


Important LLMs Papers for the Week from 08/07 to 14/07
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Second Week of July 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Training, Evaluation & Inference
LLM Fine-Tuning
LLM Quantization & Alignment
LLM Reasoning
LLM Safety & Alignment
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs. The content of the book covers the following topics:
1. LLM Progress & Benchmarking
1.1. Learning to (Learn at Test Time): RNNs with Expressive Hidden States
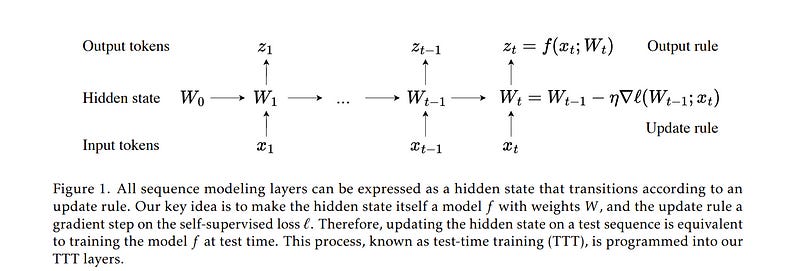
Self-attention performs well in a long context but has quadratic complexity. Existing RNN layers have linear complexity, but their performance in a long context is limited by the expressive power of their hidden state. We propose a new class of sequence modeling layers with linear complexity and an expressive hidden state.
The key idea is to make the hidden state a machine learning model itself, and the update rule a step of self-supervised learning. Since the hidden state is updated by training even on test sequences, our layers are called Test-Time Training (TTT) layers.
We consider two instantiations: TTT-Linear and TTT-MLP, whose hidden state is a linear model and a two-layer MLP respectively. We evaluate our instantiations at the scale of 125M to 1.3B parameters, comparing with a strong Transformer and Mamba, a modern RNN.
Both TTT-Linear and TTT-MLP match or exceed the baselines. Similar to Transformer, they can keep reducing perplexity by conditioning on more tokens, while Mamba cannot after 16k context.
With preliminary systems optimization, TTT-Linear is already faster than Transformer at 8k context and matches Mamba in wall-clock time. TTT-MLP still faces challenges in memory I/O, but shows larger potential in long context, pointing to a promising direction for future research.
1.2. LLaMAX: Scaling Linguistic Horizons of LLM by Enhancing Translation Capabilities Beyond 100 Languages
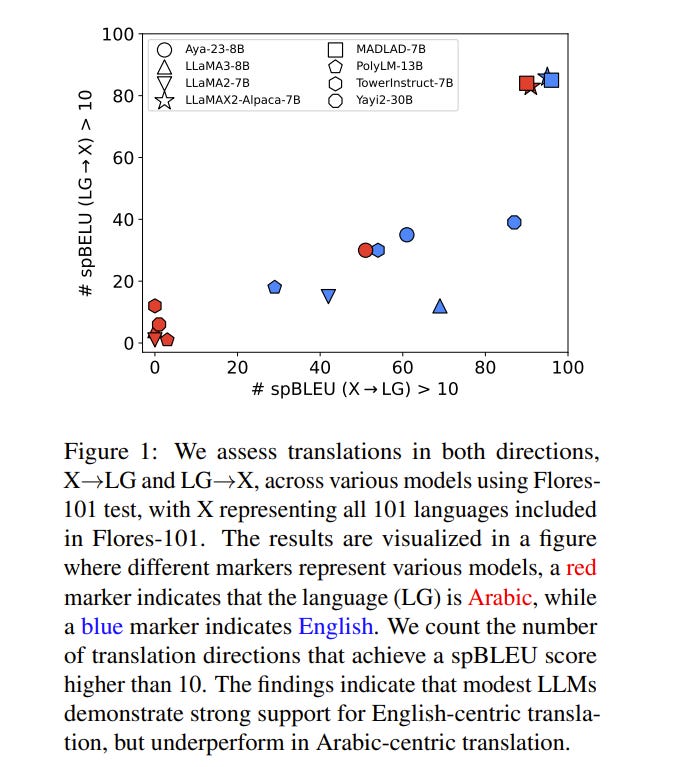
Large Language Models~(LLMs) demonstrate remarkable translation capabilities in high-resource language tasks, yet their performance in low-resource languages is hindered by insufficient multilingual data during pre-training.
To address this, we dedicate 35,000 A100-SXM4–80GB GPU hours to conducting extensive multilingual continual pre-training on the LLaMA series models, enabling translation support across more than 100 languages.
Through a comprehensive analysis of training strategies, such as vocabulary expansion and data augmentation, we develop LLaMAX. Remarkably, without sacrificing its generalization ability, LLaMAX achieves significantly higher translation performance compared to existing open-source LLMs~(by more than 10 spBLEU points) and performs on-par with specialized translation model~(M2M-100–12B) on the Flores-101 benchmark. Extensive experiments indicate that LLaMAX can serve as a robust multilingual foundation model.
1.3. GTA: A Benchmark for General Tool Agents

Significant focus has been placed on integrating large language models (LLMs) with various tools in developing general-purpose agents. This poses a challenge to LLMs’ tool-use capabilities. However, there are evident gaps between existing tool-use evaluations and real-world scenarios.
Current evaluations often use AI-generated queries, single-step tasks, dummy tools, and text-only interactions, failing to reveal the agents’ real-world problem-solving abilities effectively.
To address this, we propose GTA, a benchmark for General Tool Agents, featuring three main aspects:
Real user queries: human-written queries with simple real-world objectives but implicit tool-use, requiring the LLM to reason the suitable tools and plan the solution steps.
Real deployed tools: an evaluation platform equipped with tools across perception, operation, logic, and creativity categories to evaluate the agents’ actual task execution performance.
Real multimodal inputs: authentic image files, such as spatial scenes, web page screenshots, tables, code snippets, and printed/handwritten materials, used as the query contexts to align with real-world scenarios closely. We design 229 real-world tasks and executable tool chains to evaluate mainstream LLMs.
Our findings show that real-world user queries are challenging for existing LLMs, with GPT-4 completing less than 50% of the tasks and most LLMs achieving below 25%.
This evaluation reveals the bottlenecks in the tool-use capabilities of current LLMs in real-world scenarios, which provides future direction for advancing general-purpose tool agents.
1.4. TheoremLlama: Transforming General-Purpose LLMs into Lean4 Experts
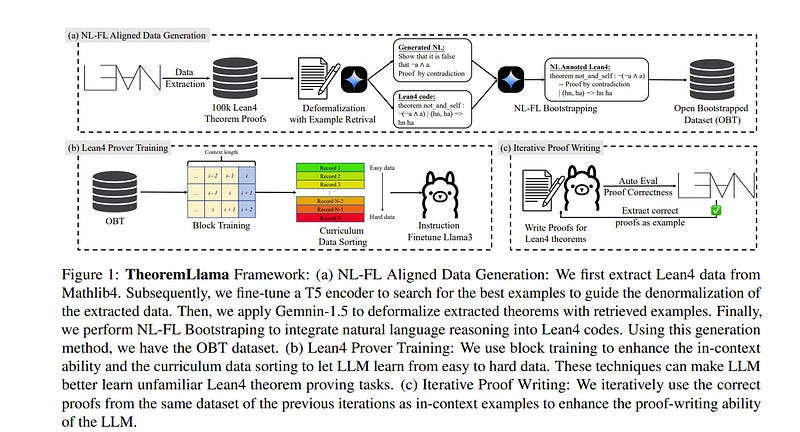
Proving mathematical theorems using computer-verifiable formal languages like Lean significantly impacts mathematical reasoning. One approach to formal theorem proving involves generating complete proofs using Large Language Models (LLMs) based on Natural Language (NL) proofs.
Similar methods have shown promising results in code generation. However, most modern LLMs exhibit suboptimal performance due to the scarcity of aligned NL and Formal Language (FL) theorem-proving data.
This scarcity results in a paucity of methodologies for training LLMs and techniques to fully utilize their capabilities in composing formal proofs. To address the challenges, this paper proposes TheoremLlama, an end-to-end framework to train a general-purpose LLM to become a Lean4 expert.
This framework encompasses NL-FL aligned dataset generation methods, training approaches for the LLM formal theorem prover, and techniques for LLM Lean4 proof writing.
Using the dataset generation method, we provide Open Bootstrapped Theorems (OBT), an NL-FL aligned and bootstrapped dataset. A key innovation in this framework is the NL-FL bootstrapping method, where NL proofs are integrated into Lean4 code for training datasets, leveraging the NL reasoning ability of LLMs for formal reasoning.
The TheoremLlama framework achieves cumulative accuracies of 36.48% and 33.61% on MiniF2F-Valid and Test datasets respectively, surpassing the GPT-4 baseline of 22.95% and 25.41%. We have also open-sourced our model checkpoints and generated dataset, and will soon make all the code publicly available.
1.5. SEED-Story: Multimodal Long Story Generation with Large Language Model

With the remarkable advancements in image generation and open-form text generation, the creation of interleaved image-text content has become an increasingly intriguing field.
Multimodal story generation, characterized by producing narrative texts and vivid images in an interleaved manner, has emerged as a valuable and practical task with broad applications.
However, this task poses significant challenges, as it necessitates the comprehension of the complex interplay between texts and images, and the ability to generate long sequences of coherent, contextually relevant texts and visuals. In this work, we propose SEED-Story, a novel method that leverages a Multimodal Large Language Model (MLLM) to generate extended multimodal stories.
Our model, built upon the powerful comprehension capability of MLLM, predicts text tokens as well as visual tokens, which are subsequently processed with an adapted visual de-tokenizer to produce images with consistent characters and styles.
We further propose a multimodal attention sink mechanism to enable the generation of stories with up to 25 sequences (only 10 for training) in a highly efficient autoregressive manner.
Additionally, we present a large-scale and high-resolution dataset named StoryStream to train our model and quantitatively evaluate the task of multimodal story generation in various aspects.
1.6. Stark: Social Long-Term Multi-Modal Conversation with Persona Commonsense Knowledge

Humans share a wide variety of images related to their personal experiences within conversations via instant messaging tools. However, existing works focus on
Image-sharing behavior in singular sessions leads to limited long-term social interaction
A lack of personalized image-sharing behavior.
In this work, we introduce Stark, a large-scale long-term multi-modal conversation dataset that covers a wide range of social personas in a multi-modality format, time intervals, and images.
To construct Stark automatically, we propose a novel multi-modal contextualization framework, Mcu, that generates long-term multi-modal dialogue distilled from ChatGPT and our proposed Plan-and-Execute image aligner.
Using our Stark, we train a multi-modal conversation model, Ultron 7B, which demonstrates impressive visual imagination ability. Furthermore, we demonstrate the effectiveness of our dataset in human evaluation. We make our source code and dataset publicly available.
View arXiv pageView PDFAdd to collection
2. LLM Training, Evaluation & Inference
2.1. HEMM: Holistic Evaluation of Multimodal Foundation Models

Multimodal foundation models that can holistically process text alongside images, video, audio, and other sensory modalities are increasingly used in a variety of real-world applications.
However, it is challenging to characterize and study progress in multimodal foundation models, given the range of possible modeling decisions, tasks, and domains.
In this paper, we introduce a Holistic Evaluation of Multimodal Models (HEMM) to systematically evaluate the capabilities of multimodal foundation models across a set of 3 dimensions: basic skills, information flow, and real-world use cases.
Basic multimodal skills are internal abilities required to solve problems, such as learning interactions across modalities, fine-grained alignment, multi-step reasoning, and the ability to handle external knowledge. Information flow studies how multimodal content changes during a task through querying, translation, editing, and fusion.
Use cases span domain-specific challenges introduced in real-world multimedia, affective computing, natural sciences, healthcare, and human-computer interaction applications.
Through comprehensive experiments across the 30 tasks in HEMM, they
Identify key dataset dimensions (e.g., basic skills, information flows, and use cases) that pose challenges to today’s models
Distill performance trends regarding how different modeling dimensions (e.g., scale, pre-training data, multimodal alignment, pre-training, and instruction tuning objectives) influence performance.
The conclusions regarding challenging multimodal interactions use cases, and tasks requiring reasoning and external knowledge, the benefits of data and model scale, and the impacts of instruction tuning yield actionable insights for future work in multimodal foundation models.
2.2. On Leakage of Code Generation Evaluation Datasets

In this paper, we consider contamination by code generation test sets, in particular in their use in modern large language models. We discuss three possible sources of such contamination and show findings supporting each of them:
Direct data leakage,
Indirect data leakage through the use of synthetic data
Overfitting to evaluation sets during model selection.
3. LLM Fine-Tuning
3.1. InverseCoder: Unleashing the Power of Instruction-Tuned Code LLMs with Inverse-Instruct

Recent advancements in open-source code large language models (LLMs) have demonstrated remarkable coding abilities by fine-tuning the data generated from powerful closed-source LLMs such as GPT-3.5 and GPT-4 for instruction tuning.
This paper explores how to further improve an instruction-tuned code LLM by generating data from itself rather than querying closed-source LLMs. Our key observation is the misalignment between the translation of formal and informal languages: translating formal language (i.e., code) to informal language (i.e., natural language) is more straightforward than the reverse.
Based on this observation, we propose INVERSE-INSTRUCT, which summarizes instructions from code snippets instead of the reverse. Specifically, given an instruction-tuning corpus for code and the resulting instruction-tuned code LLM, we ask the code LLM to generate additional high-quality instructions for the original corpus through code summarization and self-evaluation.
Then, we fine-tune the base LLM by combining the original corpus and the self-generated one, which yields a stronger instruction-tuned LLM. We present a series of code LLMs named InverseCoder, which surpasses the performance of the original code LLMs on a wide range of benchmarks, including Python text-to-code generation, multilingual coding, and data-science code generation.
3.2. AgentInstruct: Toward Generative Teaching with Agentic Flows

Synthetic data is becoming increasingly important for accelerating the development of language models, both large and small. Despite several successful use cases, researchers also raised concerns about model collapse and the drawbacks of imitating other models.
This discrepancy can be attributed to the fact that synthetic data varies in quality and diversity. Effective use of synthetic data usually requires significant human effort in curating the data.
We focus on using synthetic data for post-training, specifically creating data by powerful models to teach a new skill or behavior to another model, we refer to this setting as Generative Teaching.
We introduce AgentInstruct, an extensible agentic framework for automatically creating large amounts of diverse and high-quality synthetic data. AgentInstruct can create both the prompts and responses, using only raw data sources like text documents and code files as seeds.
We demonstrate the utility of AgentInstruct by creating a post-training dataset of 25M pairs to teach language models different skills, such as text editing, creative writing, tool usage, coding, reading comprehension, etc.
The dataset can be used for instruction tuning of any base model. We post-train Mistral-7b with the data. When comparing the resulting model Orca-3 to Mistral-7b-Instruct (which uses the same base model), we observe significant improvements across many benchmarks.
For example, 40% improvement on AGIEval, 19% improvement on MMLU, 54% improvement on GSM8K, 38% improvement on BBH, and 45% improvement on AlpacaEval. Additionally, it consistently outperforms other models such as LLAMA-8B-instruct and GPT-3.5-turbo.
4. LLM Quantization
4.1. Inference Performance Optimization for Large Language Models on CPUs
Large language models (LLMs) have shown exceptional performance and vast potential across diverse tasks. However, the deployment of LLMs with high performance in low-resource environments has garnered significant attention in the industry.
When GPU hardware resources are limited, we can explore alternative options on CPUs. To mitigate the financial burden and alleviate constraints imposed by hardware resources, optimizing inference performance is necessary. In this paper, we introduce an easily deployable inference performance optimization solution aimed at accelerating LLMs on CPUs.
In this solution, we implement an effective way to reduce the KV cache size while ensuring precision. We propose a distributed inference optimization approach and implement it based on oneAPI Collective Communications Library.
Furthermore, we propose optimization approaches for LLMs on CPU and conduct tailored optimizations for the most commonly used models.
5. LLM Reasoning
5.1. ChartGemma: Visual Instruction-tuning for Chart Reasoning in the Wild

Given the ubiquity of charts as a data analysis, visualization, and decision-making tool across industries and sciences, there has been a growing interest in developing pre-trained foundation models as well as general-purpose instruction-tuned models for chart understanding and reasoning.
However, existing methods suffer crucial drawbacks across two critical axes affecting the performance of chart representation models: they are trained on data generated from underlying data tables of the charts, ignoring the visual trends and patterns in chart images, and use weakly aligned vision-language backbone models for domain-specific training, limiting their generalizability when encountering charts in the wild.
We address these important drawbacks and introduce ChartGemma, a novel chart understanding and reasoning model developed over PaliGemma. Rather than relying on underlying data tables, ChartGemma is trained on instruction-tuning data generated directly from chart images, thus capturing both high-level trends and low-level visual information from a diverse set of charts.
Our simple approach achieves state-of-the-art results across 5 benchmarks spanning chart summarization, question answering, and fact-checking, and our elaborate qualitative studies on real-world charts show that ChartGemma generates more realistic and factually correct summaries compared to its contemporaries.
5.2. Is Your Model Really A Good Math Reasoner? Evaluating Mathematical Reasoning with Checklist

Exceptional mathematical reasoning ability is one of the key features that demonstrate the power of large language models (LLMs). How to comprehensively define and evaluate the mathematical abilities of LLMs, and even reflect the user experience in real-world scenarios, has emerged as a critical issue.
Current benchmarks predominantly concentrate on problem-solving capabilities, which presents a substantial risk of model overfitting and fails to accurately represent genuine mathematical reasoning abilities. In this paper, we argue that if a model really understands a problem, it should be robustly and readily applied across a diverse array of tasks.
Motivated by this, we introduce MATHCHECK, a well-designed checklist for testing task generalization and reasoning robustness, as well as an automatic tool to generate checklists efficiently.
MATHCHECK includes multiple mathematical reasoning tasks and robustness test types to facilitate a comprehensive evaluation of both mathematical reasoning ability and behavior testing.
Utilizing MATHCHECK, we develop MATHCHECK-GSM and MATHCHECK-GEO to assess mathematical textual reasoning and multi-modal reasoning capabilities, respectively, serving as upgraded versions of benchmarks including GSM8k, GeoQA, UniGeo, and Geometry3K.
We adopt MATHCHECK-GSM and MATHCHECK-GEO to evaluate over 20 LLMs and 11 MLLMs, assessing their comprehensive mathematical reasoning abilities.
Our results demonstrate that while frontier LLMs like GPT-4o continue to excel in various abilities on the checklist, many other model families exhibit a significant decline.
Further experiments indicate that, compared to traditional math benchmarks, MATHCHECK better reflects true mathematical abilities and represents mathematical intelligence more linearly, thereby supporting our design. On our MATHCHECK, we can easily conduct detailed behavior analysis to deeply investigate models.
5.3. Self-Recognition in Language Models
A rapidly growing number of applications rely on a small set of closed-source language models (LMs). This dependency might introduce novel security risks if LMs develop self-recognition capabilities. Inspired by human identity verification methods, we propose a novel approach for assessing self-recognition in LMs using model-generated “security questions”.
Our test can be externally administered to keep track of frontier models as it does not require access to internal model parameters or output probabilities. We use our test to examine self-recognition in ten of the most capable open- and closed-source LMs currently publicly available.
Our extensive experiments found no empirical evidence of general or consistent self-recognition in any examined LM. Instead, our results suggest that given a set of alternatives, LMs seek to pick the “best” answer, regardless of its origin.
Moreover, we find indications that preferences about which models produce the best answers are consistent across LMs. We additionally uncover novel insights on position bias considerations for LMs in multiple-choice settings.
5.4. Skywork-Math: Data Scaling Laws for Mathematical Reasoning in Large Language Models — The Story Goes On
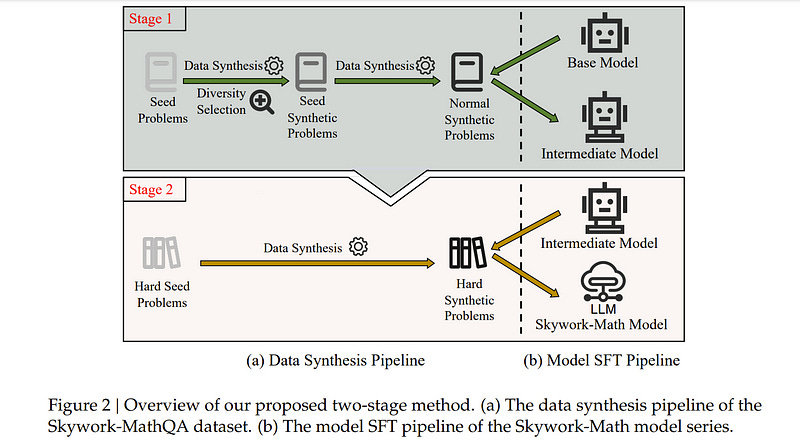
In this paper, we investigate the underlying factors that potentially enhance the mathematical reasoning capabilities of large language models (LLMs). We argue that the data scaling law for math reasoning capabilities in modern LLMs is far from being saturated, highlighting how the model’s quality improves with increases in data quantity.
To support this claim, we introduce the Skywork-Math model series, supervised fine-tuned (SFT) on common 7B LLMs using our proposed 2.5M-instance Skywork-MathQA dataset. Skywork-Math 7B has achieved impressive accuracies of 51.2% on the competition-level MATH benchmark and 83.9% on the GSM8K benchmark using only SFT data, outperforming an early version of GPT-4 on MATH.
The superior performance of Skywork-Math models contributes to our novel two-stage data synthesis and model SFT pipelines, which include three different augmentation methods and a diverse seed problem set, ensuring both the quantity and quality of the Skywork-MathQA dataset across varying difficulty levels.
Most importantly, we provide several practical takeaways to enhance math reasoning abilities in LLMs for both research and industry applications.
6. LLM Safety & Alignment
6.1. Safe Unlearning: A Surprisingly Effective and Generalizable Solution to Defend Against Jailbreak Attacks

LLMs are known to be vulnerable to jailbreak attacks, even after safety alignment. An important observation is that, while different types of jailbreak attacks can generate significantly different queries, they mostly result in similar responses that are rooted in the same harmful knowledge (e.g., detailed steps to make a bomb).
Therefore, we conjecture that directly unlearning the harmful knowledge in the LLM can be a more effective way to defend against jailbreak attacks than the mainstream supervised fine-tuning (SFT) based approaches.
Our extensive experiments confirmed our insight and suggested the surprising generalizability of our unlearning-based approach: using only 20 raw harmful questions without any jailbreak prompt during training, our solution reduced the Attack Success Rate (ASR) in Vicuna-7B on out-of-distribution (OOD) harmful questions wrapped with various complex jailbreak prompts from 82.6\% to 7.7\%.
This significantly outperforms Llama2–7B-Chat, which is fine-tuned on about 0.1M safety alignment samples but still has an ASR of 21.9\% even with the help of an additional safety system prompt.
Further analysis reveals that the generalization ability of our solution stems from the intrinsic relatedness among harmful responses across harmful questions (e.g., response patterns, shared steps and actions, and similarity among their learned representations in the LLM).
7. Transformers & Attention Models
7.1. Associative Recurrent Memory Transformer
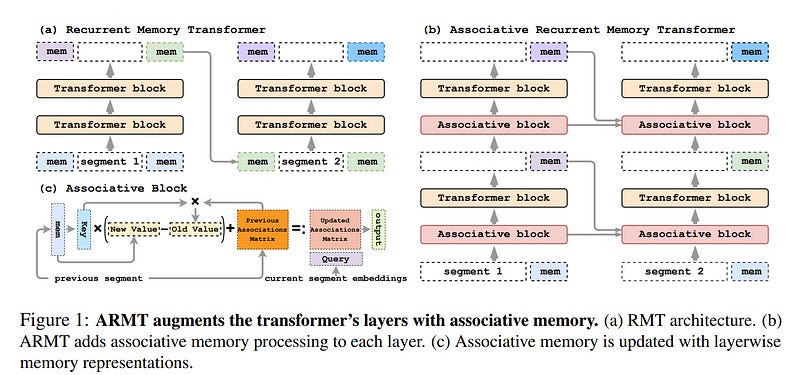
This paper addresses the challenge of creating a neural architecture for very long sequences that require constant time for processing new information at each time step.
Our approach, Associative Recurrent Memory Transformer (ARMT), is based on transformer self-attention for local context and segment-level recurrence for storage of task-specific information distributed over a long context.
We demonstrate that ARMT outperforms existing alternatives in associative retrieval tasks and sets a new performance record in the recent BABILong multi-task long-context benchmark by answering single-fact questions over 50 million tokens with an accuracy of 79.9%.
8. LLM Agents
8.1. AriGraph: Learning Knowledge Graph World Models with Episodic Memory for LLM Agents
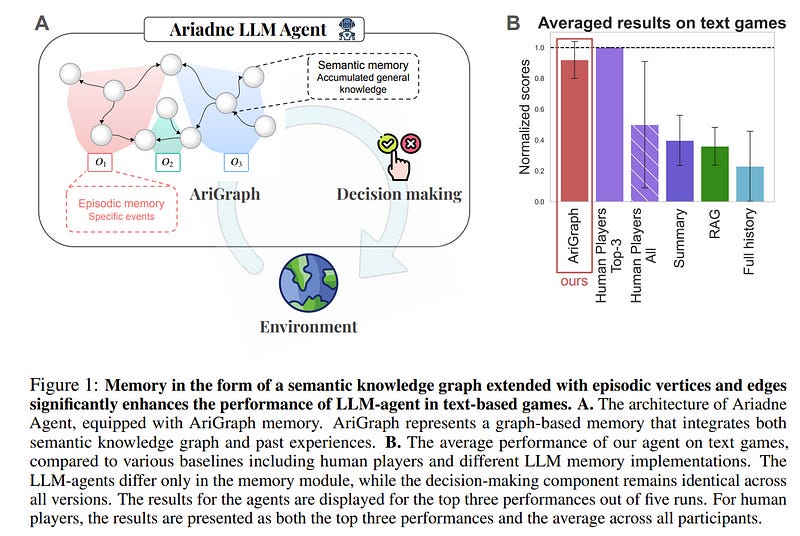
Advancements in generative AI have broadened the potential applications of Large Language Models (LLMs) in the development of autonomous agents. Achieving true autonomy requires accumulating and updating knowledge gained from interactions with the environment and effectively utilizing it.
Current LLM-based approaches leverage past experiences using a full history of observations, summarization, or retrieval augmentation. However, these unstructured memory representations do not facilitate the reasoning and planning essential for complex decision-making.
In our study, we introduce AriGraph, a novel method wherein the agent constructs a memory graph that integrates semantic and episodic memories while exploring the environment.
This graph structure facilitates efficient associative retrieval of interconnected concepts, relevant to the agent’s current state and goals, thus serving as an effective environmental model that enhances the agent’s exploratory and planning capabilities.
We demonstrate that our Ariadne LLM agent, equipped with this proposed memory architecture augmented with planning and decision-making, effectively handles complex tasks on a zero-shot basis in the TextWorld environment.
Our approach markedly outperforms established methods such as full-history, summarization, and Retrieval-Augmented Generation in various tasks, including the cooking challenge from the First TextWorld Problems competition and novel tasks like house cleaning and puzzle Treasure Hunting.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
