
Important LLMs Papers for the Week from 30/12 to 05/01
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the First Week of January 2025. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Training
LLM Agents
LLM Reasoning
My New E-Book: Efficient Python for Data Scientists

I am happy to announce publishing my new E-book Efficient Python for Data Scientists. Efficient Python for Data Scientists is your practical companion to mastering the art of writing clean, optimized, and high-performing Python code for data science. In this book, you'll explore actionable insights and strategies to transform your Python workflows, streamline data analysis, and maximize the potential of libraries like Pandas.
1. LLM Progress & Benchmarking
1.1. Next Token Prediction Towards Multimodal Intelligence: A Comprehensive Survey
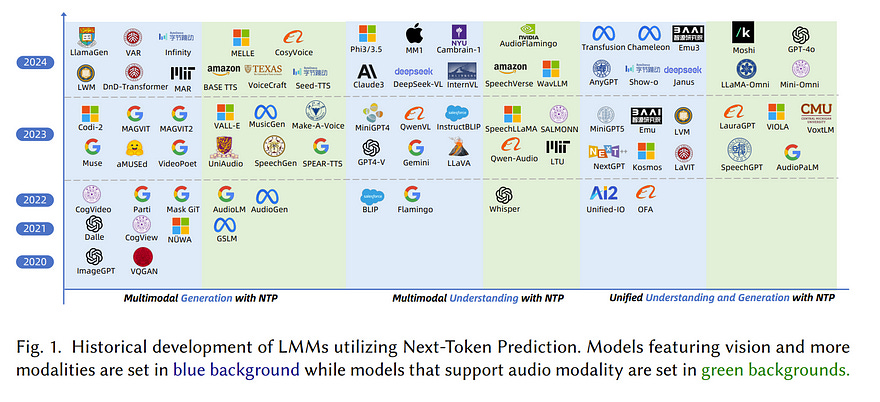
Building on the foundations of language modeling in natural language processing, Next Token Prediction (NTP) has evolved into a versatile training objective for machine learning tasks across various modalities, achieving considerable success.
As Large Language Models (LLMs) have advanced to unify understanding and generation tasks within the textual modality, recent research has shown that tasks from different modalities can also be effectively encapsulated within the NTP framework, transforming the multimodal information into tokens and predict the next one given the context.
This survey introduces a comprehensive taxonomy that unifies both understanding and generation within multimodal learning through the lens of NTP.
The proposed taxonomy covers five key aspects: Multimodal tokenization, MMNTP model architectures, unified task representation, datasets \& evaluation, and open challenges. This new taxonomy aims to aid researchers in their exploration of multimodal intelligence.
1.2. Xmodel-2 Technical Report
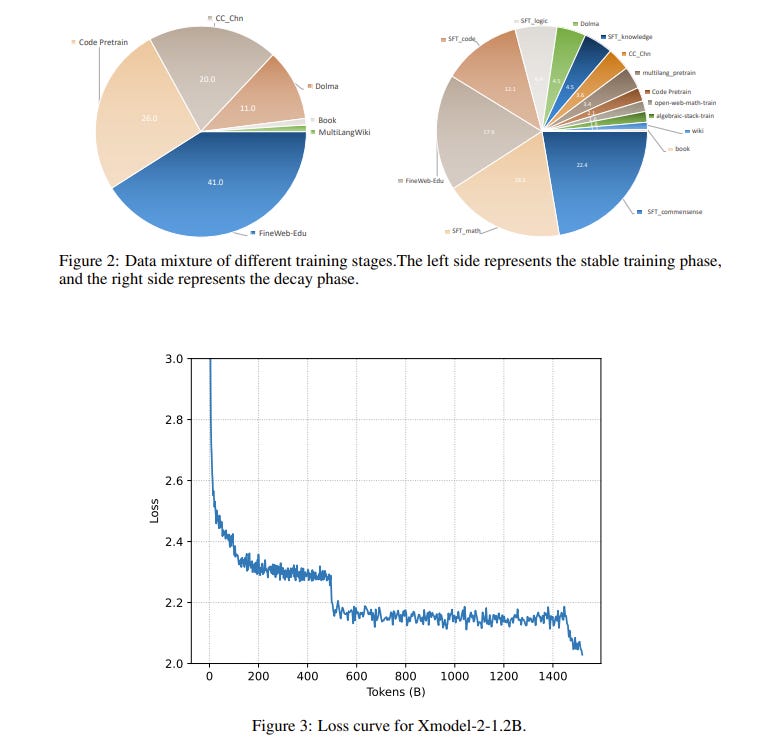
Xmodel-2 is a 1.2-billion-parameter large language model designed specifically for reasoning tasks. Its architecture enables different model scales to share a unified set of hyperparameters, allowing for extensive experimentation on smaller models and seamless transfer of optimal configurations to larger models.
To maximize training efficiency and stability, Xmodel-2 employs the WSD learning rate scheduler from MiniCPM. Pretrained on 1.5 trillion tokens from diverse sources, Xmodel-2 achieves state-of-the-art performance in complex reasoning and agent-based tasks, while maintaining low training costs.
These results highlight the potential of efficient model design and training strategies in advancing reasoning capabilities.
1.3. CodeElo: Benchmarking Competition-level Code Generation of LLMs with Human-comparable Elo Ratings
With the increasing code reasoning capabilities of existing large language models (LLMs) and breakthroughs in reasoning models like OpenAI o1 and o3, there is a growing need to develop more challenging and comprehensive benchmarks that effectively test their sophisticated competition-level coding abilities.
Existing benchmarks, like LiveCodeBench and USACO, fall short due to the unavailability of private test cases, lack of support for special judges, and misaligned execution environments.
To bridge this gap, we introduce CodeElo, a standardized competition-level code generation benchmark that effectively addresses all these challenges for the first time. CodeElo benchmark is mainly based on the official CodeForces platform and tries to align with the platform as much as possible.
We compile the recent six months of contest problems on CodeForces with detailed information such as contest divisions, problem difficulty ratings, and problem algorithm tags.
We introduce a unique judging method in which problems are submitted directly to the platform and develop a reliable Elo rating calculation system that aligns with the platform and is comparable with human participants but has lower variance.
By testing on our CodeElo, we provide the Elo ratings of 30 existing popular open-source and 3 proprietary LLMs for the first time. The results show that o1-mini and QwQ-32B-Preview stand out significantly, achieving Elo ratings of 1578 and 1261, respectively, while other models struggle even with the easiest problems, placing in the lowest 20 percent among all human participants.
Detailed analysis experiments are also conducted to provide insights into performance across algorithms and comparisons between using C++ and Python, which can suggest directions for future studies.
1.4. ProgCo: Program Helps Self-Correction of Large Language Models

Self-correction aims to enable large language models (LLMs) to self-verify and self-refine their initial responses without external feedback. However, LLMs often fail to effectively self-verify and generate correct feedback, further misleading refinement and leading to the failure of self-correction, especially in complex reasoning tasks.
In this paper, we propose Program-driven Self-Correction (ProgCo). First, program-driven verification (ProgVe) achieves complex verification logic and extensive validation through self-generated, self-executing verification pseudo-programs.
Then, program-driven refinement (ProgRe) receives feedback from ProgVe, and conducts dual reflection and refinement on both responses and verification programs to mitigate misleading or incorrect feedback in complex reasoning tasks.
Experiments on three instruction-following and mathematical benchmarks indicate that ProgCo achieves effective self-correction, and can further enhance performance when combined with real program tools.
2. LLM Training
2.1. Safeguard Fine-Tuned LLMs Through Pre- and Post-Tuning Model Merging
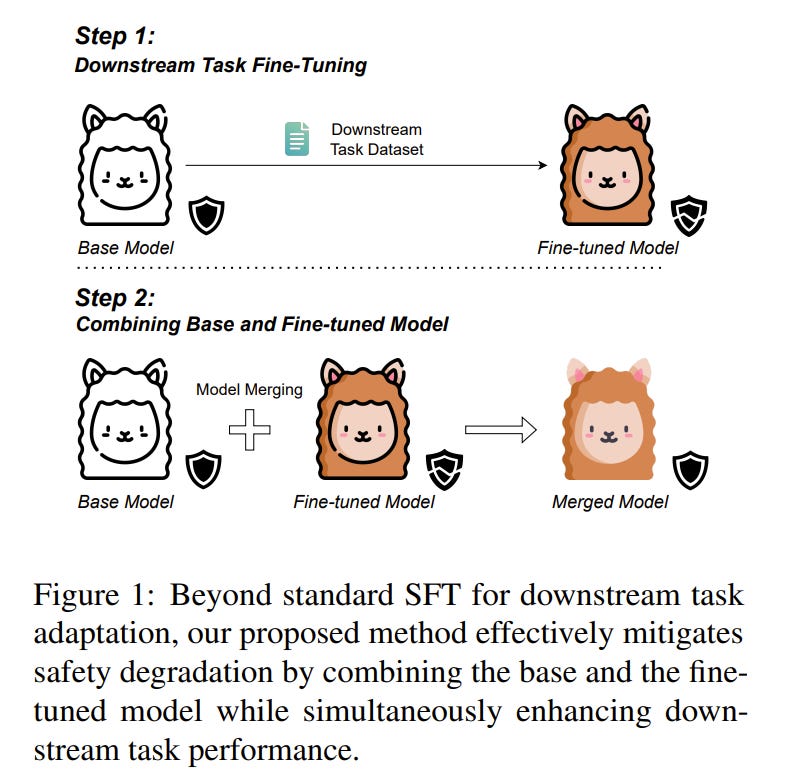
Fine-tuning large language models (LLMs) for downstream tasks is a widely adopted approach, but it often leads to safety degradation in safety-aligned LLMs. Currently, many solutions address this issue by incorporating additional safety data, which can be impractical in many cases.
In this paper, we address the question: How can we improve downstream task performance while preserving safety in LLMs without relying on additional safety data?
We propose a simple and effective method that maintains the inherent safety of LLMs while enhancing their downstream task performance: merging the weights of pre- and post-fine-tuned safety-aligned models.
Experimental results across various downstream tasks, models, and merging methods demonstrate that this approach effectively mitigates safety degradation while improving downstream task performance, offering a practical solution for adapting safety-aligned LLMs.
3. LLM Agents
3.1. Training Software Engineering Agents and Verifiers with SWE-Gym
We present SWE-Gym, the first environment for training real-world software engineering (SWE) agents. SWE-Gym contains 2,438 real-world Python task instances, each comprising a codebase with an executable runtime environment, unit tests, and a task specified in natural language.
We use SWE-Gym to train language model-based SWE agents, achieving up to 19% absolute gains in resolve rate on the popular SWE-Bench Verified and Lite test sets. We also experiment with inference-time scaling through verifiers trained on agent trajectories sampled from SWE-Gym.
When combined with our fine-tuned SWE agents, we achieve 32.0% and 26.0% on SWE-Bench Verified and Lite, respectively, reflecting a new state-of-the-art for open-weight SWE agents. To facilitate further research, we publicly release SWE-Gym, models, and agent trajectories.
4. LLM Reasoning
4.1. HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs
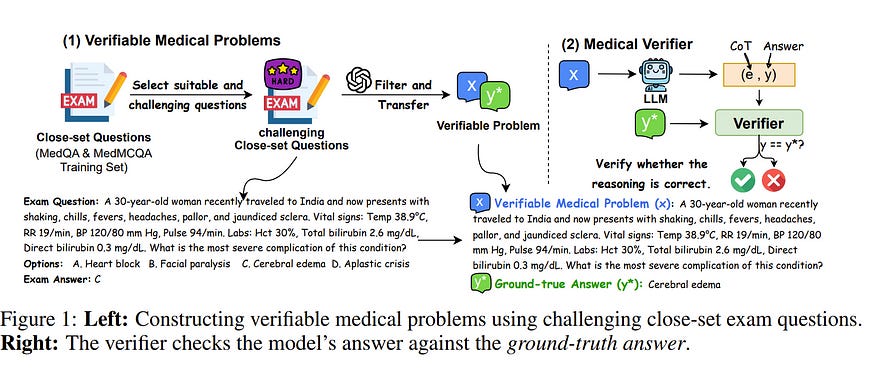
The breakthrough of OpenAI o1 highlights the potential of enhancing reasoning to improve LLM. Yet, most research in reasoning has focused on mathematical tasks, leaving domains like medicine underexplored.
The medical domain, though distinct from mathematics, also demands robust reasoning to provide reliable answers, given the high standards of healthcare. However, verifying medical reasoning is challenging, unlike those in mathematics.
To address this, we propose verifiable medical problems with a medical verifier to check the correctness of model outputs. This verifiable nature enables advancements in medical reasoning through a two-stage approach:
Using the verifier to guide the search for a complex reasoning trajectory for fine-tuning LLMs
Applying reinforcement learning (RL) with verifier-based rewards to enhance complex reasoning further. Finally, we introduce HuatuoGPT-o1, a medical LLM capable of complex reasoning, which outperforms general and medical-specific baselines using only 40K verifiable problems.
Experiments show complex reasoning improves medical problem-solving and benefits more from RL. We hope our approach inspires advancements in reasoning across medical and other specialized domains.
4.2. Efficiently Serving LLM Reasoning Programs with Certaindex
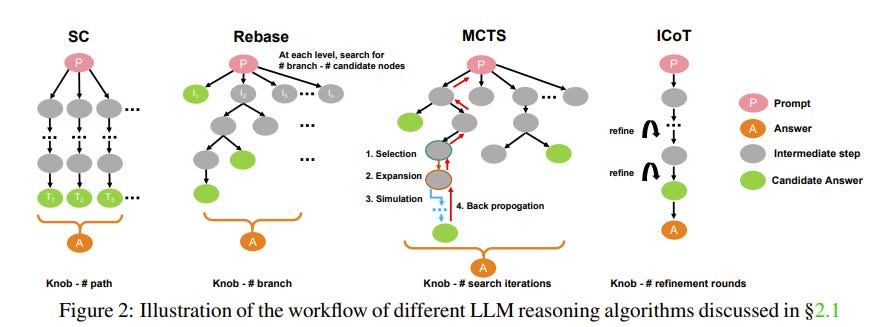
The rapid evolution of large language models (LLMs) has unlocked their capabilities in advanced reasoning tasks like mathematical problem-solving, code generation, and legal analysis.
Central to this progress are inference-time reasoning algorithms, which refine outputs by exploring multiple solution paths, at the cost of increasing compute demands and response latencies.
Existing serving systems fail to adapt to the scaling behaviors of these algorithms or the varying difficulty of queries, leading to inefficient resource use and unmet latency targets.
We present Dynasor, a system that optimizes inference-time computing for LLM reasoning queries. Unlike traditional engines, Dynasor tracks and schedules requests within reasoning queries and uses Certaindex, a proxy that measures statistical reasoning progress based on model certainty, to guide compute allocation dynamically.
Dynasor co-adapts scheduling with reasoning progress: it allocates more compute to hard queries, reduces compute for simpler ones, and terminates unpromising queries early, balancing accuracy, latency, and cost.
On diverse datasets and algorithms, Dynasor reduces computing by up to 50% in batch processing and sustains 3.3x higher query rates or 4.7x tighter latency SLOs in online serving.
4.3. MapEval: A Map-Based Evaluation of Geo-Spatial Reasoning in Foundation Models
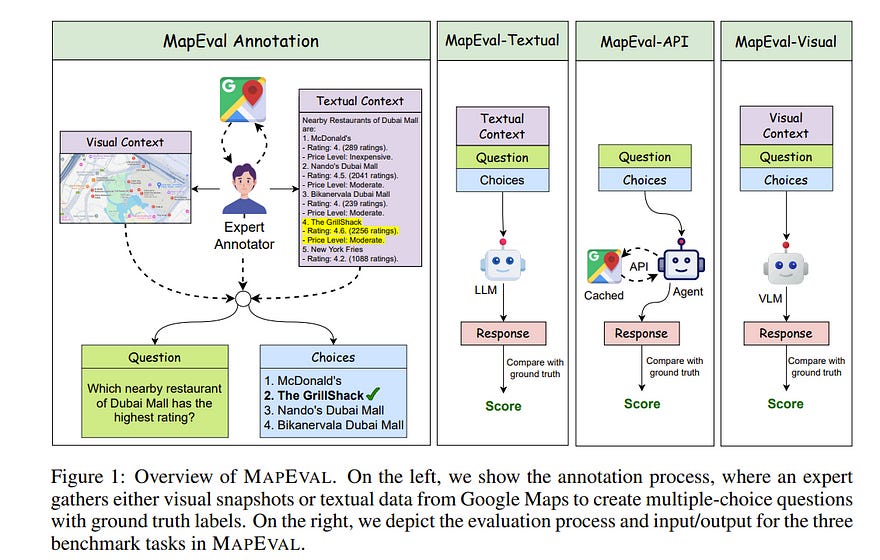
Recent advancements in foundation models have enhanced AI systems’ capabilities in autonomous tool usage and reasoning. However, their ability in location or map-based reasoning — which improves daily life by optimizing navigation, facilitating resource discovery, and streamlining logistics — has not been systematically studied.
To bridge this gap, we introduce MapEval, a benchmark designed to assess diverse and complex map-based user queries with geo-spatial reasoning.
MapEval features three task types (textual, API-based, and visual) that require collecting world information via map tools, processing heterogeneous geospatial contexts (e.g., named entities, travel distances, user reviews or ratings, images), and compositional reasoning, which all state-of-the-art foundation models find challenging.
Comprising 700 unique multiple-choice questions about locations across 180 cities and 54 countries, MapEval evaluates foundation models’ ability to handle spatial relationships, map infographics, travel planning, and navigation challenges.
Using MapEval, we conducted a comprehensive evaluation of 28 prominent foundation models. While no single model excelled across all tasks, Claude-3.5-Sonnet, GPT-4o, and Gemini-1.5-Pro achieved competitive performance overall.
However, substantial performance gaps emerged, particularly in MapEval, where agents with Claude-3.5-Sonnet outperformed GPT-4o and Gemini-1.5-Pro by 16% and 21%, respectively, and the gaps became even more amplified when compared to open-source LLMs.
Our detailed analyses provide insights into the strengths and weaknesses of current models, though all models still fall short of human performance by more than 20% on average, struggling with complex map images and rigorous geo-spatial reasoning.
This gap highlights MapEval’s critical role in advancing general-purpose foundation models with stronger geospatial understanding.
4.4. Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
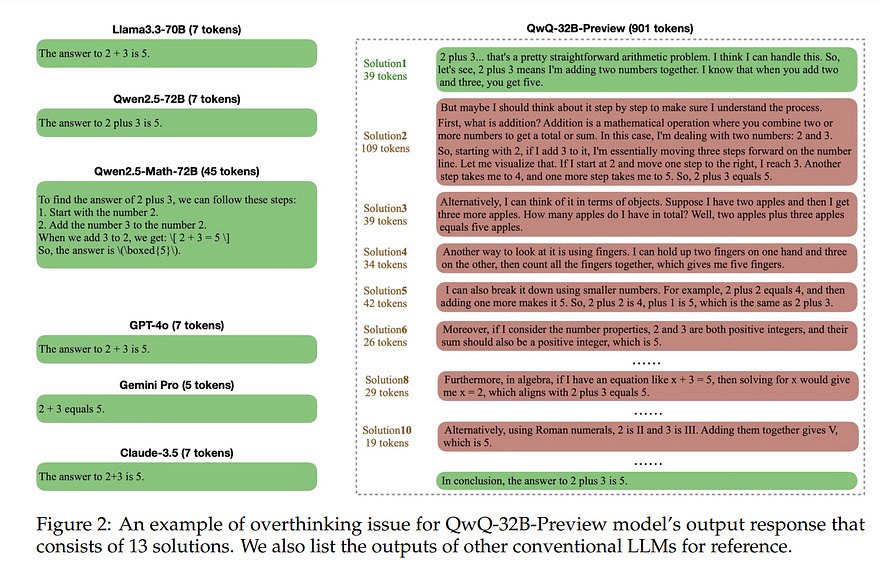
The remarkable performance of models like the OpenAI o1 can be attributed to their ability to emulate human-like long-time thinking during inference.
These models employ extended chain-of-thought (CoT) processes, exploring multiple strategies to enhance problem-solving capabilities. However, a critical question remains: How to intelligently and efficiently scale computational resources during testing?
This paper presents the first comprehensive study on the prevalent issue of overthinking in these models, where excessive computational resources are allocated for simple problems with minimal benefit.
We introduce novel efficiency metrics from both outcome and process perspectives to evaluate the rational use of computational resources by o1-like models.
Using a self-training paradigm, we propose strategies to mitigate overthinking and streamline reasoning processes without compromising accuracy.
Experimental results show that our approach successfully reduces computational overhead while preserving model performance across a range of test sets with varying difficulty levels, such as GSM8K, MATH500, GPQA, and AIME.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
