


Important LLMs Papers for the from 19/08 to 25/08
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Third Week of August 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Training, Evaluation & Inference
LLM Fine-Tuning
LLM Quantization & Alignment
LLM Reasoning
LLM Safety & Alignment
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. LLM Progress & Benchmarking
1.1. xGen-MM (BLIP-3): A Family of Open Large Multimodal Models

This report introduces xGen-MM (also known as BLIP-3), a framework for developing Large Multimodal Models (LMMs). The framework comprises meticulously curated datasets, a training recipe, model architectures, and a resulting suite of LMMs.
xGen-MM, short for xGen-MultiModal, expands the Salesforce xGen initiative on foundation AI models. Our models undergo rigorous evaluation across a range of tasks, including both single and multi-image benchmarks. Our pre-trained base model exhibits strong in-context learning capabilities and the instruction-tuned model demonstrates competitive performance among open-source LMMs with similar model sizes.
In addition, we introduce a safety-tuned model with DPO, aiming to mitigate harmful behaviors such as hallucinations and improve safety. We open-source our models, curated large-scale datasets, and our fine-tuning codebase to facilitate further advancements in LMM research. Associated resources will be available on our project page above.
1.2. Authorship Attribution in the Era of LLMs: Problems, Methodologies, and Challenges

Accurate attribution of authorship is crucial for maintaining the integrity of digital content, improving forensic investigations, and mitigating the risks of misinformation and plagiarism.
Addressing the imperative need for proper authorship attribution is essential to uphold the credibility and accountability of authentic authorship. The rapid advancements of Large Language Models (LLMs) have blurred the lines between human and machine authorship, posing significant challenges for traditional methods.
We present a comprehensive literature review that examines the latest research on authorship attribution in the era of LLMs. This survey systematically explores the landscape of this field by categorizing four representative problems:
Human-written Text Attribution
LLM-generated Text Detection
LLM-generated Text Attribution
Human-LLM Co-authored Text Attribution.
We also discuss the challenges related to ensuring the generalization and explainability of authorship attribution methods. Generalization requires the ability to generalize across various domains, while explainability emphasizes providing transparent and understandable insights into the decisions made by these models.
By evaluating the strengths and limitations of existing methods and benchmarks, we identify key open problems and future research directions in this field. This literature review serves as a roadmap for researchers and practitioners interested in understanding the state of the art in this rapidly evolving field.
1.3. TableBench: A Comprehensive and Complex Benchmark for Table Question Answering

Recent advancements in Large Language Models (LLMs) have markedly enhanced the interpretation and processing of tabular data, introducing previously unimaginable capabilities.
Despite these achievements, LLMs still encounter significant challenges when applied in industrial scenarios, particularly due to the increased complexity of reasoning required with real-world tabular data, underscoring a notable disparity between academic benchmarks and practical applications.
To address this discrepancy, we conduct a detailed investigation into the application of tabular data in industrial scenarios and propose a comprehensive and complex benchmark TableBench, including 18 fields within four major categories of table question answering (TableQA) capabilities.
Furthermore, we introduce TableLLM, trained on our meticulously constructed training set TableInstruct, achieving comparable performance with GPT-3.5.
Massive experiments conducted on TableBench indicate that both open-source and proprietary LLMs still have significant room for improvement to meet real-world demands, where the most advanced model, GPT-4, achieves only a modest score compared to humans.
1.4. Controllable Text Generation for Large Language Models: A Survey

In Natural Language Processing (NLP), Large Language Models (LLMs) have demonstrated high text generation quality. However, in real-world applications, LLMs must meet increasingly complex requirements.
Beyond avoiding misleading or inappropriate content, LLMs are also expected to cater to specific user needs, such as imitating particular writing styles or generating text with poetic richness.
These varied demands have driven the development of Controllable Text Generation (CTG) techniques, which ensure that outputs adhere to predefined control conditions — such as safety, sentiment, thematic consistency, and linguistic style — while maintaining high standards of helpfulness, fluency, and diversity.
This paper systematically reviews the latest advancements in CTG for LLMs, offering a comprehensive definition of its core concepts and clarifying the requirements for control conditions and text quality.
We categorize CTG tasks into two primary types: content control and attribute control. The key methods are discussed, including model retraining, fine-tuning, reinforcement learning, prompt engineering, latent space manipulation, and decoding-time intervention.
We analyze each method’s characteristics, advantages, and limitations, providing nuanced insights for achieving generation control. Additionally, we review CTG evaluation methods, summarize their applications across domains, and address key challenges in current research, including reduced fluency and practicality.
We also propose several appeals, such as placing greater emphasis on real-world applications in future research. This paper aims to offer valuable guidance to researchers and developers in the field.
1.5. Open-FinLLMs: Open Multimodal Large Language Models for Financial Applications

Large language models (LLMs) have advanced financial applications, yet they often lack sufficient financial knowledge and struggle with tasks involving multi-modal inputs like tables and time series data. To address these limitations, we introduce Open-FinLLMs, a series of Financial LLMs.
We begin with FinLLaMA, pre-trained on a 52 billion token financial corpus, incorporating text, tables, and time-series data to embed comprehensive financial knowledge.
FinLLaMA is then instruction fine-tuned with 573K financial instructions, resulting in FinLLaMA-instruct, which enhances task performance. Finally, we present FinLLaVA, a multimodal LLM trained with 1.43M image-text instructions to handle complex financial data types.
Extensive evaluations demonstrate FinLLaMA’s superior performance over LLaMA3–8B, LLaMA3.1–8B, and BloombergGPT in both zero-shot and few-shot settings across 19 and 4 datasets, respectively. FinLLaMA-instruct outperforms GPT-4 and other Financial LLMs on 15 datasets.
FinLLaVA excels in understanding tables and charts across 4 multimodal tasks. Additionally, FinLLaMA achieves impressive Sharpe Ratios in trading simulations, highlighting its robust financial application capabilities. We will continually maintain and improve our models and benchmarks to support ongoing innovation in academia and industry.
1.6. Show-o: One Single Transformer to Unify Multimodal Understanding and Generation

We present a unified transformer, i.e., Show-o, that unifies multimodal understanding and generation. Unlike fully autoregressive models, Show-o unifies autoregressive and (discrete) diffusion modeling to adaptively handle inputs and outputs of various and mixed modalities.
The unified model flexibly supports a wide range of vision-language tasks including visual question-answering, text-to-image generation, text-guided inpainting/extrapolation, and mixed-modality generation.
Across various benchmarks, it demonstrates comparable or superior performance to existing individual models with an equivalent or larger number of parameters tailored for understanding or generation. This significantly highlights its potential as a next-generation foundation model.
1.7. Jamba-1.5: Hybrid Transformer-Mamba Models at Scale

We present Jamba-1.5, new instruction-tuned large language models based on our Jamba architecture. Jamba is a hybrid Transformer-Mamba mixture of expert architecture, providing high throughput and low memory usage across context lengths while retaining the same or better quality as Transformer models.
We release two model sizes: Jamba-1.5-Large, with 94B active parameters, and Jamba-1.5-Mini, with 12B active parameters. Both models are fine-tuned for a variety of conversational and instruction-following capabilities and have an effective context length of 256K tokens, the largest amongst open-weight models.
To support cost-effective inference, we introduce ExpertsInt8, a novel quantization technique that allows fitting Jamba-1.5-Large on a machine with 8 80GB GPUs when processing 256K-token contexts without loss of quality.
When evaluated on a battery of academic and chatbot benchmarks, Jamba-1.5 models achieve excellent results while providing high throughput and outperforming other open-weight models on long-context benchmarks.
1.8. Hermes 3 Technical Report

Instruct (or “chat”) tuned models have become the primary way in which most people interact with large language models. As opposed to “base” or “foundation” models, instruct-tuned models are optimized to respond to imperative statements.
We present Hermes 3, a neutrally-aligned generalist instruct and tool use model with strong reasoning and creative abilities. Its largest version, Hermes 3 405B, achieves state-of-the-art performance among open-weight models on several public benchmarks.
2. LLM Fine-Tuning
2.1. Fine-tuning Large Language Models with Human-inspired Learning Strategies in Medical Question Answering
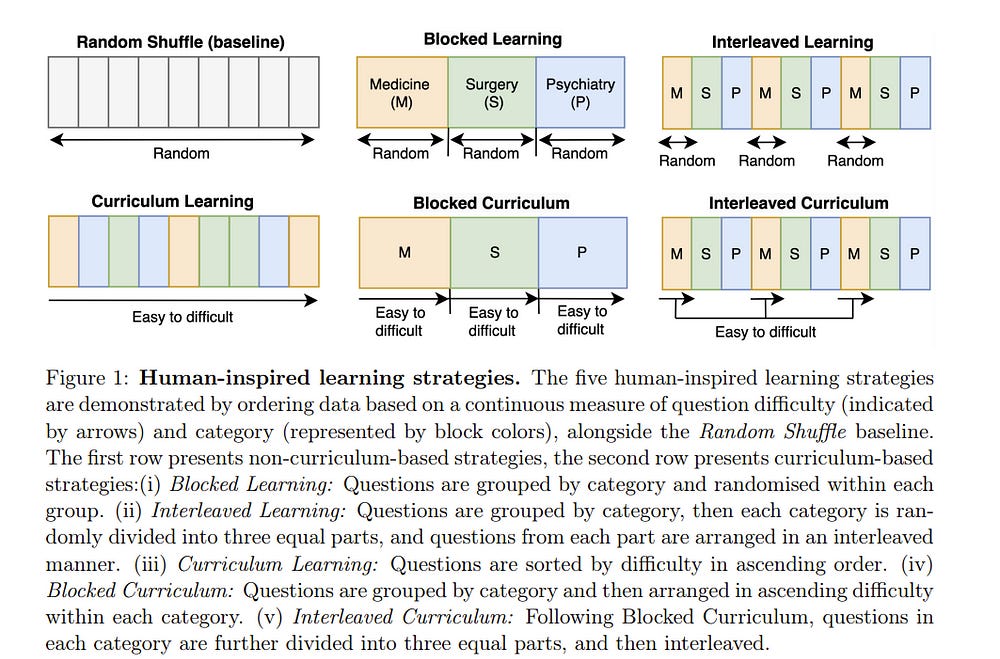
Training Large Language Models (LLMs) incurs substantial data-related costs, motivating the development of data-efficient training methods through optimized data ordering and selection.
Human-inspired learning strategies, such as curriculum learning, offer possibilities for efficient training by organizing data according to common human learning practices. Despite evidence that fine-tuning with curriculum learning improves the performance of LLMs for natural language understanding tasks, its effectiveness is typically assessed using a single model.
In this work, we extend previous research by evaluating both curriculum-based and non-curriculum-based learning strategies across multiple LLMs, using human-defined and automated data labels for medical question answering. Our results indicate a moderate impact of using human-inspired learning strategies for fine-tuning LLMs, with maximum accuracy gains of 1.77% per model and 1.81% per dataset.
Crucially, we demonstrate that the effectiveness of these strategies varies significantly across different model-dataset combinations, emphasizing that the benefits of a specific human-inspired strategy for fine-tuning LLMs do not generalize.
Additionally, we find evidence that curriculum learning using LLM-defined question difficulty outperforms human-defined difficulty, highlighting the potential of using model-generated measures for optimal curriculum design.
3. LLM Quantization & Optimization
3.1. LLM Pruning and Distillation in Practice: The Minitron Approach

We present a comprehensive report on compressing the Llama 3.1 8B and Mistral NeMo 12B models to 4B and 8B parameters, respectively, using pruning and distillation.
We explore two distinct pruning strategies: (1) depth pruning and (2) joint hidden/attention/MLP (width) pruning, and evaluate the results on common benchmarks from the LM Evaluation Harness. The models are then aligned with NeMo Aligner and tested in instruct-tuned versions.
This approach produces a compelling 4B model from Llama 3.1 8B and a state-of-the-art Mistral-NeMo-Minitron-8B (MN-Minitron-8B for brevity) model from Mistral NeMo 12B.
We found that with no access to the original data, it is beneficial to slightly fine-tune teacher models on the distillation dataset. We open-source our base model weights on Hugging Face with a permissive license.
3.2. FocusLLM: Scaling LLM’s Context by Parallel Decoding

Empowering LLMs with the ability to utilize useful information from a long context is crucial for many downstream applications. However, achieving long context lengths with the conventional transformer architecture requires substantial training and inference resources.
In this paper, we present FocusLLM, a framework designed to extend the context length of any decoder-only LLM, enabling the model to focus on relevant information from very long sequences. FocusLLM processes long text inputs by dividing them into chunks based on the model’s original context length to alleviate the issue of attention distraction.
Then, it appends the local context to each chunk as a prompt to extract essential information from each chunk based on a novel parallel decoding mechanism and ultimately integrates the extracted information into the local context.
FocusLLM stands out for great training efficiency and versatility: trained with an 8K input length with much less training cost than previous methods, FocusLLM exhibits superior performance across downstream long-context tasks and maintains strong language modeling ability when handling extensive long texts, even up to 400K tokens.
4. Tokenizers
4.1. PhysBERT: A Text Embedding Model for Physics Scientific Literature

The specialized language and complex concepts in physics pose significant challenges for information extraction through Natural Language Processing (NLP).
Central to effective NLP applications is the text embedding model, which converts text into dense vector representations for efficient information retrieval and semantic analysis. In this work, we introduce PhysBERT, the first physics-specific text embedding model.
Pre-trained on a curated corpus of 1.2 million arXiv physics papers and fine-tuned with supervised data, PhysBERT outperforms leading general-purpose models on physics-specific tasks including the effectiveness in fine-tuning for specific physics subdomains.
5. Retrieval-Augmented Generation (RAG)
5.1. Evidence-backed Fact Checking using RAG and Few-Shot In-Context Learning with LLMs
Given the widespread dissemination of misinformation on social media, implementing fact-checking mechanisms for online claims is essential. Manually verifying every claim is highly challenging, underscoring the need for an automated fact-checking system.
This paper presents our system designed to address this issue. We utilize the Averitec dataset to assess the veracity of claims. In addition to veracity prediction, our system provides supporting evidence, which is extracted from the dataset.
We develop a Retrieve and Generate (RAG) pipeline to extract relevant evidence sentences from a knowledge base, which are then inputted along with the claim into a large language model (LLM) for classification.
We also evaluate the few-shot In-Context Learning (ICL) capabilities of multiple LLMs. Our system achieves an ‘Averitec’ score of 0.33, which is a 22% absolute improvement over the baseline.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
