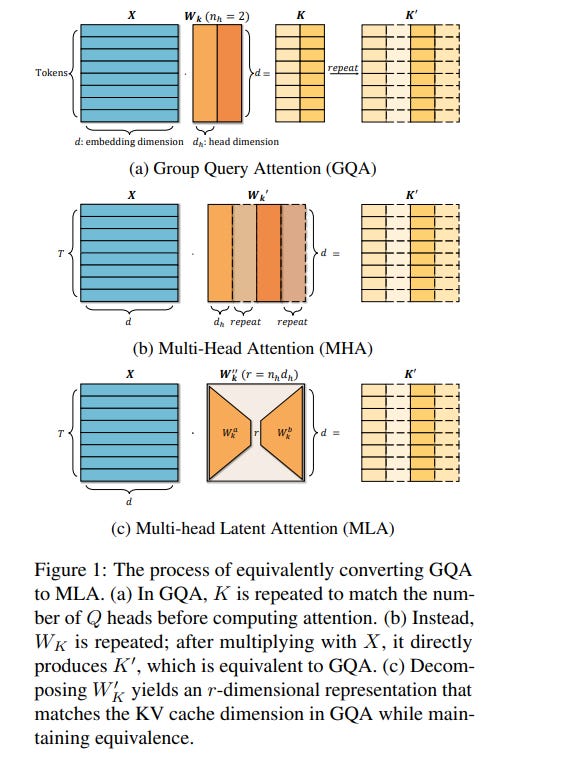
Modern large language models (LLMs) often encounter communication bottlenecks on current hardware, rather than purely computational constraints.
Multi-head Latent Attention (MLA) tackles this challenge by using low-rank matrices in the key-value (KV) layers, thereby allowing compressed latent KV states to be cached. This approach significantly reduces the KV cache size relative to traditional multi-head attention, leading to faster inference.
Moreover, MLA employs an up-projection matrix to increase expressiveness, trading additional computation for reduced communication overhead. Although MLA has demonstrated efficiency and effectiveness in Deepseek V2/V3/R1, many major model providers still rely on Group Query Attention (GQA) and have not announced any plans to adopt MLA.
In this paper, we show that GQA can always be represented by MLA while maintaining the same KV cache overhead, but the converse does not hold. To encourage broader use of MLA, we introduce **TransMLA**, a post-training method that converts widely used GQA-based pre-trained models (e.g., LLaMA, Qwen, Mixtral) into MLA-based models.
After conversion, the model can undergo additional training to boost expressiveness without increasing the KV cache size. Furthermore, we plan to develop MLA-specific inference acceleration techniques to preserve low latency in transformed models, thus enabling more efficient distillation of Deepseek R1.
6.2. LASP-2: Rethinking Sequence Parallelism for Linear Attention and Its Hybrid

Linear sequence modeling approaches, such as linear attention, provide advantages like linear-time training and constant-memory inference over sequence lengths.
However, existing sequence parallelism (SP) methods are either not optimized for the right-product-first feature of linear attention or use a ring-style communication strategy, which results in lower computation parallelism, and limits their scalability for longer sequences in distributed systems.
In this paper, we introduce LASP-2, a new SP method to enhance both communication and computation parallelism when training linear attention transformer models with very long input sequences.
Compared to previous work LASP, LASP-2 rethinks the minimal communication requirement for SP on linear attention layers and reorganizes the whole communication-computation workflow of LASP.
In this way, only one single AllGather collective communication is needed on intermediate memory states, whose sizes are independent of the sequence length, leading to significant improvements in communication and computation parallelism and their overlap.
Additionally, we extend LASP-2 to LASP-2H by applying a similar communication redesign to standard attention modules, offering an efficient SP solution for hybrid models that blend linear and standard attention layers.
Our evaluation of a Linear-Llama3 model, a variant of Llama3 with linear attention replacing standard attention, demonstrates the effectiveness of LASP-2 and LASP-2H. Specifically, LASP-2 achieves training speed improvements of 15.2% over LASP and 36.6% over Ring Attention, with a sequence length of 2048K across 64 GPUs.
7. LLM Evaluation & Benchmarking
7.1. MME-CoT: Benchmarking Chain-of-Thought in Large Multimodal Models for Reasoning Quality, Robustness, and Efficiency
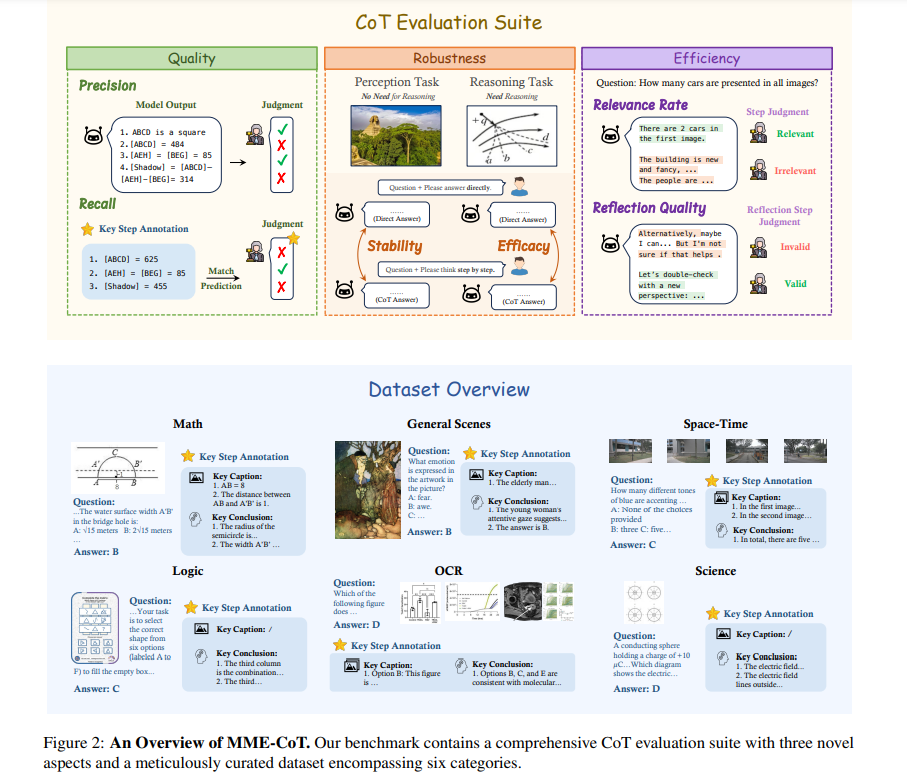
Answering questions with Chain-of-Thought (CoT) has significantly enhanced the reasoning capabilities of Large Language Models (LLMs), yet its impact on Large Multimodal Models (LMMs) still lacks a systematic assessment and in-depth investigation.
In this paper, we introduce MME-CoT, a specialized benchmark evaluating the CoT reasoning performance of LMMs, spanning six domains: math, science, OCR, logic, space-time, and general scenes.
As the first comprehensive study in this area, we propose a thorough evaluation suite incorporating three novel metrics that assess the reasoning quality, robustness, and efficiency at a fine-grained level.
Leveraging curated high-quality data and a unique evaluation strategy, we conduct an in-depth analysis of state-of-the-art LMMs, uncovering several key insights:
Models with reflection mechanism demonstrate a superior CoT quality, with Kimi k1.5 outperforming GPT-4o and demonstrating the highest quality results
CoT prompting often degrades LMM performance on perception-heavy tasks, suggesting a potentially harmful overthinking behavior
Although the CoT quality is high, LMMs with reflection exhibit significant inefficiency in both normal response and self-correction phases.
7.2. NoLiMa: Long-Context Evaluation Beyond Literal Matching
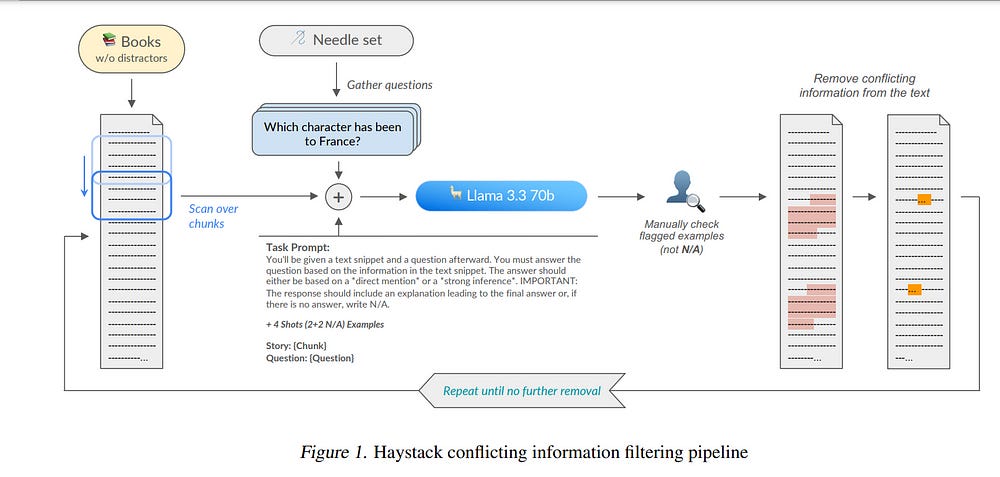
Recent large language models (LLMs) support long contexts ranging from 128K to 1M tokens. A popular method for evaluating these capabilities is the needle-in-a-haystack (NIAH) test, which involves retrieving a “needle” (relevant information) from a “haystack” (long irrelevant context). Extensions of this approach include increasing distractors, fact chaining, and in-context reasoning.
However, in these benchmarks, models can exploit existing literal matches between the needle and haystack to simplify the task. To address this, we introduce NoLiMa, a benchmark extending NIAH with a carefully designed needle set, where questions and needles have minimal lexical overlap, requiring models to infer latent associations to locate the needle within the haystack.
We evaluate 12 popular LLMs that claim to support contexts of at least 128K tokens. While they perform well in short contexts (<1K), performance degrades significantly as context length increases.
At 32K, for instance, 10 models drop below 50% of their strong short-length baselines. Even GPT-4o, one of the top-performing exceptions, experiences a reduction from an almost-perfect baseline of 99.3% to 69.7%.
Our analysis suggests these declines stem from the increased difficulty the attention mechanism faces in longer contexts when literal matches are absent, making it harder to retrieve relevant information.
7.3. BenchMAX: A Comprehensive Multilingual Evaluation Suite for Large Language Models

Previous multilingual benchmarks focus primarily on simple understanding tasks, but for large language models(LLMs), we emphasize proficiency in instruction following, reasoning, long context understanding, code generation, and so on.
However, measuring these advanced capabilities across languages is underexplored. To address the disparity, we introduce BenchMAX, a multi-way multilingual evaluation benchmark that allows for fair comparisons of these important abilities across languages.
To maintain high quality, three distinct native-speaking annotators independently annotated each sample within all tasks after the data was machine-translated from English into 16 other languages. Additionally, we present a novel translation challenge stemming from dataset construction.
Extensive experiments on BenchMAX reveal varying effectiveness of core capabilities across languages, highlighting performance gaps that cannot be bridged by simply scaling up model size.
BenchMAX serves as a comprehensive multilingual evaluation platform, providing a promising test bed to promote the development of multilingual language models. The dataset and code are publicly accessible.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
