


Important LLMs Papers for the Week from 24/02 to 01/03
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Last Week of February 2025. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Technical Reports
LLM Reasoning
LLM Training & Fine Tuning
LLM Preference Optimization & Alignment
LLM Scaling & Optimization
AI Agents
Attention Models
LLM Evaluation & Benchmarking
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. LLM Progress & Technical Reports
1.1. Thus Spake Long-Context Large Language Model
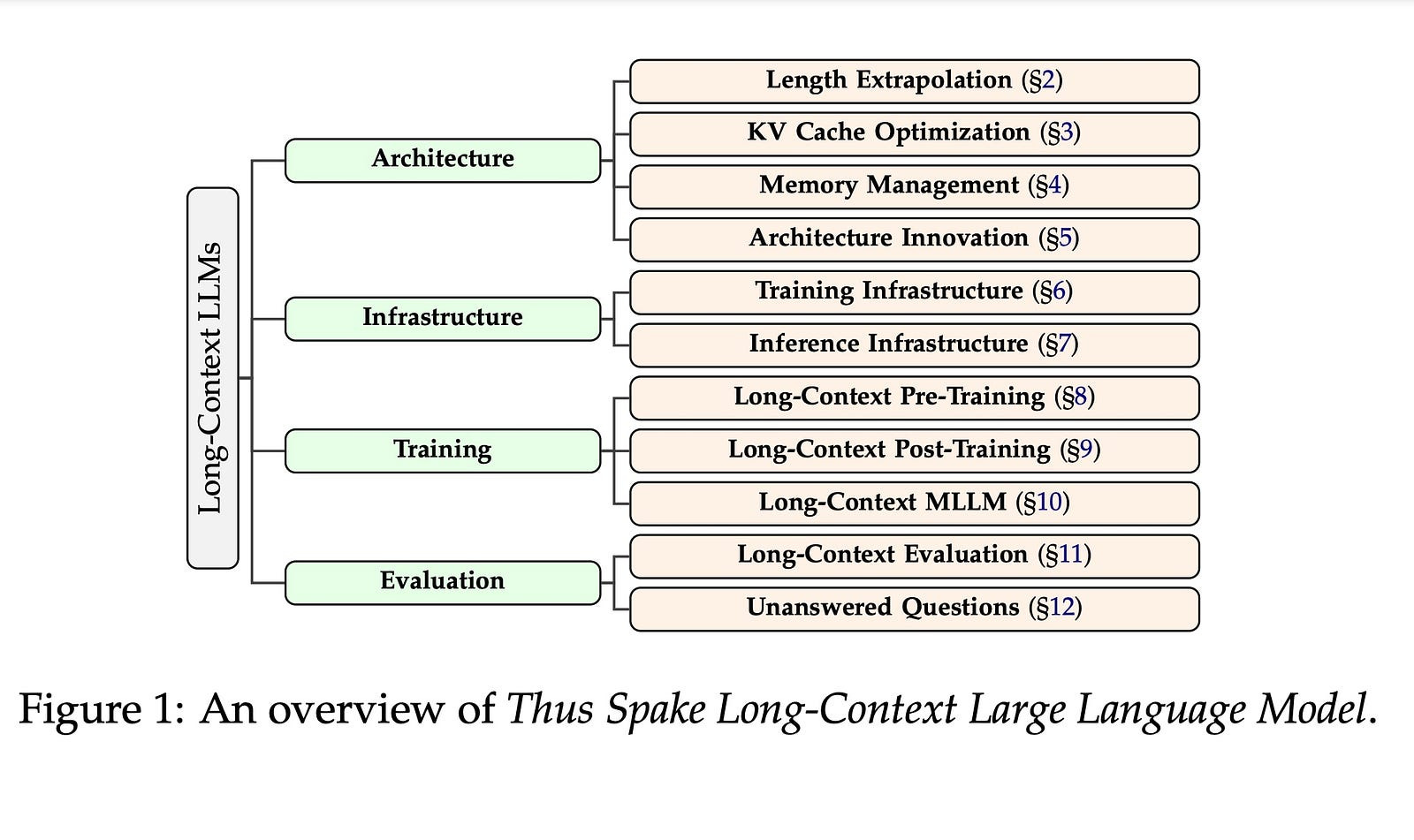
Long context is an important topic in Natural Language Processing (NLP), running through the development of NLP architectures, and offers immense opportunities for Large Language Models (LLMs) giving LLMs the lifelong learning potential akin to humans.
Unfortunately, the pursuit of a long context is accompanied by numerous obstacles. Nevertheless, long context remains a core competitive advantage for LLMs.
In the past two years, the context length of LLMs has achieved a breakthrough extension to millions of tokens. Moreover, the research on long-context LLMs has expanded from length extrapolation to a comprehensive focus on architecture, infrastructure, training, and evaluation technologies. Inspired by the symphonic poem, Thus Spake Zarathustra, we draw an analogy between the journey of extending the context of LLM and the attempts of humans to transcend its mortality.
In this survey, we will illustrate how LLM struggles between the tremendous need for a longer context and its equal need to accept the fact that it is ultimately finite. To achieve this, we give a global picture of the lifecycle of long-context LLMs from four perspectives: architecture, infrastructure, training, and evaluation, showcasing the full spectrum of long-context technologies.
At the end of this survey, we will present 10 unanswered questions currently faced by long-context LLMs. We hope this survey can serve as a systematic introduction to the research on long-context LLMs.
2. LLM Reasoning
2.1. LightThinker: Thinking Step-by-Step Compression

Large language models (LLMs) have shown remarkable performance in complex reasoning tasks, but their efficiency is hindered by the substantial memory and computational costs associated with generating lengthy tokens.
In this paper, we propose LightThinker, a novel method that enables LLMs to dynamically compress intermediate thoughts during reasoning. Inspired by human cognitive processes, LightThinker compresses verbose thought steps into compact representations and discards the original reasoning chains, thereby significantly reducing the number of tokens stored in the context window.
This is achieved by training the model on when and how to perform compression through data construction, mapping hidden states to condensed gist tokens, and creating specialized attention masks.
Additionally, we introduce the Dependency (Dep) metric to quantify the degree of compression by measuring the reliance on historical tokens during generation.
Extensive experiments on four datasets and two models show that LightThinker reduces peak memory usage and inference time, while maintaining competitive accuracy.
Our work provides a new direction for improving the efficiency of LLMs in complex reasoning tasks without sacrificing performance.
2.2. Self-rewarding correction for mathematical reasoning

We study self-rewarding reasoning large language models (LLMs), which can simultaneously generate step-by-step reasoning and evaluate the correctness of their outputs during the inference time, without external feedback.
This integrated approach allows a single model to independently guide its reasoning process, offering computational advantages for model deployment.
We particularly focus on the representative task of self-correction, where models autonomously detect errors in their responses, revise outputs, and decide when to terminate iterative refinement loops.
To enable this, we propose a two-staged algorithmic framework for constructing self-rewarding reasoning models using only self-generated data. In the first stage, we employ sequential rejection sampling to synthesize long chain-of-thought trajectories that incorporate both self-rewarding and self-correction mechanisms.
Fine-tuning models on these curated data allows them to learn the patterns of self-rewarding and self-correction. In the second stage, we further enhance the models’ ability to assess response accuracy and refine outputs through reinforcement learning with rule-based signals.
Experiments with Llama-3 and Qwen-2.5 demonstrate that our approach surpasses intrinsic self-correction capabilities and achieves performance comparable to systems that rely on external reward models.
2.3. Can Large Language Models Detect Errors in Long Chain-of-Thought Reasoning?

Recently, o1-like models have drawn significant attention, where these models produce the long Chain-of-Thought (CoT) reasoning steps to improve the reasoning abilities of existing Large Language Models (LLMs).
In this paper, to understand the qualities of these long CoTs and measure the critique abilities of existing LLMs on these long CoTs, we introduce the DeltaBench, including the generated long CoTs from different o1-like models (e.g., QwQ, DeepSeek-R1) for different reasoning tasks (e.g., Math, Code, General Reasoning), to measure the ability to detect errors in long CoT reasoning.
Based on DeltaBench, we first perform fine-grained analysis of the generated long CoTs to discover the effectiveness and efficiency of different o1-like models.
Then, we conduct extensive evaluations of existing process reward models (PRMs) and critic models to detect the errors of each annotated process, which aims to investigate the boundaries and limitations of existing PRMs and critic models. Finally, we hope that DeltaBench could guide developers to better understand their models' long CoT reasoning abilities.
2.4. SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution
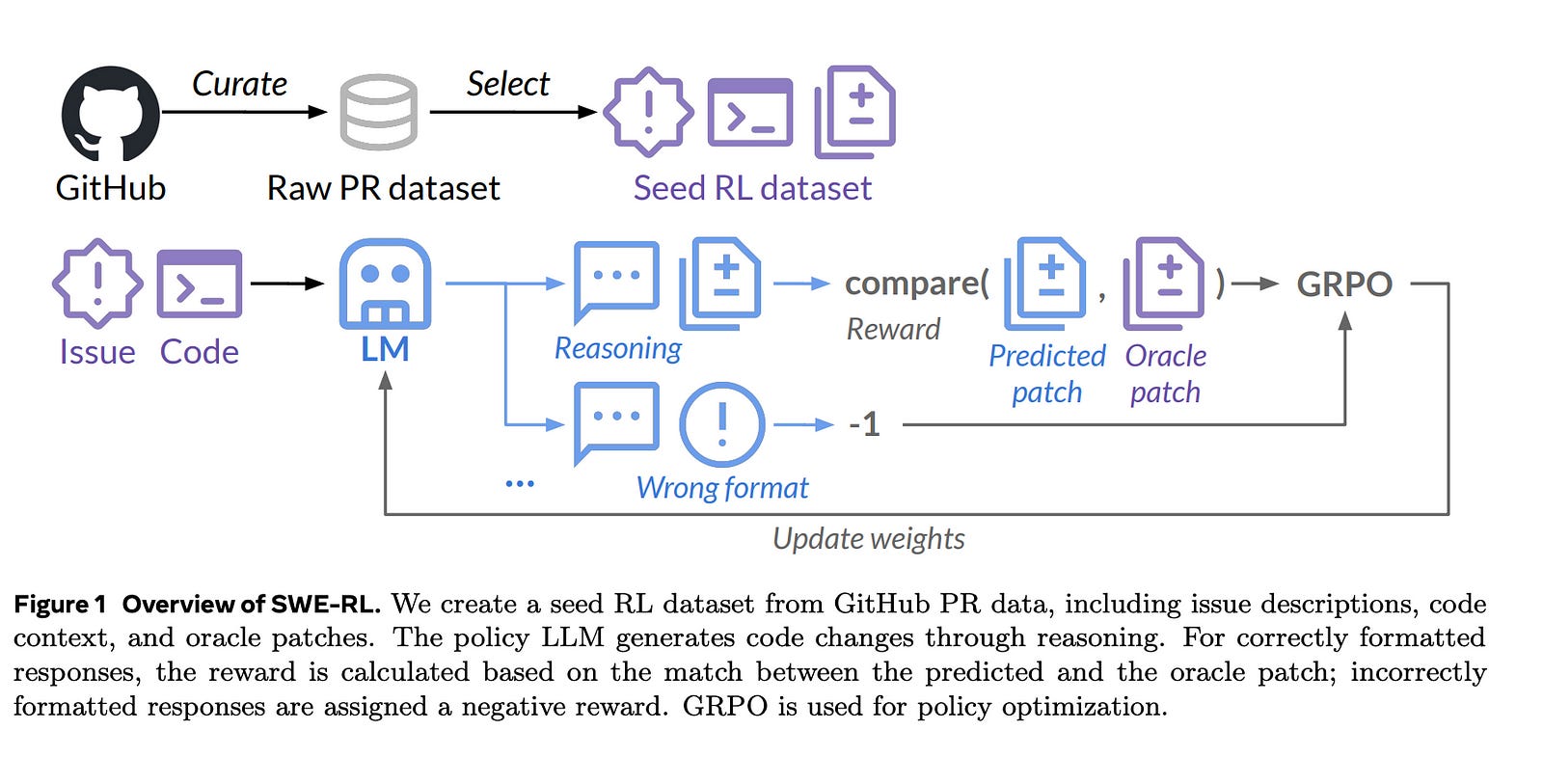
The recent DeepSeek-R1 release has demonstrated the immense potential of reinforcement learning (RL) in enhancing the general reasoning capabilities of large language models (LLMs).
While DeepSeek-R1 and other follow-up work primarily focus on applying RL to competitive coding and math problems, this paper introduces SWE-RL, the first approach to scale RL-based LLM reasoning for real-world software engineering.
Leveraging a lightweight rule-based reward (e.g., the similarity score between ground-truth and LLM-generated solutions), SWE-RL enables LLMs to autonomously recover a developer’s reasoning processes and solutions by learning from extensive open-source software evolution data — the record of a software’s entire lifecycle, including its code snapshots, code changes, and events such as issues and pull requests.
Trained on top of Llama 3, our resulting reasoning model, Llama3-SWE-RL-70B, achieves a 41.0% solve rate on SWE-bench Verified — a human-verified collection of real-world GitHub issues.
To our knowledge, this is the best performance reported for medium-sized (<100B) LLMs to date, even comparable to leading proprietary LLMs like GPT-4o. Surprisingly, despite performing RL solely on software evolution data, Llama3-SWE-RL has even emerged with generalized reasoning skills.
For example, it shows improved results on five out-of-domain tasks, namely, function coding, library use, code reasoning, mathematics, and general language understanding, whereas a supervised-finetuning baseline even leads to performance degradation on average.
Overall, SWE-RL opens up a new direction to improve the reasoning capabilities of LLMs through reinforcement learning on massive software engineering data.
3. LLM Training & Fine Tuning
3.1. Slamming: Training a Speech Language Model on One GPU in a Day

We introduce Slam, a recipe for training high-quality Speech Language Models (SLMs) on a single academic GPU in 24 hours. We do so through empirical analysis of model initialisation and architecture, synthetic training data, preference optimisation with synthetic data and tweaking all other components.
We empirically demonstrate that this training recipe also scales well with more compute, getting results on par with leading SLMs in a fraction of the compute cost.
We hope these insights will make SLM training and research more accessible. In the context of SLM scaling laws, our results far outperform predicted compute optimal performance, giving an optimistic view to SLM feasibility.
4. LLM Preference Optimization & Alignment
4.1. MedHallu: A Comprehensive Benchmark for Detecting Medical Hallucinations in Large Language Models

Advancements in Large Language Models (LLMs) and their increasing use in medical question-answering necessitate rigorous evaluation of their reliability.
A critical challenge lies in hallucination, where models generate plausible yet factually incorrect outputs. In the medical domain, this poses serious risks to patient safety and clinical decision-making. To address this, we introduce MedHallu, the first benchmark specifically designed for medical hallucination detection.
MedHallu comprises 10,000 high-quality question-answer pairs derived from PubMedQA, with hallucinated answers systematically generated through a controlled pipeline.
Our experiments show that state-of-the-art LLMs, including GPT-4o, Llama-3.1, and the medically fine-tuned UltraMedical, struggle with this binary hallucination detection task, with the best model achieving an F1 score as low as 0.625 for detecting “hard” category hallucinations.
Using bidirectional entailment clustering, we show that harder-to-detect hallucinations are semantically closer to ground truth. Through experiments, we also show incorporating domain-specific knowledge and introducing a “not sure” category as one of the answer categories improves the precision and F1 scores by up to 38% relative to baselines.
4.2. OmniAlign-V: Towards Enhanced Alignment of MLLMs with Human Preference

Recent advancements in open-source multi-modal large language models (MLLMs) have primarily focused on enhancing foundational capabilities, leaving a significant gap in human preference alignment.
This paper introduces OmniAlign-V, a comprehensive dataset of 200K high-quality training samples featuring diverse images, complex questions, and varied response formats to improve MLLMs’ alignment with human preferences.
We also present MM-AlignBench, a human-annotated benchmark specifically designed to evaluate MLLMs’ alignment with human values. Experimental results show that finetuning MLLMs with OmniAlign-V, using Supervised Fine-Tuning (SFT) or Direct Preference Optimization (DPO), significantly enhances human preference alignment while maintaining or enhancing performance on standard VQA benchmarks, preserving their fundamental capabilities.
5. LLM Scaling & Optimization
5.1. Make LoRA Great Again: Boosting LoRA with Adaptive Singular Values and Mixture-of-Experts Optimization Alignment

While Low-Rank Adaptation (LoRA) enables parameter-efficient fine-tuning for Large Language Models (LLMs), its performance often falls short of Full Fine-Tuning (Full FT).
Current methods optimize LoRA by initializing with static singular value decomposition (SVD) subsets, leading to suboptimal leveraging of pre-trained knowledge. Another path for improving LoRA is incorporating a Mixture-of-Experts (MoE) architecture.
However, weight misalignment and complex gradient dynamics make it challenging to adopt SVD prior to the LoRA MoE architecture. To mitigate these issues, we propose Great LoRA Mixture-of-Expert (GOAT), a framework that (1) adaptively integrates relevant priors using an SVD-structured MoE, and (2) aligns optimization with full fine-tuned MoE by deriving a theoretical scaling factor.
We demonstrate that proper scaling, without modifying the architecture or training algorithms, boosts LoRA MoE’s efficiency and performance. Experiments across 25 datasets, including natural language understanding, commonsense reasoning, image classification, and natural language generation, demonstrate GOAT’s state-of-the-art performance, closing the gap with Full FT.
5.2. SpargeAttn: Accurate Sparse Attention Accelerating Any Model Inference
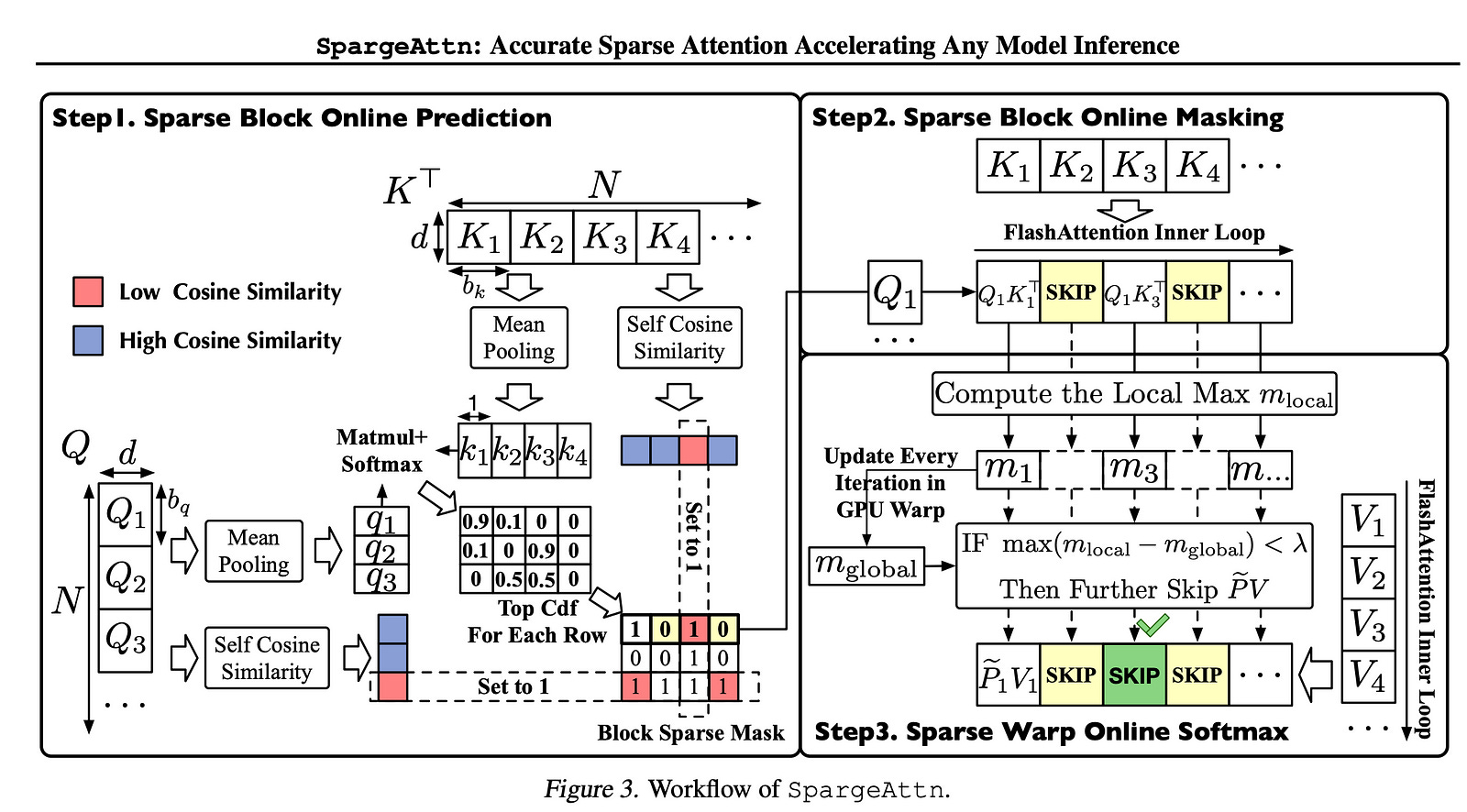
An efficient attention implementation is essential for large models due to its quadratic time complexity. Fortunately, attention commonly exhibits sparsity, i.e., many values in the attention map are near zero, allowing for the omission of corresponding computations.
Many studies have utilized the sparse pattern to accelerate attention. However, most existing works focus on optimizing attention within specific models by exploiting certain sparse patterns of the attention map. A universal sparse attention that guarantees both the speedup and end-to-end performance of diverse models remains elusive.
In this paper, we propose SpargeAttn, a universal sparse and quantized attention for any model. Our method uses a two-stage online filter: in the first stage, we rapidly and accurately predict the attention map, enabling the skip of some matrix multiplications in attention.
In the second stage, we design an online softmax-aware filter that incurs no extra overhead and further skips some matrix multiplications. Experiments show that our method significantly accelerates diverse models, including language, image, and video generation, without sacrificing end-to-end metrics.
6. AI Agents
6.1. TheoremExplainAgent: Towards Multimodal Explanations for LLM Theorem Understanding

Understanding domain-specific theorems often requires more than just text-based reasoning; effective communication through structured visual explanations is crucial for deeper comprehension.
While large language models (LLMs) demonstrate strong performance in text-based theorem reasoning, their ability to generate coherent and pedagogically meaningful visual explanations remains an open challenge.
In this work, we introduce TheoremExplainAgent, an agentic approach for generating long-form theorem explanation videos (over 5 minutes) using Manim animations.
To systematically evaluate multimodal theorem explanations, we propose TheoremExplainBench, a benchmark covering 240 theorems across multiple STEM disciplines, along with 5 automated evaluation metrics.
Our results reveal that agentic planning is essential for generating detailed long-form videos, and the o3-mini agent achieves a success rate of 93.8% and an overall score of 0.77.
However, our quantitative and qualitative studies show that most of the videos produced exhibit minor issues with visual element layout. Furthermore, multimodal explanations expose deeper reasoning flaws that text-based explanations fail to reveal, highlighting the importance of multimodal explanations.
7. Attention Models
7.1. LLM-Microscope: Uncovering the Hidden Role of Punctuation in Context Memory of Transformers

We introduce methods to quantify how Large Language Models (LLMs) encode and store contextual information, revealing that tokens often seen as minor (e.g., determiners, punctuation) carry surprisingly high context.
Notably, removing these tokens — especially stopwords, articles, and commas — consistently degrades performance on MMLU and BABILong-4k, even if removing only irrelevant tokens.
Our analysis also shows a strong correlation between contextualization and linearity, where linearity measures how closely the transformation from one layer’s embeddings to the next can be approximated by a single linear mapping.
These findings underscore the hidden importance of filler tokens in maintaining context. For further exploration, we present LLM-Microscope, an open-source toolkit that assesses token-level nonlinearity, evaluates contextual memory, visualizes intermediate layer contributions (via an adapted Logit Lens), and measures the intrinsic dimensionality of representations. This toolkit illuminates how seemingly trivial tokens can be critical for long-range understanding.
7.2. MoBA: Mixture of Block Attention for Long-Context LLMs

Scaling the effective context length is essential for advancing large language models (LLMs) toward artificial general intelligence (AGI). However, the quadratic increase in computational complexity inherent in traditional attention mechanisms presents a prohibitive overhead.
Existing approaches either impose strongly biased structures, such as sink or window attention which are task-specific, or radically modify the attention mechanism into linear approximations, whose performance in complex reasoning tasks remains inadequately explored.
In this work, we propose a solution that adheres to the ``less structure’’ principle, allowing the model to determine where to attend autonomously, rather than introducing predefined biases.
We introduce Mixture of Block Attention (MoBA), an innovative approach that applies the principles of Mixture of Experts (MoE) to the attention mechanism.
This novel architecture demonstrates superior performance on long-context tasks while offering a key advantage: the ability to seamlessly transition between full and sparse attention, enhancing efficiency without the risk of compromising performance.
MoBA has already been deployed to support Kimi’s long-context requests and demonstrates significant advancements in efficient attention computation for LLMs.
8. LLM Evaluation & Benchmarking
8.1. Prompt-to-Leaderboard
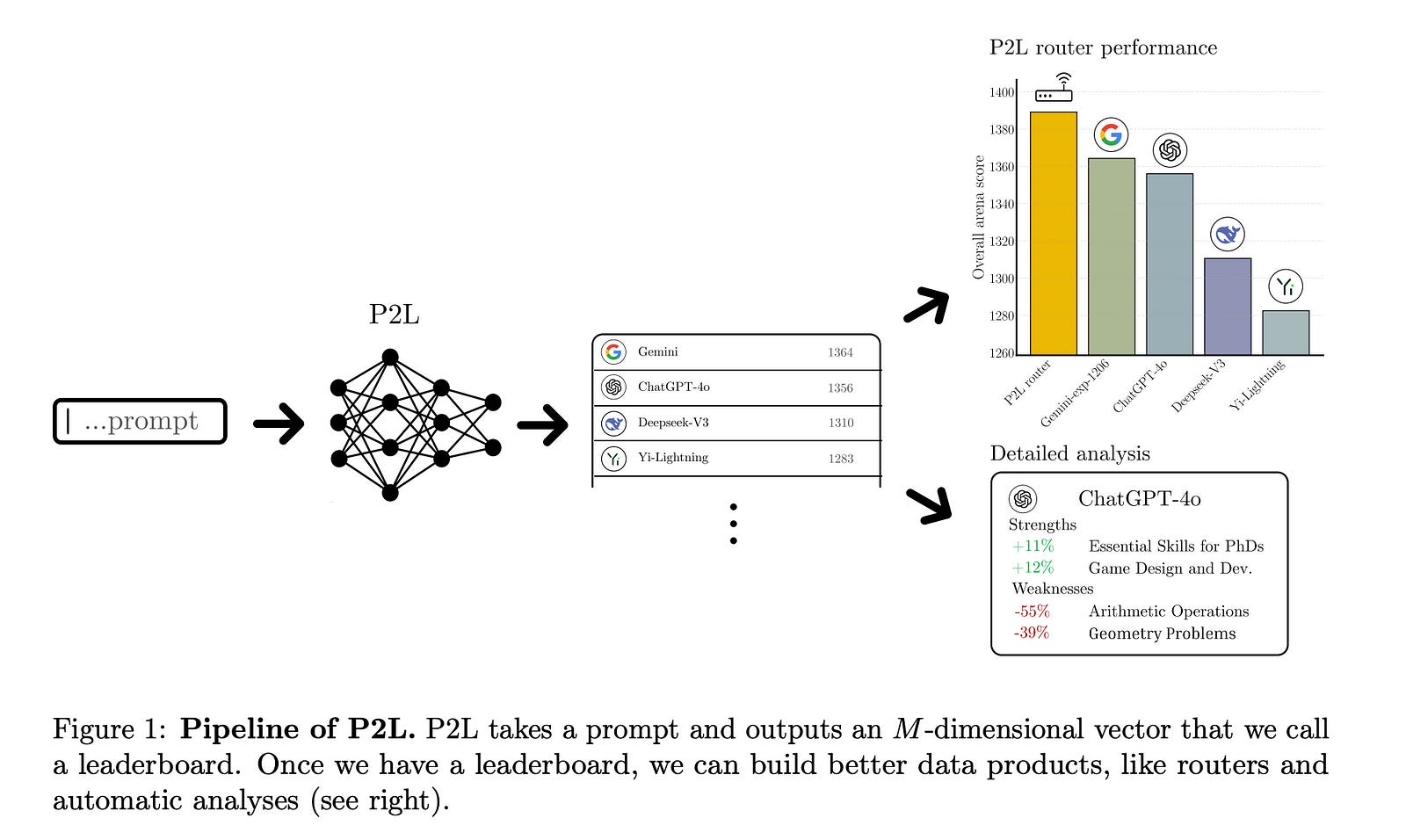
Large language model (LLM) evaluations typically rely on aggregated metrics like accuracy or human preference, averaging across users and prompts. This averaging obscures user- and prompt-specific variations in model performance.
To address this, we propose Prompt-to-Leaderboard (P2L), a method that produces leaderboards specific to a prompt. The core idea is to train an LLM taking natural language prompts as input to output a vector of Bradley-Terry coefficients which are then used to predict the human preference vote.
The resulting prompt-dependent leaderboards allow for unsupervised task-specific evaluation, optimal routing of queries to models, personalization, and automated evaluation of model strengths and weaknesses.
Data from Chatbot Arena suggest that P2L better captures the nuanced landscape of language model performance than the averaged leaderboard. Furthermore, our findings suggest that P2L’s ability to produce prompt-specific evaluations follows a power law scaling similar to that observed in LLMs themselves.
In January 2025, the router we trained based on this methodology achieved the \#1 spot in the Chatbot Arena leaderboard.
8.2. CodeCriticBench: A Holistic Code Critique Benchmark for Large Language Models
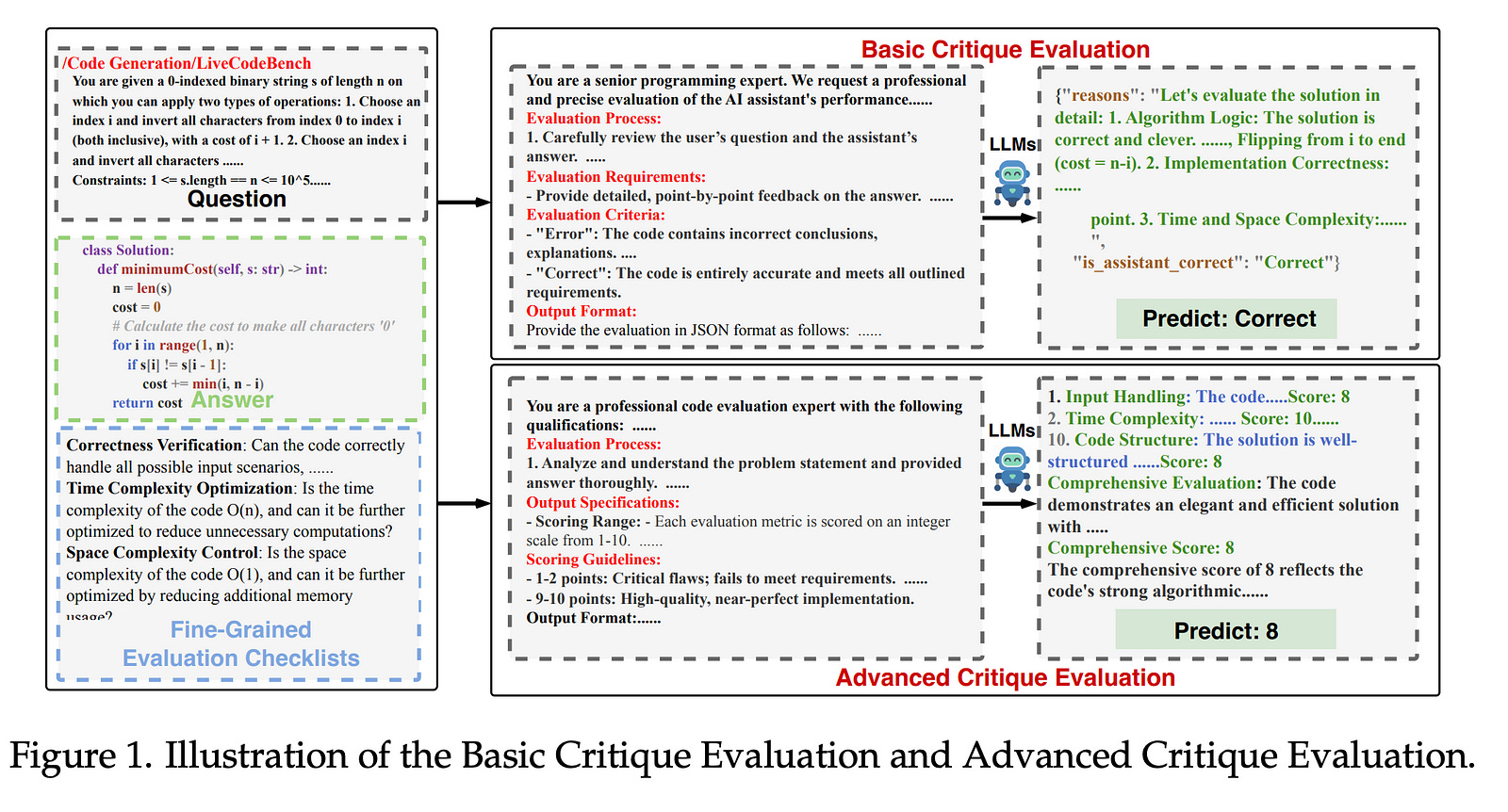
The critique capacity of Large Language Models (LLMs) is essential for reasoning abilities, which can provide necessary suggestions (e.g., detailed analysis and constructive feedback). Therefore, how to evaluate the critique capacity of LLMs has drawn great attention and several critique benchmarks have been proposed.
However, existing critique benchmarks usually have the following limitations: (1). Focusing on diverse reasoning tasks in general domains and insufficient evaluation on code tasks (e.g., only covering code generation task), where the difficulty of queries is relatively easy (e.g., the code queries of CriticBench are from Humaneval and MBPP). (2). Lacking comprehensive evaluation from different dimensions. To address these limitations, we introduce a holistic code critique benchmark for LLMs called CodeCriticBench.
Specifically, our CodeCriticBench includes two mainstream code tasks (i.e., code generation and code QA) with different difficulties. Besides, the evaluation protocols include basic critique evaluation and advanced critique evaluation for different characteristics, where fine-grained evaluation checklists are well-designed for advanced settings. Finally, we conduct extensive experimental results of existing LLMs, which show the effectiveness of CodeCriticBench.
8.3. Multimodal Inconsistency Reasoning (MMIR): A New Benchmark for Multimodal Reasoning Models

Existing Multimodal Large Language Models (MLLMs) are predominantly trained and tested on consistent visual-textual inputs, leaving open the question of whether they can handle inconsistencies in real-world, layout-rich content.
To bridge this gap, we propose the Multimodal Inconsistency Reasoning (MMIR) benchmark to assess MLLMs’ ability to detect and reason about semantic mismatches in artifacts such as webpages, presentation slides, and posters. MMIR comprises 534 challenging samples, each containing synthetically injected errors across five reasoning-heavy categories: Factual Contradiction, Identity Misattribution, Contextual Mismatch, Quantitative Discrepancy, and Temporal/Spatial Incoherence.
We evaluate six state-of-the-art MLLMs, showing that models with dedicated multimodal reasoning capabilities, such as o1, substantially outperform their counterparts while open-source models remain particularly vulnerable to inconsistency errors.
Detailed error analyses further show that models excel in detecting inconsistencies confined to a single modality, particularly in text, but struggle with cross-modal conflicts and complex layouts.
Probing experiments reveal that single-modality prompting, including Chain-of-Thought (CoT) and Set-of-Mark (SoM) methods, yields marginal gains, revealing a key bottleneck in cross-modal reasoning. Our findings highlight the need for advanced multimodal reasoning and point to future research on multimodal inconsistency.
8.4. CODESYNC: Synchronizing Large Language Models with Dynamic Code Evolution at Scale

Large Language Models (LLMs) have exhibited exceptional performance in software engineering yet face challenges in adapting to continually evolving code knowledge, particularly regarding the frequent updates of third-party library APIs.
This limitation, stemming from static pre-training datasets, often results in non-executable code or implementations with suboptimal safety and efficiency. To this end, this paper introduces CODESYNC, a data engine for identifying outdated code patterns and collecting real-time code knowledge updates from Python third-party libraries.
Building upon CODESYNC, we develop CODESYNCBENCH, a comprehensive benchmark for assessing LLMs’ ability to stay synchronized with code evolution, which covers real-world updates for 220 APIs from six Python libraries.
Our benchmark offers 3,300 test cases across three evaluation tasks and an update-aware instruction tuning dataset consisting of 2,200 training samples. Extensive experiments on 14 state-of-the-art LLMs reveal that they struggle with dynamic code evolution, even with the support of advanced knowledge updating methods (e.g., DPO, ORPO, and SimPO).
We believe that our benchmark can offer a strong foundation for the development of more effective methods for real-time code knowledge updating in the future.
Are you looking to start a career in data science and AI, and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
