


Important LLMs Papers for the Week from 22/07 to 28/07
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Fourth Week of July 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Training, Evaluation & Inference
LLM Quantization
LLM Reasoning
LLM Safety & Alignment
LLM Agents
Retrieval Augmented Generation (RAG)
Tokenizers
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. LLM Progress & Benchmarking
1.1. Dallah: A Dialect-Aware Multimodal Large Language Model for Arabic

Recent advancements have significantly enhanced the capabilities of Multimodal Large Language Models (MLLMs) in generating and understanding image-to-text content.
Despite these successes, progress is predominantly limited to English due to the scarcity of high-quality multimodal resources in other languages. This limitation impedes the development of competitive models in languages such as Arabic.
To alleviate this situation, we introduce an efficient Arabic multimodal assistant, dubbed Dallah, that utilizes an advanced language model based on LLaMA-2 to facilitate multimodal interactions. Dallah demonstrates state-of-the-art performance in Arabic MLLMs.
Through fine-tuning six Arabic dialects, Dallah showcases its capability to handle complex dialectal interactions incorporating both textual and visual elements. The model excels in two benchmark tests: one evaluating its performance on Modern Standard Arabic (MSA) and another specifically designed to assess dialectal responses.
Beyond its robust performance in multimodal interaction tasks, Dallah has the potential to pave the way for further development of dialect-aware Arabic MLLMs.
1.2. SciCode: A Research Coding Benchmark Curated by Scientists
Since language models (LMs) now outperform average humans on many challenging tasks, it has become increasingly difficult to develop challenging, high-quality, and realistic evaluations. We address this issue by examining LMs’ capabilities to generate code for solving real scientific research problems.
Incorporating input from scientists and AI researchers in 16 diverse natural science sub-fields, including mathematics, physics, chemistry, biology, and materials science, we created a scientist-curated coding benchmark, SciCode.
The problems in SciCode naturally factorize into multiple subproblems, each involving knowledge recall, reasoning, and code synthesis. In total, SciCode contains 338 subproblems decomposed from 80 challenging main problems. It offers optional descriptions specifying useful scientific background information and scientist-annotated gold-standard solutions and test cases for evaluation.
Claude3.5-Sonnet, the best-performing model among those tested, can solve only 4.6% of the problems in the most realistic setting. We believe that SciCode demonstrates both contemporary LMs’ progress toward becoming helpful scientific assistants and sheds light on the development and evaluation of scientific AI in the future.
1.3. Qalam: A Multimodal LLM for Arabic Optical Character and Handwriting Recognition
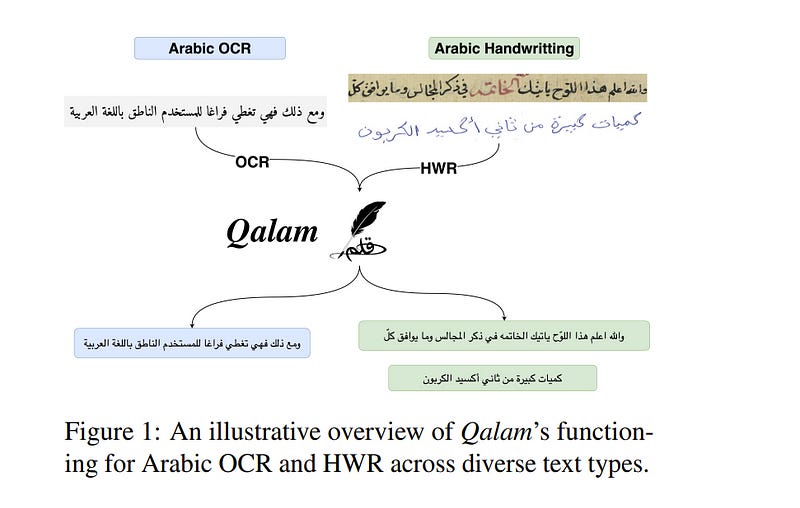
Arabic Optical Character Recognition (OCR) and Handwriting Recognition (HWR) pose unique challenges due to the cursive and context-sensitive nature of the Arabic script.
This study introduces Qalam, a novel foundation model designed for Arabic OCR and HWR, built on a SwinV2 encoder and RoBERTa decoder architecture. Our model significantly outperforms existing methods, achieving a Word Error Rate (WER) of just 0.80% in HWR tasks and 1.18% in OCR tasks.
We train Qalam on a diverse dataset, including over 4.5 million images from Arabic manuscripts and a synthetic dataset comprising 60k image-text pairs. Notably, Qalam demonstrates exceptional handling of Arabic diacritics, a critical feature in Arabic scripts.
Furthermore, it shows a remarkable ability to process high-resolution inputs, addressing a common limitation in current OCR systems. These advancements underscore Qalam’s potential as a leading solution for Arabic script recognition, offering a significant leap in accuracy and efficiency.
1.4. AssistantBench: Can Web Agents Solve Realistic and Time-Consuming Tasks?

Language agents, built on top of language models (LMs), are systems that can interact with complex environments, such as the open web. In this work, we examine whether such agents can perform realistic and time-consuming tasks on the web, e.g., monitoring real-estate markets or locating relevant nearby businesses.
We introduce AssistantBench, a challenging new benchmark consisting of 214 realistic tasks that can be automatically evaluated, covering different scenarios and domains. We find that AssistantBench exposes the limitations of current systems, including language models and retrieval-augmented language models, as no model reaches an accuracy of more than 25 points.
While closed-book LMs perform well, they exhibit low precision since they tend to hallucinate facts. State-of-the-art web agents reach a score of near zero.
Additionally, we introduce SeePlanAct (SPA), a new web agent that significantly outperforms previous agents, and an ensemble of SPA and closed-book models reaches the best overall performance. Moreover, we analyze the failures of current systems and highlight that web navigation remains a major challenge.
1.5. INF-LLaVA: Dual-perspective Perception for High-Resolution Multimodal Large Language Model

With advancements in data availability and computing resources, Multimodal Large Language Models (MLLMs) have showcased capabilities across various fields. However, the quadratic complexity of the vision encoder in MLLMs constrains the resolution of input images.
Most current approaches mitigate this issue by cropping high-resolution images into smaller sub-images, which are then processed independently by the vision encoder. Despite capturing sufficient local details, these sub-images lack global context and fail to interact with one another.
To address this limitation, we propose a novel MLLM, INF-LLaVA, designed for effective high-resolution image perception. INF-LLaVA incorporates two innovative components. First, we introduce a Dual-perspective Cropping Module (DCM), which ensures that each sub-image contains continuous details from a local perspective and comprehensive information from a global perspective.
Second, we introduce Dual-perspective Enhancement Module (DEM) to enable the mutual enhancement of global and local features, allowing INF-LLaVA to effectively process high-resolution images by simultaneously capturing detailed local information and comprehensive global context.
Extensive ablation studies validate the effectiveness of these components, and experiments on a diverse set of benchmarks demonstrate that INF-LLaVA outperforms existing MLLMs.
1.6. NNsight and NDIF: Democratizing Access to Foundation Model Internals
The enormous scale of state-of-the-art foundation models has limited their accessibility to scientists because customized experiments at large model sizes require costly hardware and complex engineering that is impractical for most researchers.
To alleviate these problems, we introduce NNsight, an open-source Python package with a simple, flexible API that can express interventions on any PyTorch model by building computation graphs.
We also introduce NDIF, a collaborative research platform providing researchers access to foundation-scale LLMs via the NNsight API.
2. LLM Training, Evaluation & Inference
2.1. MIBench: Evaluating Multimodal Large Language Models over Multiple Images

Built on the power of LLMs, numerous multimodal large language models (MLLMs) have recently achieved remarkable performance on various vision-language tasks across multiple benchmarks.
However, most existing MLLMs and benchmarks primarily focus on single-image input scenarios, leaving the performance of MLLMs when handling realistic multiple images to remain underexplored. Although a few benchmarks consider multiple images, their evaluation dimensions and samples are very limited.
Therefore, in this paper, we propose a new benchmark MIBench, to comprehensively evaluate fine-grained abilities of MLLMs in multi-image scenarios.
Specifically, MIBench categorizes the multi-image abilities into three scenarios: multi-image instruction (MII), multimodal knowledge-seeking (MKS), and multimodal in-context learning (MIC), and constructs 13 tasks with a total of 13K annotated samples.
During data construction, for MII and MKS, we extract correct options from manual annotations and create challenging distractors to obtain multiple-choice questions.
For MIC, to enable an in-depth evaluation, we set four sub-tasks and transform the original datasets into in-context learning formats. We evaluate several open-source MLLMs and close-source MLLMs on the proposed MIBench.
The results reveal that although current models excel in single-image tasks, they exhibit significant shortcomings when faced with multi-image inputs, such as confused fine-grained perception, limited multi-image reasoning, and unstable in-context learning.
2.2. Scalify: scale propagation for efficient low-precision LLM training
Low-precision formats such as float8 have been introduced in machine learning accelerated hardware to improve computational efficiency for large language model training and inference.
Nevertheless, adoption by the ML community has been slowed down by the complex, and sometimes brittle, techniques required to match higher precision training accuracy.
In this work, we present Scalify, an end-to-end scale propagation paradigm for computational graphs, generalizing and formalizing existing tensor scaling methods.
Experiment results show that Scalify supports out-of-the-box float8 matrix multiplication and gradients representation, as well as float16 optimizer state storage.
2.3. Internal Consistency and Self-Feedback in Large Language Models: A Survey
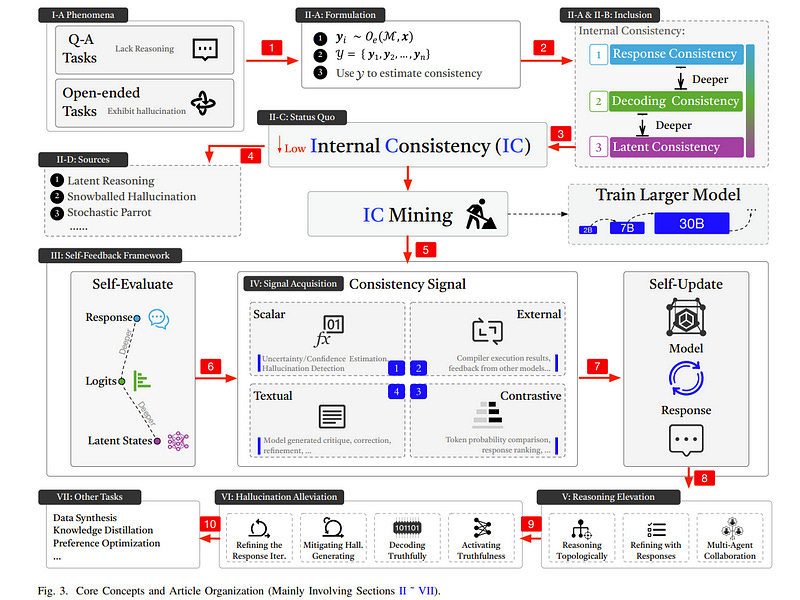
Large language models (LLMs) are expected to respond accurately but often exhibit deficient reasoning or generate hallucinatory content. To address these, studies prefixed with ``Self-’’ such as Self-Consistency, Self-Improve, and Self-Refine have been initiated.
They share a commonality: involving LLMs evaluating and updating themselves to mitigate the issues. Nonetheless, these efforts lack a unified perspective on summarization, as existing surveys predominantly focus on categorization without examining the motivations behind these works.
In this paper, we summarize a theoretical framework, termed Internal Consistency, which offers unified explanations for phenomena such as the lack of reasoning and the presence of hallucinations. Internal Consistency assesses the coherence among LLMs’ latent layer, decoding layer, and response layer based on sampling methodologies.
Expanding upon the Internal Consistency framework, we introduce a streamlined yet effective theoretical framework capable of mining Internal Consistency, named Self-Feedback. The Self-Feedback framework consists of two modules: Self-Evaluation and Self-Update.
This framework has been employed in numerous studies. We systematically classify these studies by tasks and lines of work; summarize relevant evaluation methods and benchmarks; and delve into the concern, ``Does Self-Feedback Really Work?’’ We propose several critical viewpoints, including the ``Hourglass Evolution of Internal Consistency’’, ``Consistency Is (Almost) Correctness’’ hypothesis, and ``The Paradox of Latent and Explicit Reasoning’’.
3. LLM Quantization & Optimization
3.1. Fast Matrix Multiplications for Lookup Table-Quantized LLMs

The deployment of large language models (LLMs) is often constrained by memory bandwidth, where the primary bottleneck is the cost of transferring model parameters from the GPU’s global memory to its registers.
When coupled with custom kernels that fuse the dequantization and mammal operations, weight-only quantization can thus enable faster inference by reducing the amount of memory movement. However, developing high-performance kernels for weight-quantized LLMs presents substantial challenges, especially when the weights are compressed to non-evenly-divisible bit widths (e.g., 3 bits) with non-uniform, lookup table (LUT) quantization.
This paper describes FLUTE, a flexible lookup table engine for LUT-quantized LLMs, which uses offline restructuring of the quantized weight matrix to minimize bit manipulations associated with unpacking, vectorization, and duplication of the lookup table to mitigate shared memory bandwidth constraints.
At batch sizes < 32 and quantization group size of 128 (typical in LLM inference), the FLUTE kernel can be 2–4x faster than existing GEMM kernels. As an application of FLUTE, we explore a simple extension to lookup table-based NormalFloat quantization and apply it to quantize LLaMA3 to various configurations, obtaining competitive quantization performance against strong baselines while obtaining an end-to-end throughput increase of 1.5 to 2 times.
3.2. Compact Language Models via Pruning and Knowledge Distillation
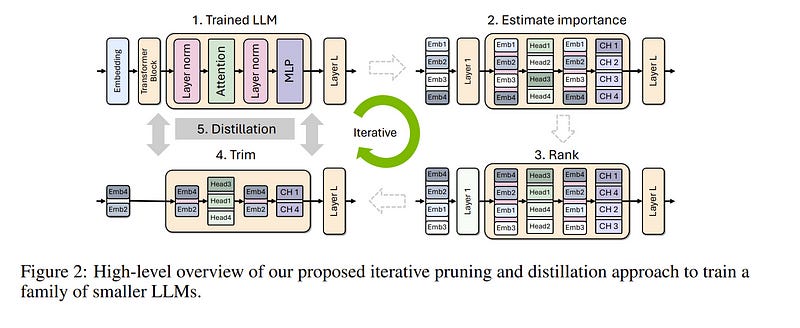
Large language models (LLMs) targeting different deployment scales and sizes are currently produced by training each variant from scratch; this is extremely compute-intensive. In this paper, we investigate if pruning an existing LLM and then re-training it with a fraction (3%) of the original training data can be a suitable alternative to repeated, full retraining.
To this end, we develop a set of practical and effective compression best practices for LLMs that combine depth, width, attention, and MLP pruning with knowledge distillation-based retraining; we arrive at these best practices through a detailed empirical exploration of pruning strategies for each axis, methods to combine axes, distillation strategies, and search techniques for arriving at optimal compressed architectures.
We use this guide to compress the Nemotron-4 family of LLMs by a factor of 2–4x and compare their performance to similarly-sized models on a variety of language modeling tasks.
Deriving 8B and 4B models from an already pretrained 15B model using our approach requires up to 40x fewer training tokens per model compared to training from scratch; this results in compute cost savings of 1.8x for training the full model family (15B, 8B, and 4B).
Minitron models exhibit up to a 16% improvement in MMLU scores compared to training from scratch, perform comparably to other community models such as Mistral 7B, Gemma 7B, and Llama-3 8B, and outperform state-of-the-art compression techniques from the literature.
We have open-sourced Minitron model weights on Huggingface, with corresponding supplementary material including example code available on GitHub.
3.3. DDK: Distilling Domain Knowledge for Efficient Large Language Models

Despite the advanced intelligence abilities of large language models (LLMs) in various applications, they still face significant computational and storage demands. Knowledge Distillation (KD) has emerged as an effective strategy to improve the performance of a smaller LLM (i.e., the student model) by transferring knowledge from a high-performing LLM (i.e., the teacher model).
Prevailing techniques in LLM distillation typically use a black-box model API to generate high-quality pretrained and aligned datasets or utilize white-box distillation by altering the loss function to better transfer knowledge from the teacher LLM.
However, these methods ignore the knowledge differences between the student and teacher LLMs across domains. This results in excessive focus on domains with minimal performance gaps and insufficient attention to domains with large gaps, reducing overall performance.
In this paper, we introduce a new LLM distillation framework called DDK, which dynamically adjusts the composition of the distillation dataset in a smooth manner according to the domain performance differences between the teacher and student models, making the distillation process more stable and effective.
Extensive evaluations show that DDK significantly improves the performance of student models, outperforming both continuously pretrained baselines and existing knowledge distillation methods by a large margin.
3.4. LazyLLM: Dynamic Token Pruning for Efficient Long Context LLM Inference

The inference of transformer-based large language models consists of two sequential stages: 1) a prefilling stage to compute the KV cache of prompts and generate the first token, and 2) a decoding stage to generate subsequent tokens.
For long prompts, the KV cache must be computed for all tokens during the prefilling stage, which can significantly increase the time needed to generate the first token. Consequently, the prefilling stage may become a bottleneck in the generation process.
An open question remains whether all prompt tokens are essential for generating the first token. To answer this, we introduce a novel method, LazyLLM, that selectively computes the KV for tokens important for the next token prediction in both the prefilling and decoding stages.
Contrary to static pruning approaches that prune the prompt at once, LazyLLM allows language models to dynamically select different subsets of tokens from the context in different generation steps, even though they might be pruned in previous steps.
Extensive experiments on standard datasets across various tasks demonstrate that LazyLLM is a generic method that can be seamlessly integrated with existing language models to significantly accelerate the generation without fine-tuning. For instance, in the multi-document question-answering task, LazyLLM accelerates the prefilling stage of the LLama 2 7B model by 2.34x while maintaining accuracy.
4. LLM Reasoning
4.1. Knowledge Mechanisms in Large Language Models: A Survey and Perspective

Understanding knowledge mechanisms in Large Language Models (LLMs) is crucial for advancing towards trustworthy AGI. This paper reviews knowledge mechanism analysis from a novel taxonomy including knowledge utilization and evolution.
Knowledge utilization delves into the mechanism of memorization, comprehension and application, and creation. Knowledge evolution focuses on the dynamic progression of knowledge within individual and group LLMs.
Moreover, we discuss what knowledge LLMs have learned, the reasons for the fragility of parametric knowledge, and the potential dark knowledge (hypothesis) that will be challenging to address. We hope this work can help understand knowledge in LLMs and provide insights for future research.
5. LLM Safety & Alignment
5.1. Course-Correction: Safety Alignment Using Synthetic Preferences

The risk of harmful content generated by large language models (LLMs) becomes a critical concern. This paper presents a systematic study on assessing and improving LLMs’ capability to perform the task of course correction, \ie, the model can steer away from generating harmful content autonomously.
To start with, we introduce the C²-Eval benchmark for quantitative assessment and analyze 10 popular LLMs, revealing varying proficiency of current safety-tuned LLMs in course correction.
To improve, we propose fine-tuning LLMs with preference learning, emphasizing the preference for timely course correction. Using an automated pipeline, we create C²-Syn, a synthetic dataset with 750K pairwise preferences, to teach models the concept of timely course correction through data-driven preference learning.
Experiments on 2 LLMs, Llama2-Chat 7B and Qwen2 7B, show that our method effectively enhances course-correction skills without affecting general performance. Additionally, it effectively improves LLMs’ safety, particularly in resisting jailbreak attacks.
5.2. BOND: Aligning LLMs with Best-of-N Distillation

Reinforcement learning from human feedback (RLHF) is a key driver of quality and safety in state-of-the-art large language models. Yet, a surprisingly simple and strong inference-time strategy is Best-of-N sampling which selects the best generation among N candidates.
In this paper, we propose Best-of-N Distillation (BOND), a novel RLHF algorithm that seeks to emulate Best-of-N but without its significant computational overhead at inference time.
Specifically, BOND is a distribution matching algorithm that forces the distribution of generations from the policy to get closer to the Best-of-N distribution.
We use the Jeffreys divergence (a linear combination of forward and backward KL) to balance between mode-covering and mode-seeking behavior and derive an iterative formulation that utilizes a moving anchor for efficiency.
We demonstrate the effectiveness of our approach and several design choices through experiments on abstractive summarization and Gemma models. Aligning Gemma policies with BOND outperforms other RLHF algorithms by improving results on several benchmarks.
5.3. PrimeGuard: Safe and Helpful LLMs through Tuning-Free Routing

Deploying language models (LMs) necessitates outputs to be both high-quality and compliant with safety guidelines. Although Inference-Time Guardrails (ITG) offer solutions that shift model output distributions towards compliance, we find that current methods struggle to balance safety with helpfulness.
ITG Methods that safely address non-compliant queries exhibit lower helpfulness while those that prioritize helpfulness compromise on safety. We refer to this trade-off as the guardrail tax, analogous to the alignment tax.
To address this, we propose PrimeGuard, a novel ITG method that utilizes structured control flow. PrimeGuard routes request to different self-instantiations of the LM with varying instructions, leveraging its inherent instruction-following capabilities and in-context learning.
Our tuning-free approach dynamically compiles system-designer guidelines for each query. We construct and release safe-eval, a diverse red-team safety benchmark.
Extensive evaluations demonstrate that PrimeGuard, without fine-tuning, overcomes the guardrail tax by:
Significantly increasing resistance to iterative jailbreak attacks
Achieving state-of-the-art results in safety guard railing
Matching helpfulness scores of alignment-tuned models.
Extensive evaluations demonstrate that PrimeGuard, without fine-tuning, outperforms all competing baselines and overcomes the guardrail tax by improving the fraction of safe responses from 61% to 97% and increasing average helpfulness scores from 4.17 to 4.29 on the largest models, while reducing attack success rate from 100% to 8%.
5.4. PERSONA: A Reproducible Testbed for Pluralistic Alignment
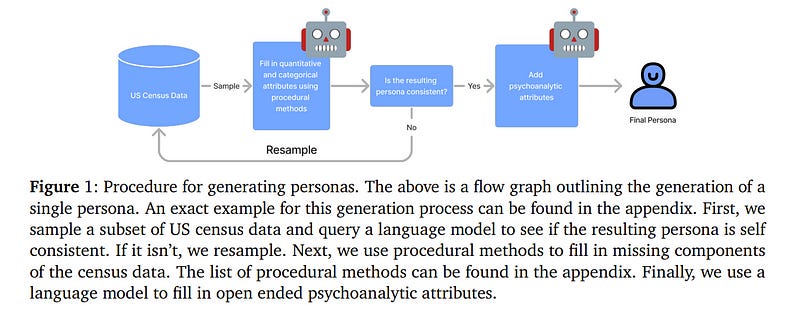
The rapid advancement of language models (LMs) necessitates robust alignment with diverse user values. However, current preference optimization approaches often fail to capture the plurality of user opinions, instead reinforcing majority viewpoints and marginalizing minority perspectives.
We introduce PERSONA, a reproducible test bed designed to evaluate and improve the pluralistic alignment of LMs. We procedurally generate diverse user profiles from US census data, resulting in 1,586 synthetic personas with varied demographic and idiosyncratic attributes.
We then generate a large-scale evaluation dataset containing 3,868 prompts and 317,200 feedback pairs obtained from our synthetic personas. Leveraging this dataset, we systematically evaluate LM capabilities in role-playing diverse users, verified through human judges, and the establishment of both a benchmark, PERSONA Bench, for pluralistic alignment approaches as well as an extensive dataset to create new and future benchmarks.
6. LLM Agents
6.1. OpenDevin: An Open Platform for AI Software Developers as Generalist Agents

Software is one of the most powerful tools that we humans have at our disposal; it allows a skilled programmer to interact with the world in complex and profound ways.
At the same time, thanks to improvements in large language models (LLMs), there has also been a rapid development in AI agents that interact with and affect change in their surrounding environments.
In this paper, we introduce OpenDevin, a platform for the development of powerful and flexible AI agents that interact with the world in similar ways to those of a human developer: by writing code, interacting with a command line, and browsing the web.
We describe how the platform allows for the implementation of new agents, safe interaction with sandboxed environments for code execution, coordination between multiple agents, and incorporation of evaluation benchmarks.
Based on our currently incorporated benchmarks, we perform an evaluation of agents over 15 challenging tasks, including software engineering (e.g., SWE-Bench) and web browsing (e.g., WebArena), among others.
Released under the permissive MIT license, OpenDevin is a community project spanning academia and industry with more than 1.3K contributions from over 160 contributors and will improve going forward.
7. Retrieval Augmented Generation (RAG)
7.1. ChatQA 2: Bridging the Gap to Proprietary LLMs in Long Context and RAG Capabilities

In this work, we introduce ChatQA 2, a Llama3-based model designed to bridge the gap between open-access LLMs and leading proprietary models (e.g., GPT-4-Turbo) in long-context understanding and retrieval-augmented generation (RAG) capabilities.
These two capabilities are essential for LLMs to process large volumes of information that cannot fit into a single prompt and are complementary to each other, depending on the downstream tasks and computational budgets.
We present a detailed continued training recipe to extend the context window of Llama3–70B-base from 8K to 128K tokens, along with a three-stage instruction tuning process to enhance the model’s instruction-following, RAG performance, and long-context understanding capabilities.
Our results demonstrate that the Llama3-ChatQA-2–70B model achieves accuracy comparable to GPT-4-Turbo-2024–0409 on many long-context understanding tasks and surpasses it on the RAG benchmark.
Interestingly, we find that the state-of-the-art long-context retriever can alleviate the top-k context fragmentation issue in RAG, further improving RAG-based results for long-context understanding tasks. We also provide extensive comparisons between RAG and long-context solutions using state-of-the-art long-context LLMs.
8. Tokenizers
8.1. Data Mixture Inference: What do BPE Tokenizers Reveal about their Training Data?

The pretraining data of today’s strongest language models is opaque. In particular, little is known about the proportions of various domains or languages represented.
In this work, we tackle a task that we call data mixture inference, which aims to uncover the distributional makeup of training data. We introduce a novel attack based on a previously overlooked source of information — byte-pair encoding (BPE) tokenizers, used by the vast majority of modern language models.
Our key insight is that the ordered list of merge rules learned by a BPE tokenizer naturally reveals information about the token frequencies in its training data: the first merge is the most common byte pair, the second is the most common pair after merging the first token, and so on.
Given a tokenizer’s merge list along with data samples for each category of interest, we formulate a linear program that solves for the proportion of each category in the tokenizer’s training set.
Importantly, to the extent to which tokenizer training data is representative of the pretraining data, we indirectly learn about the pretraining data. In controlled experiments, we show that our attack recovers mixture ratios with high precision for tokenizers trained on known mixtures of natural languages, programming languages, and data sources.
We then apply our approach to off-the-shelf tokenizers released with recent LMs. We confirm much publicly disclosed information about these models, and also make several new inferences: GPT-4o’s tokenizer is much more multilingual than its predecessors, training on 39% non-English data; Llama3 extends GPT-3.5’s tokenizer primarily for multilingual (48%) use; GPT-3.5’s and Claude’s tokenizers are trained on predominantly code (~60%).
We hope our work sheds light on current design practices for pretraining data and inspires continued research into data mixture inference for LMs.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
