


Important LLMs Papers for the Week from 23/09 to 29/09
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Fourth Week of September 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
Tokenizers & Embeddings
LLM Training, Evaluation & Inference
Retrieval Augmented Generation (RAG)
My New E-Book: Prompt Engineering Best Practices for Instruction-Tuned LLM

I am happy to announce that I have published a new ebook Prompt Engineering Best Practices for Instruction-Tuned LLM. Prompt Engineering Best Practices for Instruction-Tuned LLM is a comprehensive guide designed to equip readers with the essential knowledge and tools to master the fine-tuning and prompt engineering of large language models (LLMs). The book covers everything from foundational concepts to advanced applications, making it an invaluable resource for anyone interested in leveraging the full potential of instruction-tuned models.
1. LLM Progress & Benchmarking
1.1. A Preliminary Study of o1 in Medicine: Are We Closer to an AI Doctor?
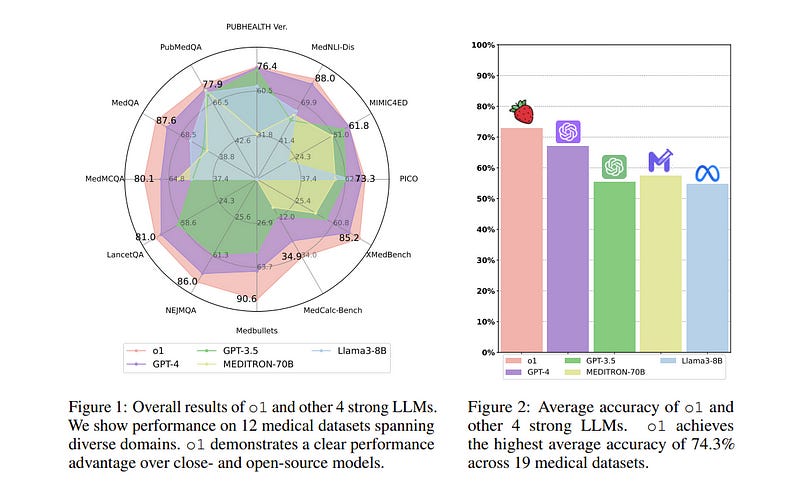
Large language models (LLMs) have exhibited remarkable capabilities across various domains and tasks, pushing the boundaries of our knowledge in learning and cognition.
The latest model, OpenAI’s o1, stands out as the first LLM with an internalized chain-of-thought technique using reinforcement learning strategies.
While it has demonstrated surprisingly strong capabilities on various general language tasks, its performance in specialized fields such as medicine remains unknown.
To this end, this report provides a comprehensive exploration of o1 in different medical scenarios, examining 3 key aspects: understanding, reasoning, and multilingual.
Specifically, our evaluation encompasses 6 tasks using data from 37 medical datasets, including two newly constructed and more challenging question-answering (QA) tasks based on professional medical quizzes from the New England Journal of Medicine (NEJM) and The Lancet.
These datasets offer greater clinical relevance compared to standard medical QA benchmarks such as MedQA, translating more effectively into real-world clinical utility.
Our analysis of o1 suggests that the enhanced reasoning ability of LLMs may (significantly) benefit their capability to understand various medical instructions and reason through complex clinical scenarios. Notably, o1 surpasses the previous GPT-4 in accuracy by an average of 6.2% and 6.6% across 19 datasets and two newly created complex QA scenarios.
Meanwhile, we identify several weaknesses in both the model capability and the existing evaluation protocols, including hallucination, inconsistent multilingual ability, and discrepant metrics for evaluation.
1.2. EuroLLM: Multilingual Language Models for Europe
The quality of open-weight LLMs has seen significant improvement, yet they remain predominantly focused on English.
In this paper, we introduce the EuroLLM project, aimed at developing a suite of open-weight multilingual LLMs capable of understanding and generating text in all official European Union languages, as well as several additional relevant languages.
We outline the progress made to date, detailing our data collection and filtering process, the development of scaling laws, the creation of our multilingual tokenizer, and the data mix and modeling configurations.
Additionally, we release our initial models: EuroLLM-1.7B and EuroLLM-1.7B-Instruct, and report their performance on multilingual general benchmarks and machine translation.
1.3. EMOVA: Empowering Language Models to See, Hear, and Speak with Vivid Emotions

GPT-4o, an Omni-modal model that enables vocal conversations with diverse emotions and tones, marks a milestone for omni-modal foundation models.
However, empowering Large Language Models to perceive and generate images, texts, and speeches end-to-end with publicly available data remains challenging in the open-source community.
Existing vision-language models rely on external tools for speech processing, while speech-language models still suffer from limited or even vision-understanding abilities. To address this gap, we propose EMOVA (EMotionally Omni-present Voice Assistant), to enable Large Language Models with end-to-end speech capabilities while maintaining the leading vision-language performance.
With a semantic-acoustic disentangled speech tokenizer, we notice surprisingly that omni-modal alignment can further enhance vision-language and speech abilities compared with the corresponding bi-modal aligned counterparts.
Moreover, a lightweight style module is proposed for flexible speech style controls (e.g., emotions and pitches). For the first time, EMOVA achieves state-of-the-art performance on both the vision-language and speech benchmarks, meanwhile, supporting omni-modal spoken dialogue with vivid emotions.
1.4. OmniBench: Towards The Future of Universal Omni-Language Models

Recent advancements in multimodal large language models (MLLMs) have aimed to integrate and interpret data across diverse modalities. However, the capacity of these models to concurrently process and reason about multiple modalities remains inadequately explored, partly due to the lack of comprehensive modality-wise benchmarks.
We introduce OmniBench, a novel benchmark designed to rigorously evaluate models’ ability to recognize, interpret, and reason across visual, acoustic, and textual inputs simultaneously. We define models capable of such tri-modal processing as omni-language models (OLMs).
OmniBench is distinguished by high-quality human annotations, ensuring that accurate responses require integrated understanding and reasoning across all three modalities.
Our main findings reveal that:
Open-source OLMs exhibit critical limitations in instruction-following and reasoning capabilities within tri-modal contexts.
The baseline models perform poorly (below 50% accuracy) even when provided with alternative textual representations of images and audio.
These results suggest that the ability to construct a consistent context from text, image, and audio is often overlooked in existing MLLM training paradigms. We advocate for future research to focus on developing more robust tri-modal integration techniques and training strategies to enhance OLM performance across diverse modalities.
2. Tokenizers & Embeddings Models
2.1. Making Text Embedders Few-Shot Learners
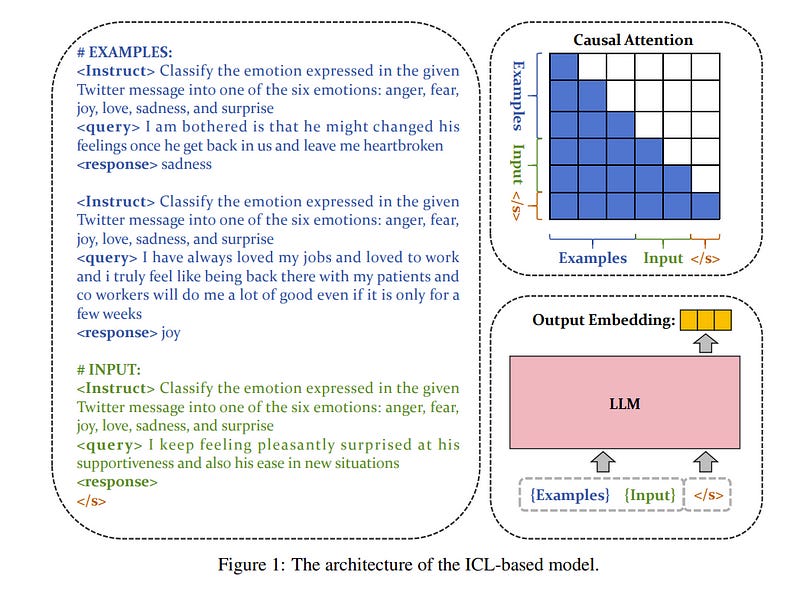
Large language models (LLMs) with decoder-only architectures demonstrate remarkable in-context learning (ICL) capabilities. This feature enables them to effectively handle both familiar and novel tasks by utilizing examples provided within their input context.
Recognizing the potential of this capability, we propose leveraging the ICL feature in LLMs to enhance the process of text embedding generation. To this end, we introduce a novel model bge-en-icl, which employs few-shot examples to produce high-quality text embeddings.
Our approach integrates task-related examples directly into the query side, resulting in significant improvements across various tasks. Additionally, we have investigated how to effectively utilize LLMs as embedding models, including various attention mechanisms, pooling methods, etc.
Our findings suggest that retaining the original framework often yields the best results, underscoring that simplicity is best. Experimental results on the MTEB and AIR-Bench benchmarks demonstrate that our approach sets new state-of-the-art (SOTA) performance.
3. LLM Training, Evaluation & Inference
3.1. HelloBench: Evaluating Long Text Generation Capabilities of Large Language Models

In recent years, Large Language Models (LLMs) have demonstrated remarkable capabilities in various tasks (e.g., long-context understanding), and many benchmarks have been proposed.
However, we observe that long text generation capabilities are not well investigated. Therefore, we introduce the Hierarchical Long Text Generation Benchmark (HelloBench), a comprehensive, in-the-wild, and open-ended benchmark to evaluate LLMs’ performance in generating long text.
Based on Bloom’s Taxonomy, HelloBench categorizes long text generation tasks into five subtasks: open-ended QA, summarization, chat, text completion, and heuristic text generation. Besides, we propose Hierarchical Long Text Evaluation (HelloEval), a human-aligned evaluation method that significantly reduces the time and effort required for human evaluation while maintaining a high correlation with human evaluation.
We have conducted extensive experiments across around 30 mainstream LLMs and observed that the current LLMs lack long text generation capabilities. Specifically, first, regardless of whether the instructions include explicit or implicit length constraints, we observe that most LLMs cannot generate text that is longer than 4000 words.
Second, we observe that while some LLMs can generate longer text, many issues exist (e.g., severe repetition and quality degradation). Third, to demonstrate the effectiveness of HelloEval, we compare HelloEval with traditional metrics (e.g., ROUGE, BLEU, etc.) and LLM-as-a-Judge methods, which show that HelloEval has the highest correlation with human evaluation.
3.2. MaskLLM: Learnable Semi-Structured Sparsity for Large Language Models

Large Language Models (LLMs) are distinguished by their massive parameter counts, which typically result in significant redundancy. This work introduces MaskLLM, a learnable pruning method that establishes Semi-structured (or ``N:M’’) Sparsity in LLMs, aimed at reducing computational overhead during inference.
Instead of developing a new importance criterion, MaskLLM explicitly models N:M patterns as a learnable distribution through Gumbel Softmax sampling. This approach facilitates end-to-end training on large-scale datasets and offers two notable advantages:
High-quality Masks — our method effectively scales to large datasets and learns accurate masks.
Transferability — the probabilistic modeling of mask distribution enables the transfer learning of sparsity across domains or tasks.
We assessed MaskLLM using 2:4 sparsity on various LLMs, including LLaMA-2, Nemotron-4, and GPT-3, with sizes ranging from 843M to 15B parameters, and our empirical results show substantial improvements over state-of-the-art methods.
For instance, leading approaches achieve a perplexity (PPL) of 10 or greater on Wikitext compared to the dense model’s 5.12 PPL, but MaskLLM achieves a significantly lower 6.72 PPL solely by learning the masks with frozen weights. Furthermore, MaskLLM’s learnable nature allows customized masks for lossless application of 2:4 sparsity to downstream tasks or domains.
3.3. Programming Every Example: Lifting Pre-training Data Quality like Experts at Scale

Large language model pre-training has traditionally relied on human experts to craft heuristics for improving the corpora quality, resulting in numerous rules developed to date.
However, these rules lack the flexibility to address the unique characteristics of individual examples effectively. Meanwhile, applying tailored rules to every example is impractical for human experts. In this paper, we demonstrate that even small language models, with as few as 0.3B parameters, can exhibit substantial data refining capabilities comparable to those of human experts.
We introduce Programming Every Example (ProX), a novel framework that treats data refinement as a programming task, enabling models to refine corpora by generating and executing fine-grained operations, such as string normalization, for each individual example at scale.
Experimental results show that models pre-trained on ProX-curated data outperform either original data or data filtered by other selection methods by more than 2% across various downstream benchmarks. Its effectiveness spans various model sizes and pre-training corpora, including C4, RedPajama-V2, and FineWeb.
Furthermore, ProX exhibits significant potential in domain-specific continual pre-training: without domain-specific design, models trained on OpenWebMath refined by ProX outperform human-crafted rule-based methods, improving average accuracy by 7.6% over Mistral-7B, with 14.6% for Llama-2–7B and 20.3% for CodeLlama-7B, all within 10B tokens to be comparable to models like Llemma-7B trained on 200B tokens.
Further analysis highlights that ProX significantly saves training FLOPs, offering a promising path for efficient LLM pre-training. We are open-sourcing ProX with >100B corpus, and models, and sharing all training and implementation details for reproducible research and future innovation.
3.4. RACER: Rich Language-Guided Failure Recovery Policies for Imitation Learning

Developing robust and correctable visuomotor policies for robotic manipulation is challenging due to the lack of self-recovery mechanisms from failures and the limitations of simple language instructions in guiding robot actions.
To address these issues, we propose a scalable data generation pipeline that automatically augments expert demonstrations with failure recovery trajectories and fine-grained language annotations for training. We then introduce Rich languAge-guided failure reCovERy (RACER), a supervisor-actor framework, which combines failure recovery data with rich language descriptions to enhance robot control.
RACER features a vision-language model (VLM) that acts as an online supervisor, providing detailed language guidance for error correction and task execution, and a language-conditioned visuomotor policy as an actor to predict the next actions.
Our experimental results show that RACER outperforms the state-of-the-art Robotic View Transformer (RVT) on RLbench across various evaluation settings, including standard long-horizon tasks, dynamic goal-change tasks, and zero-shot unseen tasks, achieving superior performance in both simulated and real-world environments.
4. Retrieval Augmented Generation (RAG)
4.1. Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation

Large Language Models (LLMs) have demonstrated significant performance improvements across various cognitive tasks. An emerging application is using LLMs to enhance retrieval-augmented generation (RAG) capabilities.
These systems require LLMs to understand user queries, retrieve relevant information, and synthesize coherent and accurate responses. Given the increasing real-world deployment of such systems, comprehensive evaluation becomes crucial.
To this end, we propose FRAMES (Factuality, Retrieval, and Reasoning MEasurement Set), a high-quality evaluation dataset designed to test LLMs’ ability to provide factual responses, assess retrieval capabilities, and evaluate the reasoning required to generate final answers.
While previous work has provided datasets and benchmarks to evaluate these abilities in isolation, FRAMES offers a unified framework that provides a clearer picture of LLM performance in end-to-end RAG scenarios.
Our dataset comprises challenging multi-hop questions that require the integration of information from multiple sources. We present baseline results demonstrating that even state-of-the-art LLMs struggle with this task, achieving 0.40 accuracy with no retrieval.
The accuracy is significantly improved with our proposed multi-step retrieval pipeline, achieving an accuracy of 0.66 (>50% improvement). We hope our work will help bridge evaluation gaps and assist in developing more robust and capable RAG systems.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
