


Important LLM Papers for the Week From 28/07 to 02/08
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers must stay informed about the latest progress.
This article summarizes some of the most important LLM papers published during the Fourth Week of July 2025. The papers cover various topics that shape the next generation of language models, including model optimization and scaling, reasoning, benchmarking, and performance enhancement.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Technical Reports
LLM Reasoning
Post Training & Policy Optimization
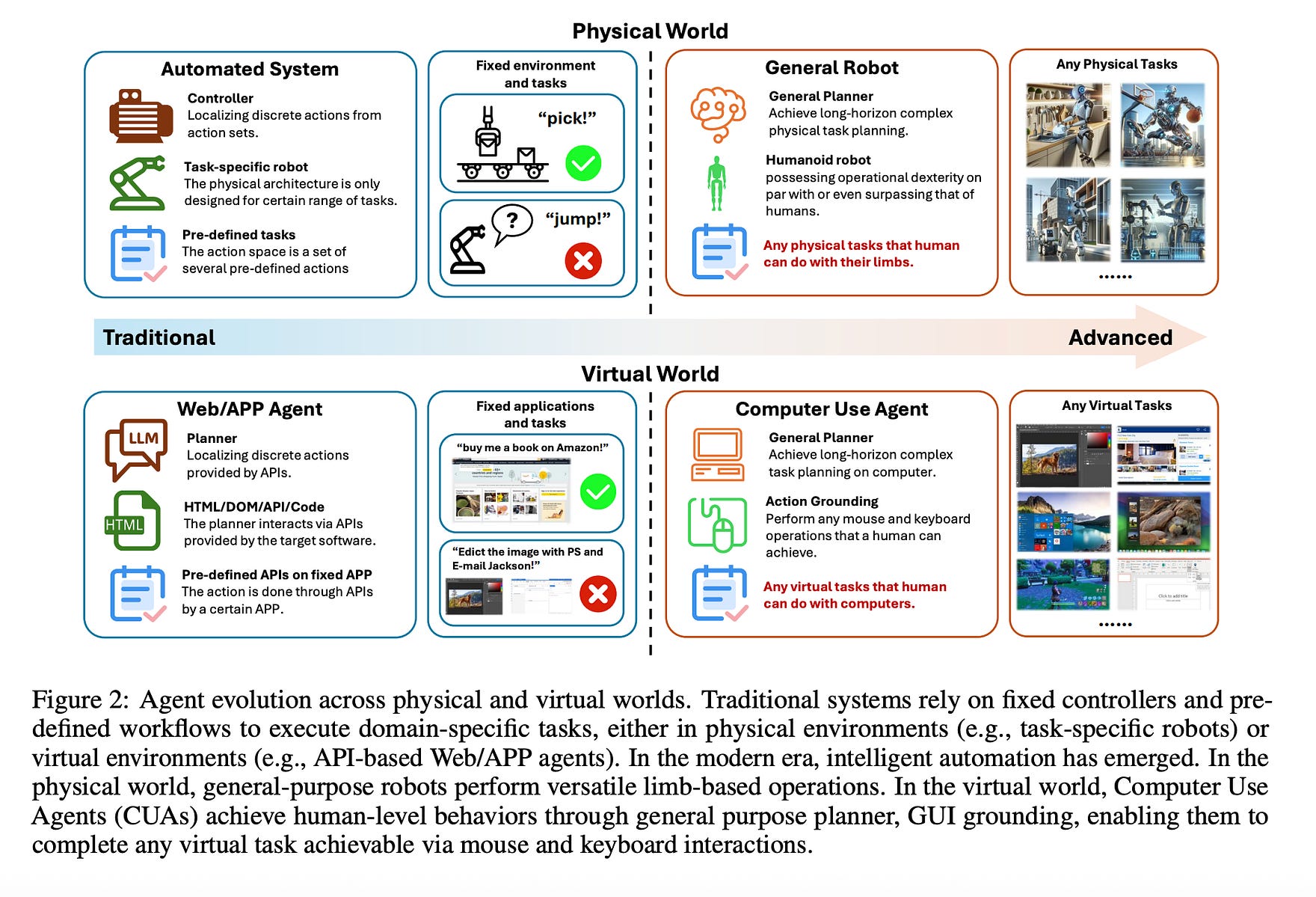
AI Agents
Get All My Books, One Button Away With 40% Off

I have created a bundle for my books and roadmaps, so you can buy everything with just one button and for 40% less than the original price. The bundle features 8 eBooks, including:
1. LLM Progress & Technical Reports
1.1. Phi-Ground Tech Report: Advancing Perception in GUI Grounding
The paper addresses a critical bottleneck in the development of Computer Use Agents (CUAs) — AI agents that can operate computers like a human, similar to Jarvis from “Iron Man”.
A core component for these agents is GUI Grounding: the ability to accurately connect a language instruction (e.g., “click the shapes button”) to a specific, clickable coordinate on a graphical user interface (GUI). Current models struggle with this, achieving less than 65% accuracy on challenging high-resolution benchmarks, making them unreliable for real-world deployment.
The Phi-Ground Solution
The authors conduct a deep empirical study into every aspect of training GUI grounding models and, based on their findings, develop the Phi-Ground family of models. Their primary approach is a two-stage process called the “Agent Setting”, which decouples complex reasoning from precise perception:
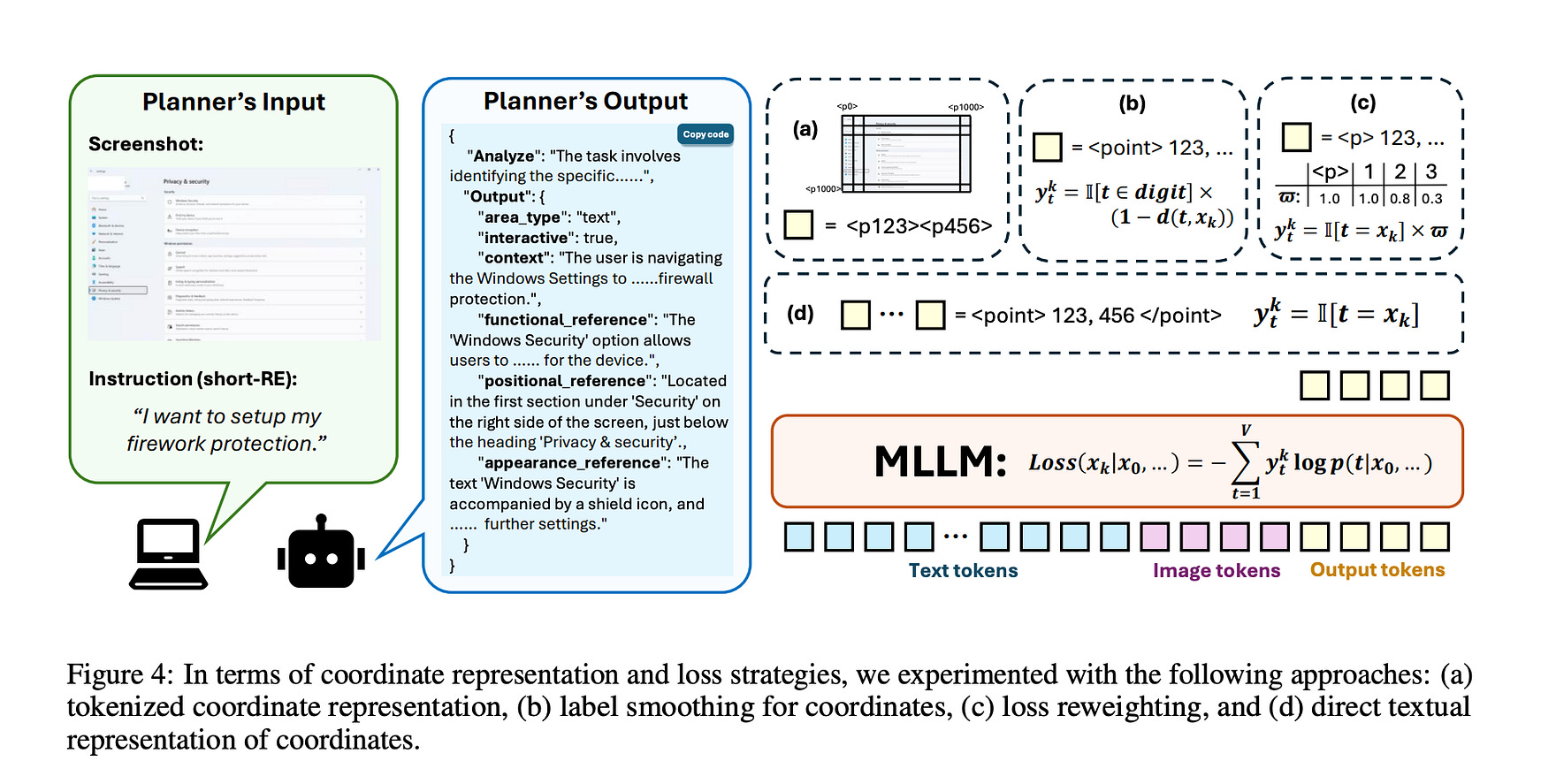
Planner (Advanced LLM): A powerful, large multimodal model (like GPT-4O) acts as a “planner.” It takes a simple user instruction and a screenshot, and generates a detailed, explicit textual description of the target element, called a Long Reference Expression (Long RE). This description includes functional, positional, and appearance details.
Grounder (Phi-Ground Model): The specialized Phi-Ground model then takes this detailed Long RE and the screenshot to perform the final, precise task of identifying the exact (x, y) coordinates for the action (e.g., a click).
Key Findings from the Empirical Study
The paper’s main contribution is a series of systematic experiments that challenge common assumptions and reveal best practices for training these models:
Input Modality Order Matters: Feeding the model text first, then the image, leads to significantly better performance. This makes the image processing “instruction-aware,” as the model knows what to look for before it even “sees” the image.
Simple is Better for Coordinates: The authors experimented with complex methods like tokenizing coordinates, label smoothing, and loss re-weighting. They found that the most effective and scalable approach was the simplest: representing coordinates as plain text (e.g., “123, 456”) and using a standard text generation loss.
Data Augmentation is Crucial for High Resolution: For high-resolution UIs where elements can be tiny, random resize (shrinking the UI image and placing it on a larger canvas) was a highly effective data augmentation technique that significantly improved performance.
Data Distribution is Key to Generalization: The researchers found that different data sources (web pages, desktop apps, mobile) have very different UI layout biases. To build a robust model, they created a massive 40M+ sample dataset from diverse sources (including CommonCrawl, Bing Image Search, and human-labeled data) and developed a resampling method to ensure a more uniform spatial distribution of UI elements.
Experimental Results
The Phi-Ground model family sets a new state-of-the-art across five different GUI grounding benchmarks.
Dominance in the Agent Setting: When used with a planner, the Phi-Ground models achieve the highest scores on all benchmarks, with standout results of 55.0% on ScreenSpot-pro and 36.2% on UI-Vision, significantly outperforming previous models.
SOTA in End-to-End Setting: Even when used as a single end-to-end model (without a separate planner), Phi-Ground achieves SOTA results on three of the five benchmarks, demonstrating its strong standalone perception capabilities.
Pareto Efficiency: The models are shown to be highly efficient, providing the best performance for a given amount of computational cost, making them a practical choice.
Conclusion and Broader Impact
The Phi-Ground tech report provides a comprehensive guide to building high-performance GUI grounding models. It demonstrates that through careful attention to data collection, distribution, and training methodology, it is possible to create specialized models that significantly advance the state of the art. This work is a critical step towards making Computer Use Agents more reliable and effective, while also offering valuable insights for other multimodal perception tasks.
Important Resources:
1.2. Falcon-H1: A Family of Hybrid-Head Language Models Redefining Efficiency and Performance
The paper addresses the limitations of traditional LLMs, which are based on either pure Transformer architectures (powerful but computationally expensive, especially with long contexts) or newer architectures like Mamba (more efficient but with different trade-offs).
The goal was to create a new family of models that could achieve state-of-the-art performance while being significantly more efficient in terms of both parameters and training data.
The Main Innovation: A Parallel Hybrid Architecture
The Falcon-H1 series introduces a novel parallel hybrid architecture. Unlike previous models that were either pure Transformer, pure Mamba, or used them sequentially, Falcon-H1 combines the strengths of both within each block:

Transformer-based Attention: Excels at modeling complex, long-range dependencies.
Mamba-based State Space Models (SSMs): Offer superior computational and memory efficiency, especially for long context windows.
Keep reading with a 7-day free trial
Subscribe to To Data & Beyond to keep reading this post and get 7 days of free access to the full post archives.