


Important LLMs Papers for the Week from 16/09 to 22/09
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Third Week of September 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Scaling
Tokenizers & Embeddings
LLM Quantization & Optimization
LLM Training, Evaluation & Inference
LLM Reasoning
Retrieval Augmented Generation (RAG)
Transformers & Attention Based Models
My New E-Book: Prompt Engineering Best Practices for Instruction-Tuned LLM

I am happy to announce that I have published a new ebook Prompt Engineering Best Practices for Instruction-Tuned LLM. Prompt Engineering Best Practices for Instruction-Tuned LLM is a comprehensive guide designed to equip readers with the essential knowledge and tools to master the fine-tuning and prompt engineering of large language models (LLMs). The book covers everything from foundational concepts to advanced applications, making it an invaluable resource for anyone interested in leveraging the full potential of instruction-tuned models.
1. LLM Progress & Benchmarking
1.1. Qwen2.5-Coder Technical Report

In this report, we introduce the Qwen2.5-Coder series, a significant upgrade from its predecessor, CodeQwen1.5. This series includes two models: Qwen2.5-Coder-1.5B and Qwen2.5-Coder-7B.
As a code-specific model, Qwen2.5-Coder is built upon the Qwen2.5 architecture and continues pretrained on a vast corpus of over 5.5 trillion tokens. Through meticulous data cleaning, scalable synthetic data generation, and balanced data mixing, Qwen2.5-Coder demonstrates impressive code generation capabilities while retaining general versatility.
The model has been evaluated on a wide range of code-related tasks, achieving state-of-the-art (SOTA) performance across more than 10 benchmarks, including code generation, completion, reasoning, and repair, consistently outperforming larger models of the same model size.
We believe that the release of the Qwen2.5-Coder series will not only push the boundaries of research in code intelligence but also, through its permissive licensing, encourage broader adoption by developers in real-world applications.
1.2. LLMs + Persona-Plug = Personalized LLMs

Personalization plays a critical role in numerous language tasks and applications, since users with the same requirements may prefer diverse outputs based on their individual interests.
This has led to the development of various personalized approaches aimed at adapting large language models (LLMs) to generate customized outputs aligned with user preferences. Some of them involve fine-tuning a unique personalized LLM for each user, which is too expensive for widespread application.
Alternative approaches introduce personalization information in a plug-and-play manner by retrieving the user’s relevant historical texts as demonstrations. However, this retrieval-based strategy may break the continuity of the user history and fail to capture the user’s overall styles and patterns, hence leading to sub-optimal performance.
To address these challenges, we propose a novel personalized LLM model, It constructs a user-specific embedding for each individual by modeling all her historical contexts through a lightweight plug-in user embedder module.
By attaching this embedding to the task input, LLMs can better understand and capture user habits and preferences, thereby producing more personalized outputs without tuning their own parameters.
Extensive experiments on various tasks in the language model personalization (LaMP) benchmark demonstrate that the proposed model significantly outperforms existing personalized LLM approaches.
1.3. NVLM: Open Frontier-Class Multimodal LLMs

We introduce NVLM 1.0, a family of frontier-class multimodal large language models (LLMs) that achieve state-of-the-art results on vision-language tasks, rivaling the leading proprietary models (e.g., GPT-4o) and open-access models (e.g., Llama 3-V 405B and InternVL 2).
Remarkably, NVLM 1.0 shows improved text-only performance over its LLM backbone after multimodal training. In terms of model design, we perform a comprehensive comparison between decoder-only multimodal LLMs (e.g., LLaVA) and cross-attention-based models (e.g., Flamingo).
Based on the strengths and weaknesses of both approaches, we propose a novel architecture that enhances both training efficiency and multimodal reasoning capabilities.
Furthermore, we introduce a 1-D tile-tagging design for tile-based dynamic high-resolution images, which significantly boosts performance on multimodal reasoning and OCR-related tasks. Regarding training data, we meticulously curate and provide detailed information on our multimodal pretraining and supervised fine-tuning datasets.
Our findings indicate that dataset quality and task diversity are more important than scale, even during the pretraining phase, across all architectures.
Notably, we develop production-grade multimodality for the NVLM-1.0 models, enabling them to excel in vision-language tasks while maintaining and even improving text-only performance compared to their LLM backbones.
To achieve this, we craft and integrate a high-quality text-only dataset into multimodal training, alongside a substantial amount of multimodal math and reasoning data, leading to enhanced math and coding capabilities across modalities.
1.4. A Controlled Study on Long Context Extension and Generalization in LLMs

Broad textual understanding and in-context learning require language models that utilize full document contexts. Due to the implementation challenges associated with directly training long-context models, many methods have been proposed for extending models to handle long contexts.
However, owing to differences in data and model classes, it has been challenging to compare these approaches, leading to uncertainty as to how to evaluate long-context performance and whether it differs from standard evaluation.
We implement a controlled protocol for extension methods with a standardized evaluation, utilizing consistent base models and extension data.
Our study yields several insights into long-context behavior. First, we reaffirm the critical role of perplexity as a general-purpose performance indicator even in longer-context tasks.
Second, we find that current approximate attention methods systematically underperform across long-context tasks. Finally, we confirm that exact fine-tuning-based methods are generally effective within the range of their extension, whereas extrapolation remains challenging.
All codebases, models, and checkpoints will be made available open-source, promoting transparency and facilitating further research in this critical area of AI development.
2. LLM Scaling
2.1. Scaling Smart: Accelerating Large Language Model Pre-training with Small Model Initialization

The pre-training phase of language models often begins with randomly initialized parameters. With the current trends in scaling models, training their large number of parameters can be extremely slow and costly. In contrast, small language models are less expensive to train, but they often cannot achieve the accuracy of large models.
In this paper, we explore an intriguing idea to connect these two different regimes: Can we develop a method to initialize large language models using smaller pre-trained models? Will such initialization bring any benefits in terms of training time and final accuracy?
In this paper, we introduce HyperCloning, a method that can expand the parameters of a pre-trained language model to those of a larger model with increased hidden dimensions.
Our method ensures that the larger model retains the functionality of the smaller model. As a result, the larger model already inherits the predictive power and accuracy of the smaller model before the training starts.
We demonstrate that training such an initialized model results in significant savings in terms of GPU hours required for pre-training large language models.
3. Tokenizers & Embeddings
3.1. Jina-embeddings-v3: Multilingual Embeddings With Task LoRA

We introduce jina-embeddings-v3, a novel text embedding model with 570 million parameters, that achieves state-of-the-art performance on multilingual data and long-context retrieval tasks, supporting context lengths of up to 8192 tokens.
The model includes a set of task-specific Low-Rank Adaptation (LoRA) adapters to generate high-quality embeddings for query-document retrieval, clustering, classification, and text matching.
Additionally, Matryoshka Representation Learning is integrated into the training process, allowing flexible truncation of embedding dimensions without compromising performance.
Evaluation on the MTEB benchmark shows that jina-embeddings-v3 outperforms the latest proprietary embeddings from OpenAI and Cohere on English tasks while achieving superior performance compared to multilingual-e5-large-instruct across all multilingual tasks.
4. LLM Quantization & Optimization
4.1. A Comprehensive Evaluation of Quantized Instruction-Tuned Large Language Models: An Experimental Analysis up to 405B
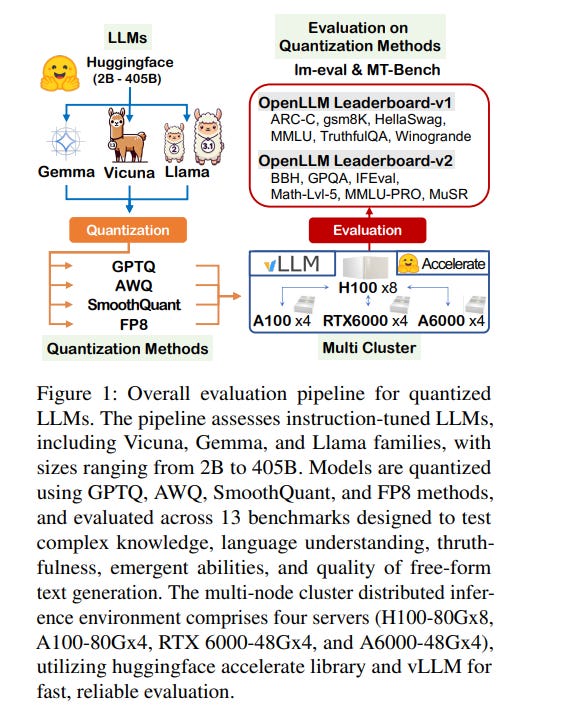
Prior research works have evaluated quantized LLMs using limited metrics such as perplexity or a few basic knowledge tasks and old datasets. Additionally, recent large-scale models such as Llama 3.1 with up to 405B have not been thoroughly examined.
This paper evaluates the performance of instruction-tuned LLMs across various quantization methods (GPTQ, AWQ, SmoothQuant, and FP8) on models ranging from 7B to 405B.
Using 13 benchmarks, we assess performance across six task types: commonsense Q\&A, knowledge and language understanding, instruction following, hallucination detection, mathematics, and dialogue.
Our key findings reveal that
Quantizing a larger LLM to a similar size as a smaller FP16 LLM generally performs better across most benchmarks, except for hallucination detection and instruction following
Performance varies significantly with different quantization methods, model size, and bit-width, with weight-only methods often yielding better results in larger models.
Task difficulty does not significantly impact accuracy degradation due to quantization.
The MT-Bench evaluation method has limited discriminatory power among recent high-performing LLMs.
5. LLM Training, Evaluation & Inference
5.1. Preference Tuning with Human Feedback on Language, Speech, and Vision Tasks: A Survey

Preference tuning is a crucial process for aligning deep generative models with human preferences. This survey offers a thorough overview of recent advancements in preference tuning and the integration of human feedback.
The paper is organized into three main sections:
Introduction and preliminaries: an introduction to reinforcement learning frameworks, preference tuning tasks, models, and datasets across various modalities: language, speech, and vision, as well as different policy approaches,
In-depth examination of each preference tuning approach: a detailed analysis of the methods used in preference tuning
Applications, discussion, and future directions: an exploration of the applications of preference tuning in downstream tasks, including evaluation methods for different modalities, and an outlook on future research directions.
Our objective is to present the latest methodologies in preference tuning and model alignment, enhancing the understanding of this field for researchers and practitioners. We hope to encourage further engagement and innovation in this area.
5.2. Training Language Models to Self-Correct via Reinforcement Learning

Self-correction is a highly desirable capability of large language models (LLMs), yet it has consistently been found to be largely ineffective in modern LLMs. Existing approaches for training self-correction either require multiple models or rely on a more capable model or other forms of supervision.
To this end, we develop a multi-turn online reinforcement learning (RL) approach, SCoRe, that significantly improves an LLM’s self-correction ability using entirely self-generated data.
To build SCoRe, we first show that variants of supervised fine-tuning (SFT) on offline model-generated correction traces are insufficient for instilling self-correction behavior.
In particular, we observe that training via SFT either suffers from a distribution mismatch between the training data and the model’s own responses or implicitly prefers only a certain mode of correction behavior that is often not effective at test time.
SCoRe addresses these challenges by training under the model’s own distribution of self-generated correction traces and using appropriate regularization to steer the learning process into learning a self-correction strategy that is effective at test time as opposed to simply fitting high-reward responses for a given prompt.
This regularization prescribes running a first phase of RL on a base model to generate a policy initialization that is less susceptible to collapse and then using a reward bonus to amplify self-correction during training.
When applied to Gemini 1.0 Pro and 1.5 Flash models, we find that SCoRe achieves state-of-the-art self-correction performance, improving the base models’ self-correction by 15.6% and 9.1% respectively on the MATH and HumanEval benchmarks.
5.3. B4: Towards Optimal Assessment of Plausible Code Solutions with Plausible Tests

Selecting the best code solution from multiple generated ones is an essential task in code generation, which can be achieved by using some reliable validators (e.g., developer-written test cases) for assistance.
Since reliable test cases are not always available and can be expensive to build in practice, researchers propose to automatically generate test cases to assess code solutions.
However, when both code solutions and test cases are plausible and not reliable, selecting the best solution becomes challenging. Although some heuristic strategies have been proposed to tackle this problem, they lack a strong theoretical guarantee and it is still an open question whether an optimal selection strategy exists.
Our work contributes in two ways. First, we show that within a Bayesian framework, the optimal selection strategy can be defined based on the posterior probability of the observed passing states between solutions and tests. The problem of identifying the best solution is then framed as an integer programming problem.
Second, we propose an efficient approach for approximating this optimal (yet uncomputable) strategy, where the approximation error is bounded by the correctness of prior knowledge. We then incorporate effective prior knowledge to tailor code generation tasks.
Both theoretical and empirical studies confirm that existing heuristics are limited in selecting the best solutions with plausible test cases. Our proposed approximated optimal strategy B4 significantly surpasses existing heuristics in selecting code solutions generated by large language models (LLMs) with LLM-generated tests, achieving a relative performance improvement by up to 50% over the strongest heuristic and 246% over the random selection in the most challenging scenarios.
6. LLM Reasoning
6.1. To CoT or not to CoT? Chain-of-thought helps mainly with math and symbolic reasoning

Chain-of-thought (CoT) via prompting is the de facto method for eliciting reasoning capabilities from large language models (LLMs). But for what kinds of tasks is this extra ``thinking’’ really helpful? To analyze this, we conducted a quantitative meta-analysis covering over 100 papers using CoT and ran our own evaluations of 20 datasets across 14 models.
Our results show that CoT gives strong performance benefits primarily on tasks involving math or logic, with much smaller gains on other types of tasks. On MMLU, directly generating the answer without CoT leads to almost identical accuracy as CoT unless the question or model’s response contains an equals sign, indicating symbolic operations and reasoning.
Following this finding, we analyze the behavior of CoT on these problems by separating planning and execution and comparing them against tool-augmented LLMs. Much of CoT’s gain comes from improving symbolic execution, but it underperforms relative to using a symbolic solver.
Our results indicate that CoT can be applied selectively, maintaining performance while saving inference costs. Furthermore, they suggest a need to move beyond prompt-based CoT to new paradigms that better leverage intermediate computation across the whole range of LLM applications.
6.2. InfiMM-WebMath-40B: Advancing Multimodal Pre-Training for Enhanced Mathematical Reasoning

Pre-training on large-scale, high-quality datasets is crucial for enhancing the reasoning capabilities of Large Language Models (LLMs), especially in specialized domains such as mathematics.
Despite the recognized importance, the Multimodal LLMs (MLLMs) field currently lacks a comprehensive open-source pre-training dataset specifically designed for mathematical reasoning. To address this gap, we introduce InfiMM-WebMath-40B, a high-quality dataset of interleaved image-text documents.
It comprises 24 million web pages, 85 million associated image URLs, and 40 billion text tokens, all meticulously extracted and filtered from CommonCrawl. We provide a detailed overview of our data collection and processing pipeline.
To demonstrate the robustness of InfiMM-WebMath-40B, we conducted evaluations in both text-only and multimodal settings. Our evaluations on text-only benchmarks show that, despite utilizing only 40 billion tokens, our dataset significantly enhances the performance of our 1.3B model, delivering results comparable to DeepSeekMath-1.3B, which uses 120 billion tokens for the same model size.
Nevertheless, with the introduction of our multi-modal math pre-training dataset, our models set a new state-of-the-art among open-source models on multi-modal math benchmarks such as MathVerse and We-Math.
7. Retrieval Augmented Generation (RAG)
7.1. RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval

Transformer-based large Language Models (LLMs) become increasingly important in various domains. However, the quadratic time complexity of attention operation poses a significant challenge for scaling to longer contexts due to the extremely high inference latency and GPU memory consumption for caching key-value (KV) vectors.
This paper proposes RetrievalAttention, a training-free approach to accelerate attention computation. To leverage the dynamic sparse property of attention, RetrievalAttention builds approximate nearest neighbor search (ANNS) indexes upon KV vectors in CPU memory and retrieves the most relevant ones via vector search during generation.
Due to the out-of-distribution (OOD) between query vectors and key vectors, off-the-shelf ANNS indexes still need to scan O(N) (usually 30% of all keys) data for accurate retrieval, which fails to exploit the high sparsity.
RetrievalAttention first identifies the OOD challenge of ANNS-based attention, and addresses it via an attention-aware vector search algorithm that can adapt to queries and only access 1–3% of data, thus achieving a sub-linear time complexity.
RetrievalAttention greatly reduces the inference cost of long-context LLM with much lower GPU memory requirements while maintaining the model accuracy. RetrievalAttention only needs 16GB GPU memory for serving 128K tokens in LLMs with 8B parameters, which is capable of generating one token in 0.188 seconds on a single NVIDIA RTX4090 (24GB).
8. Transformers & Attention Based Models
8.1. Kolmogorov-Arnold Transformer
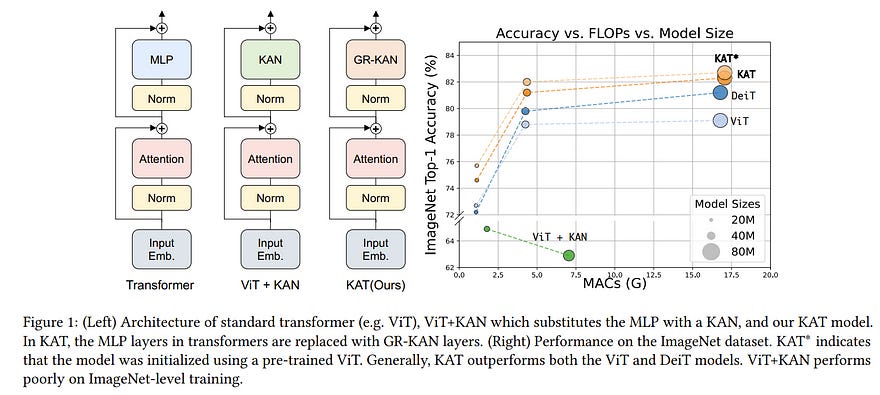
Transformers stand as the cornerstone of modern deep learning. Traditionally, these models rely on multi-layer perceptron (MLP) layers to mix the information between channels.
In this paper, we introduce the Kolmogorov-Arnold Transformer (KAT), a novel architecture that replaces MLP layers with Kolmogorov-Arnold Network (KAN) layers to enhance the expressiveness and performance of the model. Integrating KANs into transformers, however, is no easy feat, especially when scaled up.
Specifically, we identify three key challenges: (C1) Base function. The standard B-spline function used in KANs is not optimized for parallel computing on modern hardware, resulting in slower inference speeds. (C2) Parameter and Computation Inefficiency.
KAN requires a unique function for each input-output pair, making the computation extremely large. (C3) Weight initialization. The initialization of weights in KANs is particularly challenging due to their learnable activation functions, which are critical for achieving convergence in deep neural networks.
To overcome the aforementioned challenges, we propose three key solutions: (S1) Rational basis. We replace B-spline functions with rational functions to improve compatibility with modern GPUs. By implementing this in CUDA, we achieve faster computations. (S2) Group KAN.
We share the activation weights through a group of neurons, to reduce the computational load without sacrificing performance. (S3) Variance-preserving initialization.
We carefully initialize the activation weights to make sure that the activation variance is maintained across layers. With these designs, KAT scales effectively and readily outperforms traditional MLP-based transformers.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
