


Important LLMs Papers for the Week from 23/12 to 29/12
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Fourth and last Week of December 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
Attention Models & Transformers
LLM Training
LLM Quantization
LLM Reasoning
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. LLM Progress & Benchmarking
1.1. OpenAI o1 System Card

The o1 model series is trained with large-scale reinforcement learning to reason using the chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models.
In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks.
Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence.
Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
1.2. YuLan-Mini: An Open Data-efficient Language Model

Effective pre-training of large language models (LLMs) has been challenging due to the immense resource demands and the complexity of the technical processes involved.
This paper presents a detailed technical report on YuLan-Mini, a highly capable base model with 2.42B parameters that achieves top-tier performance among models of similar parameter scales.
Our pre-training approach focuses on enhancing training efficacy through three key technical contributions: an elaborate data pipeline that combines data cleaning with data schedule strategies, a robust optimization method to mitigate training instability, and an effective annealing approach that incorporates targeted data selection and long context training.
Remarkably, YuLan-Mini, trained on 1.08T tokens, achieves performance comparable to industry-leading models that require significantly more data. To facilitate reproduction, we release the full details of the data composition for each training phase.
1.3. Revisiting In-Context Learning with Long-Context Language Models

In-context learning (ICL) is a technique by which language models make predictions based on examples in their input context. Previously, their context window size limited the number of examples that could be shown, making example selection techniques crucial for identifying the maximally effective set of examples.
However, the recent advent of Long Context Language Models (LCLMs) has significantly increased the number of examples that can be included in context, raising an important question of whether ICL performance in a many-shot regime is still sensitive to the sample selection method.
To answer this, we revisit these approaches in the context of LCLMs through extensive experiments on 18 datasets spanning 4 tasks. Surprisingly, we observe that sophisticated example selection techniques do not yield significant improvements over a simple random sample selection method.
Instead, we find that the advent of LCLMs has fundamentally shifted the challenge of ICL from selecting the most effective examples to collecting sufficient examples to fill the context window.
Specifically, in certain datasets, including all available examples does not fully utilize the context window; however, by augmenting the examples in context with a simple data augmentation approach, we substantially improve ICL performance by 5%.
2. Attention Models & Transformers
2.1. SCOPE: Optimizing Key-Value Cache Compression in Long-context Generation

The key-value (KV) cache has become a bottleneck of LLMs for long-context generation. Despite the numerous efforts in this area, the optimization for the decoding phase is generally ignored.
However, we believe such optimization is crucial, especially for long-output generation tasks based on the following two observations:
Excessive compression during the prefill phase, which requires specific full context impairs the comprehension of the reasoning task
Deviation of heavy hitters occurs in the reasoning tasks with long outputs.
Therefore, SCOPE, a simple yet efficient framework that separately performs KV cache optimization during the prefill and decoding phases, is introduced.
Specifically, the KV cache during the prefill phase is preserved to maintain the essential information, while a novel strategy based on sliding is proposed to select essential heavy hitters for the decoding phase. Memory usage and memory transfer are further optimized using adaptive and discontinuous strategies.
Extensive experiments on LongGenBench show the effectiveness and generalization of SCOPE and its compatibility as a plug-in to other prefill-only KV compression methods.
2.2. A Silver Bullet or a Compromise for Full Attention? A Comprehensive Study of Gist Token-based Context Compression

In this work, we provide a thorough investigation of gist-based context compression methods to improve long-context processing in large language models.
We focus on two key questions: (1) How well can these methods replace full attention models? and (2) What potential failure patterns arise due to compression?
Through extensive experiments, we show that while gist-based compression can achieve near-lossless performance on tasks like retrieval-augmented generation and long-document QA, it faces challenges in tasks like synthetic recall.
Furthermore, we identify three key failure patterns: lost by the boundary, lost if surprise, and lost along the way. To mitigate these issues, we propose two effective strategies: fine-grained autoencoding, which enhances the reconstruction of original token information, and segment-wise token importance estimation, which adjusts optimization based on token dependencies.
Our work provides valuable insights into the understanding of gist token-based context compression and offers practical strategies for improving compression capabilities.
2.3. Fourier Position Embedding: Enhancing Attention’s Periodic Extension for Length Generalization

Extending the context length of Language Models (LMs) by improving Rotary Position Embedding (RoPE) has become a trend. While existing works mainly address RoPE’s limitations within attention mechanism, this paper provides an analysis across nearly all parts of LMs, uncovering their adverse effects on length generalization for RoPE-based attention.
Using Discrete Signal Processing theory, we show that RoPE enables periodic attention by implicitly achieving a Non-Uniform Discrete Fourier Transform. However, this periodicity is undermined by the spectral damage caused by:
Linear layers and activation functions outside of attention
Insufficiently trained frequency components brought by time-domain truncation.
Building on our observations, we propose Fourier Position Embedding (FoPE), which enhances attention’s frequency-domain properties to improve both its periodic extension and length generalization.
FoPE constructs the Fourier Series and zero-outs the destructive frequency components, increasing model robustness against the spectrum damage.
Experiments across various model scales show that, within varying context windows, FoPE can maintain a more stable perplexity and a more consistent accuracy in a needle-in-haystack task compared to RoPE and ALiBi. Several analyses and ablations bring further support to our method and theoretical modeling.
3. LLM Training
3.1. RobustFT: Robust Supervised Fine-tuning for Large Language Models under Noisy Response

Supervised fine-tuning (SFT) plays a crucial role in adapting large language models (LLMs) to specific domains or tasks. However, as demonstrated by empirical experiments, the collected data inevitably contains noise in practical applications, which poses significant challenges to model performance on downstream tasks.
Therefore, there is an urgent need for a noise-robust SFT framework to enhance model capabilities in downstream tasks. To address this challenge, we introduce a robust SFT framework (RobustFT) that performs noise detection and relabeling on downstream task data.
For noise identification, our approach employs a multi-expert collaborative system with inference-enhanced models to achieve superior noise detection.
In the denoising phase, we utilize a context-enhanced strategy, which incorporates the most relevant and confident knowledge followed by careful assessment to generate reliable annotations.
Additionally, we introduce an effective data selection mechanism based on response entropy, ensuring only high-quality samples are retained for fine-tuning. Extensive experiments conducted on multiple LLMs across five datasets demonstrate RobustFT’s exceptional performance in noisy scenarios.
3.2. Deliberation in Latent Space via Differentiable Cache Augmentation

Techniques enabling large language models (LLMs) to “think more” by generating and attending to intermediate reasoning steps have shown promise in solving complex problems.
However, the standard approaches generate sequences of discrete tokens immediately before responding, so they can incur significant latency costs and be challenging to optimize.
In this work, we demonstrate that a frozen LLM can be augmented with an offline coprocessor that operates on the model’s key-value (kv) cache. This coprocessor augments the cache with a set of latent embeddings designed to improve the fidelity of subsequent decoding.
We train this coprocessor using the language modeling loss from the decoder on standard pretraining data while keeping the decoder itself frozen.
This approach enables the model to learn, in an end-to-end differentiable fashion, how to distill additional computation into its kv-cache. Because the decoder remains unchanged, the coprocessor can operate offline and asynchronously, and the language model can function normally if the coprocessor is unavailable or if a given cache is deemed not to require extra computation.
We show experimentally that when a cache is augmented, the decoder achieves lower perplexity on numerous subsequent tokens. Furthermore, even without any task-specific training, our experiments demonstrate that cache augmentation consistently reduces perplexity and improves performance across a range of reasoning-intensive tasks.
4. LLM Quantization
4.1. Distilled Decoding 1: One-step Sampling of Image Auto-regressive Models with Flow Matching

Autoregressive (AR) models have achieved state-of-the-art performance in text and image generation but suffer from slow generation due to the token-by-token process.
We ask an ambitious question: can a pre-trained AR model be adapted to generate outputs in just one or two steps? If successful, this would significantly advance the development and deployment of AR models.
We notice that existing works that try to speed up AR generation by generating multiple tokens at once fundamentally cannot capture the output distribution due to the conditional dependencies between tokens, limiting their effectiveness for a few-step generation.
To address this, we propose Distilled Decoding (DD), which uses flow matching to create a deterministic mapping from the Gaussian distribution to the output distribution of the pre-trained AR model.
We then train a network to distill this mapping, enabling a few-step generation. DD doesn’t need the training data of the original AR model, making it more practical.
We evaluate DD on state-of-the-art image AR models and present promising results on ImageNet-256. For VAR, which requires a 10-step generation, DD enables one-step generation (6.3 times speed-up), with an acceptable increase in FID from 4.19 to 9.96.
For LlamaGen, DD reduces generation from 256 steps to 1, achieving a 217.8 times speed-up with a comparable FID increase from 4.11 to 11.35. In both cases, baseline methods completely fail with FID>100. DD also excels in text-to-image generation, reducing the generation from 256 steps to 2 for LlamaGen with a minimal FID increase from 25.70 to 28.95.
As the first work to demonstrate the possibility of one-step generation for image AR models, DD challenges the prevailing notion that AR models are inherently slow, and opens up new opportunities for efficient AR generation.
5. LLM Reasoning
5.1. Offline Reinforcement Learning for LLM Multi-Step Reasoning

Improving the multi-step reasoning ability of large language models (LLMs) with offline reinforcement learning (RL) is essential for quickly adapting them to complex tasks.
While Direct Preference Optimization (DPO) has shown promise in aligning LLMs with human preferences, it is less suitable for multi-step reasoning tasks because (1) DPO relies on paired preference data, which is not readily available for multi-step reasoning tasks, and (2) it treats all tokens uniformly, making it ineffective for credit assignment in multi-step reasoning tasks, which often come with sparse reward.
In this work, we propose OREO (Offline Reasoning Optimization), an offline RL method for enhancing LLM multi-step reasoning. Building on insights from previous works of maximum entropy reinforcement learning, it jointly learns a policy model and value function by optimizing the soft Bellman Equation.
We show in principle that it reduces the need to collect pairwise data and enables better credit assignment. Empirically, OREO surpasses existing offline learning methods on multi-step reasoning benchmarks, including mathematical reasoning tasks (GSM8K, MATH) and embodied agent control (ALFWorld).
When additional resources are available, the approach can be extended to a multi-iteration framework. Furthermore, the learned value function can be leveraged to guide the tree search for free, which can further boost performance during test time.
5.2. Diving into Self-Evolving Training for Multimodal Reasoning

Reasoning ability is essential for Large Multimodal Models (LMMs). In the absence of multimodal chain-of-thought annotated data, self-evolving training, where the model learns from its outputs, has emerged as an effective and scalable approach for enhancing reasoning abilities.
Despite its growing usage, a comprehensive understanding of self-evolving training, particularly in the context of multimodal reasoning, remains limited. In this paper, we delve into the intricacies of self-evolving training for multimodal reasoning, pinpointing three key factors: Training Method, Reward Model, and Prompt Variation.
We systematically examine each factor and explore how various configurations affect the training’s effectiveness. Our analysis leads to a set of best practices for each factor, aimed at optimizing multimodal reasoning.
Furthermore, we explore the Self-Evolution Dynamics during training and the impact of automatic balancing mechanisms in boosting performance.
After all the investigations, we present a final recipe for self-evolving training in multimodal reasoning, encapsulating these design choices into a framework we call MSTaR (Multimodal Self-evolving Training for Reasoning), which is universally effective for models with different sizes on various benchmarks, e.g., surpassing the pre-evolved model significantly on 5 multimodal reasoning benchmarks without using additional human annotations, as demonstrated on MiniCPM-V-2.5 (8B), Phi-3.5-Vision (4B) and InternVL2 (2B).
We believe this study fills a significant gap in the understanding of self-evolving training for multimodal reasoning and offers a robust framework for future research.
Our policy and reward models, as well as the collected data, is released to facilitate further investigation in multimodal reasoning.
5.3. B-STaR: Monitoring and Balancing Exploration and Exploitation in Self-Taught Reasoners

In the absence of extensive human-annotated data for complex reasoning tasks, self-improvement — where models are trained on their own outputs — has emerged as a primary method for enhancing performance.
However, the critical factors underlying the mechanism of these iterative self-improving methods remain poorly understood, such as under what conditions self-improvement is effective, and what are the bottlenecks in the current iterations.
In this work, we identify and propose methods to monitor two pivotal factors in this iterative process: (1) the model’s ability to generate sufficiently diverse responses (exploration); and (2) the effectiveness of external rewards in distinguishing high-quality candidates from lower-quality ones (exploitation).
Using mathematical reasoning as a case study, we begin with a quantitative analysis to track the dynamics of exploration and exploitation, discovering that a model’s exploratory capabilities rapidly deteriorate over iterations, and the effectiveness of exploiting external rewards diminishes as well.
Motivated by these findings, we introduce B-STaR, a Self-Taught Reasoning framework that autonomously adjusts configurations across iterations to Balance exploration and exploitation, thereby optimizing the self-improving effectiveness based on the current policy model and available rewards.
Our experiments on mathematical reasoning, coding, and commonsense reasoning demonstrate that B-STaR not only enhances the model’s exploratory capabilities throughout training but also achieves a more effective balance between exploration and exploitation, leading to superior performance.
5.4. Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning
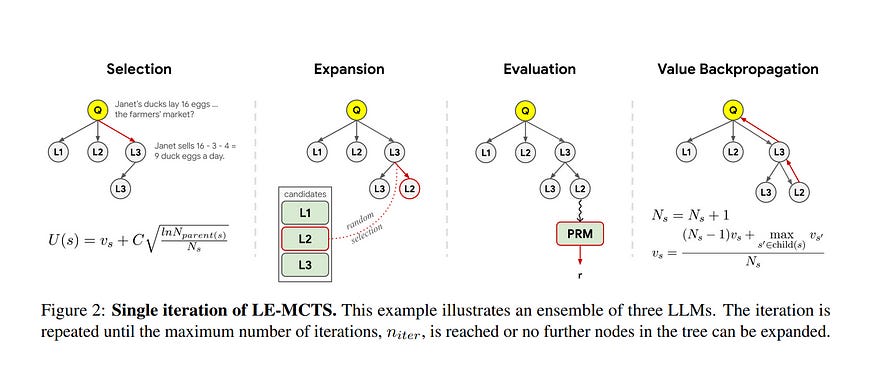
Despite recent advances in large language models, open-source models often struggle to consistently perform well on complex reasoning tasks. Existing ensemble methods, whether applied at the token or output levels, fail to address these challenges.
In response, we present Language Model Ensemble with Monte Carlo Tree Search (LE-MCTS), a novel framework for process-level ensembling of language models. LE-MCTS formulates step-by-step reasoning with an ensemble of language models as a Markov decision process.
In this framework, states represent intermediate reasoning paths, while actions consist of generating the next reasoning step using one of the language models selected from a predefined pool.
Guided by a process-based reward model, LE-MCTS performs a tree search over the reasoning steps generated by different language models, identifying the most accurate reasoning chain.
Experimental results on five mathematical reasoning benchmarks demonstrate that our approach outperforms both single-language model decoding algorithms and language model ensemble methods.
Notably, LE-MCTS improves performance by 3.6% and 4.3% on the MATH and MQA datasets, respectively, highlighting its effectiveness in solving complex reasoning problems.
5.5. Token-Budget-Aware LLM Reasoning

Reasoning is critical for large language models (LLMs) to excel in a wide range of tasks. While methods like Chain-of-Thought (CoT) reasoning enhance LLM performance by decomposing problems into intermediate steps, they also incur significant overhead in token usage, leading to increased costs.
We find that the reasoning process of current LLMs is unnecessarily lengthy and it can be compressed by including a reasonable token budget in the prompt, but the choice of token budget plays a crucial role in the actual compression effectiveness.
We then propose a token-budget-aware LLM reasoning framework, which dynamically estimates token budgets for different problems based on reasoning complexity and uses the estimated token budgets to guide the reasoning process.
Experiments show that our method effectively reduces token costs in CoT reasoning with only a slight performance reduction, offering a practical solution to balance efficiency and accuracy in LLM reasoning.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
