


Important LLMs Papers for the Week from 03/03 to 09/03
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the First Week of March 2025. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Technical Reports
LLM Reasoning
LLM Training & Fine Tuning
AI Agents
Multimodal LLMs
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. LLM Progress & Technical Reports
1.1. Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
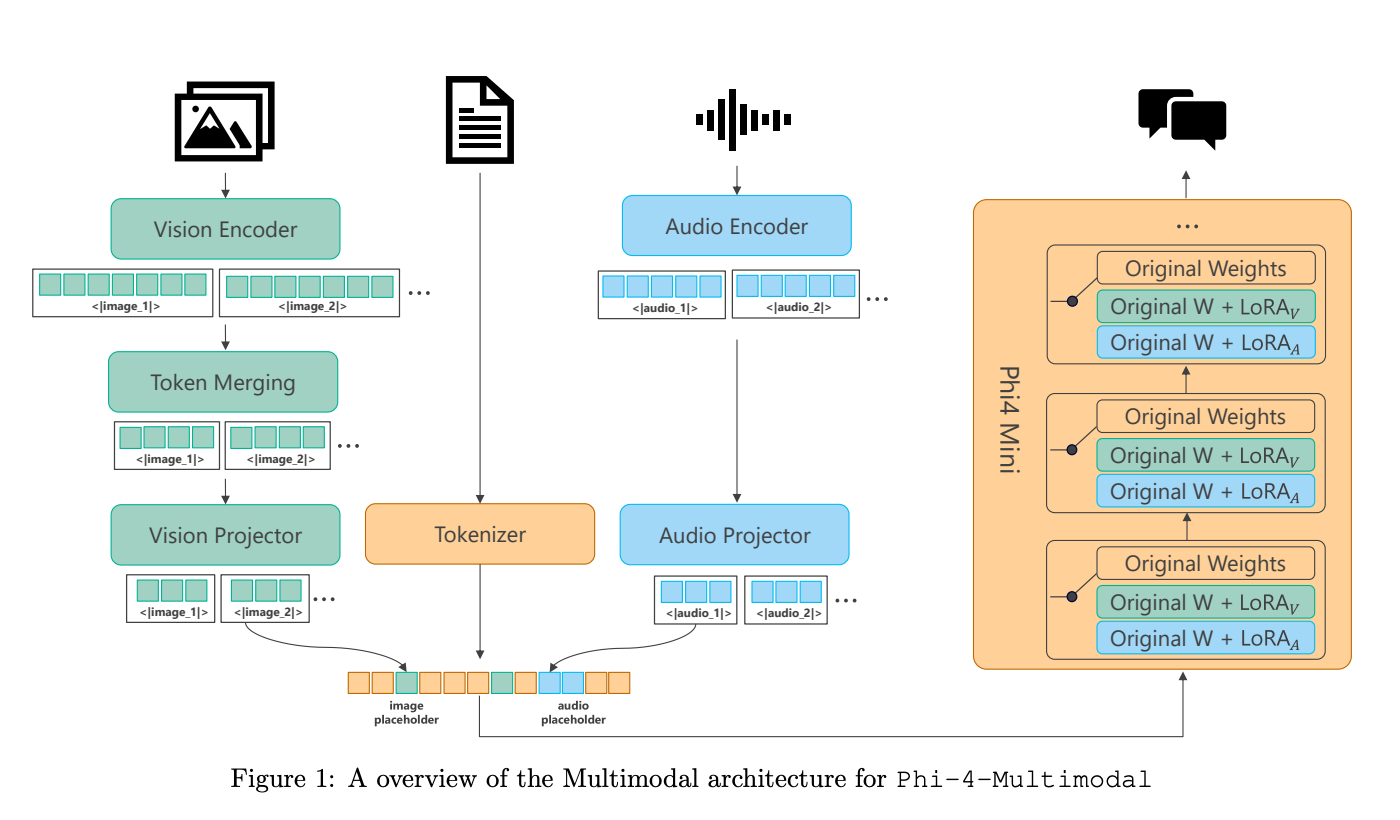
We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning.
This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation.
Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference.
For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks.
Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
1.2. How to Steer LLM Latents for Hallucination Detection?

Hallucinations in LLMs pose a significant concern to their safe deployment in real-world applications. Recent approaches have leveraged the latent space of LLMs for hallucination detection, but their embeddings, optimized for linguistic coherence rather than factual accuracy, often fail to separate truthful and hallucinated content.
To this end, we propose the Truthfulness Separator Vector (TSV), a lightweight and flexible steering vector that reshapes the LLM’s representation space during inference to enhance the separation between truthful and hallucinated outputs, without altering model parameters.
Our two-stage framework first trains TSV on a small set of labeled exemplars to form compact and well-separated clusters. It then augments the exemplar set with unlabeled LLM generations, employing an optimal transport-based algorithm for pseudo-labeling combined with a confidence-based filtering process.
Extensive experiments demonstrate that TSV achieves state-of-the-art performance with minimal labeled data, exhibiting strong generalization across datasets and providing a practical solution for real-world LLM applications.
1.3. Audio Flamingo 2: An Audio-Language Model with Long-Audio Understanding and Expert Reasoning Abilities
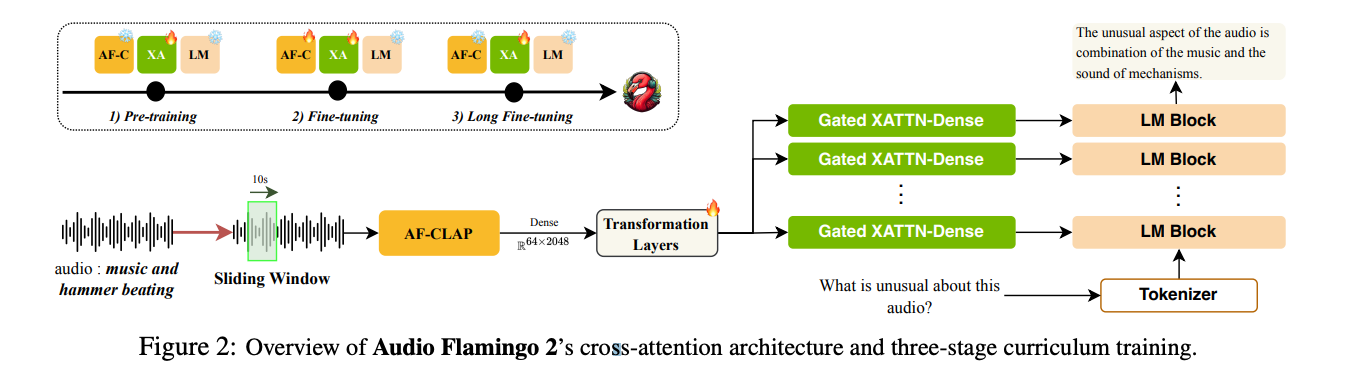
Understanding and reasoning over non-speech sounds and music are crucial for both humans and AI agents to interact effectively with their environments. In this paper, we introduce Audio Flamingo 2 (AF2), an Audio-Language Model (ALM) with advanced audio understanding and reasoning capabilities.
AF2 leverages (i) a custom CLAP model, (ii) synthetic Audio QA data for fine-grained audio reasoning, and (iii) a multi-stage curriculum learning strategy. AF2 achieves state-of-the-art performance with only a 3B parameter small language model, surpassing large open-source and proprietary models across over 20 benchmarks.
Next, for the first time, we extend audio understanding to long audio segments (30 secs to 5 mins) and propose LongAudio, a large and novel dataset for training ALMs on long audio captioning and question-answering tasks.
Fine-tuning AF2 on LongAudio leads to exceptional performance on our proposed LongAudioBench, an expert annotated benchmark for evaluating ALMs on long audio understanding capabilities. We conduct extensive ablation studies to confirm the efficacy of our approach.
1.4. Babel: Open Multilingual Large Language Models Serving Over 90% of Global Speakers

Large language models (LLMs) have revolutionized natural language processing (NLP), yet open-source multilingual LLMs remain scarce, with existing models often limited in language coverage.
Such models typically prioritize well-resourced languages, while widely spoken but under-resourced languages are often overlooked. To address this disparity, we introduce Babel, an open multilingual LLM that covers the top 25 languages by number of speakers, supports over 90% of the global population, and includes many languages neglected by other open multilingual LLMs.
Unlike traditional continue pretraining approaches, Babel expands its parameter count through a layer extension technique that elevates Babel’s performance ceiling. We introduce two variants: Babel-9B, designed for efficient inference and fine-tuning, and Babel-83B, which sets a new standard for open multilingual LLMs.
Extensive evaluations on multilingual tasks demonstrate its superior performance compared to open LLMs of comparable size. In addition, using open-source supervised fine-tuning datasets, Babel achieves remarkable performance, with Babel-9B-Chat leading among 10B-sized LLMs and Babel-83B-Chat setting a new standard for multilingual tasks, reaching the same level of commercial models.
1.5. Multi-Turn Code Generation Through Single-Step Rewards

We address the problem of code generation from multi-turn execution feedback. Existing methods either generate code without feedback or use complex, hierarchical reinforcement learning to optimize multi-turn rewards.
We propose a simple yet scalable approach, muCode, that solves multi-turn code generation using only single-step rewards. Our key insight is that code generation is a one-step recoverable MDP, where the correct code can be recovered from any intermediate code state in a single turn.
muCode iteratively trains both a generator to provide code solutions conditioned on multi-turn execution feedback and a verifier to score the newly generated code. Experimental evaluations show that our approach achieves significant improvements over the state-of-the-art baselines. We provide analysis of the design choices of the reward models and policy, and show the efficacy of muCode at utilizing the execution feedback.
1.6. KodCode: A Diverse, Challenging, and Verifiable Synthetic Dataset for Coding
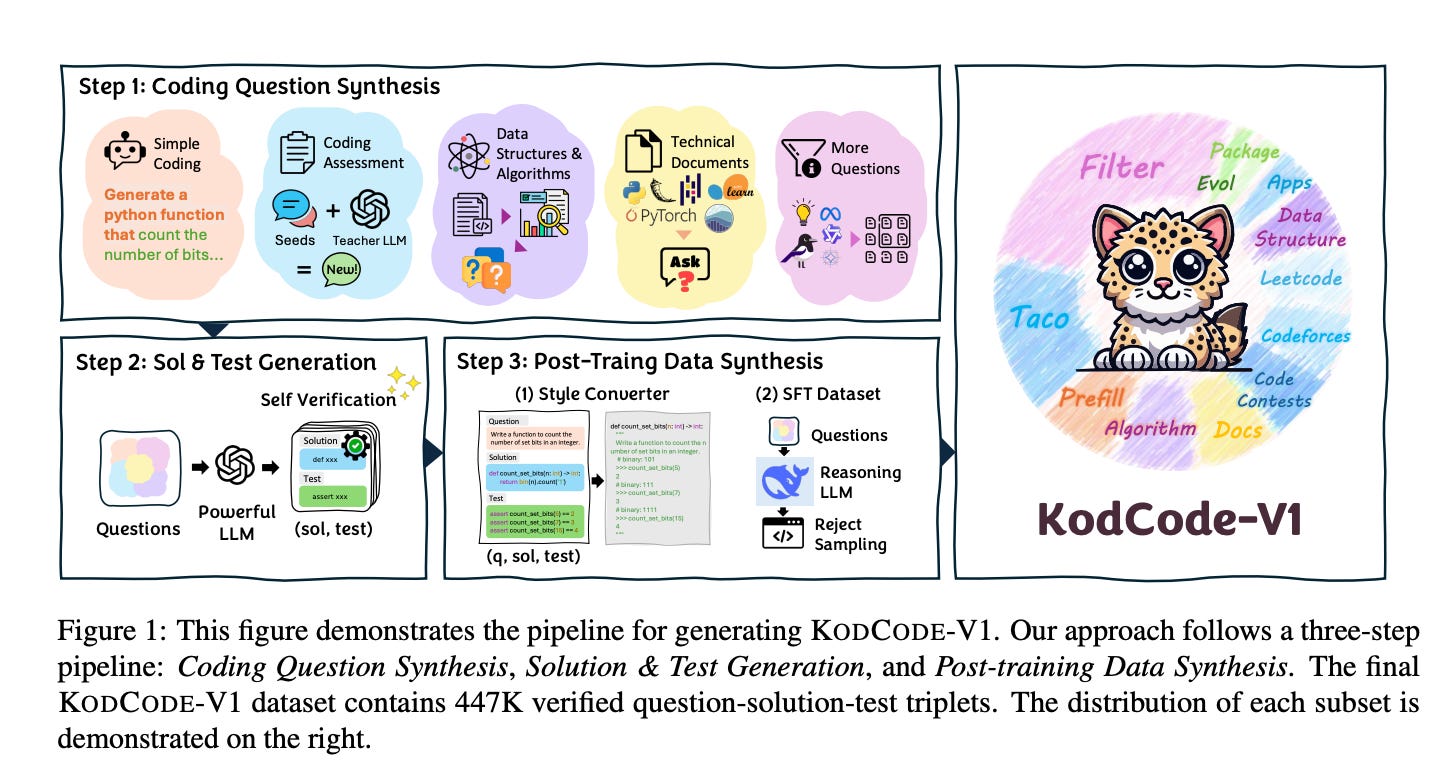
We introduce KodCode, a synthetic dataset that addresses the persistent challenge of acquiring high-quality, verifiable training data across diverse difficulties and domains for training Large Language Models for coding.
Existing code-focused resources typically fail to ensure either the breadth of coverage (e.g., spanning simple coding tasks to advanced algorithmic problems) or verifiable correctness (e.g., unit tests).
In contrast, KodCode comprises question-solution-test triplets that are systematically validated via a self-verification procedure. Our pipeline begins by synthesizing a broad range of coding questions, then generates solutions and test cases with additional attempts allocated to challenging problems.
Finally, post-training data synthesis is done by rewriting questions into diverse formats and generating responses under a test-based reject sampling procedure from a reasoning model (DeepSeek R1).
This pipeline yields a large-scale, robust and diverse coding dataset. KodCode is suitable for supervised fine-tuning and the paired unit tests also provide great potential for RL tuning. Fine-tuning experiments on coding benchmarks (HumanEval(+), MBPP(+), BigCodeBench, and LiveCodeBench) demonstrate that KodCode-tuned models achieve state-of-the-art performance, surpassing models like Qwen2.5-Coder-32B-Instruct and DeepSeek-R1-Distill-Llama-70B.
2. LLM Reasoning
2.1. START: Self-taught Reasoner with Tools

Large reasoning models (LRMs) like OpenAI-o1 and DeepSeek-R1 have demonstrated remarkable capabilities in complex reasoning tasks through the utilization of a Chain-of-thought (CoT).
However, these models often suffer from hallucinations and inefficiencies due to their reliance solely on internal reasoning processes. In this paper, we introduce START (Self-Taught Reasoner with Tools), a novel tool-integrated long CoT reasoning LLM that significantly enhances reasoning capabilities by leveraging external tools.
Through code execution, START is capable of performing complex computations, self-checking, exploring diverse methods, and self-debugging, thereby addressing the limitations of LRMs.
The core innovation of START lies in its self-learning framework, which comprises two key techniques:
Hint-infer: We demonstrate that inserting artificially designed hints (e.g., ``Wait, maybe using Python here is a good idea.’’) during the inference process of a LRM effectively stimulates its ability to utilize external tools without the need for any demonstration data. Hint-infer can also serve as a simple and effective sequential test-time scaling method
Hint Rejection Sampling Fine-Tuning (Hint-RFT): Hint-RFT combines Hint-infer and RFT by scoring, filtering, and modifying the reasoning trajectories with tool invocation generated by a LRM via Hint-infer, followed by fine-tuning the LRM. Through this framework, we have fine-tuned the QwQ-32B model to achieve START.
On PhD-level science QA (GPQA), competition-level math benchmarks (AMC23, AIME24, AIME25), and the competition-level code benchmark (LiveCodeBench), START achieves accuracy rates of 63.6%, 95.0%, 66.7%, 47.1%, and 47.3%, respectively. It significantly outperforms the base QwQ-32B and achieves performance comparable to the state-of-the-art open-weight model R1-Distill-Qwen-32B and the proprietary model o1-Preview.
2.2. Chain of Draft: Thinking Faster by Writing Less
Large Language Models (LLMs) have demonstrated remarkable performance in solving complex reasoning tasks through mechanisms like Chain-of-Thought (CoT) prompting, which emphasizes verbose, step-by-step reasoning.
However, humans typically employ a more efficient strategy: drafting concise intermediate thoughts that capture only essential information. In this work, we propose Chain of Draft (CoD), a novel paradigm inspired by human cognitive processes, where LLMs generate minimalistic yet informative intermediate reasoning outputs while solving tasks.
By reducing verbosity and focusing on critical insights, CoD matches or surpasses CoT in accuracy while using as little as only 7.6% of the tokens, significantly reducing cost and latency across various reasoning tasks.
2.3. SoS1: O1 and R1-Like Reasoning LLMs are Sum-of-Square Solvers

Large Language Models (LLMs) have achieved human-level proficiency across diverse tasks, but their ability to perform rigorous mathematical problem solving remains an open challenge.
In this work, we investigate a fundamental yet computationally intractable problem: determining whether a given multivariate polynomial is nonnegative. This problem, closely related to Hilbert’s Seventeenth Problem, plays a crucial role in global polynomial optimization and has applications in various fields.
First, we introduce SoS-1K, a meticulously curated dataset of approximately 1,000 polynomials, along with expert-designed reasoning instructions based on five progressively challenging criteria.
Evaluating multiple state-of-the-art LLMs, we find that without structured guidance, all models perform only slightly above the random guess baseline 50%. However, high-quality reasoning instructions significantly improve accuracy, boosting performance up to 81%.
Furthermore, our 7B model, SoS-7B, fine-tuned on SoS-1K for just 4 hours, outperforms the 671B DeepSeek-V3 and GPT-4o-mini in accuracy while only requiring 1.8% and 5% of the computation time needed for letters, respectively. Our findings highlight the potential of LLMs to push the boundaries of mathematical reasoning and tackle NP-hard problems.
2.4. Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs

Test-time inference has emerged as a powerful paradigm for enabling language models to ``think’’ longer and more carefully about complex challenges, much like skilled human experts.
While reinforcement learning (RL) can drive self-improvement in language models on verifiable tasks, some models exhibit substantial gains while others quickly plateau. For instance, we find that Qwen-2.5–3B far exceeds Llama-3.2–3B under identical RL training for the game of Countdown.
This discrepancy raises a critical question: what intrinsic properties enable effective self-improvement? We introduce a framework to investigate this question by analyzing four key cognitive behaviors — verification, backtracking, subgoal setting, and backward chaining — that both expert human problem solvers and successful language models employ. Our study reveals that Qwen naturally exhibits these reasoning behaviors, whereas Llama initially lacks them.
In systematic experimentation with controlled behavioral datasets, we find that priming Llama with examples containing these reasoning behaviors enables substantial improvements during RL, matching or exceeding Qwen’s performance. Importantly, the presence of reasoning behaviors, rather than correctness of answers, proves to be the critical factor — models primed with incorrect solutions containing proper reasoning patterns achieve comparable performance to those trained on correct solutions.
Finally, leveraging continued pretraining with OpenWebMath data, filtered to amplify reasoning behaviors, enables the Llama model to match Qwen’s self-improvement trajectory. Our findings establish a fundamental relationship between initial reasoning behaviors and the capacity for improvement, explaining why some language models effectively utilize additional computation while others plateau.
2.5. HoT: Highlighted Chain of Thought for Referencing Supporting Facts from Inputs

An Achilles heel of Large Language Models (LLMs) is their tendency to hallucinate non-factual statements. A response mixed of factual and non-factual statements poses a challenge for humans to verify and accurately base their decisions on.
To combat this problem, we propose Highlighted Chain-of-Thought Prompting (HoT), a technique for prompting LLMs to generate responses with XML tags that ground facts to those provided in the query.
That is, given an input question, LLMs would first re-format the question to add XML tags highlighting key facts, and then, generate a response with highlights over the facts referenced from the input.
Interestingly, in few-shot settings, HoT outperforms vanilla chain of thought prompting (CoT) on a wide range of 17 tasks from arithmetic, reading comprehension to logical reasoning. When asking humans to verify LLM responses, highlights help time-limited participants to more accurately and efficiently recognize when LLMs are correct. Yet, surprisingly, when LLMs are wrong, HoTs tend to make users believe that an answer is correct.
3. LLM Training & Fine Tuning
3.1. Fine-Tuning Small Language Models for Domain-Specific AI: An Edge AI Perspective
Deploying large scale language models on edge devices faces inherent challenges such as high computational demands, energy consumption, and potential data privacy risks. This paper introduces the Shakti Small Language Models (SLMs) Shakti-100M, Shakti-250M, and Shakti-500M which target these constraints head-on.
By combining efficient architectures, quantization techniques, and responsible AI principles, the Shakti series enables on-device intelligence for smartphones, smart appliances, IoT systems, and beyond. We provide comprehensive insights into their design philosophy, training pipelines, and benchmark performance on both general tasks (e.g., MMLU, Hellaswag) and specialized domains (healthcare, finance, and legal).
Our findings illustrate that compact models, when carefully engineered and fine-tuned, can meet and often exceed expectations in real-world edge-AI scenarios.
4. AI Agents
4.1. MultiAgentBench: Evaluating the Collaboration and Competition of LLM agents
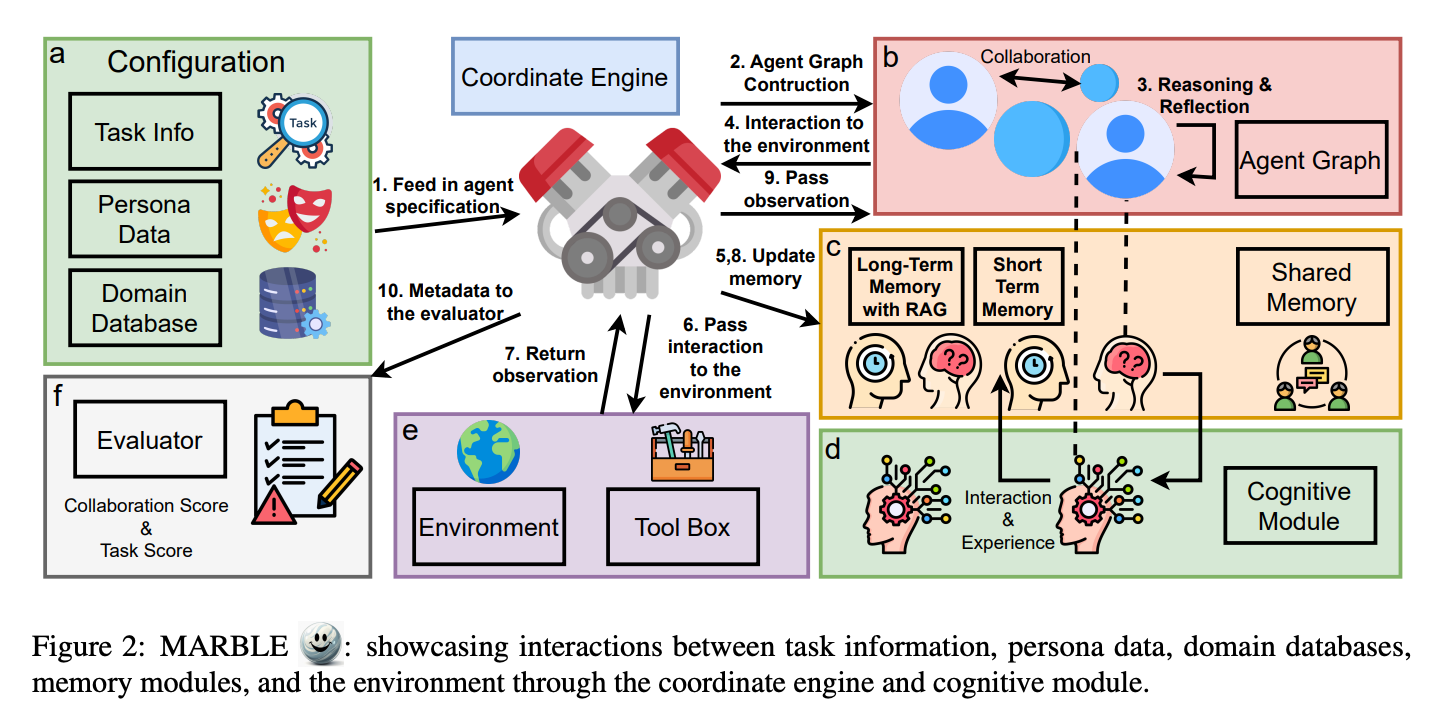
Large Language Models (LLMs) have shown remarkable capabilities as autonomous agents, yet existing benchmarks either focus on single-agent tasks or are confined to narrow domains, failing to capture the dynamics of multi-agent coordination and competition.
In this paper, we introduce MultiAgentBench, a comprehensive benchmark designed to evaluate LLM-based multi-agent systems across diverse, interactive scenarios. Our framework measures not only task completion but also the quality of collaboration and competition using novel, milestone-based key performance indicators.
Moreover, we evaluate various coordination protocols (including star, chain, tree, and graph topologies) and innovative strategies such as group discussion and cognitive planning. Notably, gpt-4o-mini reaches the average highest task score, graph structure performs the best among coordination protocols in the research scenario, and cognitive planning improves milestone achievement rates by 3%.
4.2. MPO: Boosting LLM Agents with Meta Plan Optimization

Recent advancements in large language models (LLMs) have enabled LLM-based agents to successfully tackle interactive planning tasks. However, despite their successes, existing approaches often suffer from planning hallucinations and require retraining for each new agent.
To address these challenges, we propose the Meta Plan Optimization (MPO) framework, which enhances agent planning capabilities by directly incorporating explicit guidance.
Unlike previous methods that rely on complex knowledge, which either require significant human effort or lack quality assurance, MPO leverages high-level general guidance through meta plans to assist agent planning and enables continuous optimization of the meta plans based on feedback from the agent’s task execution.
Our experiments conducted on two representative tasks demonstrate that MPO significantly outperforms existing baselines. Moreover, our analysis indicates that MPO provides a plug-and-play solution that enhances both task completion efficiency and generalization capabilities in previous unseen scenarios.
5. Multimodal LLMs
5.1. Token-Efficient Long Video Understanding for Multimodal LLMs

Recent advances in video-based multimodal large language models (Video-LLMs) have significantly improved video understanding by processing videos as sequences of image frames.
However, many existing methods treat frames independently in the vision backbone, lacking explicit temporal modeling, which limits their ability to capture dynamic patterns and efficiently handle long videos.
To address these limitations, we introduce STORM (Spatiotemporal TOken Reduction for Multimodal LLMs), a novel architecture incorporating a dedicated temporal encoder between the image encoder and the LLM.
Our temporal encoder leverages the Mamba State Space Model to integrate temporal information into image tokens, generating enriched representations that preserve inter-frame dynamics across the entire video sequence.
This enriched encoding not only enhances video reasoning capabilities but also enables effective token reduction strategies, including test-time sampling and training-based temporal and spatial pooling, substantially reducing computational demands on the LLM without sacrificing key temporal information.
By integrating these techniques, our approach simultaneously reduces training and inference latency while improving performance, enabling efficient and robust video understanding over extended temporal contexts.
Extensive evaluations show that STORM achieves state-of-the-art results across various long video understanding benchmarks (more than 5\% improvement on MLVU and LongVideoBench) while reducing the computation costs by up to 8 times and the decoding latency by 2.4–2.9 times for the fixed numbers of input frames.
5.2. Visual-RFT: Visual Reinforcement Fine-Tuning

Reinforcement Fine-Tuning (RFT) in Large Reasoning Models like OpenAI o1 learns from feedback on its answers, which is especially useful in applications when fine-tuning data is scarce. Recent open-source work like DeepSeek-R1 demonstrates that reinforcement learning with verifiable reward is one key direction in reproducing o1.
While the R1-style model has demonstrated success in language models, its application in multi-modal domains remains under-explored. This work introduces Visual Reinforcement Fine-Tuning (Visual-RFT), which further extends the application areas of RFT on visual tasks.
Specifically, Visual-RFT first uses Large Vision-Language Models (LVLMs) to generate multiple responses containing reasoning tokens and final answers for each input, and then uses our proposed visual perception verifiable reward functions to update the model via the policy optimization algorithm such as Group Relative Policy Optimization (GRPO).
We design different verifiable reward functions for different perception tasks, such as the Intersection over Union (IoU) reward for object detection. Experimental results on fine-grained image classification, few-shot object detection, reasoning grounding, as well as open-vocabulary object detection benchmarks show the competitive performance and advanced generalization ability of Visual-RFT compared with Supervised Fine-tuning (SFT).
For example, Visual-RFT improves accuracy by 24.3% over the baseline in one-shot fine-grained image classification with around 100 samples. In few-shot object detection, Visual-RFT also exceeds the baseline by 21.9 on COCO’s two-shot setting and 15.4 on LVIS.
Our Visual-RFT represents a paradigm shift in fine-tuning LVLMs, offering a data-efficient, reward-driven approach that enhances reasoning and adaptability for domain-specific tasks.
5.3. LLMVoX: Autoregressive Streaming Text-to-Speech Model for Any LLM
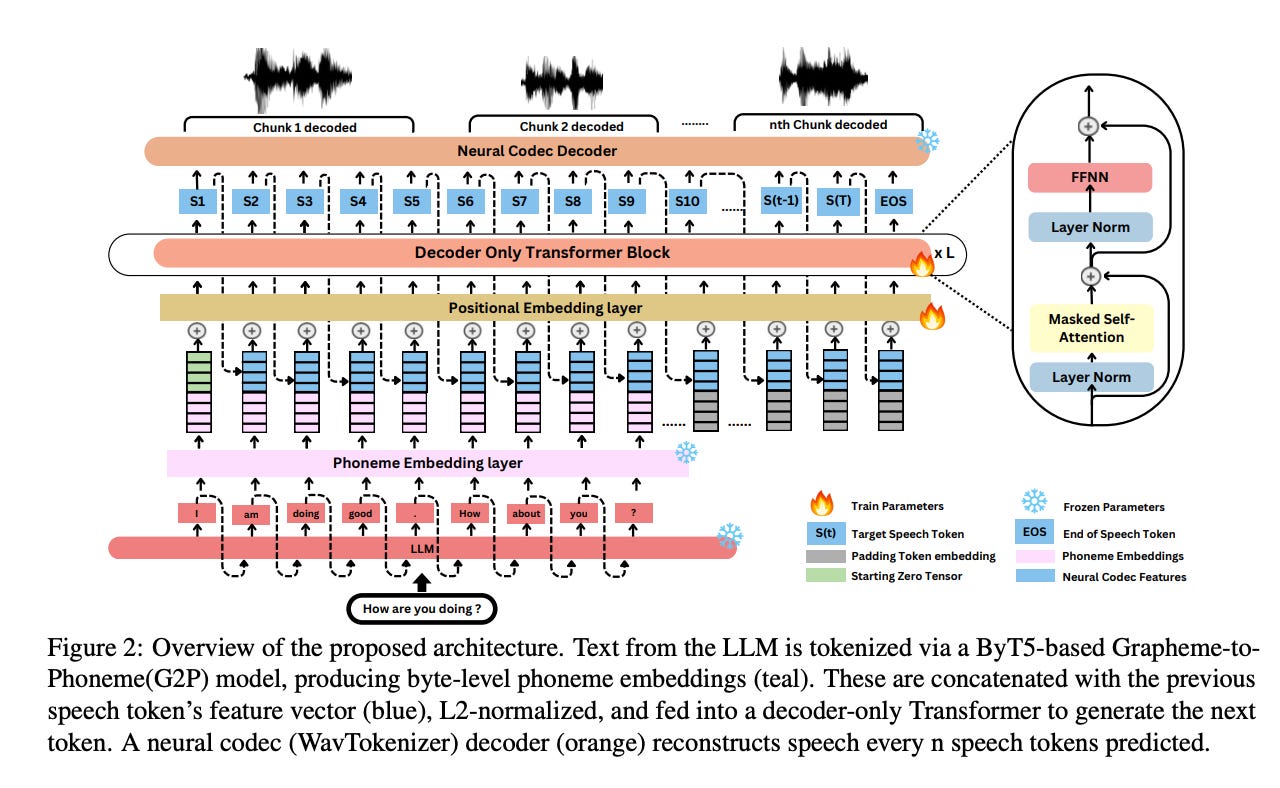
Recent advancements in speech-to-speech dialogue systems leverage LLMs for multimodal interactions, yet they remain hindered by fine-tuning requirements, high computational overhead, and text-speech misalignment. Existing speech-enabled LLMs often degrade conversational quality by modifying the LLM, thereby compromising its linguistic capabilities.
In contrast, we propose LLMVoX, a lightweight 30M-parameter, LLM-agnostic, autoregressive streaming TTS system that generates high-quality speech with low latency, while fully preserving the capabilities of the base LLM.
Our approach achieves a significantly lower word error rate than speech-enabled LLMs while operating at comparable latency and UTMOS scores. By decoupling speech synthesis from LLM processing via a multi-queue token streaming system, LLMVoX supports seamless, infinite-length dialogues. Its plug-and-play design also facilitates extension to various tasks with different backbones.
Furthermore, LLMVoX generalizes to new languages with only dataset adaptation, attaining a low Character Error Rate on an Arabic speech task. Additionally, we have integrated LLMVoX with a Vision-Language Model to create an omni-model with speech, text, and vision capabilities, without requiring additional multimodal training.
Are you looking to start a career in data science and AI, and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
