


Important LLMs Papers for the Week from 25/11 to 30/11
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Fourth Week of November 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
Transformers
LLM Training
LLM Quantization
LLM Reasoning
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. LLM Progress & Benchmarking
1.1. From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge
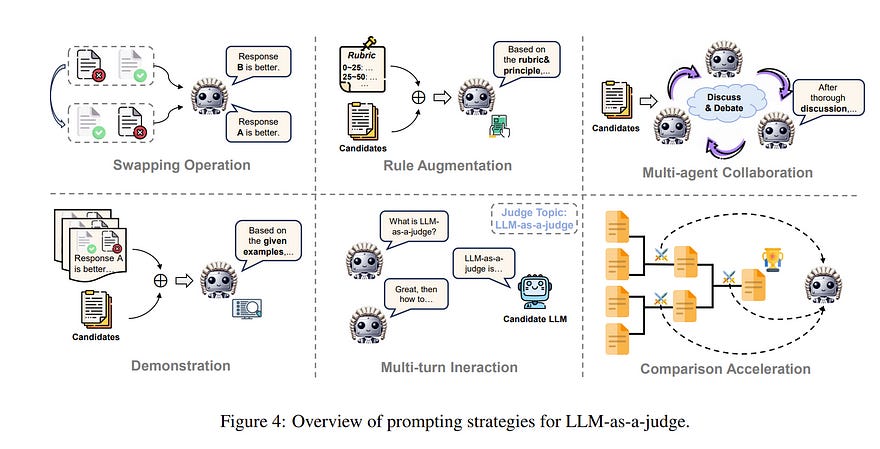
Assessment and evaluation have long been critical challenges in artificial intelligence (AI) and natural language processing (NLP). However, traditional methods, whether matching-based or embedding-based, often fall short of judging subtle attributes and delivering satisfactory results.
Recent advancements in Large Language Models (LLMs) inspire the “LLM-as-a-judge” paradigm, where LLMs are leveraged to perform scoring, ranking, or selection across various tasks and applications.
This paper provides a comprehensive survey of LLM-based judgment and assessment, offering an in-depth overview to advance this emerging field.
We begin by giving detailed definitions from both input and output perspectives. Then we introduce a comprehensive taxonomy to explore LLM-as-a-judge from three dimensions: what to judge, how to judge, and where to judge.
Finally, we compile benchmarks for evaluating LLM-as-a-judge and highlight key challenges and promising directions, aiming to provide valuable insights and inspire future research in this promising research area.
1.2. O1 Replication Journey — Part 2: Surpassing O1-preview through Simple Distillation, Big Progress or Bitter Lesson?

This paper presents a critical examination of current approaches to replicating OpenAI’s O1 model capabilities, with a particular focus on the widespread but often undisclosed use of knowledge distillation techniques.
While our previous work explored the fundamental technical path to O1 replication, this study reveals how simple distillation from O1’s API, combined with supervised fine-tuning, can achieve superior performance on complex mathematical reasoning tasks.
Through extensive experiments, we show that a base model fine-tuned on simply tens of thousands of samples of O1-distilled long-thought chains outperforms the O1-preview on the American Invitational Mathematics Examination (AIME) with minimal technical complexity.
Moreover, our investigation extends beyond mathematical reasoning to explore the generalization capabilities of O1-distilled models across diverse tasks: hallucination, safety, and open-domain QA.
Notably, despite training only on mathematical problem-solving data, our models demonstrated strong generalization to open-ended QA tasks and became significantly less susceptible to sycophancy after fine-tuning.
We deliberately make this finding public to promote transparency in AI research and to challenge the current trend of obscured technical claims in the field. Our work includes:
A detailed technical exposition of the distillation process and its effectiveness
A comprehensive benchmark framework for evaluating and categorizing O1 replication attempts based on their technical transparency and reproducibility
A critical discussion of the limitations and potential risks of over-relying on distillation approaches, our analysis culminates in a crucial bitter lesson: while the pursuit of more capable AI systems is important, the development of researchers grounded in first-principles thinking is paramount.
2. Transformers
2.1. Star Attention: Efficient LLM Inference over Long Sequences
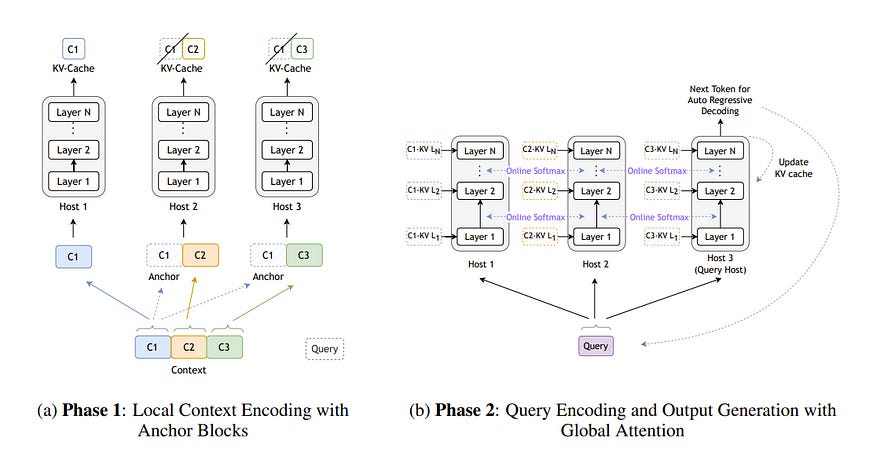
Inference with Transformer-based Large Language Models (LLMs) on long sequences is both costly and slow due to the quadratic complexity of the self-attention mechanism.
We introduce Star Attention, a two-phase block-sparse approximation that improves computational efficiency by sharding attention across multiple hosts while minimizing communication overhead.
In the first phase, the context is processed using blockwise-local attention across hosts, in parallel. In the second phase, query and response tokens attend to all prior cached tokens through sequence-global attention.
Star Attention integrates seamlessly with most Transformer-based LLMs trained with global attention, reducing memory requirements and inference time by up to 11x while preserving 95–100% accuracy.
3. LLM Training
3.1. TÜLU 3: Pushing Frontiers in Open Language Model Post-Training

Language model post-training is applied to refine behaviors and unlock new skills across a wide range of recent language models, but open recipes for applying these techniques lag behind proprietary ones.
The underlying training data and recipes for post-training are simultaneously the most important pieces of the puzzle and the portion with the least transparency.
To bridge this gap, we introduce TULU 3, a family of fully open state-of-the-art post-trained models, alongside its data, code, and training recipes, serving as a comprehensive guide for modern post-training techniques.
TULU 3, which builds on Llama 3.1 base models, achieves results surpassing the instruct versions of Llama 3.1, Qwen 2.5, Mistral, and even closed models such as GPT-4o-mini and Claude 3.5-Haiku.
The training algorithms for our models include supervised finetuning (SFT), Direct Preference Optimization (DPO), and a novel method we call Reinforcement Learning with Verifiable Rewards (RLVR).
With TULU 3, we introduce a multi-task evaluation scheme for post-training recipes with development and unseen evaluations, standard benchmark implementations, and substantial decontamination of existing open datasets on said benchmarks.
We conclude with an analysis and discussion of training methods that did not reliably improve performance. In addition to the TULU 3 model weights and demo, we release the complete recipe — including datasets for diverse core skills, a robust toolkit for data curation and evaluation, the training code and infrastructure, and, most importantly, a detailed report for reproducing and further adapting the TULU 3 approach to more domains.
4. LLM Quantization
4.1. Low-Bit Quantization Favors Undertrained LLMs: Scaling Laws for Quantized LLMs with 100T Training Tokens
We reveal that low-bit quantization favors undertrained large language models (LLMs) by observing that models with larger sizes or fewer training tokens experience less quantization-induced degradation (QiD) when applying low-bit quantization, whereas smaller models with extensive training tokens suffer significant QiD.
To gain deeper insights into this trend, we study over 1500 quantized LLM checkpoints of various sizes and at different training levels (undertrained or fully trained) in a controlled setting, deriving scaling laws for understanding the relationship between QiD and factors such as the number of training tokens, model size, and bit width.
With the derived scaling laws, we propose a novel perspective that we can use QiD to measure an LLM’s training levels and determine the number of training tokens required for fully training LLMs of various sizes. Moreover, we use the scaling laws to predict the quantization performance of different-sized LLMs trained with 100 trillion tokens.
Our projection shows that the low-bit quantization performance of future models, which are expected to be trained with over 100 trillion tokens, may NOT be desirable.
This poses a potential challenge for low-bit quantization in the future and highlights the need for awareness of a model’s training level when evaluating low-bit quantization research.
5. LLM Reasoning
5.1. Large Multi-modal Models Can Interpret Features in Large Multi-modal Models

Recent advances in Large Multimodal Models (LMMs) have led to significant breakthroughs in both academia and industry. One question that arises is how we, as humans, can understand their internal neural representations.
This paper takes an initial step towards addressing this question by presenting a versatile framework to identify and interpret the semantics within LMMs.
Specifically, 1) we first apply a Sparse Autoencoder(SAE) to disentangle the representations into human-understandable features. 2) We then present an automatic interpretation framework to interpret the open-semantic features learned in SAE by the LMMs themselves.
We employ this framework to analyze the LLaVA-NeXT-8B model using the LLaVA-OV-72B model, demonstrating that these features can effectively steer the model’s behavior.
Our results contribute to a deeper understanding of why LMMs excel in specific tasks, including EQ tests, and illuminate the nature of their mistakes along with potential strategies for their rectification.
These findings offer new insights into the internal mechanisms of LMMs and suggest parallels with the cognitive processes of the human brain.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
