


Important LLMs Papers for the Week from 18/11 to 24/11
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Third Week of November 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
Transformers
LLM Reasoning
LLM Agents
Retrieval Augment Generation (RAG)
LLM Alignment & Safety
LLM Quantization
LLM Training & Fine Tuning
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. LLM Progress & Benchmarking
1.1. BlueLM-V-3B: Algorithm and System Co-Design for Multimodal Large Language Models on Mobile Devices

The emergence and growing popularity of multimodal large language models (MLLMs) have significant potential to enhance various aspects of daily life, from improving communication to facilitating learning and problem-solving.
Mobile phones, as essential daily companions, represent the most effective and accessible deployment platform for MLLMs, enabling seamless integration into everyday tasks.
However, deploying MLLMs on mobile phones presents challenges due to limitations in memory size and computational capability, making it difficult to achieve smooth and real-time processing without extensive optimization.
In this paper, we present BlueLM-V-3B, an algorithm and system co-design approach specifically tailored for the efficient deployment of MLLMs on mobile platforms.
To be specific, we redesign the dynamic resolution scheme adopted by mainstream MLLMs and implement system optimization for hardware-aware deployment to optimize model inference on mobile phones.
BlueLM-V-3B boasts the following key highlights: (1) Small Size: BlueLM-V-3B features a language model with 2.7B parameters and a vision encoder with 400M parameters. (2) Fast Speed: BlueLM-V-3B achieves a generation speed of 24.4 token/s on the MediaTek Dimensity 9300 processor with 4-bit LLM weight quantization. (3) Strong Performance: BlueLM-V-3B has attained the highest average score of 66.1 on the OpenCompass benchmark among models with leq 4B parameters and surpassed a series of models with much larger parameter sizes (e.g., MiniCPM-V-2.6, InternVL2–8B).
1.2. SlimLM: An Efficient Small Language Model for On-Device Document Assistance

While small language models (SLMs) show promises for mobile deployment, their real-world performance and applications on smartphones remain underexplored.
We present SlimLM, a series of SLMs optimized for document assistance tasks on mobile devices. Through extensive experiments on a Samsung Galaxy S24, we identify the optimal trade-offs between model size (ranging from 125M to 7B parameters), context length, and inference time for efficient on-device processing.
SlimLM is pre-trained on SlimPajama-627B and fine-tuned on DocAssist, our constructed dataset for summarization, question answering, and suggestion tasks. Our smallest model demonstrates efficient performance on S24, while larger variants offer enhanced capabilities within mobile constraints.
We evaluate SlimLM against existing SLMs, showing comparable or superior performance and offering a benchmark for future research in on-device language models. We also provide an Android application that offers practical insights into SLM deployment.
Our findings provide valuable insights and illuminate the capabilities of running advanced language models on high-end smartphones, potentially reducing server costs and enhancing privacy through on-device processing.
1.3. RedPajama: an Open Dataset for Training Large Language Models

Large language models are increasingly becoming a cornerstone technology in artificial intelligence, the sciences, and society as a whole, yet the optimal strategies for dataset composition and filtering remain largely elusive.
Many of the top-performing models lack transparency in their dataset curation and model development processes, posing an obstacle to the development of fully open language models.
In this paper, we identify three core data-related challenges that must be addressed to advance open-source language models. These include (1) transparency in model development, including the data curation process, (2) access to large quantities of high-quality data, and (3) availability of artifacts and metadata for dataset curation and analysis.
To address these challenges, we release RedPajama-V1, an open reproduction of the LLaMA training dataset. In addition, we release RedPajama-V2, a massive web-only dataset consisting of raw, unfiltered text data together with quality signals and metadata.
Together, the RedPajama datasets comprise over 100 trillion tokens spanning multiple domains and with their quality signals facilitate the filtering of data, aiming to inspire the development of numerous new datasets.
To date, these datasets have already been used in the training of strong language models used in production, such as Snowflake Arctic, Salesforce’s XGen, and AI2’s OLMo.
To provide insight into the quality of RedPajama, we present a series of analyses and ablation studies with decoder-only language models with up to 1.6B parameters.
Our findings demonstrate how quality signals for web data can be effectively leveraged to curate high-quality subsets of the dataset, underscoring the potential of RedPajama to advance the development of transparent and high-performing language models at scale.
2. Transformers
2.1. SageAttention2 Technical Report: Accurate 4-Bit Attention for Plug-and-play Inference Acceleration

Although quantization for linear layers has been widely used, its application to accelerate the attention process remains limited. SageAttention utilizes 8-bit matrix multiplication, 16-bit matrix multiplication with a 16-bit accumulator, and precision-enhancing methods, implementing an accurate and 2x speedup kernel compared to FlashAttention2.
To further enhance the efficiency of attention computation while maintaining precision, we propose SageAttention2, which utilizes significantly faster 4-bit matrix multiplication (Matmul) alongside additional precision-enhancing techniques.
First, we propose to quantize matrixes (Q, K) to INT4 in a warp-level granularity and quantize matrixes (wide-tilde P, V) to FP8. Second, we propose a method to smooth Q and V, enhancing the accuracy of attention with INT4 QK and FP8 PV.
Third, we analyze the quantization accuracy across timesteps and layers, then propose an adaptive quantization method to ensure the end-to-end metrics over various models.
The operations per second (OPS) of SageAttention2 surpass FlashAttention2 and xformers by about 3x and 5x on RTX4090, respectively. Comprehensive experiments confirm that our approach incurs negligible end-to-end metrics loss across diverse models, including those for large language processing, image generation, and video generation.
3. LLM Reasoning
3.1. Patience Is The Key to Large Language Model Reasoning

Recent advancements in the field of large language models, particularly through the Chain of Thought (CoT) approach, have demonstrated significant improvements in solving complex problems.
However, existing models either tend to sacrifice detailed reasoning for brevity due to user preferences or require extensive and expensive training data to learn complicated reasoning abilities, limiting their potential to solve complex tasks.
To bridge this gap, following the concept of scaling test time, we propose a simple method by encouraging models to adopt a more patient reasoning style without the need to introduce new knowledge or skills.
To employ a preference optimization approach, we generate detailed reasoning processes as positive examples and simple answers as negative examples, thereby training the model to favor thoroughness in its responses. Our results demonstrate a performance increase of up to 6.7% on GSM8k with training just on a lightweight dataset.
3.2. Insight-V: Exploring Long-Chain Visual Reasoning with Multimodal Large Language Models

Large Language Models (LLMs) demonstrate enhanced capabilities and reliability by reasoning more, evolving from Chain-of-Thought prompting to product-level solutions like OpenAI o1.
Despite various efforts to improve LLM reasoning, high-quality long-chain reasoning data, and optimized training pipelines still remain inadequately explored in vision-language tasks.
In this paper, we present Insight-V, an early effort to 1) scalably produce long and robust reasoning data for complex multi-modal tasks, and 2) an effective training pipeline to enhance the reasoning capabilities of multi-modal large language models (MLLMs).
Specifically, to create long and structured reasoning data without human labor, we design a two-step pipeline with a progressive strategy to generate sufficiently long and diverse reasoning paths and a multi-granularity assessment method to ensure data quality.
We observe that directly supervising MLLMs with such long and complex reasoning data will not yield ideal reasoning ability. To tackle this problem, we design a multi-agent system consisting of a reasoning agent dedicated to performing long-chain reasoning and a summary agent trained to judge and summarize reasoning results.
We further incorporate an iterative DPO algorithm to enhance the reasoning agent’s generation stability and quality. Based on the popular LLaVA-NeXT model and our stronger base MLLM, we demonstrate significant performance gains across challenging multi-modal benchmarks requiring visual reasoning. Benefiting from our multi-agent system, Insight-V can also easily maintain or improve performance on perception-focused multi-modal tasks.
3.3. Enhancing the Reasoning Ability of Multimodal Large Language Models via Mixed Preference Optimization

Existing open-source multimodal large language models (MLLMs) generally follow a training process involving pre-training and supervised fine-tuning.
However, these models suffer from distribution shifts, which limit their multimodal reasoning, particularly in the Chain-of-Thought (CoT) performance. To address this, we introduce a preference optimization (PO) process to enhance the multimodal reasoning capabilities of MLLMs.
Specifically, (1) on the data side, we design an automated preference data construction pipeline to create MMPR, a high-quality, large-scale multimodal reasoning preference dataset. and (2) on the model side, we explore integrating PO with MLLMs, developing a simple yet effective method, termed Mixed Preference Optimization (MPO), which boosts multimodal CoT performance.
Our approach demonstrates improved performance across multiple benchmarks, particularly in multimodal reasoning tasks. Notably, our model, InternVL2–8B-MPO, achieves an accuracy of 67.0 on MathVista, outperforming InternVL2–8B by 8.7 points and achieving performance comparable to the 10x larger InternVL2–76B. We hope this study could inspire further advancements in MLLMs. Code, data, and model shall be publicly released.
3.4. Marco-o1: Towards Open Reasoning Models for Open-Ended Solutions

Currently, OpenAI o1 has sparked a surge of interest in the study of large reasoning models (LRM). Building on this momentum, Marco-o1 not only focuses on disciplines with standard answers, such as mathematics, physics, and coding — which are well-suited for reinforcement learning (RL) — but also places greater emphasis on open-ended resolutions.
We aim to address the question: “Can the o1 model effectively generalize to broader domains where clear standards are absent and rewards are challenging to quantify?”
Marco-o1 is powered by Chain-of-Thought (CoT) fine-tuning, Monte Carlo Tree Search (MCTS), reflection mechanisms, and innovative reasoning strategies — optimized for complex real-world problem-solving tasks.
4. LLM Agents
4.1. Is Your LLM Secretly a World Model of the Internet? Model-Based Planning for Web Agents

Language agents have demonstrated promising capabilities in automating web-based tasks, though their current reactive approaches still underperform largely compared to humans.
While incorporating advanced planning algorithms, particularly tree search methods, could enhance these agents’ performance, implementing tree search directly on live websites poses significant safety risks and practical constraints due to irreversible actions such as confirming a purchase.
In this paper, we introduce a novel paradigm that augments language agents with model-based planning, pioneering the innovative use of large language models (LLMs) as world models in complex web environments.
Our method, WebDreamer, builds on the key insight that LLMs inherently encode comprehensive knowledge about website structures and functionalities.
Specifically, WebDreamer uses LLMs to simulate outcomes for each candidate action (e.g., “What would happen if I click this button?”) using natural language descriptions, and then evaluates these imagined outcomes to determine the optimal action at each step.
Empirical results on two representative web agent benchmark with online interaction — VisualWebArena and Mind2Web-live — demonstrate that WebDreamer achieves substantial improvements over reactive baselines. By establishing the viability of LLMs as world models in web environments, this work lays the groundwork for a paradigm shift in automated web interaction.
More broadly, our findings open exciting new avenues for future research into 1) optimizing LLMs specifically for world modeling in complex, dynamic environments, and 2) model-based speculative planning for language agents.
5. Retrieval Augment Generation (RAG)
5.1. OpenScholar: Synthesizing Scientific Literature with Retrieval-augmented LMs
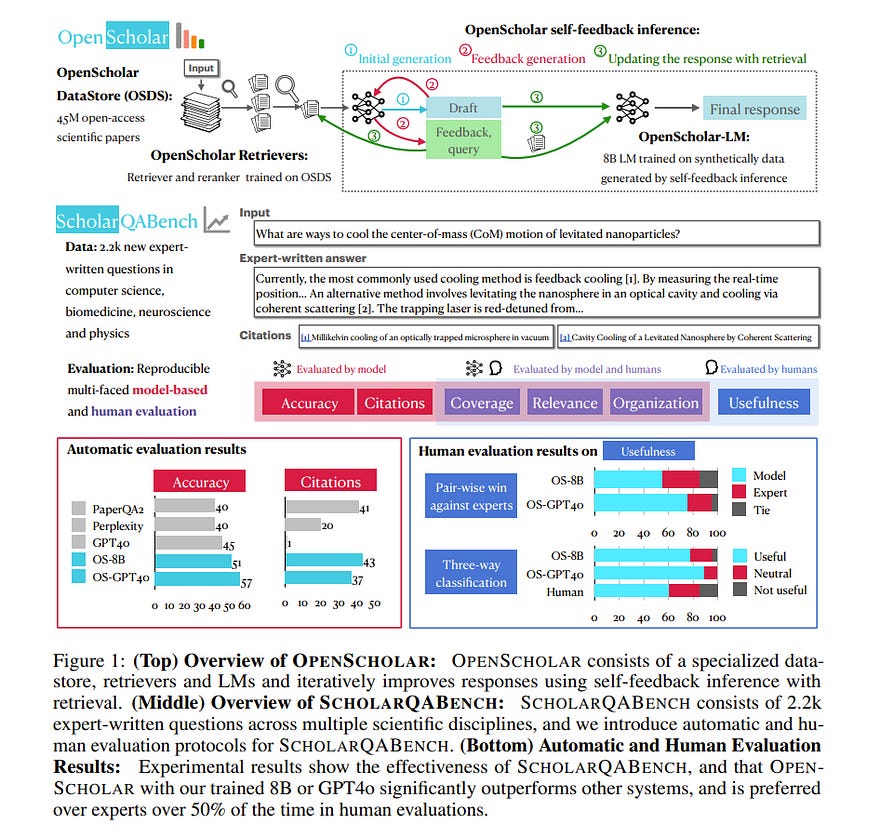
Scientific progress depends on researchers’ ability to synthesize the growing body of literature. Can large language models (LMs) assist scientists in this task?
We introduce OpenScholar, a specialized retrieval-augmented LM that answers scientific queries by identifying relevant passages from 45 million open-access papers and synthesizing citation-backed responses.
To evaluate OpenScholar, we develop ScholarQABench, the first large-scale multi-domain benchmark for literature search, comprising 2,967 expert-written queries and 208 long-form answers across computer science, physics, neuroscience, and biomedicine.
On ScholarQABench, OpenScholar-8B outperforms GPT-4o by 5% and PaperQA2 by 7% in correctness, despite being a smaller, open model. While GPT4o hallucinates citations 78 to 90% of the time, OpenScholar achieves citation accuracy on par with human experts.
OpenScholar’s datastore, retriever, and self-feedback inference loop also improve off-the-shelf LMs: for instance, OpenScholar-GPT4o improves GPT-4o’s correctness by 12%.
In human evaluations, experts preferred OpenScholar-8B and OpenScholar-GPT4o responses over expert-written ones 51% and 70% of the time, respectively, compared to GPT4o’s 32%. We open-source all of our code, models, datastore, data, and a public demo.
6. LLM Alignment & Safety
6.1. SymDPO: Boosting In-Context Learning of Large Multimodal Models with Symbol Demonstration Direct Preference Optimization
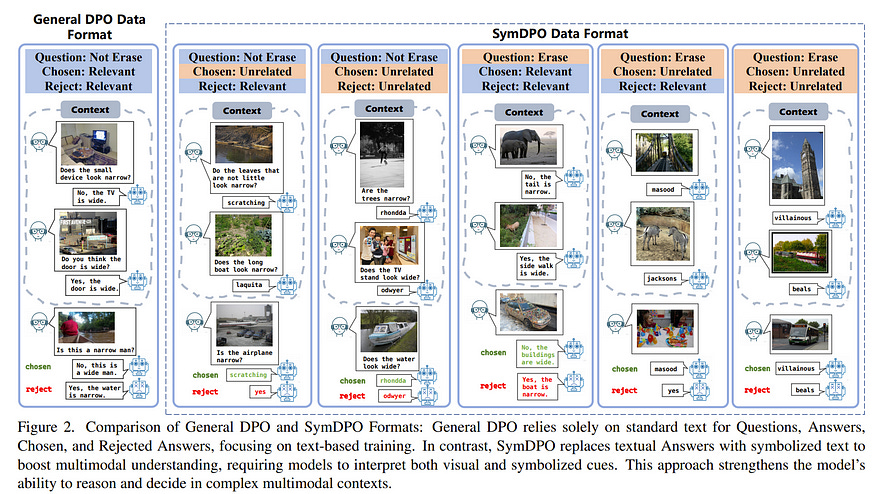
As language models continue to scale, Large Language Models (LLMs) have exhibited emerging capabilities in In-Context Learning (ICL), enabling them to solve language tasks by prefixing a few in-context demonstrations (ICDs) as context.
Inspired by these advancements, researchers have extended these techniques to develop Large Multimodal Models (LMMs) with ICL capabilities. However, existing LMMs face a critical issue: they often fail to effectively leverage the visual context in multimodal demonstrations and instead simply follow textual patterns.
This indicates that LMMs do not achieve effective alignment between multimodal demonstrations and model outputs. To address this problem, we propose Symbol Demonstration Direct Preference Optimization (SymDPO).
Specifically, SymDPO aims to break the traditional paradigm of constructing multimodal demonstrations by using random symbols to replace text answers within instances. This forces the model to carefully understand the demonstration images and establish a relationship between the images and the symbols to answer questions correctly.
We validate the effectiveness of this method on multiple benchmarks, demonstrating that with SymDPO, LMMs can more effectively understand the multimodal context within examples and utilize this knowledge to answer questions better.
7. LLM Quantization
7.1. When Precision Meets Position: BFloat16 Breaks Down RoPE in Long-Context Training

Extending context window sizes allows large language models (LLMs) to process longer sequences and handle more complex tasks. Rotary Positional Embedding (RoPE) has become the de facto standard due to its relative positional encoding properties that benefit long-context training.
However, we observe that using RoPE with BFloat16 format results in numerical issues, causing it to deviate from its intended relative positional encoding, especially in long-context scenarios.
This issue arises from BFloat16’s limited precision and accumulates as context length increases, with the first token contributing significantly to this problem.
To address this, we develop AnchorAttention, a plug-and-play attention method that alleviates numerical issues caused by BFloat16, improves long-context capabilities, and speeds up training.
AnchorAttention reduces unnecessary attention computations, maintains semantic coherence, and boosts computational efficiency by treating the first token as a shared anchor with a consistent position ID, making it visible to all documents within the training context.
Experiments on three types of LLMs demonstrate that AnchorAttention significantly improves long-context performance and reduces training time by over 50% compared to standard full attention mechanisms while preserving the original LLM’s capabilities on general tasks.
8. LLM Training & Fine Tuning
8.1. Search, Verify, and Feedback: Towards Next Generation Post-training Paradigm of Foundation Models via Verifier Engineering

The evolution of machine learning has increasingly prioritized the development of powerful models and more scalable supervision signals.
However, the emergence of foundation models presents significant challenges in providing effective supervision signals necessary for further enhancing their capabilities.
Consequently, there is an urgent need to explore novel supervision signals and technical approaches. In this paper, we propose verifier engineering, a novel post-training paradigm specifically designed for the era of foundation models.
The core of verifier engineering involves leveraging a suite of automated verifiers to perform verification tasks and deliver meaningful feedback to foundation models.
We systematically categorize the verifier engineering process into three essential stages: search, verify, and feedback, and provide a comprehensive review of state-of-the-art research developments within each stage. We believe that verifier engineering constitutes a fundamental pathway toward achieving Artificial General Intelligence.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
