


Important LLMs Papers for the Week from 14/10 to 20/10
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Third Week of October 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Training, Evaluation & Inference
LLM Reasoning
Attention Based Models
Retrieval Augmented Generation (RAG)
LLM Agents
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. LLM Progress & Benchmarking
1.1. Baichuan-Omni Technical Report

The salient multimodal capabilities and interactive experience of GPT-4o highlight its critical role in practical applications, yet it lacks a high-performing open-source counterpart.
In this paper, we introduce Baichuan-Omni, the first open-source 7B Multimodal Large Language Model (MLLM) adept at concurrently processing and analyzing modalities of image, video, audio, and text, while delivering an advanced multimodal interactive experience and strong performance.
We propose an effective multimodal training schema starting with 7B model and proceeding through two stages of multimodal alignment and multitask fine-tuning across audio, image, video, and text modal. This approach equips the language model with the ability to handle visual and audio data effectively.
Demonstrating strong performance across various omni-modal and multimodal benchmarks, we aim for this contribution to serve as a competitive baseline for the open-source community in advancing multimodal understanding and real-time interaction.
1.2. LiveXiv — A Multi-Modal Live Benchmark Based on Arxiv Papers Content
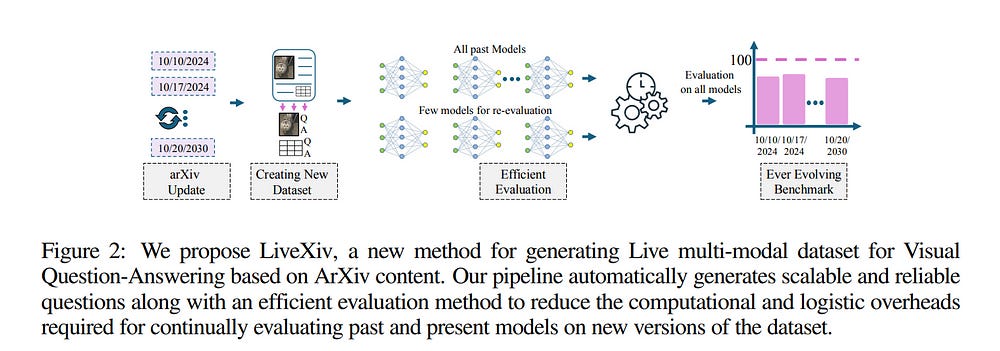
The large-scale training of multi-modal models on data scraped from the web has shown outstanding utility in infusing these models with the required world knowledge to perform effectively on multiple downstream tasks.
However, one downside of scraping data from the web can be the potential sacrifice of the benchmarks on which the abilities of these models are often evaluated. To safeguard against test data contamination and to truly test the abilities of these foundation models we propose LiveXiv: A scalable evolving live benchmark based on scientific ArXiv papers.
LiveXiv accesses domain-specific manuscripts at any given timestamp and proposes to automatically generate visual question-answer pairs (VQA). This is done without any human-in-the-loop, using the multi-modal content in the manuscripts, like graphs, charts, and tables.
Moreover, we introduce an efficient evaluation approach that estimates the performance of all models on the evolving benchmark using evaluations of only a subset of models. This significantly reduces the overall evaluation cost.
We benchmark multiple open and proprietary Large Multi-modal Models (LMMs) on the first version of our benchmark, showing its challenging nature and exposing the models true abilities, avoiding contamination. Lastly, in our commitment to high quality, we have collected and evaluated a manually verified subset.
By comparing its overall results to our automatic annotations, we have found that the performance variance is indeed minimal (<2.5%). Our dataset is available online on HuggingFace, and our code will be available here.
1.3. Omni-MATH: A Universal Olympiad Level Mathematic Benchmark For Large Language Models

Recent advancements in large language models (LLMs) have led to significant breakthroughs in mathematical reasoning capabilities.
However, existing benchmarks like GSM8K or MATH are now being solved with high accuracy (e.g., OpenAI o1 achieves 94.8% on MATH dataset), indicating their inadequacy for truly challenging these models.
To bridge this gap, we propose a comprehensive and challenging benchmark specifically designed to assess LLMs’ mathematical reasoning at the Olympiad level. Unlike existing Olympiad-related benchmarks, our dataset focuses exclusively on mathematics and comprises a vast collection of 4428 competition-level problems with rigorous human annotation.
These problems are meticulously categorized into over 33 sub-domains and span more than 10 distinct difficulty levels, enabling a holistic assessment of model performance in Olympiad-mathematical reasoning. Furthermore, we conducted an in-depth analysis based on this benchmark.
Our experimental results show that even the most advanced models, OpenAI o1-mini and OpenAI o1-preview, struggle with highly challenging Olympiad-level problems, with 60.54% and 52.55% accuracy, highlighting significant challenges in Olympiad-level mathematical reasoning.
1.4. Your Mixture-of-Experts LLM Is Secretly an Embedding Model For Free

While large language models (LLMs) excel on generation tasks, their decoder-only architecture often limits their potential as embedding models if no further representation finetuning is applied.
Does this contradict their claim of generalists? To answer the question, we take a closer look at Mixture-of-Experts (MoE) LLMs. Our study shows that the expert routers in MoE LLMs can serve as an off-the-shelf embedding model with promising performance on a diverse class of embedding-focused tasks, without requiring any fine-tuning.
Moreover, our extensive analysis shows that the MoE routing weights (RW) is complementary to the hidden state (HS) of LLMs, a widely-used embedding. Compared to HS, we find that RW is more robust to the choice of prompts and focuses on high-level semantics.
Motivated by the analysis, we propose MoEE combining RW and HS, which achieves better performance than using either separately. Our exploration of their combination and prompting strategy shed several novel insights, e.g., a weighted sum of RW and HS similarities outperforms the similarity on their concatenation.
Our experiments are conducted on 6 embedding tasks with 20 datasets from the Massive Text Embedding Benchmark (MTEB). The results demonstrate the significant improvement brought by MoEE to LLM-based embedding without further finetuning.
2. LLM Training, Evaluation & Inference
2.1. Multi-Agent Collaborative Data Selection for Efficient LLM Pre-training

Efficient data selection is crucial to accelerate the pretraining of large language models (LLMs). While various methods have been proposed to enhance data efficiency, limited research has addressed the inherent conflicts between these approaches to achieve optimal data selection for LLM pre-taining.
To tackle this problem, we propose a novel multi-agent collaborative data selection mechanism. In this framework, each data selection method serves as an independent agent, and an agent console is designed to dynamically integrate the information from all agents throughout the LLM training process.
We conduct extensive empirical studies to evaluate our multi-agent framework. The experimental results demonstrate that our approach significantly improves data efficiency, accelerates convergence in LLM training, and achieves an average performance gain of 10.5% across multiple language model benchmarks compared to the state-of-the-art methods.
2.2. MEGA-Bench: Scaling Multimodal Evaluation to over 500 Real-World Tasks

We present MEGA-Bench, an evaluation suite that scales multimodal evaluation to over 500 real-world tasks, to address the highly heterogeneous daily use cases of end users.
Our objective is to optimize for a set of high-quality data samples that cover a highly diverse and rich set of multimodal tasks while enabling cost-effective and accurate model evaluation.
In particular, we collected 505 realistic tasks encompassing over 8,000 samples from 16 expert annotators to extensively cover the multimodal task space. Instead of unifying these problems into standard multi-choice questions (like MMMU, MMBench, and MMT-Bench), we embrace a wide range of output formats like numbers, phrases, code, \LaTeX, coordinates, JSON, free-form, etc.
To accommodate these formats, we developed over 40 metrics to evaluate these tasks. Unlike existing benchmarks, MEGA-Bench offers a fine-grained capability report across multiple dimensions (e.g., application, input type, output format, skill), allowing users to interact with and visualize model capabilities in depth. We evaluate a wide variety of frontier vision-language models on MEGA-Bench to understand their capabilities across these dimensions.
2.3. The Curse of Multi-Modalities: Evaluating Hallucinations of Large Multimodal Models across Language, Visual, and Audio
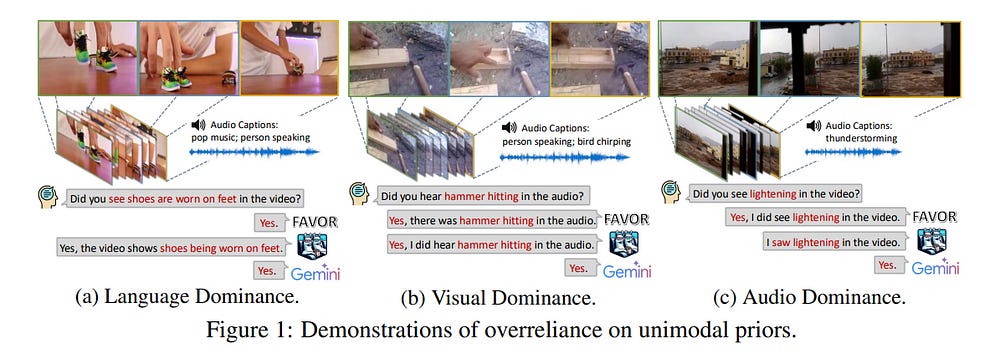
Recent advancements in large multimodal models (LMMs) have significantly enhanced performance across diverse tasks, with ongoing efforts to further integrate additional modalities such as video and audio.
However, most existing LMMs remain vulnerable to hallucinations, the discrepancy between the factual multimodal input and the generated textual output, which has limited their applicability in various real-world scenarios.
This paper presents the first systematic investigation of hallucinations in LMMs involving the three most common modalities: language, visual, and audio. Our study reveals two key contributors to hallucinations: overreliance on unimodal priors and spurious inter-modality correlations.
To address these challenges, we introduce the benchmark The Curse of Multi-Modalities (CMM), which comprehensively evaluates hallucinations in LMMs, providing a detailed analysis of their underlying issues.
Our findings highlight key vulnerabilities, including imbalances in modality integration and biases from training data, underscoring the need for balanced cross-modal learning and enhanced hallucination mitigation strategies. Based on our observations and findings, we suggest potential research directions that could enhance the reliability of LMMs.
3. LLM Reasoning
3.1. HumanEval-V: Evaluating Visual Understanding and Reasoning Abilities of Large Multimodal Models Through Coding Tasks

Coding tasks have been valuable for evaluating Large Language Models (LLMs), as they demand the comprehension of high-level instructions, complex reasoning, and the implementation of functional programs — core capabilities for advancing Artificial General Intelligence.
Despite the progress in Large Multimodal Models (LMMs), which extend LLMs with visual perception and understanding capabilities, there remains a notable lack of coding benchmarks that rigorously assess these models, particularly in tasks that emphasize visual reasoning.
To address this gap, we introduce HumanEval-V, a novel and lightweight benchmark specifically designed to evaluate LMMs’ visual understanding and reasoning capabilities through code generation. HumanEval-V includes 108 carefully crafted, entry-level Python coding tasks derived from platforms like CodeForces and Stack Overflow.
Each task is adapted by modifying the context and algorithmic patterns of the original problems, with visual elements redrawn to ensure distinction from the source, preventing potential data leakage.
LMMs are required to complete the code solution based on the provided visual context and a predefined Python function signature outlining the task requirements.
Every task is equipped with meticulously handcrafted test cases to ensure a thorough and reliable evaluation of model-generated solutions. We evaluate 19 state-of-the-art LMMs using HumanEval-V, uncovering significant challenges.
Proprietary models like GPT-4o achieve only 13% pass@1 and 36.4% pass@10, while open-weight models with 70B parameters score below 4% pass@1.
Ablation studies further reveal the limitations of current LMMs in vision reasoning and coding capabilities. These results underscore key areas for future research to enhance LMMs’ capabilities.
4. Attention Based Models
4.1. What Matters in Transformers? Not All Attention is Needed
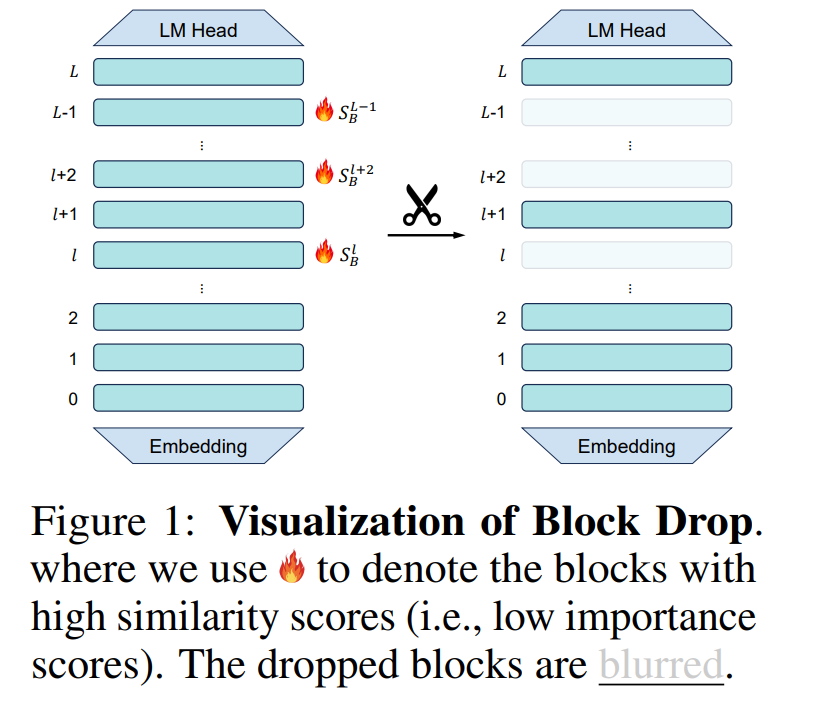
While scaling Transformer-based large language models (LLMs) has demonstrated promising performance across various tasks, it also introduces redundant architectures, posing efficiency challenges for real-world deployment.
Despite some recognition of redundancy in LLMs, the variability of redundancy across different architectures in transformers, such as MLP and Attention layers, is under-explored.
In this work, we investigate redundancy across different modules within Transformers, including Blocks, MLP, and Attention layers, using a similarity-based metric.
Surprisingly, despite the critical role of attention layers in distinguishing transformers from other architectures, we found that a large portion of these layers exhibit excessively high similarity and can be pruned without degrading performance. For instance, Llama-2–70B achieved a 48.4\% speedup with only a 2.4\% performance drop by pruning half of the attention layers.
Furthermore, by tracing model checkpoints throughout the training process, we observed that attention layer redundancy is inherent and consistent across training stages.
Additionally, we further propose a method that jointly drops Attention and MLP layers, allowing us to more aggressively drop additional layers. For instance, when dropping 31 layers (Attention + MLP), Llama-2–13B still retains 90\% of the performance on the MMLU task. Our work provides valuable insights for future network architecture design.
5. Retrieval Augmented Generation (RAG)
5.1. StructRAG: Boosting Knowledge Intensive Reasoning of LLMs via Inference-time Hybrid Information Structurization

Retrieval-augmented generation (RAG) is a key means to effectively enhance large language models (LLMs) in many knowledge-based tasks. However, existing RAG methods struggle with knowledge-intensive reasoning tasks, because useful information required for these tasks is badly scattered.
This characteristic makes it difficult for existing RAG methods to accurately identify key information and perform global reasoning with such noisy augmentation.
In this paper, motivated by the cognitive theories that humans convert raw information into various structured knowledge when tackling knowledge-intensive reasoning, we proposes a new framework, StructRAG, which can identify the optimal structure type for the task at hand, reconstruct original documents into this structured format, and infer answers based on the resulting structure.
Extensive experiments across various knowledge-intensive tasks show that StructRAG achieves state-of-the-art performance, particularly excelling in challenging scenarios, demonstrating its potential as an effective solution for enhancing LLMs in complex real-world applications.
5.2. Toward General Instruction-Following Alignment for Retrieval-Augmented Generation
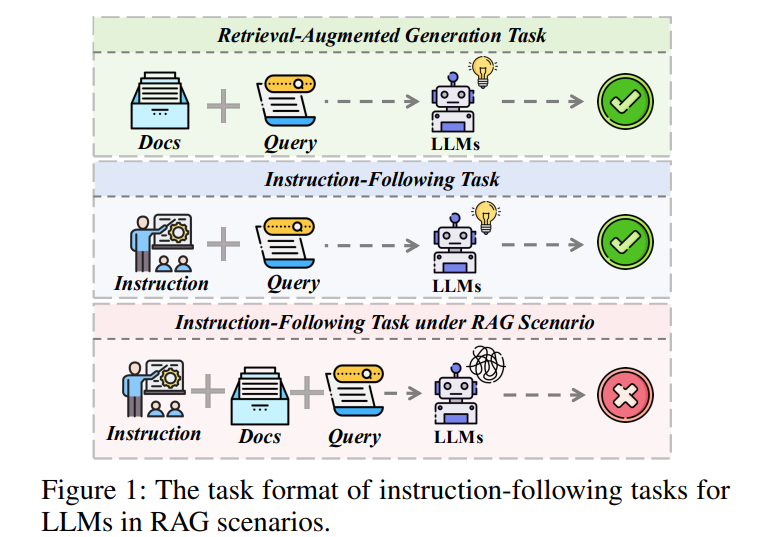
Following natural instructions is crucial for the effective application of Retrieval-Augmented Generation (RAG) systems. Despite recent advancements in Large Language Models (LLMs), research on assessing and improving instruction-following (IF) alignment within the RAG domain remains limited.
To address this issue, we propose VIF-RAG, the first automated, scalable, and verifiable synthetic pipeline for instruction-following alignment in RAG systems. We start by manually crafting a minimal set of atomic instructions (<100) and developing combination rules to synthesize and verify complex instructions for a seed set.
We then use supervised models for instruction rewriting while simultaneously generating code to automate the verification of instruction quality via a Python executor. Finally, we integrate these instructions with extensive RAG and general data samples, scaling up to a high-quality VIF-RAG-QA dataset (>100k) through automated processes.
To further bridge the gap in instruction-following auto-evaluation for RAG systems, we introduce FollowRAG Benchmark, which includes approximately 3K test samples, covering 22 categories of general instruction constraints and four knowledge-intensive QA datasets.
Due to its robust pipeline design, FollowRAG can seamlessly integrate with different RAG benchmarks. Using FollowRAG and eight widely-used IF and foundational abilities benchmarks for LLMs, we demonstrate that VIF-RAG markedly enhances LLM performance across a broad range of general instruction constraints while effectively leveraging its capabilities in RAG scenarios. Further analysis offers practical insights for achieving IF alignment in RAG systems.
5.3. VisRAG: Vision-based Retrieval-augmented Generation on Multi-modality Documents

Retrieval-augmented generation (RAG) is an effective technique that enables large language models (LLMs) to utilize external knowledge sources for generation.
However, current RAG systems are solely based on text, rendering it impossible to utilize vision information like layout and images that play crucial roles in real-world multi-modality documents. In this paper, we introduce VisRAG, which tackles this issue by establishing a vision-language model (VLM)-based RAG pipeline.
In this pipeline, instead of first parsing the document to obtain text, the document is directly embedded using a VLM as an image and then retrieved to enhance the generation of a VLM.
Compared to traditional text-based RAG, VisRAG maximizes the retention and utilization of the data information in the original documents, eliminating the information loss introduced during the parsing process.
We collect both open-source and synthetic data to train the retriever in VisRAG and explore a variety of generation methods. Experiments demonstrate that VisRAG outperforms traditional RAG in both the retrieval and generation stages, achieving a 25–39\% end-to-end performance gain over traditional text-based RAG pipeline.
Further analysis reveals that VisRAG is effective in utilizing training data and demonstrates strong generalization capability, positioning it as a promising solution for RAG on multi-modality documents.
5.4. MMed-RAG: Versatile Multimodal RAG System for Medical Vision Language Models

Artificial Intelligence (AI) has demonstrated significant potential in healthcare, particularly in disease diagnosis and treatment planning. Recent progress in Medical Large Vision-Language Models (Med-LVLMs) has opened up new possibilities for interactive diagnostic tools.
However, these models often suffer from factual hallucinations, which can lead to incorrect diagnoses. Fine-tuning and retrieval-augmented generation (RAG) have emerged as methods to address these issues.
However, the amount of high-quality data and distribution shifts between training data and deployment data limit the application of fine-tuning methods.
Although RAG is lightweight and effective, existing RAG-based approaches are not sufficiently general to different medical domains and can potentially cause misalignment issues, both between modalities and between the model and the ground truth.
In this paper, we propose a versatile multimodal RAG system, MMed-RAG, designed to enhance the factuality of Med-LVLMs. Our approach introduces a domain-aware retrieval mechanism, an adaptive retrieved contexts selection method, and a provable RAG-based preference fine-tuning strategy.
These innovations make the RAG process sufficiently general and reliable, significantly improving alignment when introducing retrieved contexts. Experimental results across five medical datasets (involving radiology, ophthalmology, pathology) on medical VQA and report generation demonstrate that MMed-RAG can achieve an average improvement of 43.8% in the factual accuracy of Med-LVLMs.
6. LLM Agents
6.1. Agent-as-a-Judge: Evaluate Agents with Agents

Contemporary evaluation techniques are inadequate for agentic systems. These approaches either focus exclusively on final outcomes — ignoring the step-by-step nature of agentic systems, or require excessive manual labor.
To address this, we introduce the Agent-as-a-Judge framework, wherein agentic systems are used to evaluate agentic systems. This is an organic extension of the LLM-as-a-Judge framework, incorporating agentic features that enable intermediate feedback for the entire task-solving process.
We apply the Agent-as-a-Judge to the task of code generation. To overcome issues with existing benchmarks and provide a proof-of-concept testbed for Agent-as-a-Judge, we present DevAI, a new benchmark of 55 realistic automated AI development tasks.
It includes rich manual annotations, like a total of 365 hierarchical user requirements. We benchmark three of the popular agentic systems using Agent-as-a-Judge and find it dramatically outperforms LLM-as-a-Judge and is as reliable as our human evaluation baseline.
Altogether, we believe that Agent-as-a-Judge marks a concrete step forward for modern agentic systems — by providing rich and reliable reward signals necessary for dynamic and scalable self-improvement.
6.2. MobA: A Two-Level Agent System for Efficient Mobile Task Automation

Current mobile assistants are limited by dependence on system APIs or struggle with complex user instructions and diverse interfaces due to restricted comprehension and decision-making abilities.
To address these challenges, we propose MobA, a novel mobile phone agent powered by large multimodal language models that enhance comprehension and planning capabilities through a sophisticated two-level agent architecture.
The high-level Global Agent (GA) is responsible for understanding user commands, tracking history memories, and planning tasks. The low-level Local Agent (LA) predicts detailed actions in the form of function calls, guided by sub-tasks and memory from the GA.
Integrating a Reflection Module allows for efficient task completion and enables the system to handle previously unseen complex tasks. MobA demonstrates significant improvements in task execution efficiency and completion rate in real-life evaluations, underscoring the potential of MLLM-empowered mobile assistants.
6.3. Revealing the Barriers of Language Agents in Planning

Autonomous planning has been an ongoing pursuit since the inception of artificial intelligence. Based on curated problem solvers, early planning agents could deliver precise solutions for specific tasks but lacked generalization.
The emergence of large language models (LLMs) and their powerful reasoning capabilities has reignited interest in autonomous planning by automatically generating reasonable solutions for given tasks.
However, prior research and our experiments show that current language agents still lack human-level planning abilities. Even the state-of-the-art reasoning model, OpenAI o1, achieves only 15.6% on one of the complex real-world planning benchmarks.
This highlights a critical question: What hinders language agents from achieving human-level planning? Although existing studies have highlighted weak performance in agent planning, the deeper underlying issues and the mechanisms and limitations of the strategies proposed to address them remain insufficiently understood.
In this work, we apply the feature attribution study and identify two key factors that hinder agent planning: the limited role of constraints and the diminishing influence of questions.
We also find that although current strategies help mitigate these challenges, they do not fully resolve them, indicating that agents still have a long way to go before reaching human-level intelligence.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
