


Important LLM Papers for the Week From 05/04 to 11/05
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the First Week of May 2025. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Technical Reports
LLM Reasoning
LLM Training & Fine-Tuning
Vision Language Models
LLM Evaluation
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. LLM Progress & Technical Reports
1.1. Voila: Voice-Language Foundation Models for Real-Time Autonomous Interaction and Voice Role-Play

A voice AI agent that blends seamlessly into daily life would interact with humans in an autonomous, real-time, and emotionally expressive manner. Rather than merely reacting to commands, it would continuously listen, reason, and respond proactively, fostering fluid, dynamic, and emotionally resonant interactions.
We introduce Voila, a family of large voice-language foundation models that make a step towards this vision. Voila moves beyond traditional pipeline systems by adopting a new end-to-end architecture that enables full-duplex, low-latency conversations while preserving rich vocal nuances such as tone, rhythm, and emotion.
It achieves a response latency of just 195 milliseconds, surpassing the average human response time. Its hierarchical multi-scale Transformer integrates the reasoning capabilities of large language models (LLMs) with powerful acoustic modeling, enabling natural, persona-aware voice generation, where users can simply write text instructions to define the speaker’s identity, tone, and other characteristics. Moreover, Voila supports over one million pre-built voices and efficient customization of new ones from brief audio samples as short as 10 seconds.
Beyond spoken dialogue, Voila is designed as a unified model for a wide range of voice-based applications, including automatic speech recognition (ASR), Text-to-Speech (TTS), and, with minimal adaptation, multilingual speech translation. Voila is fully open-sourced to support open research and accelerate progress toward next-generation human-machine interactions.
1.2. FormalMATH: Benchmarking Formal Mathematical Reasoning of Large Language Models

Formal mathematical reasoning remains a critical challenge for artificial intelligence, hindered by limitations of existing benchmarks in scope and scale.
To address this, we present FormalMATH, a large-scale Lean4 benchmark comprising 5,560 formally verified problems spanning from high-school Olympiad challenges to undergraduate-level theorems across diverse domains (e.g., algebra, applied mathematics, calculus, number theory, and discrete mathematics).
To mitigate the inefficiency of manual formalization, we introduce a novel human-in-the-loop autoformalization pipeline that integrates:
Specialized large language models (LLMs) for statement autoformalization
Multi-LLM semantic verification
Negation-based disproof filtering strategies using off-the-shelf LLM-based proofs.
This approach reduces expert annotation costs by retaining 72.09% of statements before manual verification while ensuring fidelity to the original natural-language problems.
Our evaluation of state-of-the-art LLM-based theorem provers reveals significant limitations: even the strongest models achieve only a 16.46% success rate under practical sampling budgets, exhibiting pronounced domain bias (e.g., excelling in algebra but failing in calculus) and over-reliance on simplified automation tactics.
Notably, we identify a counterintuitive inverse relationship between natural-language solution guidance and proof success in chain-of-thought reasoning scenarios, suggesting that human-written informal reasoning introduces noise rather than clarity in formal reasoning settings. We believe that FormalMATH provides a robust benchmark for benchmarking formal mathematical reasoning.
1.3. ZeroSearch: Incentivize the Search Capability of LLMs without Searching

Effective information searching is essential for enhancing the reasoning and generation capabilities of large language models (LLMs). Recent research has explored using reinforcement learning (RL) to improve LLMs’ search capabilities by interacting with live search engines in real-world environments.
While these approaches show promising results, they face two major challenges:
Uncontrolled Document Quality: The quality of documents returned by search engines is often unpredictable, introducing noise and instability into the training process.
Prohibitively High API Costs: RL training requires frequent rollouts, potentially involving hundreds of thousands of search requests, which incur substantial API expenses and severely constrain scalability.
To address these challenges, we introduce ZeroSearch, a reinforcement learning framework that incentivizes the search capabilities of LLMs without interacting with real search engines.
Our approach begins with lightweight supervised fine-tuning to transform the LLM into a retrieval module capable of generating both relevant and noisy documents in response to a query.
During RL training, we employ a curriculum-based rollout strategy that incrementally degrades the quality of generated documents, progressively eliciting the model’s reasoning ability by exposing it to increasingly challenging retrieval scenarios.
Extensive experiments demonstrate that ZeroSearch effectively incentivizes the search capabilities of LLMs using a 3B LLM as the retrieval module.
Remarkably, a 7B retrieval module achieves comparable performance to the real search engine, while a 14B retrieval module even surpasses it. Furthermore, it generalizes well across both base and instruction-tuned models of various parameter sizes and is compatible with a wide range of RL algorithms.
2. LLM Reasoning
2.1. Absolute Zero: Reinforced Self-play Reasoning with Zero Data
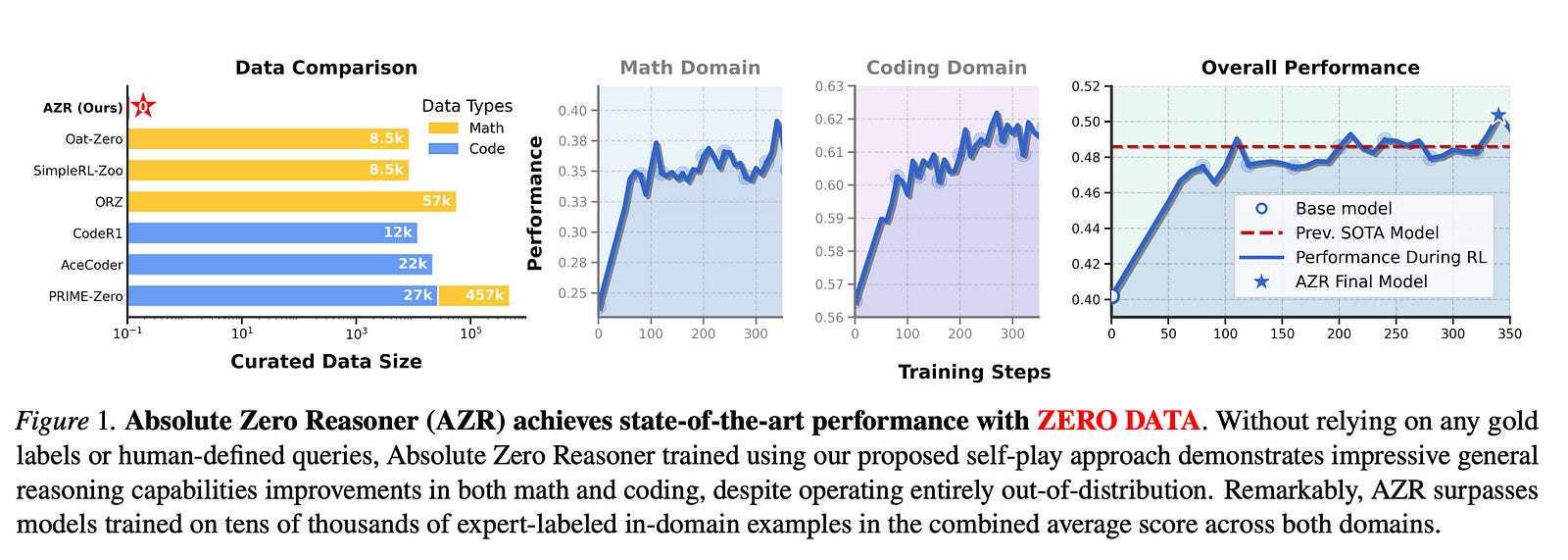
Reinforcement learning with verifiable rewards (RLVR) has shown promise in enhancing the reasoning capabilities of large language models by learning directly from outcome-based rewards.
Recent RLVR works that operate under the zero setting avoid supervision in labeling the reasoning process, but still depend on manually curated collections of questions and answers for training.
The scarcity of high-quality, human-produced examples raises concerns about the long-term scalability of relying on human supervision, a challenge already evident in the domain of language model pertaining.
Furthermore, in a hypothetical future where AI surpasses human intelligence, tasks provided by humans may offer limited learning potential for a superintelligent system.
To address these concerns, we propose a new RLVR paradigm called Absolute Zero, in which a single model learns to propose tasks that maximize its own learning progress and improve reasoning by solving them, without relying on any external data.
Under this paradigm, we introduce the Absolute Zero Reasoner (AZR), a system that self-evolves its training curriculum and reasoning ability by using a code executor to both validate proposed code reasoning tasks and verify answers, serving as a unified source of verifiable reward to guide open-ended yet grounded learning.
Despite being trained entirely without external data, AZR achieves overall SOTA performance on coding and mathematical reasoning tasks, outperforming existing zero-shot models that rely on tens of thousands of in-domain human-curated examples.
Furthermore, we demonstrate that AZR can be effectively applied across different model scales and is compatible with various model classes.
2.2. Perception, Reason, Think, and Plan: A Survey on Large Multimodal Reasoning Models

Reasoning lies at the heart of intelligence, shaping the ability to make decisions, draw conclusions, and generalize across domains. In artificial intelligence, as systems increasingly operate in open, uncertain, and multimodal environments, reasoning becomes essential for enabling robust and adaptive behavior.
Large Multimodal Reasoning Models (LMRMs) have emerged as a promising paradigm, integrating modalities such as text, images, audio, and video to support complex reasoning capabilities and aiming to achieve comprehensive perception, precise understanding, and deep reasoning.
As research advances, multimodal reasoning has rapidly evolved from modular, perception-driven pipelines to unified, language-centric frameworks that offer more coherent cross-modal understanding. While instruction tuning and reinforcement learning have improved model reasoning, significant challenges remain in omni-modal generalization, reasoning depth, and agentic behavior.
To address these issues, we present a comprehensive and structured survey of multimodal reasoning research, organized around a four-stage developmental roadmap that reflects the field’s shifting design philosophies and emerging capabilities.
First, we review early efforts based on task-specific modules, where reasoning was implicitly embedded across stages of representation, alignment, and fusion.
Next, we examine recent approaches that unify reasoning into multimodal LLMs, with advances such as Multimodal Chain-of-Thought (MCoT) and multimodal reinforcement learning enabling richer and more structured reasoning chains.
Finally, drawing on empirical insights from challenging benchmarks and experimental cases of OpenAI O3 and O4-mini, we discuss the conceptual direction of native large multimodal reasoning models (N-LMRMs), which aim to support scalable, agentic, and adaptive reasoning and planning in complex, real-world environments.
2.3. RM-R1: Reward Modeling as Reasoning
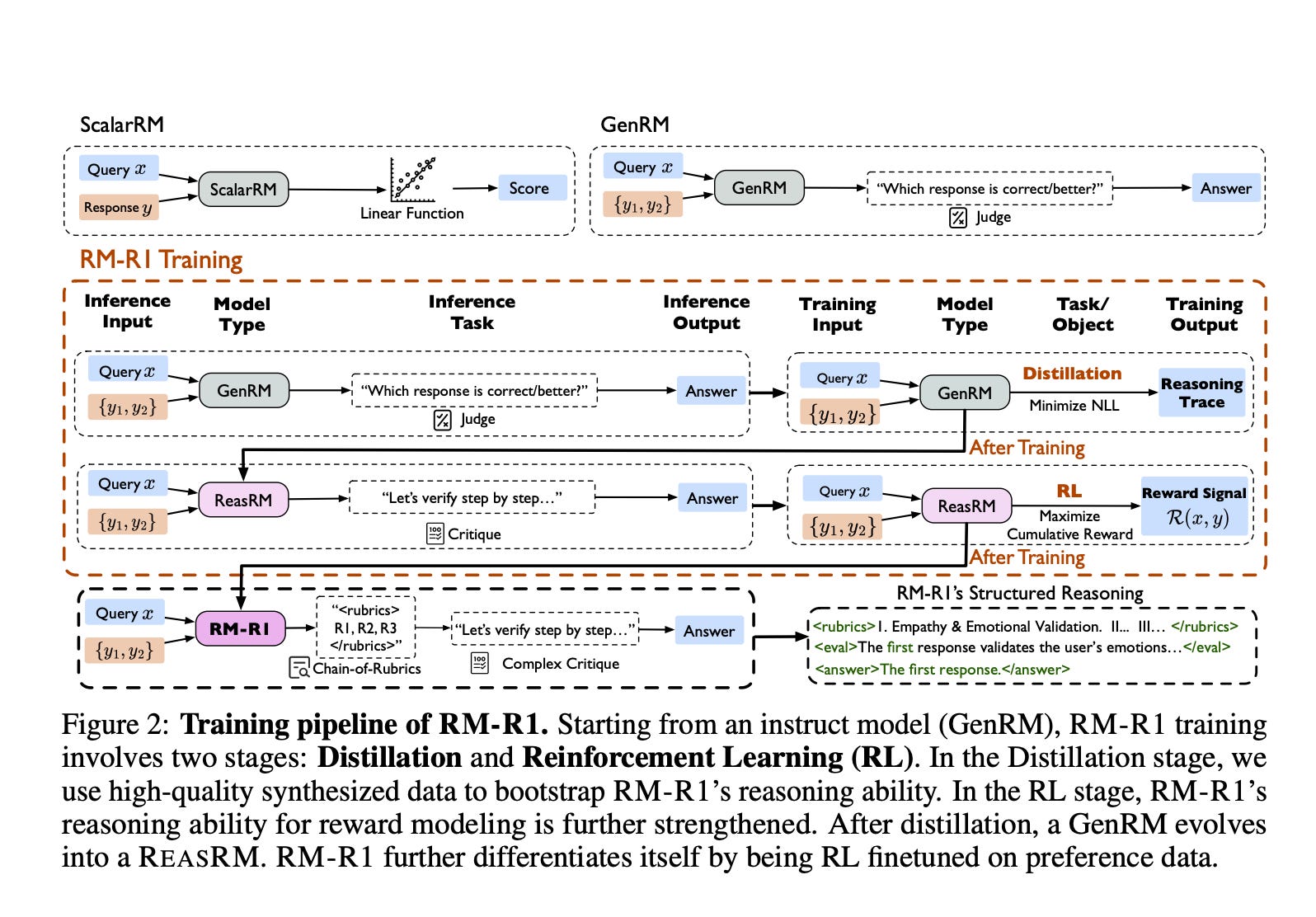
Reward modeling is essential for aligning large language models (LLMs) with human preferences, especially through reinforcement learning from human feedback (RLHF).
To provide accurate reward signals, a reward model (RM) should stimulate deep thinking and conduct interpretable reasoning before assigning a score or a judgment.
However, existing RMs either produce opaque scalar scores or directly generate the prediction of a preferred answer, making them struggle to integrate natural language critiques, thus lacking interpretability.
Inspired by recent advances of long chain-of-thought (CoT) on reasoning-intensive tasks, we hypothesize and validate that integrating reasoning capabilities into reward modeling significantly enhances RM’s interpretability and performance.
In this work, we introduce a new class of generative reward models — Reasoning Reward Models (ReasRMs) — which formulate reward modeling as a reasoning task.
We propose a reasoning-oriented training pipeline and train a family of ReasRMs, RM-R1. The training consists of two key stages:
Distillation of high-quality reasoning chains
Reinforcement learning with verifiable rewards. RM-R1 improves LLM rollouts by self-generating reasoning traces or chat-specific rubrics and evaluating candidate responses against them.
Empirically, our models achieve state-of-the-art or near state-of-the-art performance of generative RMs across multiple comprehensive reward model benchmarks, outperforming much larger open-weight models (e.g., Llama3.1–405B) and proprietary ones (e.g., GPT-4o) by up to 13.8%. Beyond final performance, we perform a thorough empirical analysis to understand the key ingredients of successful ReasRM training.
2.4. Llama-Nemotron: Efficient Reasoning Models

We introduce the Llama-Nemotron series of models, an open family of heterogeneous reasoning models that deliver exceptional reasoning capabilities, inference efficiency, and an open license for enterprise use.
The family comes in three sizes — Nano (8B), Super (49B), and Ultra (253B) — and performs competitively with state-of-the-art reasoning models such as DeepSeek-R1 while offering superior inference throughput and memory efficiency.
In this report, we discuss the training procedure for these models, which entails using neural architecture search from Llama 3 models for accelerated inference, knowledge distillation, and continued pretraining, followed by a reasoning-focused post-training stage consisting of two main parts: supervised fine-tuning and large scale reinforcement learning.
Llama-Nemotron models are the first open-source models to support a dynamic reasoning toggle, allowing users to switch between standard chat and reasoning modes during inference.
To further support open research and facilitate model development, we provide the following resources: 1. We release the Llama-Nemotron reasoning models — LN-Nano, LN-Super, and LN-Ultra — under the commercially permissive NVIDIA Open Model License Agreement. 2.
We release the complete post-training dataset: Llama-Nemotron-Post-Training-Dataset. 3. We also release our training codebases: NeMo, NeMo-Aligner, and Megatron-LM.
2.5. Grokking in the Wild: Data Augmentation for Real-World Multi-Hop Reasoning with Transformers
Transformers have achieved great success in numerous NLP tasks but continue to exhibit notable gaps in multi-step factual reasoning, especially when real-world knowledge is sparse.
Recent advances in grokking have demonstrated that neural networks can transition from memorizing to perfectly generalizing once they detect underlying logical patterns — yet these studies have primarily used small, synthetic tasks.
In this paper, for the first time, we extend grokking to real-world factual data and address the challenge of dataset sparsity by augmenting existing knowledge graphs with carefully designed synthetic data to raise the ratio phi_r of inferred facts to atomic facts above the threshold required for grokking.
Surprisingly, we find that even factually incorrect synthetic data can strengthen emergent reasoning circuits rather than degrade accuracy, as it forces the model to rely on relational structure rather than memorization. When evaluated on multi-hop reasoning benchmarks, our approach achieves up to 95–100% accuracy on 2WikiMultiHopQA — substantially improving over strong baselines and matching or exceeding current state-of-the-art results.
We further provide an in-depth analysis of how increasing phi_r drives the formation of generalizing circuits inside Transformers. Our findings suggest that grokking-based data augmentation can unlock implicit multi-hop reasoning capabilities, opening the door to more robust and interpretable factual reasoning in large-scale language models.
2.6. Agentic Reasoning and Tool Integration for LLMs via Reinforcement Learning

Large language models (LLMs) have achieved remarkable progress in complex reasoning tasks, yet they remain fundamentally limited by their reliance on static internal knowledge and text-only reasoning. Real-world problem solving often demands dynamic, multi-step reasoning, adaptive decision making, and the ability to interact with external tools and environments. In this work, we introduce ARTIST (Agentic Reasoning and Tool Integration in Self-improving Transformers), a unified framework that tightly couples agentic reasoning, reinforcement learning, and tool integration for LLMs. ARTIST enables models to autonomously decide when, how, and which tools to invoke within multi-turn reasoning chains, leveraging outcome-based RL to learn robust strategies for tool use and environment interaction without requiring step-level supervision. Extensive experiments on mathematical reasoning and multi-turn function calling benchmarks show that ARTIST consistently outperforms state-of-the-art baselines, with up to 22% absolute improvement over base models and strong gains on the most challenging tasks. Detailed studies and metric analyses reveal that agentic RL training leads to deeper reasoning, more effective tool use, and higher-quality solutions. Our results establish agentic RL with tool integration as a powerful new frontier for robust, interpretable, and generalizable problem-solving in LLMs.
3. LLM Training & Fine-Tuning
3.1. Flow-GRPO: Training Flow Matching Models via Online RL

We propose Flow-GRPO, the first method integrating online reinforcement learning (RL) into flow matching models. Our approach uses two key strategies:
An ODE-to-SDE conversion that transforms a deterministic Ordinary Differential Equation (ODE) into an equivalent Stochastic Differential Equation (SDE) that matches the original model’s marginal distribution at all timesteps, enabling statistical sampling for RL exploration.
A Denoising Reduction strategy that reduces training denoising steps while retaining the original inference timestep number, significantly improving sampling efficiency without performance degradation.
Empirically, Flow-GRPO is effective across multiple text-to-image tasks. For complex compositions, RL-tuned SD3.5 generates nearly perfect object counts, spatial relations, and fine-grained attributes, boosting GenEval accuracy from 63% to 95%.
In visual text rendering, its accuracy improves from 59% to 92%, significantly enhancing text generation. Flow-GRPO also achieves substantial gains in human preference alignment.
Notably, little to no reward hacking occurred, meaning rewards did not increase at the cost of image quality or diversity, and both remained stable in our experiments.
3.2. Unified Multimodal Chain-of-Thought Reward Model through Reinforcement Fine-Tuning

Recent advances in multimodal Reward Models (RMs) have shown significant promise in delivering reward signals to align vision models with human preferences.
However, current RMs are generally restricted to providing direct responses or engaging in shallow reasoning processes with limited depth, often leading to inaccurate reward signals.
We posit that incorporating explicit long chains of thought (CoT) into the reward reasoning process can significantly strengthen their reliability and robustness.
Furthermore, we believe that once RMs internalize CoT reasoning, their direct response accuracy can also be improved through implicit reasoning capabilities.
To this end, this paper proposes UnifiedReward-Think, the first unified multimodal CoT-based reward model, capable of multi-dimensional, step-by-step long-chain reasoning for both visual understanding and generation reward tasks.
Specifically, we adopt an exploration-driven reinforcement fine-tuning approach to elicit and incentivize the model’s latent complex reasoning ability:
We first use a small amount of image generation preference data to distill the reasoning process of GPT-4o, which is then used for the model’s cold start to learn the format and structure of CoT reasoning.
Subsequently, by leveraging the model’s prior knowledge and generalization capabilities, we prepare large-scale unified multimodal preference data to elicit the model’s reasoning process across various vision tasks. During this phase, correct reasoning outputs are retained for rejection sampling to refine the model.
While incorrectly predicted samples are finally used for Group Relative Policy Optimization (GRPO) based reinforcement fine-tuning, enabling the model to explore diverse reasoning paths and optimize for correct and robust solutions.
Extensive experiments across various vision reward tasks demonstrate the superiority of our model.
3.3. A Survey on Inference Engines for Large Language Models: Perspectives on Optimization and Efficiency

Large language models (LLMs) are widely applied in chatbots, code generators, and search engines. Workloads such as chain-of-thought, complex reasoning, and agent services significantly increase the inference cost by invoking the model repeatedly.
Optimization methods such as parallelism, compression, and caching have been adopted to reduce costs, but the diverse service requirements make it hard to select the right method.
Recently, specialized LLM inference engines have emerged as a key component for integrating optimization methods into service-oriented infrastructures. However, a systematic study on inference engines is still lacking. This paper provides a comprehensive evaluation of 25 open-source and commercial inference engines.
We examine each inference engine in terms of ease-of-use, ease-of-deployment, general-purpose support, scalability, and suitability for throughput- and latency-aware computation.
Furthermore, we explore the design goals of each inference engine by investigating the optimization techniques it supports. In addition, we assess the ecosystem maturity of open source inference engines and handle the performance and cost policy of commercial solutions.
We outline future research directions that include support for complex LLM-based services, support for various hardware, and enhanced security, offering practical guidance to researchers and developers in selecting and designing optimized LLM inference engines.
4. Vision Language Models
4.1. Unified Multimodal Understanding and Generation Models: Advances, Challenges, and Opportunities
Recent years have seen remarkable progress in both multimodal understanding models and image generation models. Despite their respective successes, these two domains have evolved independently, leading to distinct architectural paradigms:
While autoregressive-based architectures have dominated multimodal understanding, diffusion-based models have become the cornerstone of image generation.
Recently, there has been growing interest in developing unified frameworks that integrate these tasks. The emergence of GPT-4o’s new capabilities exemplifies this trend, highlighting the potential for unification.
However, the architectural differences between the two domains pose significant challenges. To provide a clear overview of current efforts toward unification, we present a comprehensive survey aimed at guiding future research.
First, we introduce the foundational concepts and recent advancements in multimodal understanding and text-to-image generation models. Next, we review existing unified models, categorizing them into three main architectural paradigms: diffusion-based, autoregressive-based, and hybrid approaches that fuse autoregressive and diffusion mechanisms.
For each category, we analyze the structural designs and innovations introduced by related works. Additionally, we compile datasets and benchmarks tailored for unified models, offering resources for future exploration.
Finally, we discuss the key challenges facing this nascent field, including tokenization strategy, cross-modal attention, and data. As this area is still in its early stages, we anticipate rapid advancements and will regularly update this survey. Our goal is to inspire further research and provide a valuable reference for the community.
4.2. On Path to Multimodal Generalist: General-Level and General-Bench

The Multimodal Large Language Model (MLLM) is currently experiencing rapid growth, driven by the advanced capabilities of LLMs. Unlike earlier specialists, existing MLLMs are evolving towards a Multimodal Generalist paradigm.
Initially limited to understanding multiple modalities, these models have advanced to not only comprehend but also generate across modalities. Their capabilities have expanded from coarse-grained to fine-grained multimodal understanding and from supporting limited modalities to arbitrary ones.
While many benchmarks exist to assess MLLMs, a critical question arises: Can we simply assume that higher performance across tasks indicates a stronger MLLM capability, bringing us closer to human-level AI? We argue that the answer is not as straightforward as it seems.
This project introduces General-Level, an evaluation framework that defines 5-scale levels of MLLM performance and generality, offering a methodology to compare MLLMs and gauge the progress of existing systems towards more robust multimodal generalists and, ultimately, towards AGI.
At the core of the framework is the concept of Synergy, which measures whether models maintain consistent capabilities across comprehension and generation, and across multiple modalities.
To support this evaluation, we present General-Bench, which encompasses a broader spectrum of skills, modalities, formats, and capabilities, including over 700 tasks and 325,800 instances.
The evaluation results that involve over 100 existing state-of-the-art MLLMs uncover the capability rankings of generalists, highlighting the challenges in reaching genuine AI. We expect this project to pave the way for future research on next-generation multimodal foundation models, providing a robust infrastructure to accelerate the realization of AGI.
5. LLM Evaluation
5.1. Sentient Agent as a Judge: Evaluating Higher-Order Social Cognition in Large Language Models

Assessing how well a large language model (LLM) understands humans, rather than merely text, remains an open challenge. To bridge the gap, we introduce Sentient Agent as a Judge (SAGE), an automated evaluation framework that measures an LLM’s higher-order social cognition.
SAGE instantiates a Sentient Agent that simulates human-like emotional changes and inner thoughts during interaction, providing a more realistic evaluation of the tested model in multi-turn conversations.
At every turn, the agent reasons about (i) how its emotion changes, (ii) how it feels, and (iii) how it should reply, yielding a numerical emotion trajectory and interpretable inner thoughts.
Experiments on 100 supportive-dialogue scenarios show that the final Sentient emotion score correlates strongly with Barrett-Lennard Relationship Inventory (BLRI) ratings and utterance-level empathy metrics, validating psychological fidelity.
We also built a public Sentient Leaderboard covering 18 commercial and open-source models that uncovers substantial gaps (up to 4x) between frontier systems (GPT-4o-Latest, Gemini2.5-Pro) and earlier baselines, gaps not reflected in conventional leaderboards (e.g., Arena).
SAGE thus provides a principled, scalable, and interpretable tool for tracking progress toward genuinely empathetic and socially adept language agents.
Are you looking to start a career in data science and AI, but do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
