


Important LLMs Papers for the Week from 17/02 to 23/02
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Third Week of February 2025. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Technical Reports
LLM Reasoning
LLM Training & Fine Tuning
LLM Preference Optimization & Alignment
LLM Scaling & Optimization
Retrieval Augmented Generation (RAG)
Attention Models
LLM Evaluation & Benchmarking
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. LLM Progress & Technical Reports
1.1. SWE-Lancer: Can Frontier LLMs Earn $1 Million from Real-World Freelance Software Engineering?

We introduce SWE-Lancer, a benchmark of over 1,400 freelance software engineering tasks from Upwork, valued at \1 million USD total in real-world payouts.
SWE-Lancer encompasses both independent engineering tasks — ranging from 50 bug fixes to $32,000 feature implementations — and managerial tasks, where models choose between technical implementation proposals.
Independent tasks are graded with end-to-end tests triple-verified by experienced software engineers, while managerial decisions are assessed against the choices of the original hired engineering managers.
We evaluate model performance and find that frontier models are still unable to solve the majority of tasks. To facilitate future research, we open-source a unified Docker image and a public evaluation split, SWE-Lancer Diamond (https://github.com/openai/SWELancer-Benchmark).
By mapping model performance to monetary value, we hope SWE-Lancer enables greater research into the economic impact of AI model development.
1.2. Qwen2.5-VL Technical Report
We introduce Qwen2.5-VL, the latest flagship model of Qwen vision-language series, which demonstrates significant advancements in both foundational capabilities and innovative functionalities.
Qwen2.5-VL achieves a major leap forward in understanding and interacting with the world through enhanced visual recognition, precise object localization, robust document parsing, and long-video comprehension.
A standout feature of Qwen2.5-VL is its ability to localize objects using bounding boxes or points accurately. It provides robust structured data extraction from invoices, forms, and tables, as well as detailed analysis of charts, diagrams, and layouts.
To handle complex inputs, Qwen2.5-VL introduces dynamic resolution processing and absolute time encoding, enabling it to process images of varying sizes and videos of extended durations (up to hours) with second-level event localization.
This allows the model to natively perceive spatial scales and temporal dynamics without relying on traditional normalization techniques. By training a native dynamic-resolution Vision Transformer (ViT) from scratch and incorporating Window Attention, we reduce computational overhead while maintaining native resolution.
As a result, Qwen2.5-VL excels not only in static image and document understanding but also as an interactive visual agent capable of reasoning, tool usage, and task execution in real-world scenarios such as operating computers and mobile devices.
Qwen2.5-VL is available in three sizes, addressing diverse use cases from edge AI to high-performance computing. The flagship Qwen2.5-VL-72B model matches state-of-the-art models like GPT-4o and Claude 3.5 Sonnet, particularly excelling in document and diagram understanding. Additionally, Qwen2.5-VL maintains robust linguistic performance, preserving the core language competencies of the Qwen2.5 LLM.
2. LLM Reasoning
2.1. The Danger of Overthinking: Examining the Reasoning-Action Dilemma in Agentic Tasks

Large Reasoning Models (LRMs) represent a breakthrough in AI problem-solving capabilities, but their effectiveness in interactive environments can be limited.
This paper introduces and analyzes overthinking in LRMs. A phenomenon where models favor extended internal reasoning chains over environmental interaction.
Through experiments on software engineering tasks using SWE Bench Verified, we observe three recurring patterns: Analysis Paralysis, Rogue Actions, and Premature Disengagement. We propose a framework to study these behaviors, which correlates with human expert assessments, and analyze 4018 trajectories.
We observe that higher overthinking scores correlate with decreased performance, with reasoning models exhibiting stronger tendencies toward overthinking compared to non-reasoning models.
Our analysis reveals that simple efforts to mitigate overthinking in agentic environments, such as selecting the solution with the lower overthinking score, can improve model performance by almost 30% while reducing computational costs by 43%.
These results suggest that mitigating overthinking has strong practical implications. We suggest that by leveraging native function-calling capabilities and selective reinforcement learning, overthinking tendencies could be mitigated.
2.2. Diverse Inference and Verification for Advanced Reasoning
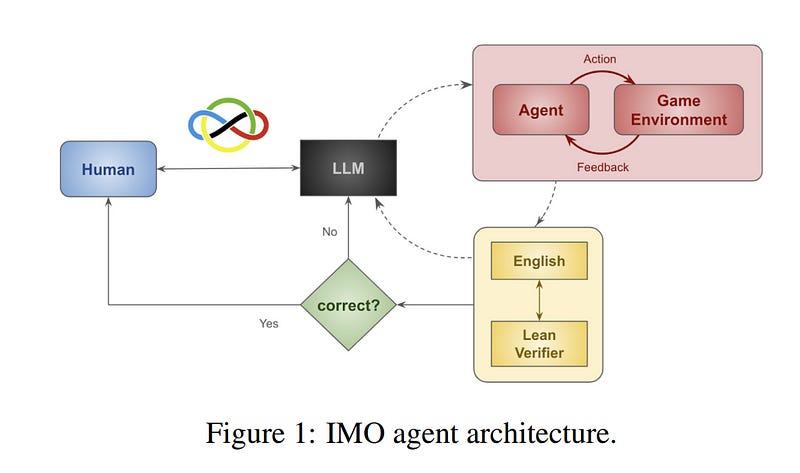
Reasoning LLMs such as OpenAI o1, o3 and DeepSeek R1 have made significant progress in mathematics and coding, yet find challenging advanced tasks such as International Mathematical Olympiad (IMO) combinatorics problems, Abstraction and Reasoning Corpus (ARC) puzzles, and Humanity’s Last Exam (HLE) questions.
We use a diverse inference approach that combines multiple models and methods at test time. We find that verifying mathematics and code problems, and rejection sampling on other problems is simple and effective.
We automatically verify correctness of solutions to IMO problems by Lean, and ARC puzzles by code, and find that best-of-N effectively answers HLE questions.
Our approach increases answer accuracy on IMO combinatorics problems from 33.3% to 77.8%, accuracy on HLE questions from 8% to 37%, and solves 80% of ARC puzzles that 948 humans could not and 26.5% of ARC puzzles that o3 high compute does not.
Test-time simulations, reinforcement learning, and meta-learning with inference feedback improve generalization by adapting agent graph representations and varying prompts, code, and datasets. Our approach is reliable, robust, and scalable, and in the spirit of reproducible research, we will make it publicly available upon publication.
2.3. Small Models Struggle to Learn from Strong Reasoners
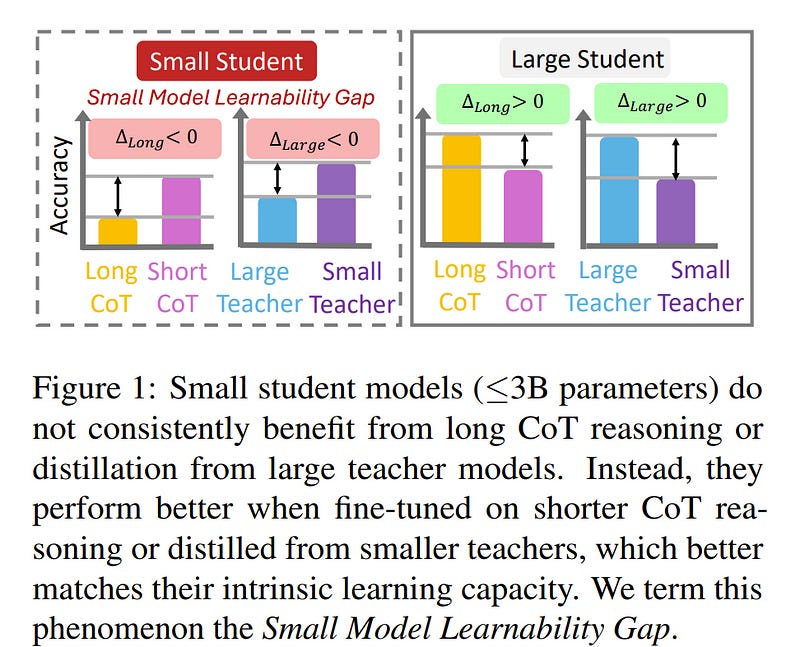
Large language models (LLMs) excel in complex reasoning tasks, and distilling their reasoning capabilities into smaller models has shown promise.
However, we uncover an interesting phenomenon, which we term the Small Model Learnability Gap: small models (leq3B parameters) do not consistently benefit from long chain-of-thought (CoT) reasoning or distillation from larger models.
Instead, they perform better when fine-tuned on shorter, simpler reasoning chains that better align with their intrinsic learning capacity. To address this, we propose Mix Distillation, a simple yet effective strategy that balances reasoning complexity by combining long and short CoT examples or reasoning from both larger and smaller models.
Our experiments demonstrate that Mix Distillation significantly improves small model reasoning performance compared to training on either data alone. These findings highlight the limitations of direct strong model distillation and underscore the importance of adapting reasoning complexity for effective reasoning capability transfer.
3. LLM Training & Fine Tuning
3.1. How Do LLMs Acquire New Knowledge? A Knowledge Circuits Perspective on Continual Pre-Training

Despite exceptional capabilities in knowledge-intensive tasks, Large Language Models (LLMs) face a critical gap in understanding how they internalize new knowledge, particularly how to structurally embed acquired knowledge in their neural computations.
We address this issue through the lens of knowledge circuit evolution, identifying computational subgraphs that facilitate knowledge storage and processing.
Our systematic analysis of circuit evolution throughout continual pre-training reveals several key findings:
The acquisition of new knowledge is influenced by its relevance to pre-existing knowledge.
The evolution of knowledge circuits exhibits a distinct phase shift from formation to optimization.
The evolution of knowledge circuits follows a deep-to-shallow pattern.
These insights not only advance our theoretical understanding of the mechanisms of new knowledge acquisition in LLMs, but also provide potential implications for improving continual pre-training strategies to enhance model performance.
3.2. Craw4LLM: Efficient Web Crawling for LLM Pretraining
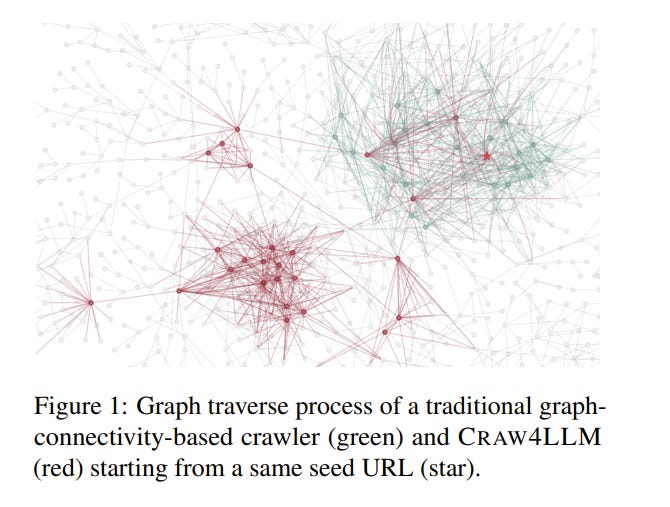
Web crawl is a main source of large language models’ (LLMs) pretraining data, but the majority of crawled web pages are discarded in pretraining due to low data quality.
This paper presents Crawl4LLM, an efficient web crawling method that explores the web graph based on the preference of LLM pretraining. Specifically, it leverages the influence of a webpage in LLM pretraining as the priority score of the web crawler’s scheduler, replacing the standard graph connectivity based priority.
Our experiments on a web graph containing 900 million webpages from a commercial search engine’s index demonstrate the efficiency of Crawl4LLM in obtaining high-quality pretraining data.
With just 21% URLs crawled, LLMs pretrained on Crawl4LLM data reach the same downstream performances of previous crawls, significantly reducing the crawling waste and alleviating the burdens on websites.
3.3. ReLearn: Unlearning via Learning for Large Language Models

Current unlearning methods for large language models usually rely on reverse optimization to reduce target token probabilities. However, this paradigm disrupts the subsequent tokens prediction, degrading model performance and linguistic coherence.
Moreover, existing evaluation metrics overemphasize contextual forgetting while inadequately assessing response fluency and relevance. To address these challenges, we propose ReLearn, a data augmentation and fine-tuning pipeline for effective unlearning, along with a comprehensive evaluation framework.
This framework introduces Knowledge Forgetting Rate (KFR) and Knowledge Retention Rate (KRR) to measure knowledge-level preservation, and Linguistic Score (LS) to evaluate generation quality. Our experiments show that ReLearn successfully achieves targeted forgetting while preserving high-quality output.
Through mechanistic analysis, we further demonstrate how reverse optimization disrupts coherent text generation, while ReLearn preserves this essential capability.
4. LLM Preference Optimization & Alignment
4.1. Rethinking Diverse Human Preference Learning through Principal Component Analysis

Understanding human preferences is crucial for improving foundation models and building personalized AI systems. However, preferences are inherently diverse and complex, making it difficult for traditional reward models to capture their full range.
While fine-grained preference data can help, collecting it is expensive and hard to scale. In this paper, we introduce Decomposed Reward Models (DRMs), a novel approach that extracts diverse human preferences from binary comparisons without requiring fine-grained annotations.
Our key insight is to represent human preferences as vectors and analyze them using Principal Component Analysis (PCA). By constructing a dataset of embedding differences between preferred and rejected responses, DRMs identify orthogonal basis vectors that capture distinct aspects of preference.
These decomposed rewards can be flexibly combined to align with different user needs, offering an interpretable and scalable alternative to traditional reward models.
We demonstrate that DRMs effectively extract meaningful preference dimensions (e.g., helpfulness, safety, humor) and adapt to new users without additional training. Our results highlight DRMs as a powerful framework for personalized and interpretable LLM alignment.
4.2. On the Trustworthiness of Generative Foundation Models: Guideline, Assessment, and Perspective
Generative Foundation Models (GenFMs) have emerged as transformative tools. However, their widespread adoption raises critical concerns regarding trustworthiness across dimensions.
This paper presents a comprehensive framework to address these challenges through three key contributions. First, we systematically review global AI governance laws and policies from governments and regulatory bodies, as well as industry practices and standards.
Based on this analysis, we propose a set of guiding principles for GenFMs, developed through extensive multidisciplinary collaboration that integrates technical, ethical, legal, and societal perspectives.
Second, we introduce TrustGen, the first dynamic benchmarking platform designed to evaluate trustworthiness across multiple dimensions and model types, including text-to-image, large language, and vision-language models.
TrustGen leverages modular components — metadata curation, test case generation, and contextual variation — to enable adaptive and iterative assessments, overcoming the limitations of static evaluation methods. Using TrustGen, we reveal significant progress in trustworthiness while identifying persistent challenges.
Finally, we provide an in-depth discussion of the challenges and future directions for trustworthy GenFMs, which reveals the complex, evolving nature of trustworthiness, highlighting the nuanced trade-offs between utility and trustworthiness, and consideration for various downstream applications, identifying persistent challenges and providing a strategic roadmap for future research.
This work establishes a holistic framework for advancing trustworthiness in GenAI, paving the way for safer and more responsible integration of GenFMs into critical applications. To facilitate advancement in the community, we release the toolkit for dynamic evaluation.
5. LLM Scaling & Optimization
5.1. DarwinLM: Evolutionary Structured Pruning of Large Language Models
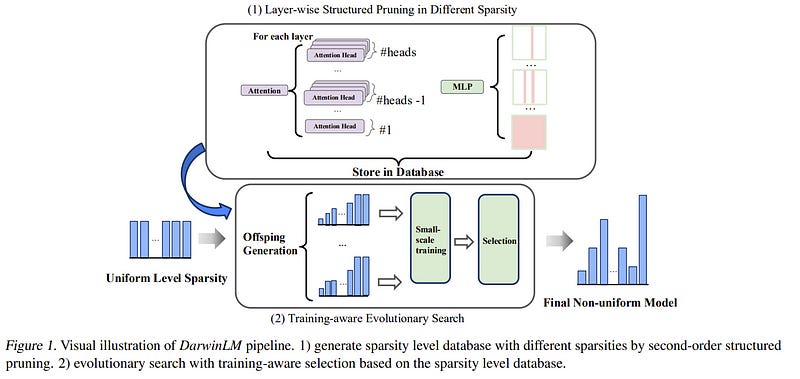
Large Language Models (LLMs) have achieved significant success across various NLP tasks. However, their massive computational costs limit their widespread use, particularly in real-time applications.
Structured pruning offers an effective solution by compressing models and directly providing end-to-end speed improvements, regardless of the hardware environment.
Meanwhile, different components of the model exhibit varying sensitivities towards pruning, calling for non-uniform model compression. However, a pruning method should not only identify a capable substructure, but also account for post-compression training.
To this end, we propose \sysname, a method for training-aware structured pruning. \sysname builds upon an evolutionary search process, generating multiple offspring models in each generation through mutation, and selecting the fittest for survival.
To assess the effect of post-training, we incorporate a lightweight, multistep training process within the offspring population, progressively increasing the number of tokens and eliminating poorly performing models in each selection stage.
We validate our method through extensive experiments on Llama-2–7B, Llama-3.1–8B and Qwen-2.5–14B-Instruct, achieving state-of-the-art performance for structured pruning. For instance, \sysname surpasses ShearedLlama while requiring 5 times less training data during post-compression training.
6. Retrieval Augmented Generation (RAG)
6.1. SearchRAG: Can search engines be helpful for answering LLM-based medical Questions?

Large Language Models (LLMs) have shown remarkable capabilities in general domains but often struggle with tasks requiring specialized knowledge.
Conventional Retrieval-Augmented Generation (RAG) techniques typically retrieve external information from static knowledge bases, which can be outdated or incomplete, missing fine-grained clinical details essential for accurate medical question answering.
In this work, we propose SearchRAG, a novel framework that overcomes these limitations by leveraging real-time search engines. Our method employs synthetic query generation to convert complex medical questions into search-engine-friendly queries and utilizes uncertainty-based knowledge selection to filter and incorporate the most relevant and informative medical knowledge into the LLM’s input.
Experimental results demonstrate that our method significantly improves response accuracy in medical question answering tasks, particularly for complex questions requiring detailed and up-to-date knowledge.
7. Attention Models
7.1. Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
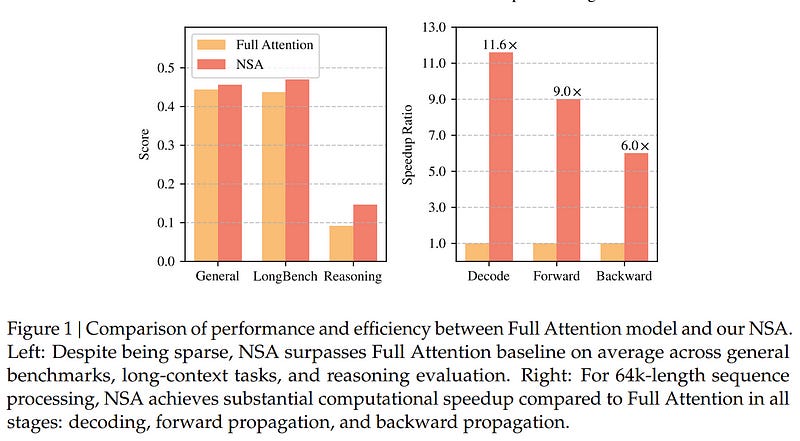
Long-context modeling is crucial for next-generation language models, yet the high computational cost of standard attention mechanisms poses significant computational challenges.
Sparse attention offers a promising direction for improving efficiency while maintaining model capabilities. We present NSA, a Natively trainable Sparse Attention mechanism that integrates algorithmic innovations with hardware-aligned optimizations to achieve efficient long-context modeling.
NSA employs a dynamic hierarchical sparse strategy, combining coarse-grained token compression with fine-grained token selection to preserve both global context awareness and local precision.
Our approach advances sparse attention design with two key innovations:
We achieve substantial speedups through arithmetic intensity-balanced algorithm design, with implementation optimizations for modern hardware.
We enable end-to-end training, reducing pretraining computation without sacrificing model performance. As shown in the Figure, experiments show the model pretrained with NSA maintains or exceeds Full Attention models across general benchmarks, long-context tasks, and instruction-based reasoning.
Meanwhile, NSA achieves substantial speedups over Full Attention on 64k-length sequences across decoding, forward propagation, and backward propagation, validating its efficiency throughout the model lifecycle.
8. LLM Evaluation & Benchmarking
8.1. ZeroBench: An Impossible Visual Benchmark for Contemporary Large Multimodal Models

Large Multimodal Models (LMMs) exhibit major shortfalls when interpreting images and, by some measures, have poorer spatial cognition than small children or animals.
Despite this, they attain high scores on many popular visual benchmarks, with headroom rapidly eroded by an ongoing surge of model progress. To address this, there is a pressing need for difficult benchmarks that remain relevant for longer.
We take this idea to its limit by introducing ZeroBench lightweight visual reasoning benchmark that is entirely impossible for contemporary frontier LMMs. Our benchmark consists of 100 manually curated questions and 334 less difficult subquestions.
We evaluate 20 LMMs on ZeroBench, all of which score 0.0%, and rigorously analyse the errors. To encourage progress in visual understanding, we publicly release ZeroBench.
8.2. MMTEB: Massive Multilingual Text Embedding Benchmark

Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity.
To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) — a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages.
MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date.
Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters.
To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings.
Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands.
For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.
Are you looking to start a career in data science and AI, and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
