


Important LLMs Papers for the Week from 21/10 to 27/10
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Fourth Week of October 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Training, Evaluation & Inference
LLM Alignment & Safety
LLM Reasoning
LLM Agents
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. LLM Progress & Benchmarking
1.1. CAMEL-Bench: A Comprehensive Arabic LMM Benchmark

In recent years, there has been a significant interest in developing large multimodal models (LMMs) capable of performing various visual reasoning and understanding tasks.
This has led to the introduction of multiple LMM benchmarks to evaluate LMMs on different tasks. However, most existing LMM evaluation benchmarks are predominantly English-centric.
In this work, we develop a comprehensive LMM evaluation benchmark for the Arabic language to represent a large population of over 400 million speakers.
The proposed benchmark, named CAMEL-Bench, comprises eight diverse domains and 38 sub-domains including, multi-image understanding, complex visual perception, handwritten document understanding, video understanding, medical imaging, plant diseases, and remote sensing-based land use understanding to evaluate broad scenario generalizability.
Our CAMEL-Bench comprises around 29,036 questions that are filtered from a larger pool of samples, where the quality is manually verified by native speakers to ensure reliable model assessment.
We conduct evaluations of both closed-source, including GPT-4 series, and open-source LMMs. Our analysis reveals the need for substantial improvement, especially among the best open-source models, with even the closed-source GPT-4o achieving an overall score of 62%. Our benchmark and evaluation scripts are open-sourced.
1.2. UCFE: A User-Centric Financial Expertise Benchmark for Large Language Models

This paper introduces the UCFE: User-Centric Financial Expertise benchmark, an innovative framework designed to evaluate the ability of large language models (LLMs) to handle complex real-world financial tasks.
UCFE benchmark adopts a hybrid approach that combines human expert evaluations with dynamic, task-specific interactions to simulate the complexities of evolving financial scenarios.
Firstly, we conducted a user study involving 804 participants, collecting their feedback on financial tasks. Secondly, based on this feedback, we created our dataset that encompasses a wide range of user intents and interactions.
This dataset serves as the foundation for benchmarking 12 LLM services using the LLM-as-Judge methodology. Our results show a significant alignment between benchmark scores and human preferences, with a Pearson correlation coefficient of 0.78, confirming the effectiveness of the UCFE dataset and our evaluation approach.
UCFE benchmark not only reveals the potential of LLMs in the financial sector but also provides a robust framework for assessing their performance and user satisfaction. The benchmark dataset and evaluation code are available.
1.3. Mini-Omni2: Towards Open-source GPT-4o with Vision, Speech and Duplex Capabilities

GPT-4o, an all-encompassing model, represents a milestone in the development of large multi-modal language models. It can understand visual, auditory, and textual modalities, directly output audio, and support flexible duplex interaction.
Models from the open-source community often achieve some functionalities of GPT-4o, such as visual understanding and voice chat. Nevertheless, training a unified model that incorporates all modalities is challenging due to the complexities of multi-modal data, intricate model architectures, and training processes.
In this paper, we introduce Mini-Omni2, a visual-audio assistant capable of providing real-time, end-to-end voice responses to visual and audio queries. By integrating pretrained visual and auditory encoders, Mini-Omni2 maintains performance in individual modalities.
We propose a three-stage training process to align modalities, allowing the language model to handle multi-modal inputs and outputs after training on a limited dataset.
For interaction, we introduce a command-based interruption mechanism, enabling more flexible interaction with users. To the best of our knowledge, Mini-Omni2 is one of the closest reproductions of GPT-4o, which has similar form of functionality, and we hope it can offer valuable insights for subsequent research.
1.4. Pangea: A Fully Open Multilingual Multimodal LLM for 39 Languages

Despite recent advances in multimodal large language models (MLLMs), their development has predominantly focused on English- and Western-centric datasets and tasks, leaving most of the world’s languages and diverse cultural contexts underrepresented.
This paper introduces Pangea, a multilingual multimodal LLM trained on PangeaIns, a diverse 6M instruction dataset spanning 39 languages. PangeaIns features
High-quality English instructions
Carefully machine-translated instructions
Culturally relevant multimodal tasks to ensure cross-cultural coverage.
To rigorously assess models’ capabilities, we introduce PangeaBench, a holistic evaluation suite encompassing 14 datasets covering 47 languages. Results show that Pangea significantly outperforms existing open-source models in multilingual settings and diverse cultural contexts.
Ablation studies further reveal the importance of English data proportions, language popularity, and the number of multimodal training samples on overall performance.
We fully open-source our data, code, and trained checkpoints, to facilitate the development of inclusive and robust multilingual MLLMs, promoting equity and accessibility across a broader linguistic and cultural spectrum.
1.5. Can Knowledge Editing Really Correct Hallucinations?

Large Language Models (LLMs) suffer from hallucinations, referring to the non-factual information in generated content, despite their superior capacities across tasks.
Meanwhile, knowledge editing has been developed as a new popular paradigm to correct the erroneous factual knowledge encoded in LLMs with the advantage of avoiding retraining from scratch.
However, one common issue of existing evaluation datasets for knowledge editing is that they do not ensure LLMs actually generate hallucinated answers to the evaluation questions before editing.
When LLMs are evaluated on such datasets after being edited by different techniques, it is hard to directly adopt the performance to assess the effectiveness of different knowledge editing methods in correcting hallucinations.
Thus, the fundamental question remains insufficiently validated: Can knowledge editing really correct hallucinations in LLMs? We proposed HalluEditBench to holistically benchmark knowledge editing methods in correcting real-world hallucinations.
First, we rigorously construct a massive hallucination dataset with 9 domains, 26 topics, and more than 6,000 hallucinations. Then, we assess the performance of knowledge editing methods in a holistic way on five dimensions including Efficacy, Generalization, Portability, Locality, and Robustness.
Through HalluEditBench, we have provided new insights into the potentials and limitations of different knowledge editing methods in correcting hallucinations, which could inspire future improvements and facilitate progress in the field of knowledge editing.
1.6. Unbounded: A Generative Infinite Game of Character Life Simulation

We introduce the concept of a generative infinite game, a video game that transcends the traditional boundaries of finite, hard-coded systems by using generative models.
Inspired by James P. Carse’s distinction between finite and infinite games, we leverage recent advances in generative AI to create Unbounded: a game of character life simulation that is fully encapsulated in generative models.
Specifically, Unbounded draws inspiration from sandbox life simulations and allows you to interact with your autonomous virtual character in a virtual world by feeding, playing with and guiding it — with open-ended mechanics generated by an LLM, some of which can be emergent.
In order to develop Unbounded, we propose technical innovations in both the LLM and visual generation domains. Specifically, we present:
A specialized, distilled large language model (LLM) that dynamically generates game mechanics, narratives, and character interactions in real-time.
A new dynamic regional image prompt Adapter (IP-Adapter) for vision models that ensures consistent yet flexible visual generation of a character across multiple environments.
We evaluate our system through both qualitative and quantitative analysis, showing significant improvements in character life simulation, user instruction following, narrative coherence, and visual consistency for both characters and the environments compared to traditional related approaches.
2. LLM Training, Evaluation & Inference
2.1. NaturalBench: Evaluating Vision-Language Models on Natural Adversarial Samples

Vision-language models (VLMs) have made significant progress in recent visual-question-answering (VQA) benchmarks that evaluate complex visio-linguistic reasoning.
However, are these models truly effective? In this work, we show that VLMs still struggle with natural images and questions that humans can easily answer, which we term natural adversarial samples.
We also find it surprisingly easy to generate these VQA samples from natural image-text corpora using off-the-shelf models like CLIP and ChatGPT. We propose a semi-automated approach to collect a new benchmark, NaturalBench, for reliably evaluating VLMs with 10,000 human-verified VQA samples.
Crucially, we adopt a vision-centric design by pairing each question with two images that yield different answers, preventing blind solutions from answering without using the images.
This makes NaturalBench more challenging than previous benchmarks that can be solved with commonsense priors. We evaluate 53 state-of-the-art VLMs on NaturalBench, showing that models like LLaVA-OneVision, Cambrian-1, Llama3.2-Vision, Molmo, Qwen2-VL, and even GPT-4o lag 50%-70% behind human performance (over 90%).
We analyze why NaturalBench is hard from two angles:
Compositionality: Solving NaturalBench requires diverse Visio-linguistic skills, including understanding attribute bindings, object relationships, and advanced reasoning like logic and counting. To this end, unlike prior work that uses a single tag per sample, we tag each NaturalBench sample with 1 to 8 skill tags for fine-grained evaluation.
Biases: NaturalBench exposes severe biases in VLMs, as models often choose the same answer regardless of the image.
Lastly, we apply our benchmark curation method to diverse data sources, including long captions (over 100 words) and non-English languages like Chinese and Hindi, highlighting its potential for dynamic evaluations of VLMs.
2.2. AutoTrain: No-code training for state-of-the-art models
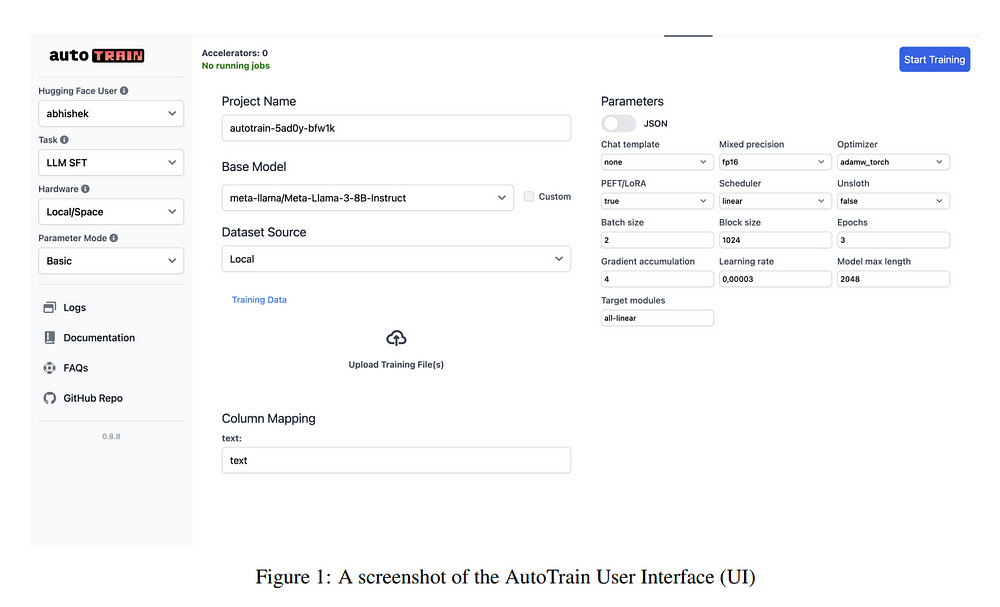
With the advancements in open-source models, training (or finetuning) models on custom datasets has become a crucial part of developing solutions that are tailored to specific industrial or open-source applications.
Yet, there is no single tool that simplifies the process of training across different types of modalities or tasks. We introduce AutoTrain (aka AutoTrain Advanced) — an open-source, no-code tool/library that can be used to train (or finetune) models for different kinds of tasks such as large language model (LLM) finetuning, text classification/regression, token classification, sequence-to-sequence task, finetuning of sentence transformers, visual language model (VLM) finetuning, image classification/regression and even classification and regression tasks on tabular data.
AutoTrain Advanced is an open-source library providing best practices for training models on custom datasets. The library is available at https://github.com/huggingface/autotrain-advanced. AutoTrain can be used in fully local mode or on cloud machines and works with tens of thousands of models shared on Hugging Face Hub and their variations.
2.3. SemiEvol: Semi-supervised Fine-tuning for LLM Adaptation

Supervised fine-tuning (SFT) is crucial in adapting large language models (LLMs) to a specific domain or task. However, only a limited amount of labeled data is available in practical applications, which poses a severe challenge for SFT in yielding satisfactory results.
Therefore, a data-efficient framework that can fully exploit labeled and unlabeled data for LLM fine-tuning is highly anticipated. Towards this end, we introduce a semi-supervised fine-tuning framework named SemiEvol for LLM adaptation from a propagate-and-select manner.
For knowledge propagation, SemiEvol adopts a bi-level approach, propagating knowledge from labeled data to unlabeled data through both in-weight and in-context methods. For knowledge selection, SemiEvol incorporates a collaborative learning mechanism, selecting higher-quality pseudo-response samples. We conducted experiments using GPT-4o-mini and Llama-3.1 on seven general or domain-specific datasets, demonstrating significant improvements in model performance on target data. Furthermore, we compared SemiEvol with SFT and self-evolution methods, highlighting its practicality in hybrid data scenarios.
3. LLM Alignment & Safety
3.1. Baichuan Alignment Technical Report
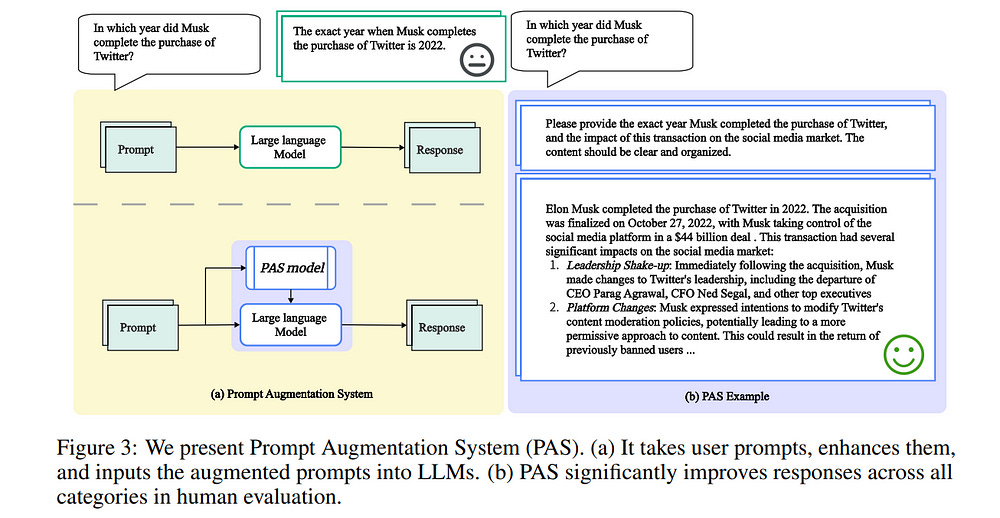
We introduce Baichuan Alignment, a detailed analysis of the alignment techniques employed in the Baichuan series of models. This represents the industry’s first comprehensive account of alignment methodologies, offering valuable insights for advancing AI research.
We investigate the critical components that enhance model performance during the alignment process, including optimization methods, data strategies, capability enhancements, and evaluation processes. The process spans three key stages: Prompt Augmentation System (PAS), Supervised Fine-Tuning (SFT), and Preference Alignment.
The problems encountered, the solutions applied, and the improvements made are thoroughly recorded. Through comparisons across well-established benchmarks, we highlight the technological advancements enabled by Baichuan Alignment.
Baichuan-Instruct is an internal model, while Qwen2-Nova-72B and Llama3-PBM-Nova-70B are instructed versions of the Qwen2–72B and Llama-3–70B base models, optimized through Baichuan Alignment.
Baichuan-Instruct demonstrates significant improvements in core capabilities, with user experience gains ranging from 17% to 28%, and performs exceptionally well on specialized benchmarks.
In open-source benchmark evaluations, both Qwen2-Nova-72B and Llama3-PBM-Nova-70B consistently outperform their respective official instruct versions across nearly all datasets.
This report aims to clarify the key technologies behind the alignment process, fostering a deeper understanding within the community.
3.2. Aligning Large Language Models via Self-Steering Optimization
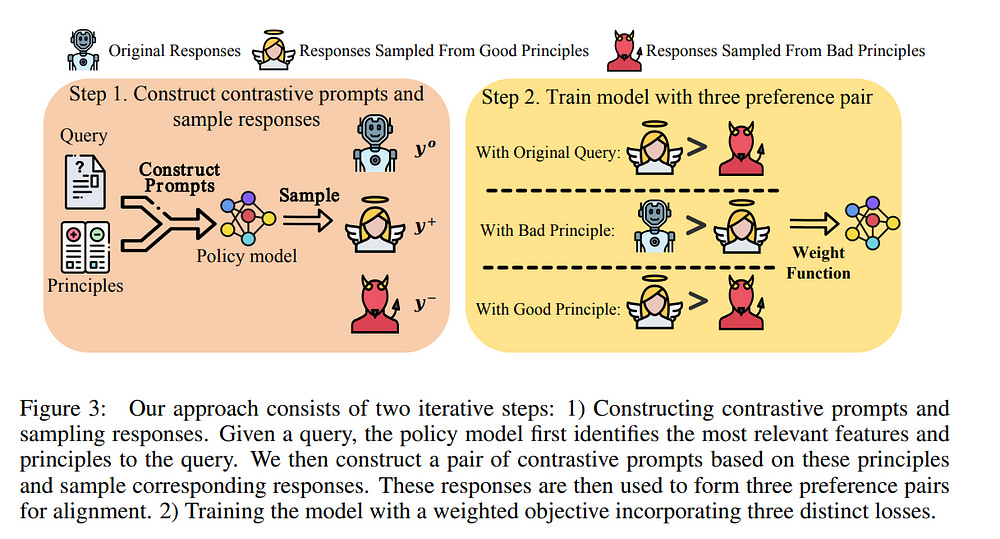
Automated alignment develops alignment systems with minimal human intervention. The key to automated alignment lies in providing learnable and accurate preference signals for preference learning without human annotation.
In this paper, we introduce Self-Steering Optimization (SSO), an algorithm that autonomously generates high-quality preference signals based on predefined principles during iterative training, eliminating the need for manual annotation.
SSO maintains the accuracy of signals by ensuring a consistent gap between chosen and rejected responses while keeping them both on-policy to suit the current policy model’s learning capacity. SSO can benefit the online and offline training of the policy model, as well as enhance the training of reward models.
We validate the effectiveness of SSO with two foundation models, Qwen2 and Llama3.1, indicating that it provides accurate, on-policy preference signals throughout iterative training.
Without any manual annotation or external models, SSO leads to significant performance improvements across six subjective or objective benchmarks. Besides, the preference data generated by SSO significantly enhanced the performance of the reward model on Rewardbench.
Our work presents a scalable approach to preference optimization, paving the way for more efficient and effective automated alignment.
3.3. LOGO — Long cOntext aliGnment via efficient preference Optimization

Long-context models(LCMs) have shown great potential in processing long input sequences(even more than 100M tokens) conveniently and effectively.
With significant progress, recent research has pointed out that LCMs can accurately locate token-level salient information within the context. Yet, the generation performance of these LCMs is far from satisfactory and might result in misaligned responses, such as hallucinations.
To enhance the generation capability of LCMs, existing works have investigated the effects of data size and quality for both pre-training and instruction tuning. Though achieving meaningful improvement, previous methods fall short in either effectiveness or efficiency.
In this paper, we introduce LOGO(Long cOntext aliGnment via efficient preference Optimization), a training strategy that first introduces preference optimization for long-context alignment.
To overcome the GPU memory-bound issue caused by the long sequence, LOGO employs a reference-free preference optimization strategy and adopts a position synthesis method to construct the training data.
By training with only 0.3B data on a single 8timesA800 GPU machine for 16 hours, LOGO allows the Llama-3–8B-Instruct-80K model to achieve comparable performance with GPT-4 in real-world long-context tasks while preserving the model’s original capabilities on other tasks, e.g., language modeling and MMLU. Moreover, LOGO can extend the model’s context window size while enhancing its generation performance.
4. LLM Reasoning
4.1. Unleashing Reasoning Capability of LLMs via Scalable Question Synthesis from Scratch

The availability of high-quality data is one of the most important factors in improving the reasoning capability of LLMs. Existing works have demonstrated the effectiveness of creating more instruction data from seed questions or knowledge bases.
Recent research indicates that continually scaling up data synthesis from strong models (e.g., GPT-4) can further elicit reasoning performance. Though promising, the open-sourced community still lacks high-quality data at scale and scalable data synthesis methods with affordable costs.
To address this, we introduce ScaleQuest, a scalable and novel data synthesis method that utilizes “small-size” (e.g., 7B) open-source models to generate questions from scratch without the need for seed data with complex augmentation constraints.
With the efficient ScaleQuest, we automatically constructed a mathematical reasoning dataset consisting of 1 million problem-solution pairs, which are more effective than existing open-sourced datasets.
It can universally increase the performance of mainstream open-source models (i.e., Mistral, Llama3, DeepSeekMath, and Qwen2-Math) by achieving 29.2% to 46.4% gains on MATH.
Notably, simply fine-tuning the Qwen2-Math-7B-Base model with our dataset can even surpass Qwen2-Math-7B-Instruct, a strong and well-aligned model on closed-source data, and proprietary models such as GPT-4-Turbo and Claude-3.5 Sonnet.
5. LLM Agents
5.1. Web Agents with World Models: Learning and Leveraging Environment Dynamics in Web Navigation
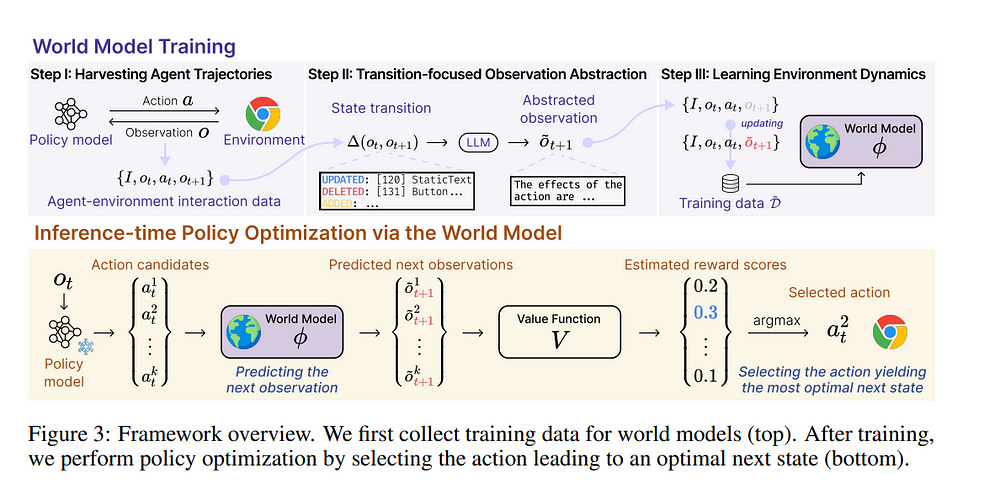
Large language models (LLMs) have recently gained much attention in building autonomous agents. However, the performance of current LLM-based web agents in long-horizon tasks is far from optimal, often yielding errors such as repeatedly buying a non-refundable flight ticket.
By contrast, humans can avoid such an irreversible mistake, as we have an awareness of the potential outcomes (e.g., losing money) of our actions, also known as the “world model”.
Motivated by this, our study first starts with preliminary analyses, confirming the absence of world models in current LLMs (e.g., GPT-4o, Claude-3.5-Sonnet, etc.).
Then, we present a World-model-augmented (WMA) web agent, which simulates the outcomes of its actions for better decision-making. To overcome the challenges in training LLMs as world models predicting next observations, such as repeated elements across observations and long HTML inputs, we propose a transition-focused observation abstraction, where the prediction objectives are free-form natural language descriptions exclusively highlighting important state differences between time steps.
Experiments on WebArena and Mind2Web show that our world models improve agents’ policy selection without training and demonstrate our agents’ cost- and time-efficiency compared to recent tree-search-based agents.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
