


Important LLMs Papers for the Week from 20/01 to 26/01
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Fourth Week of January 2025. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Reasoning
LLM Agents
LLM Preference Optimization & Alignment
LLM Scaling & Optimization
My New E-Book: Efficient Python for Data Scientists

I am happy to announce publishing my new E-book Efficient Python for Data Scientists. Efficient Python for Data Scientists is your practical companion to mastering the art of writing clean, optimized, and high-performing Python code for data science. In this book, you'll explore actionable insights and strategies to transform your Python workflows, streamline data analysis, and maximize the potential of libraries like Pandas.
1. LLM Progress & Benchmarking
1.1. Bridging Language Barriers in Healthcare: A Study on Arabic LLMs

This paper investigates the challenges of developing large language models (LLMs) proficient in both multilingual understanding and medical knowledge.
We demonstrate that simply translating medical data does not guarantee strong performance on clinical tasks in the target language. Our experiments reveal that the optimal language mix in training data varies significantly across different medical tasks.
We find that larger models with carefully calibrated language ratios achieve superior performance on native-language clinical tasks. Furthermore, our results suggest that relying solely on fine-tuning may not be the most effective approach for incorporating new language knowledge into LLMs.
Instead, data and computationally intensive pretraining methods may still be necessary to achieve optimal performance in multilingual medical settings. These findings provide valuable guidance for building effective and inclusive medical AI systems for diverse linguistic communities.
1.2. Autonomy-of-Experts Models

Mixture-of-Experts (MoE) models mostly use a router to assign tokens to specific expert modules, activating only partial parameters and often outperforming dense models.
We argue that the separation between the router’s decision-making and the experts’ execution is a critical yet overlooked issue, leading to suboptimal expert selection and ineffective learning.
To address this, we propose Autonomy-of-Experts (AoE), a novel MoE paradigm in which experts autonomously select themselves to process inputs.
AoE is based on the insight that an expert is aware of its own capacity to effectively process a token, an awareness reflected in the scale of its internal activations.
In AoE, routers are removed; instead, experts pre-compute internal activations for inputs and are ranked based on their activation norms. Only the top-ranking experts proceed with the forward pass, while the others abort.
The overhead of pre-computing activations is reduced through a low-rank weight factorization. This self-evaluating-then-partner-comparing approach ensures improved expert selection and effective learning.
We pre-train language models having 700M up to 4B parameters, demonstrating that AoE outperforms traditional MoE models with comparable efficiency.
1.3. Demons in the Detail: On Implementing Load Balancing Loss for Training Specialized Mixture-of-Expert Models

This paper revisits the implementation of Load-balancing Loss (LBL) when training Mixture-of-Experts (MoEs) models. Specifically, LBL for MoEs is defined as N_E sum_{i=1}^{N_E} f_i p_i, where N_E is the total number of experts, f_i represents the frequency of expert (i) being selected, and p_i denotes the average rating score of the expert i.
Existing MoE training frameworks usually employ the parallel training strategy so that f_i and the LBL are calculated within a micro-batch and then averaged across parallel groups.
In essence, a micro-batch for training billion-scale LLMs normally contains very few sequences. So, the micro-batch LBL is almost at the sequence level, and the router is pushed to distribute the token evenly within each sequence.
Under this strict constraint, even tokens from a domain-specific sequence (e.g., code) are uniformly routed to all experts, thereby inhibiting expert specialization.
In this work, we propose calculating LBL using a global batch to lose this constraint. Because a global-batch contains much more diverse sequences than a micro-batch, which will encourage load balance at the corpus level.
Specifically, we introduce an extra communication step to synchronize f_i across micro-batches and then use it to calculate the LBL. Through experiments on training MoEs-based LLMs (up to 42.8B total parameters and 400B tokens), we surprisingly find that the global-batch LBL strategy yields excellent performance gains in both pre-training perplexity and downstream tasks. Our analysis reveals that the global-batch LBL also greatly improves the domain specialization of MoE experts.
2. LLM Reasoning
2.1. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning

We introduce our first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1. DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step, demonstrates remarkable reasoning capabilities.
Through RL, DeepSeek-R1-Zero naturally emerges with numerous powerful and intriguing reasoning behaviors. However, it encounters challenges such as poor readability, and language mixing.
To address these issues and further enhance reasoning performance, we introduce DeepSeek-R1, which incorporates multi-stage training and cold-start data before RL. DeepSeek-R1 achieves performance comparable to OpenAI-o1–1217 on reasoning tasks.
To support the research community, we open-source DeepSeek-R1-Zero, DeepSeek-R1, and six dense models (1.5B, 7B, 8B, 14B, 32B, 70B) distilled from DeepSeek-R1 based on Qwen and Llama.
2.2. Evolving Deeper LLM Thinking

We explore an evolutionary search strategy for scaling inference time compute in Large Language Models. The proposed approach, Mind Evolution, uses a language model to generate, recombine, and refine candidate responses.
The proposed approach avoids the need to formalize the underlying inference problem whenever a solution evaluator is available. Controlling for inference cost, we find that Mind Evolution significantly outperforms other inference strategies such as Best-of-N and Sequential Revision in natural language planning tasks.
In the TravelPlanner and Natural Plan benchmarks, Mind Evolution solves more than 98% of the problem instances using Gemini 1.5 Pro without the use of a formal solver.
2.3. Multiple Choice Questions: Reasoning Makes Large Language Models (LLMs) More Self-Confident Even When They Are Wrong

One of the most widely used methods to evaluate LLMs is Multiple Choice Question (MCQ) tests. MCQ benchmarks enable the testing of LLM knowledge on almost any topic at scale as the results can be processed automatically.
To help the LLM answer, a few examples called few shots can be included in the prompt. Moreover, the LLM can be asked to answer the question directly with the selected option or to first provide the reasoning and then the selected answer, which is known as the chain of thought.
In addition to checking whether the selected answer is correct, the evaluation can look at the LLM-estimated probability of its response as an indication of the confidence of the LLM in the response.
In this paper, we study how the LLM confidence in its answer depends on whether the model has been asked to answer directly or to provide the reasoning before answering.
The results of the evaluation of questions on a wide range of topics in seven different models show that LLMs are more confident in their answers when they provide reasoning before the answer.
This occurs regardless of whether the selected answer is correct. Our hypothesis is that this behavior is due to the reasoning that modifies the probability of the selected answer, as the LLM predicts the answer based on the input question and the reasoning that supports the selection made.
Therefore, LLM-estimated probabilities seem to have intrinsic limitations that should be understood to use them in evaluation procedures. Interestingly, the same behavior has been observed in humans, for whom explaining an answer increases confidence in its correctness.
2.4. Reasoning Language Models: A Blueprint

Reasoning language models (RLMs), also known as Large Reasoning Models (LRMs), such as OpenAI’s o1 and o3, DeepSeek-V3, and Alibaba’s QwQ, have redefined AI’s problem-solving capabilities by extending LLMs with advanced reasoning mechanisms.
Yet, their high costs, proprietary nature, and complex architectures — uniquely combining Reinforcement Learning (RL), search heuristics, and LLMs — present accessibility and scalability challenges.
To address these, we propose a comprehensive blueprint that organizes RLM components into a modular framework, based on a survey and analysis of all RLM works.
This blueprint incorporates diverse reasoning structures (chains, trees, graphs, and nested forms), reasoning strategies (e.g., Monte Carlo Tree Search, Beam Search), RL concepts (policy, value models, and others), and supervision schemes (Output-Based and Process-Based Supervision).
We also provide detailed mathematical formulations and algorithmic specifications to simplify RLM implementation. By showing how schemes like LLaMA-Berry, QwQ, Journey Learning, and Graph of Thoughts fit as special cases, we demonstrate the blueprint’s versatility and unifying potential.
To illustrate its utility, we introduce x1, a modular implementation for rapid RLM prototyping and experimentation. Using x1 and a literature review, we provide key insights, such as multi-phase training for policy and value models, and the importance of familiar training distributions.
Finally, we outline how RLMs can integrate with a broader LLM ecosystem, including tools and databases. Our work demystifies RLM construction, democratizes advanced reasoning capabilities, and fosters innovation, aiming to mitigate the gap between “rich AI” and “poor AI” by lowering barriers to RLM development and experimentation.
3. LLM Agents
3.1. Agent-R: Training Language Model Agents to Reflect via Iterative Self-Training

LLM agents are increasingly pivotal for addressing complex tasks in interactive environments. Existing work mainly focuses on enhancing performance through behavior cloning from stronger experts, yet such approaches often falter in real-world applications, mainly due to the inability to recover from errors.
However, step-level critique data is difficult and expensive to collect. Automating and dynamically constructing self-critique datasets is thus crucial to empowering models with intelligent agent capabilities. In this work, we propose an iterative self-training framework, Agent-R, that enables language Agents to Reflect on the fly.
Unlike traditional methods that reward or penalize actions based on correctness, Agent-R leverages MCTS to construct training data that recover correct trajectories from erroneous ones.
A key challenge of agent reflection lies in the necessity for timely revision rather than waiting until the end of a rollout. To address this, we introduce a model-guided critique construction mechanism: the actor model identifies the first error step (within its current capability) in a failed trajectory. Starting from it, we splice it with the adjacent correct path, which shares the same parent node in the tree.
This strategy enables the model to learn reflection based on its current policy, therefore yielding better learning efficiency. To further explore the scalability of this self-improvement paradigm, we investigate iterative refinement of both error correction capabilities and dataset construction.
Our findings demonstrate that Agent-R continuously improves the model’s ability to recover from errors and enables timely error correction. Experiments on three interactive environments show that Agent-R effectively equips agents to correct erroneous actions while avoiding loops, achieving superior performance compared to baseline methods (+5.59%).
3.2. Mobile-Agent-E: Self-Evolving Mobile Assistant for Complex Tasks

Smartphones have become indispensable in modern life, yet navigating complex tasks on mobile devices often remains frustrating. Recent advancements in large multimodal model (LMM) — based mobile agents have demonstrated the ability to perceive and act in mobile environments.
However, current approaches face significant limitations: they fall short in addressing real-world human needs, struggle with reasoning-intensive and long-horizon tasks, and lack mechanisms to learn and improve from prior experiences.
To overcome these challenges, we introduce Mobile-Agent-E, a hierarchical multi-agent framework capable of self-evolution through past experience. By hierarchical, we mean an explicit separation of high-level planning and low-level action execution.
The framework comprises a Manager, responsible for devising overall plans by breaking down complex tasks into subgoals, and four subordinate agents — Perceptor, Operator, Action Reflector, and Notetaker — which handle fine-grained visual perception, immediate action execution, error verification, and information aggregation, respectively.
Mobile-Agent-E also features a novel self-evolution module that maintains a persistent long-term memory comprising Tips and Shortcuts. Tips are general guidance and lessons learned from prior tasks on how to interact with the environment effectively.
Shortcuts are reusable, executable sequences of atomic operations tailored for specific subroutines. The inclusion of Tips and Shortcuts facilitates continuous refinement in performance and efficiency.
Alongside this framework, we introduce Mobile-Eval-E, a new benchmark featuring complex mobile tasks requiring long-horizon, multi-app interactions.
Empirical results show that Mobile-Agent-E achieves a 22% absolute improvement over previous state-of-the-art approaches across three foundation model backbones.
3.3. IntellAgent: A Multi-Agent Framework for Evaluating Conversational AI Systems

Large Language Models (LLMs) are transforming artificial intelligence, evolving into task-oriented systems capable of autonomous planning and execution.
One of the primary applications of LLMs is conversational AI systems, which must navigate multi-turn dialogues, integrate domain-specific APIs, and adhere to strict policy constraints.
However, evaluating these agents remains a significant challenge, as traditional methods fail to capture the complexity and variability of real-world interactions.
We introduce IntellAgent, a scalable, open-source multi-agent framework designed to evaluate conversational AI systems comprehensively. IntellAgent automates the creation of diverse, synthetic benchmarks by combining policy-driven graph modeling, realistic event generation, and interactive user-agent simulations.
This innovative approach provides fine-grained diagnostics, addressing the limitations of static and manually curated benchmarks with coarse-grained metrics. IntellAgent represents a paradigm shift in evaluating conversational AI.
By simulating realistic, multi-policy scenarios across varying levels of complexity, IntellAgent captures the nuanced interplay of agent capabilities and policy constraints.
Unlike traditional methods, it employs a graph-based policy model to represent relationships, likelihoods, and complexities of policy interactions, enabling highly detailed diagnostics. IntellAgent also identifies critical performance gaps, offering actionable insights for targeted optimization.
Its modular, open-source design supports seamless integration of new domains, policies, and APIs, fostering reproducibility and community collaboration.
Our findings demonstrate that IntellAgent serves as an effective framework for advancing conversational AI by addressing challenges in bridging research and deployment.
4. LLM Preference Optimization & Alignment
4.1. Test-Time Preference Optimization: On-the-Fly Alignment via Iterative Textual Feedback
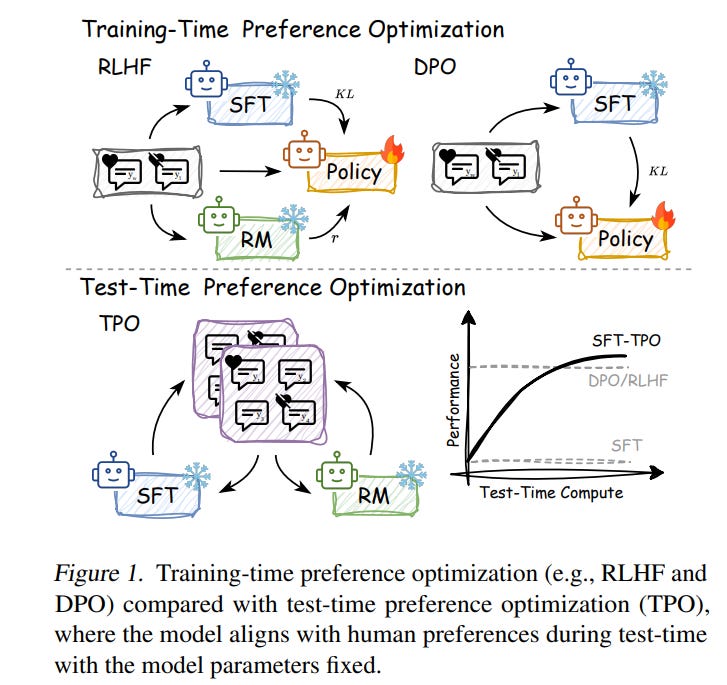
Large language models (LLMs) demonstrate impressive performance but lack the flexibility to adapt to human preferences quickly without retraining.
In this work, we introduce Test-time Preference Optimization (TPO), a framework that aligns LLM outputs with human preferences during inference, removing the need to update model parameters.
Rather than relying on purely numerical rewards, TPO translates reward signals into textual critiques and uses them as textual rewards to iteratively refine its response.
Evaluations on benchmarks covering instruction following, preference alignment, safety, and mathematics reveal that TPO progressively improves alignment with human preferences.
Notably, after only a few TPO steps, the initially unaligned Llama-3.1–70B-SFT model can surpass the aligned counterpart, Llama-3.1–70B-Instruct. Furthermore, TPO scales efficiently with both the search width and depth during inference.
Through case studies, we illustrate how TPO exploits the innate capacity of LLM to interpret and act upon reward signals. Our findings establish TPO as a practical, lightweight alternative for test-time preference optimization, achieving alignment on the fly.
4.2. SRMT: Shared Memory for Multi-agent Lifelong Pathfinding

Multi-agent reinforcement learning (MARL) demonstrates significant progress in solving cooperative and competitive multi-agent problems in various environments.
One of the principal challenges in MARL is the need for explicit prediction of the agents’ behavior to achieve cooperation. To resolve this issue, we propose the Shared Recurrent Memory Transformer (SRMT) which extends memory transformers to multi-agent settings by pooling and globally broadcasting individual working memories, enabling agents to exchange information implicitly and coordinate their actions.
We evaluate SRMT on the Partially Observable Multi-Agent Pathfinding problem in a toy Bottleneck navigation task that requires agents to pass through a narrow corridor and on a POGEMA benchmark set of tasks.
In the Bottleneck task, SRMT consistently outperforms a variety of reinforcement learning baselines, especially under sparse rewards, and generalizes effectively to longer corridors than those seen during training.
On POGEMA maps, including Mazes, Random, and MovingAI, SRMT is competitive with recent MARL, hybrid, and planning-based algorithms. These results suggest that incorporating shared recurrent memory into the transformer-based architectures can enhance coordination in decentralized multi-agent systems.
5. LLM Scaling & Optimization
5.1. Kimi k1.5: Scaling Reinforcement Learning with LLMs

Language model pretraining with next token prediction has proved effective for scaling compute but is limited to the amount of available training data.
Scaling reinforcement learning (RL) unlocks a new axis for the continued improvement of artificial intelligence, with the promise that large language models (LLMs) can scale their training data by learning to explore with rewards.
However, prior published work has not produced competitive results. In light of this, we report on the training practice of Kimi k1.5, our latest multi-modal LLM trained with RL, including its RL training techniques, multi-modal data recipes, and infrastructure optimization.
Long context scaling and improved policy optimization methods are key ingredients of our approach, which establishes a simplistic, effective RL framework without relying on more complex techniques such as Monte Carlo tree search, value functions, and process reward models.
Notably, our system achieves state-of-the-art reasoning performance across multiple benchmarks and modalities — e.g., 77.5 on AIME, 96.2 on MATH 500, 94th percentile on Codeforces, 74.9 on MathVista — matching OpenAI’s o1.
Moreover, we present effective long2short methods that use long-CoT techniques to improve short-CoT models, yielding state-of-the-art short-CoT reasoning results — e.g., 60.8 on AIME, 94.6 on MATH500, 47.3 on LiveCodeBench — outperforming existing short-CoT models such as GPT-4o and Claude Sonnet 3.5 by a large margin (up to +550%).
5.2. Sigma: Differential Rescaling of Query, Key, and Value for Efficient Language Models
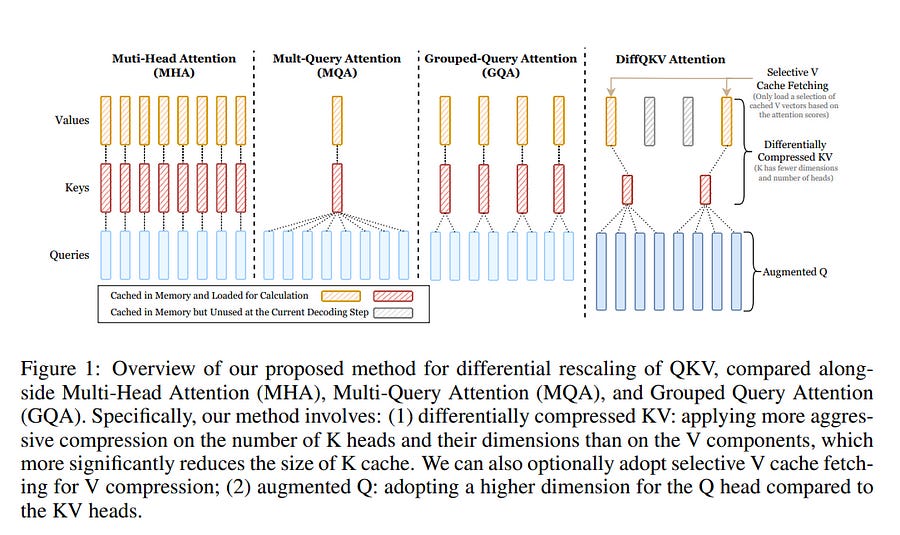
We introduce Sigma, an efficient large language model specialized for the system domain, empowered by a novel architecture including DiffQKV attention, and pre-trained on our meticulously collected system domain data.
DiffQKV attention significantly enhances the inference efficiency of Sigma by optimizing the Query (Q), Key (K), and Value (V) components in the attention mechanism differentially, based on their varying impacts on the model performance and efficiency indicators.
Specifically, we (1) conduct extensive experiments that demonstrate the model’s varying sensitivity to the compression of K and V components, leading to the development of differentially compressed KV, and (2) propose augmented Q to expand the Q head dimension, which enhances the model’s representation capacity with minimal impacts on the inference speed.
Rigorous theoretical and empirical analyses reveal that DiffQKV attention significantly enhances efficiency, achieving up to a 33.36% improvement in inference speed over the conventional grouped-query attention (GQA) in long-context scenarios.
We pre-train Sigma on 6T tokens from various sources, including 19.5B system domain data that we carefully collect and 1T tokens of synthesized and rewritten data. In general domains, Sigma achieves comparable performance to other state-of-arts models.
In the system domain, we introduce the first comprehensive benchmark AIMicius, where Sigma demonstrates remarkable performance across all tasks, significantly outperforming GPT-4 with an absolute improvement up to 52.5%.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
