
Important LLM Papers for the Week From 15/09 To 21/09
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers must stay informed about the latest progress.
This article summarizes some of the most important LLM papers published during the Third Week of September 2025. The papers cover various topics that shape the next generation of language models, including model optimization and scaling, reasoning, benchmarking, and performance enhancement.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Technical Reports
Vision Language Models
LLM Reasoning
Post Training & RL
Get All My Books, One Button Away With 40% Off

I have created a bundle for my books and roadmaps, so you can buy everything with just one button and for 40% less than the original price. The bundle features 8 eBooks, including:
1. LLM Progress & Technical Reports
1.1. Hala Technical Report: Building Arabic-Centric Instruction & Translation Models at Scale
A new family of Arabic-centric instruction and translation models, called HALA, has been developed to address the scarcity of high-quality Arabic data for training large language models.
These models have demonstrated state-of-the-art performance on various Arabic-centric benchmarks, outperforming existing models in both smaller and larger size categories.
The development of HALA is a significant step forward for Arabic natural language processing. The researchers have released the models, data, and training methods to encourage further research and development in this area.
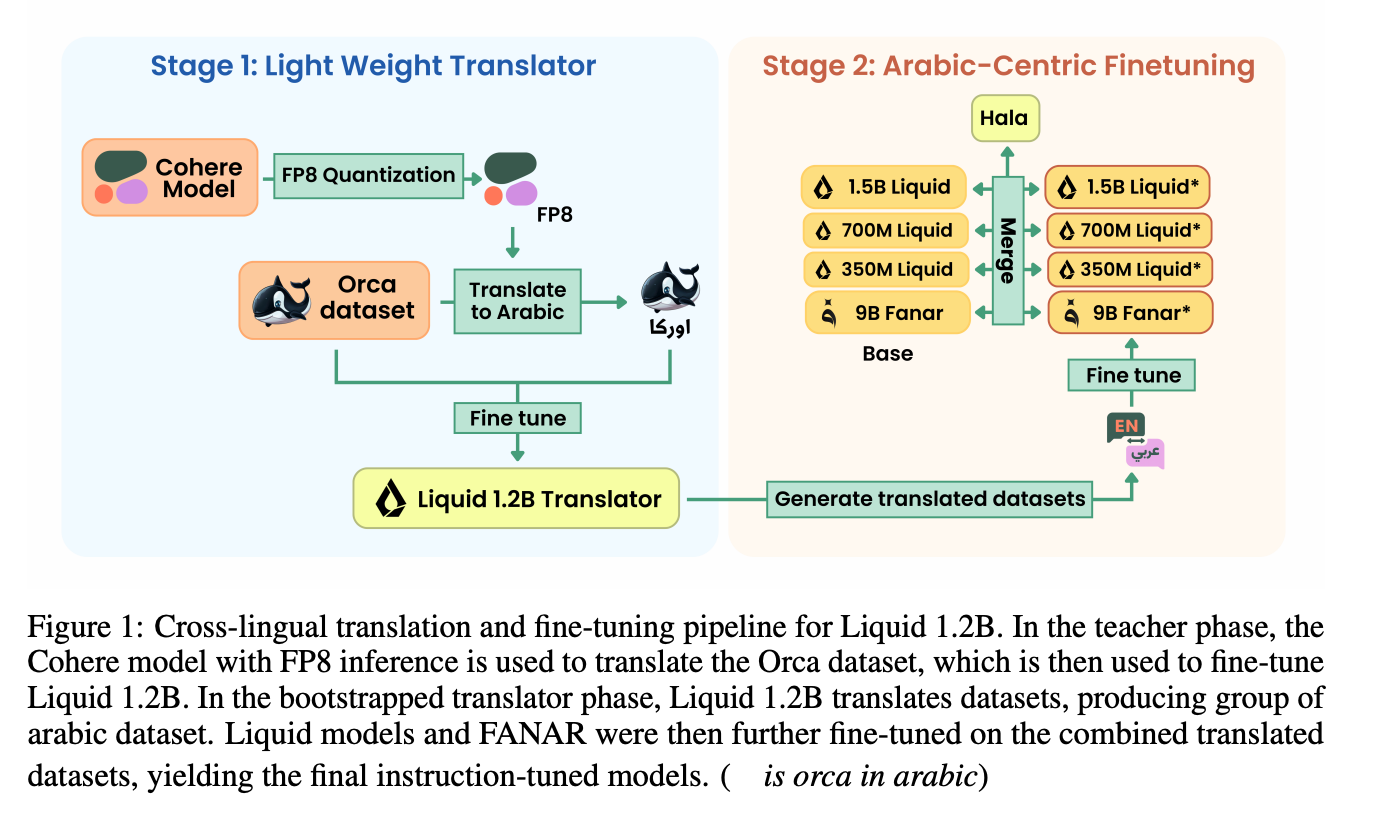
A “Translate-and-Tune” Pipeline
A key innovation in the development of HALA is the “translate-and-tune” pipeline. This two-stage process begins by using a powerful English-to-Arabic translation model to translate a large corpus of high-quality English instruction-following data into Arabic. This translated data is then used to fine-tune a lightweight Arabic language model, creating a specialized translator for generating further instruction data.
To enhance the models while maintaining their core strengths, the researchers employed a technique called Spherical Linear Interpolation (slerp). This method merges the parameters of the fine-tuned Arabic model with the original base model, effectively combining the Arabic specialization with the general capabilities of the base model.
This figure provides a visual overview of the entire cross-lingual translation and fine-tuning pipeline, illustrating both the “Light Weight Translator” and “Arabic-Centric Finetuning” stages. It effectively shows the flow from the initial translation model to the final, merged HALA models.
Impressive Performance on Arabic Benchmarks
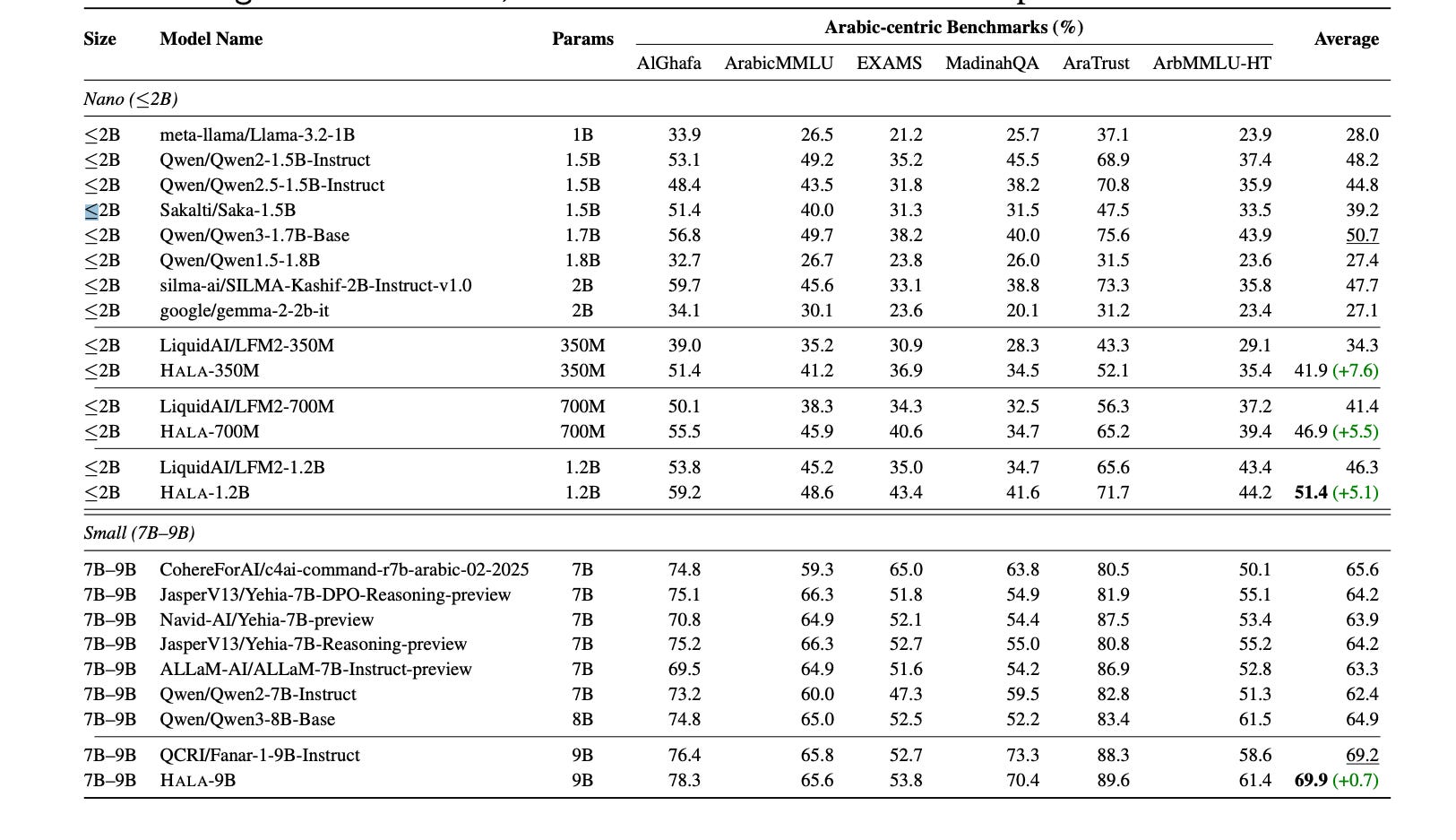
HALA models were evaluated on a suite of Arabic-centric tasks. The results show that the HALA models consistently outperform their base models across all tested sizes.
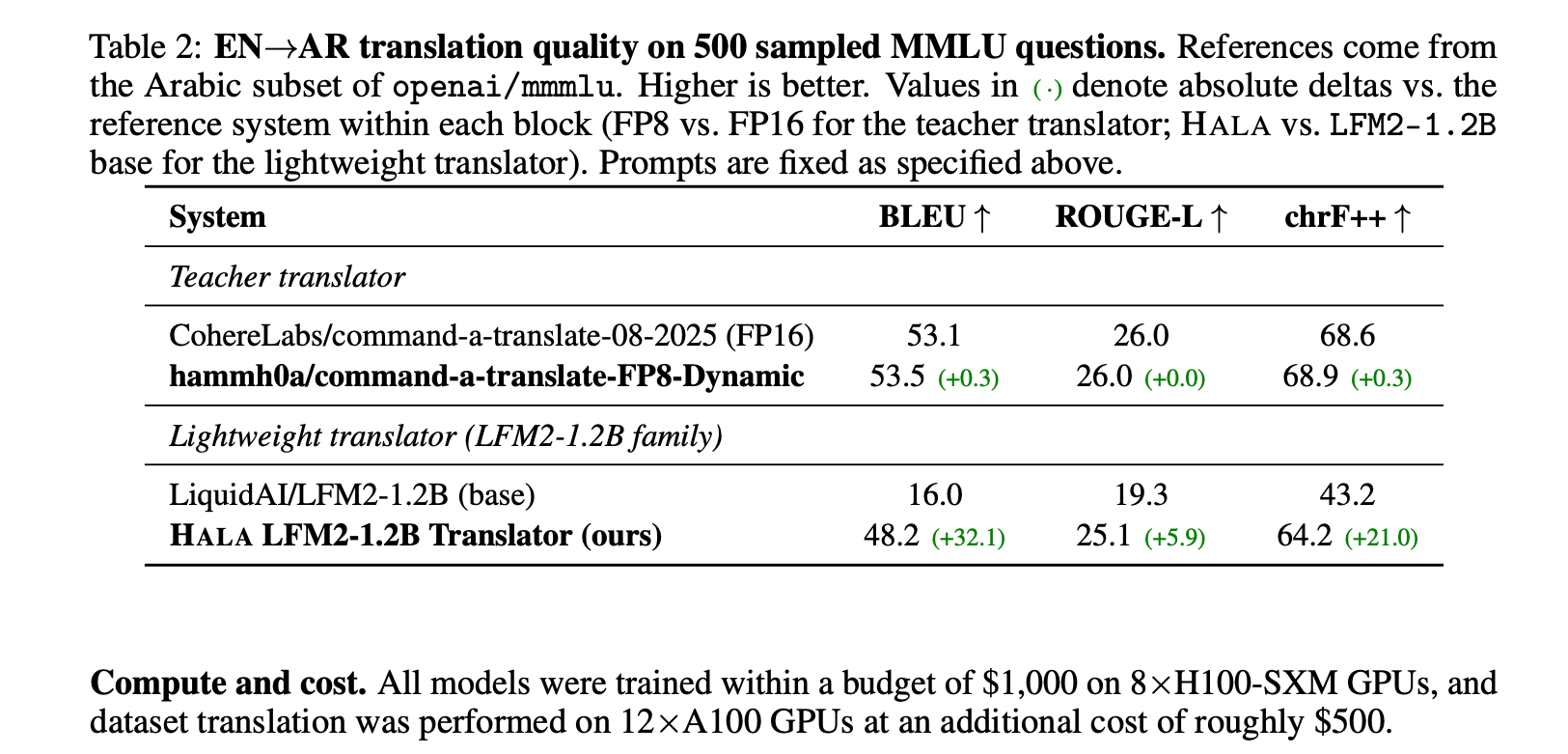
The researchers also conducted a detailed analysis of the translation quality of their lightweight translator, which demonstrated significant improvements in key translation metrics compared to its base model, confirming the effectiveness of the fine-tuning process.
This table presents the main evaluation results, comparing the performance of various HALA models against other multilingual and Arabic-centric models on several benchmarks. It clearly highlights the superior performance of the HALA models in their respective size categories.
This table is crucial for understanding the quality of the translation pipeline. It shows the translation fidelity of the specialized translator, providing concrete evidence of its effectiveness with metrics like BLEU, ROUGE-L, and chrF++.
Important Resources:
1.2. ReSum: Unlocking Long-Horizon Search Intelligence via Context Summarization
This paper from Alibaba Group introduces ReSum, a novel paradigm designed to overcome the context window limitations that hinder the performance of LLM-based web agents on complex, long-horizon search tasks.
By developing a specialized summary model and a tailored reinforcement learning strategy, the researchers created agents that can explore the web indefinitely, achieving state-of-the-art results and significantly outperforming existing open-source web agents.
Key Idea: Indefinite Exploration Through Context Summarization
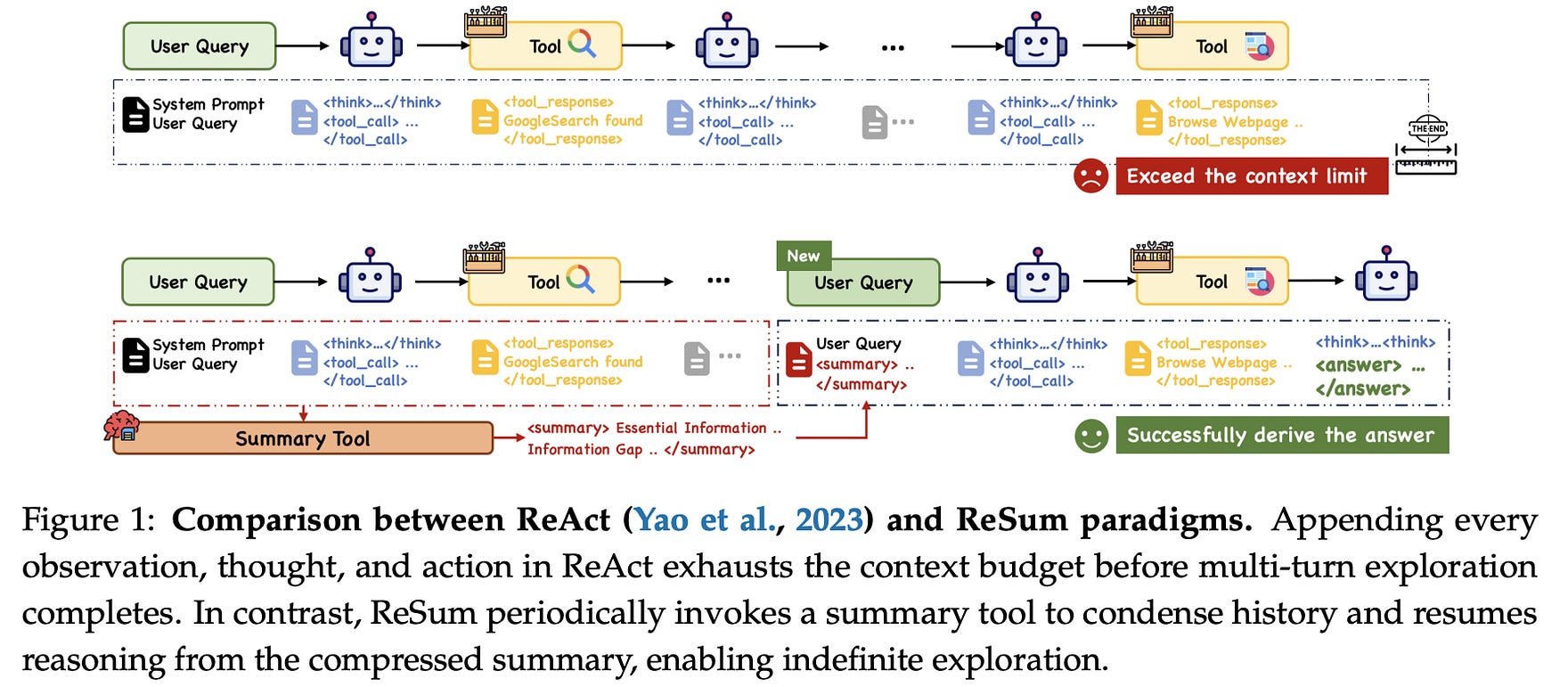
The primary challenge for web agents in complex search scenarios is the limited context window of LLMs. Paradigms like ReAct, which append every thought, action, and observation to the history, quickly exhaust the available context, leading to premature termination of the search process.
ReSum addresses this by periodically compressing the growing interaction history into a compact, structured summary. This allows the agent to maintain awareness of its previous findings and continue its exploration from a condensed reasoning state, effectively enabling indefinite long-horizon reasoning.
Main Methodology: A Specialized Summary Tool and Tailored Reinforcement Learning
The ReSum framework is built on two core components: a specialized summary model and a reinforcement learning algorithm adapted for summary-based reasoning.
ReSumTool-30B: Recognizing that generic LLMs struggle with summarizing web search conversations, the researchers developed ReSumTool-30B. This specialized model is fine-tuned to distill key evidence, identify information gaps, and suggest next steps from noisy and extensive interaction histories.
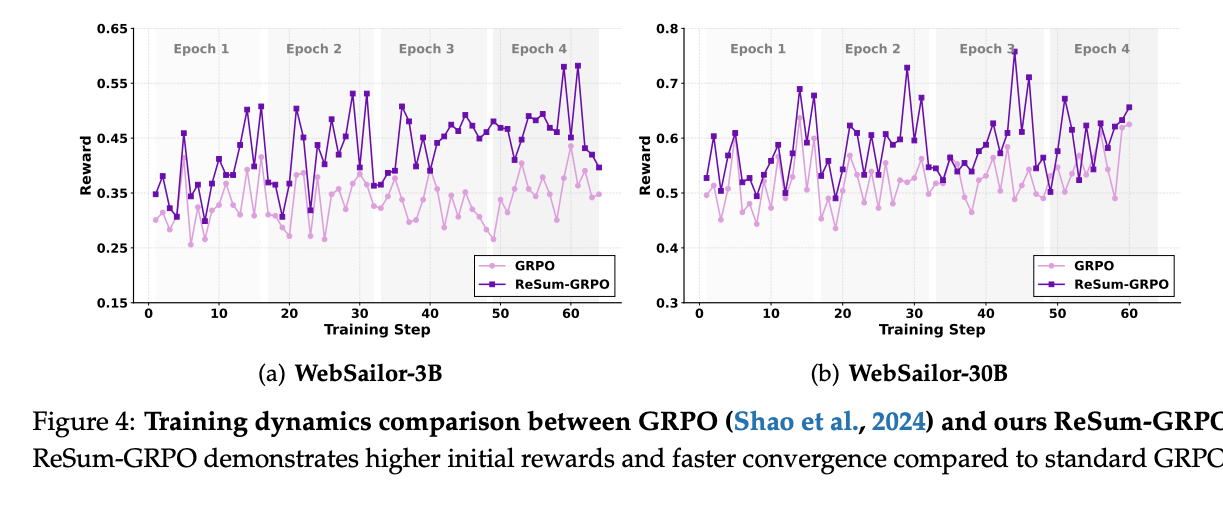
ReSum-GRPO: To train agents to effectively use these summaries, the paper introduces ReSum-GRPO. This reinforcement learning algorithm adapts the Group Relative Policy Optimization (GRPO) framework by treating long, summary-segmented trajectories as individual training episodes. This encourages the agent to both effectively reason from the compressed summary and to gather information that leads to high-quality summaries.
This figure provides a clear comparison between the ReAct and ReSum paradigms, visually demonstrating how ReSum avoids context exhaustion through summarization.
Most Important Findings
The ReSum paradigm and the associated training methods deliver significant performance improvements across multiple challenging benchmarks.
State-of-the-Art Performance: A ReSum-GRPO-trained agent, WebResummer-30B, achieved state-of-the-art results on the BrowseComp-zh and BrowseComp-en benchmarks, with Pass@1 scores of 33.3% and 18.3% respectively, surpassing existing open-source web agents with only 1K training samples.
Significant Improvement Over ReAct: In a training-free setting, ReSum demonstrated an average absolute improvement of 4.5% over the ReAct paradigm, with this advantage increasing to 8.2% after ReSum-GRPO training.
Effective Summary-Conditioned Reasoning: The ReSum-GRPO training was shown to be highly effective in familiarizing agents with reasoning from a compressed context, leading to higher rewards and faster convergence during training compared to standard GRPO.
Efficient and Scalable: The ReSum paradigm achieves these performance gains with minimal modifications to the existing ReAct framework, ensuring simplicity and compatibility with current agent architectures.
This diagram illustrates the ReSum-GRPO training process, showing how long trajectories are segmented by summaries and how a unified trajectory-level reward is broadcast to all segments.
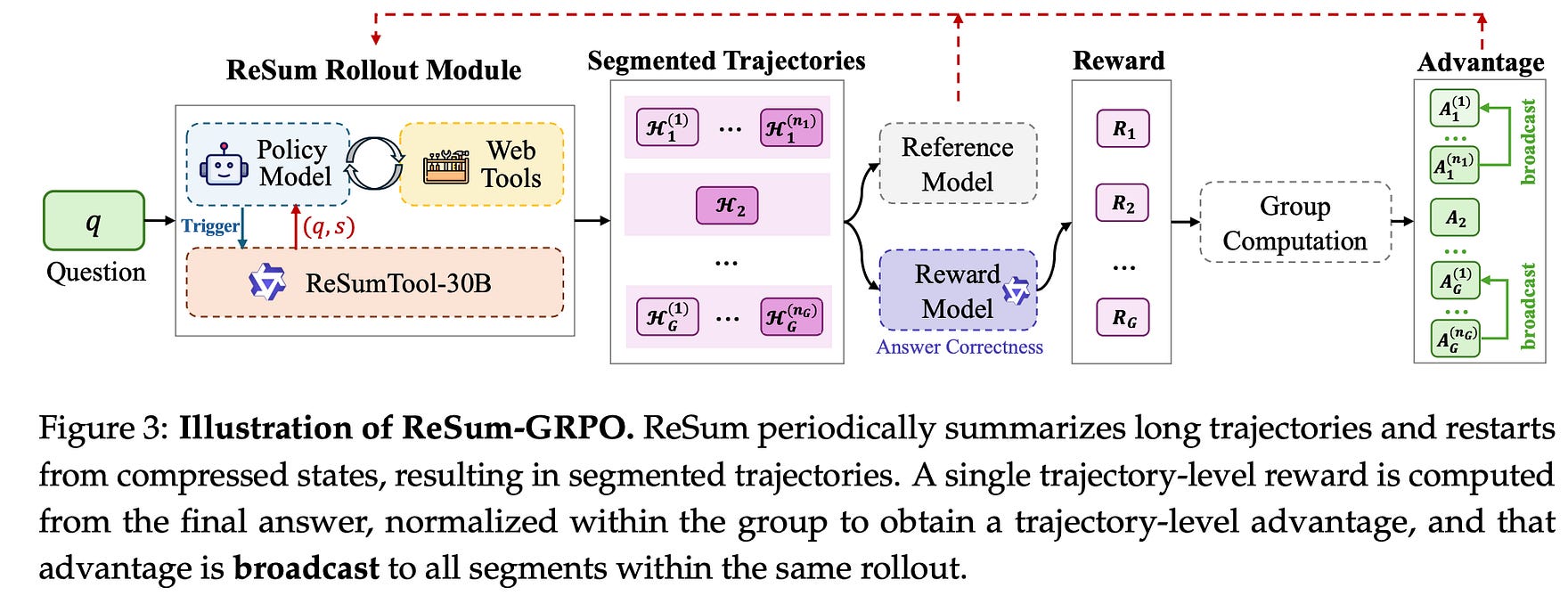
This table provides a comprehensive performance comparison of ReSum against ReAct and other baselines across various web agents and benchmarks, highlighting the consistent improvements achieved by ReSum.
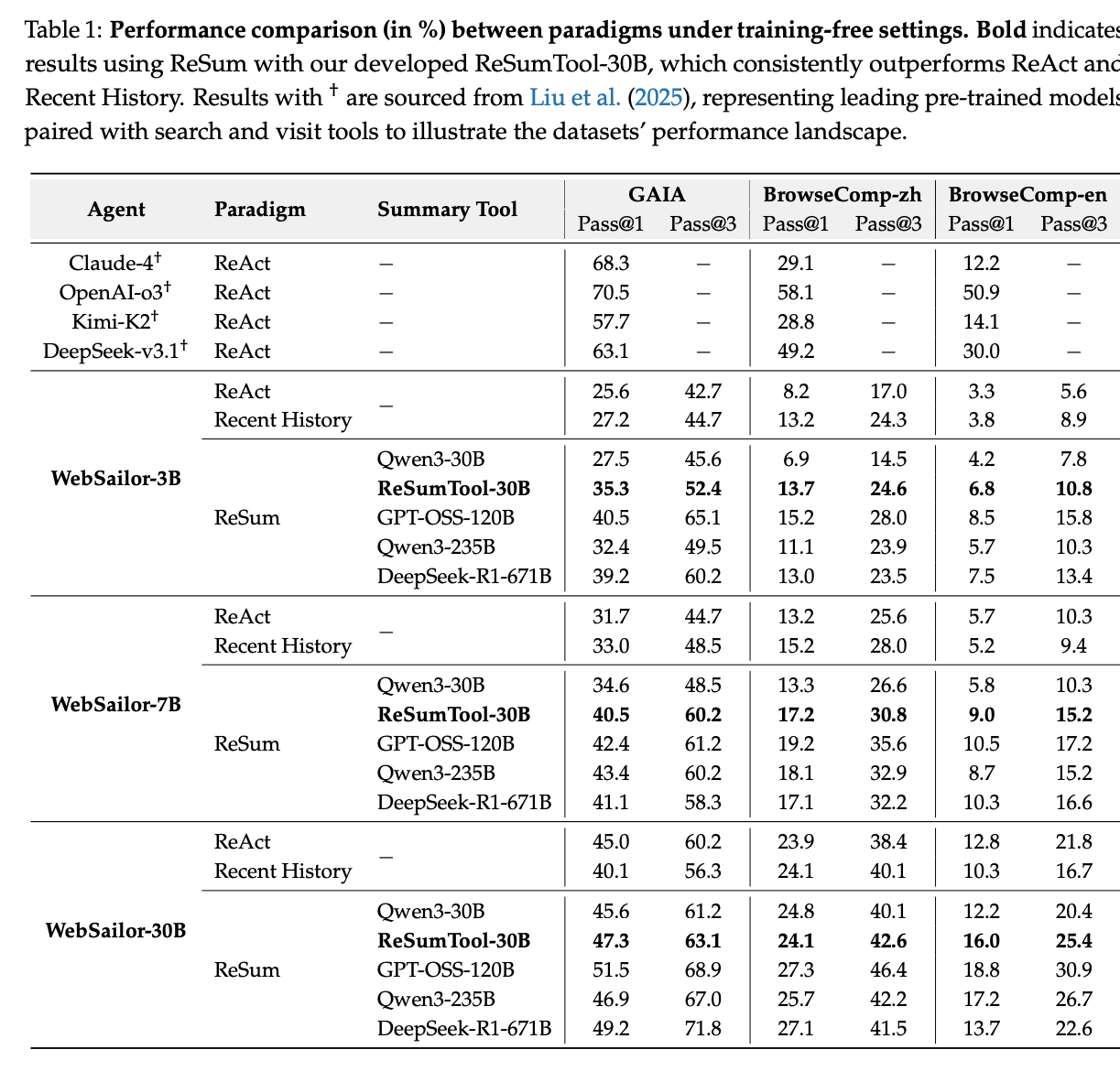
This table showcases the performance boost provided by ReSum-GRPO training, comparing it with standard GRPO and demonstrating the effectiveness of the paradigm adaptation.
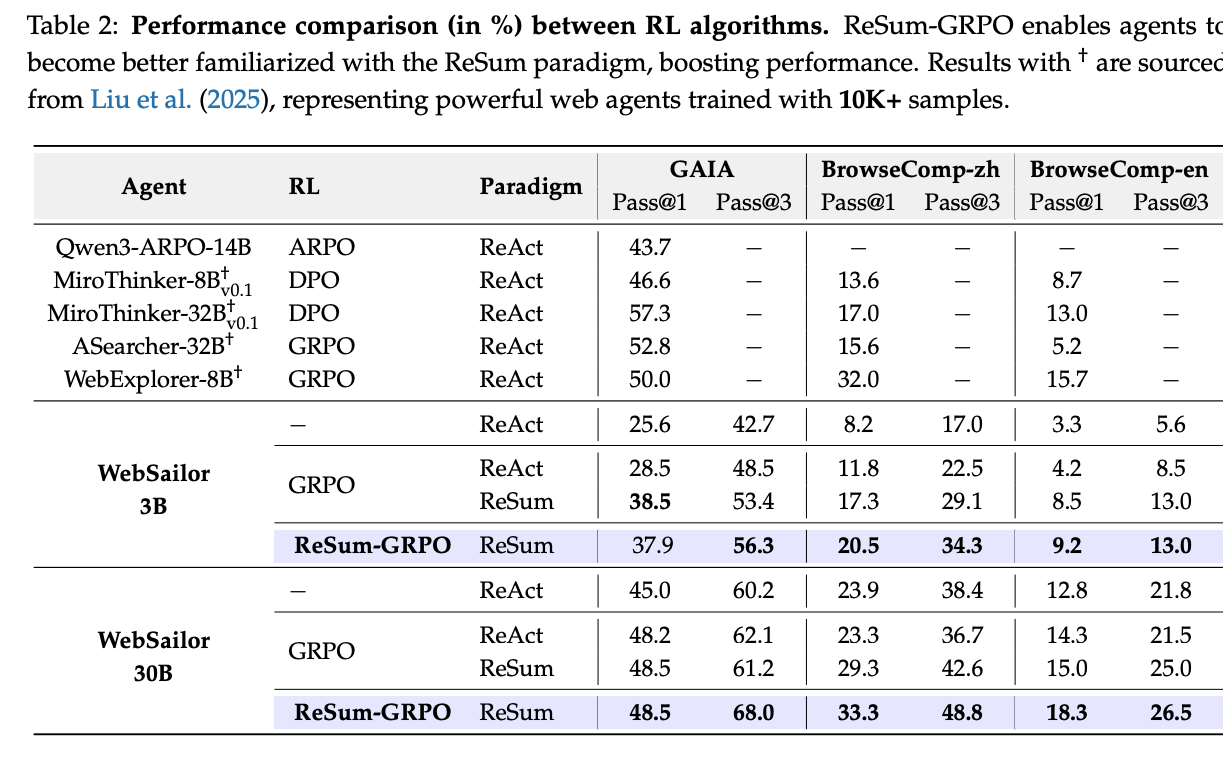
These charts are crucial for visualizing the training dynamics, showing that ReSum-GRPO achieves higher initial rewards and faster convergence than standard GRPO.
Important Resources:
1.3. WebWeaver: Structuring Web-Scale Evidence with Dynamic Outlines for Open-Ended Deep Research
This paper from Alibaba Group’s Tongyi Lab introduces WebWeaver, a novel dual-agent framework designed to tackle the complex challenge of open-ended deep research (OEDR).
By emulating the dynamic, iterative nature of human research, WebWeaver overcomes the key limitations of current AI agents, establishing a new state-of-the-art in producing comprehensive, reliable, and well-structured research reports.
Key Idea: Research Like a Human, Not a Machine
The core problem with existing research agents is their rigid, machine-like processes. They either use a static, pre-determined outline that can’t adapt to discoveries, or they gather all information at once and attempt a single, massive “one-shot” generation, which leads to “loss in the middle” errors and hallucinations.
WebWeaver’s key idea is to mirror the more organic and effective human research process. A human researcher’s plan is not static; it’s a living document that evolves as they gather evidence. Similarly, a human writer doesn’t read all of their notes at once but refers to specific evidence for each section they write.
WebWeaver operationalizes this through a dual-agent system: a Planner that iteratively builds and refines an outline in tandem with evidence discovery, and a Writer that composes the final report section-by-section, retrieving only the necessary evidence for the task at hand.
Main Methodology: A Dynamic Planner and a Hierarchical Writer
WebWeaver’s framework elegantly divides the research task into two synergistic phases, executed by two distinct agents:
The Planner (Dynamic Research Cycle): This agent is responsible for exploration and planning. It operates in a continuous loop, interleaving two key actions:
Evidence Acquisition: It performs web searches to gather information, filtering relevant URLs and extracting key evidence, which is stored in a structured memory bank.
Outline Optimization: Based on the new evidence, the planner continuously refines, expands, and restructures the report’s outline. Critically, it embeds citations into the outline, linking each section directly to the corresponding evidence IDs in the memory bank. This iterative cycle continues until a comprehensive, source-grounded plan is complete.
2. The Writer (Memory-Grounded Synthesis): Once the planner is done, the writer takes over to compose the final report. To avoid the pitfalls of long-context generation, it adopts a hierarchical, “divide and conquer” strategy:
It proceeds section by section through the planner’s final outline.
For each section, it performs a targeted retrieval, using the embedded citations to pull only the relevant evidence from the memory bank.
It then synthesizes and writes that single section, before pruning the just-used evidence from its context and moving to the next. This ensures the model’s focus remains sharp and prevents “contextual bleeding” between different parts of the report.
This is the central workflow diagram that clearly illustrates the two main loops: the planner on the left iteratively searching and optimizing the outline, and the writer on the right performing hierarchical retrieval and section-by-section writing.
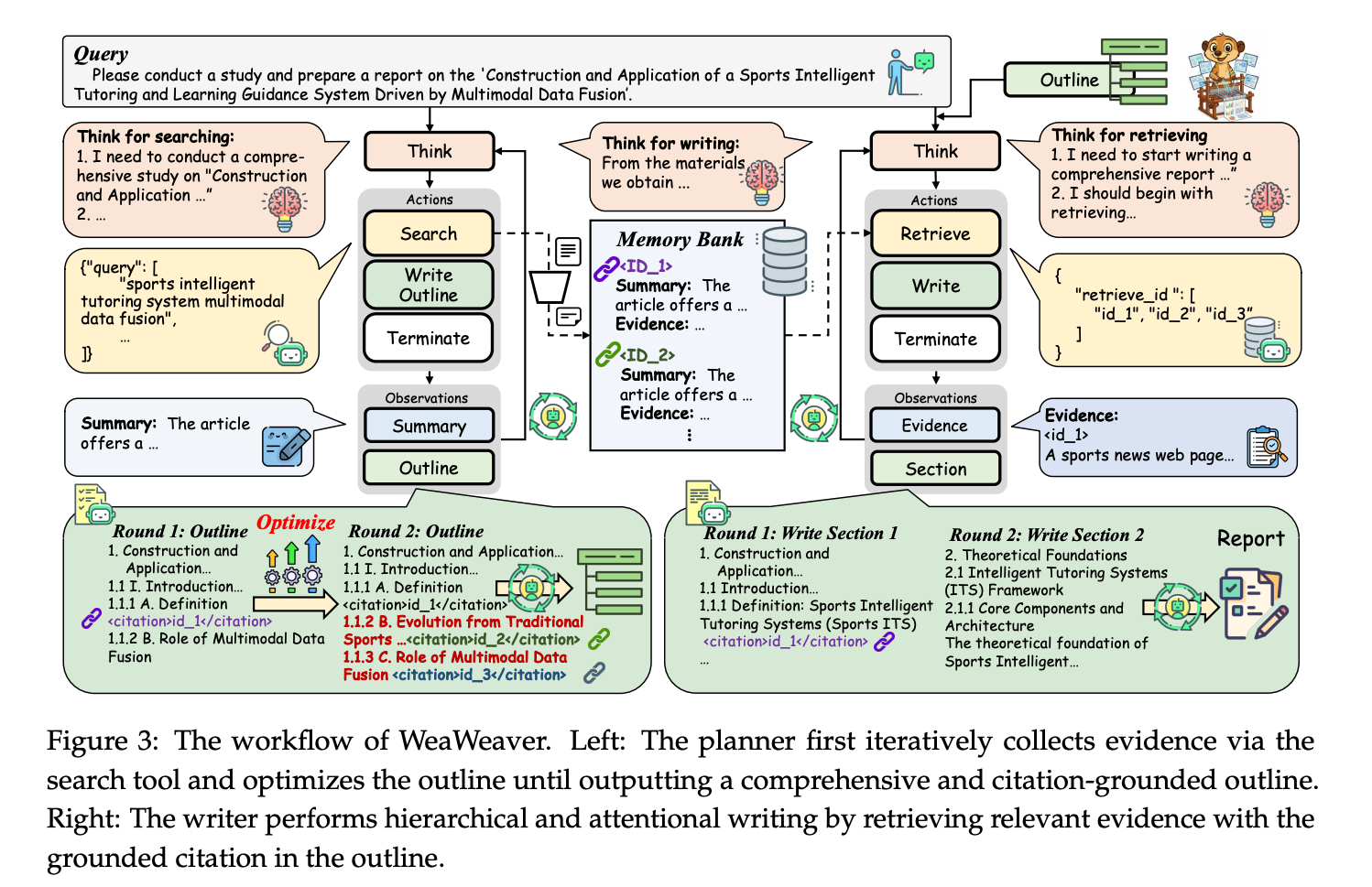
Most Important Findings
WebWeaver’s human-centric approach delivers significant and consistent performance gains, setting a new standard for open-source deep research agents.
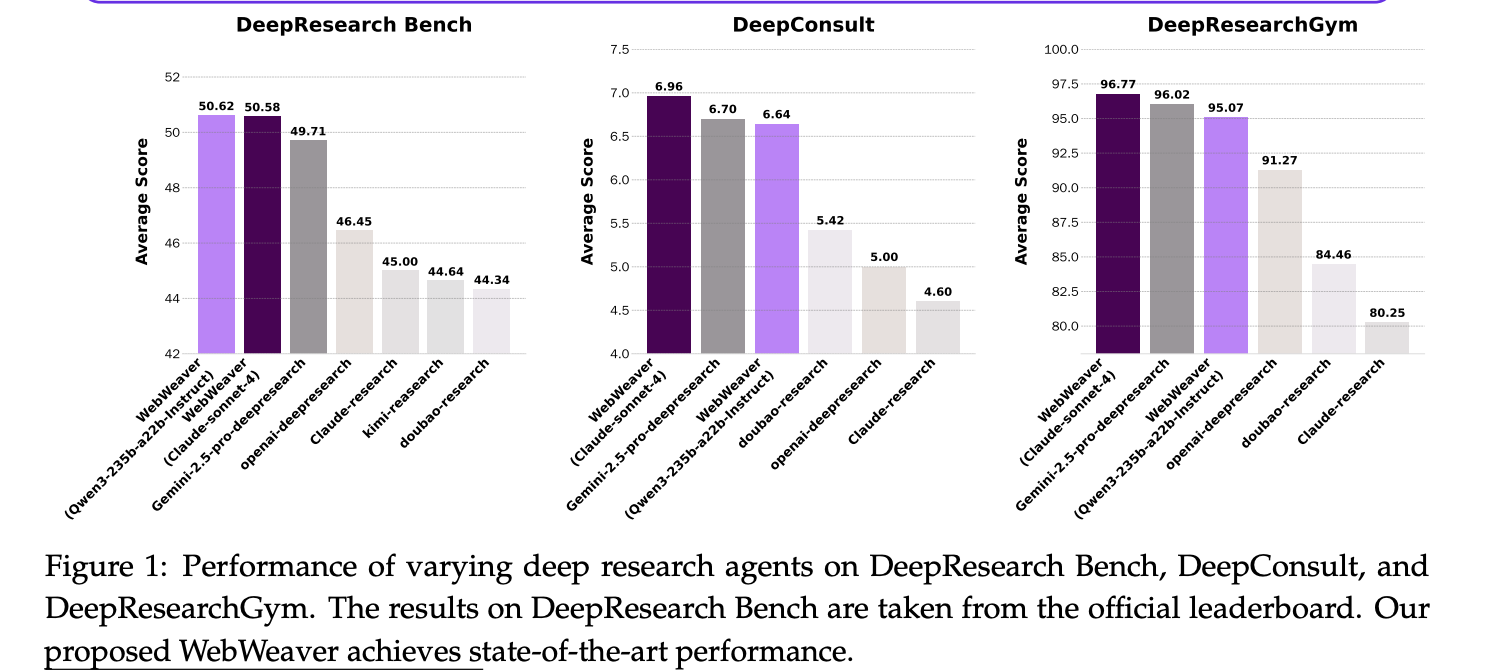
State-of-the-Art Performance: WebWeaver outperforms all other proprietary and open-source agents across three major benchmarks: DeepResearch Bench, DeepConsult, and DeepResearchGym.
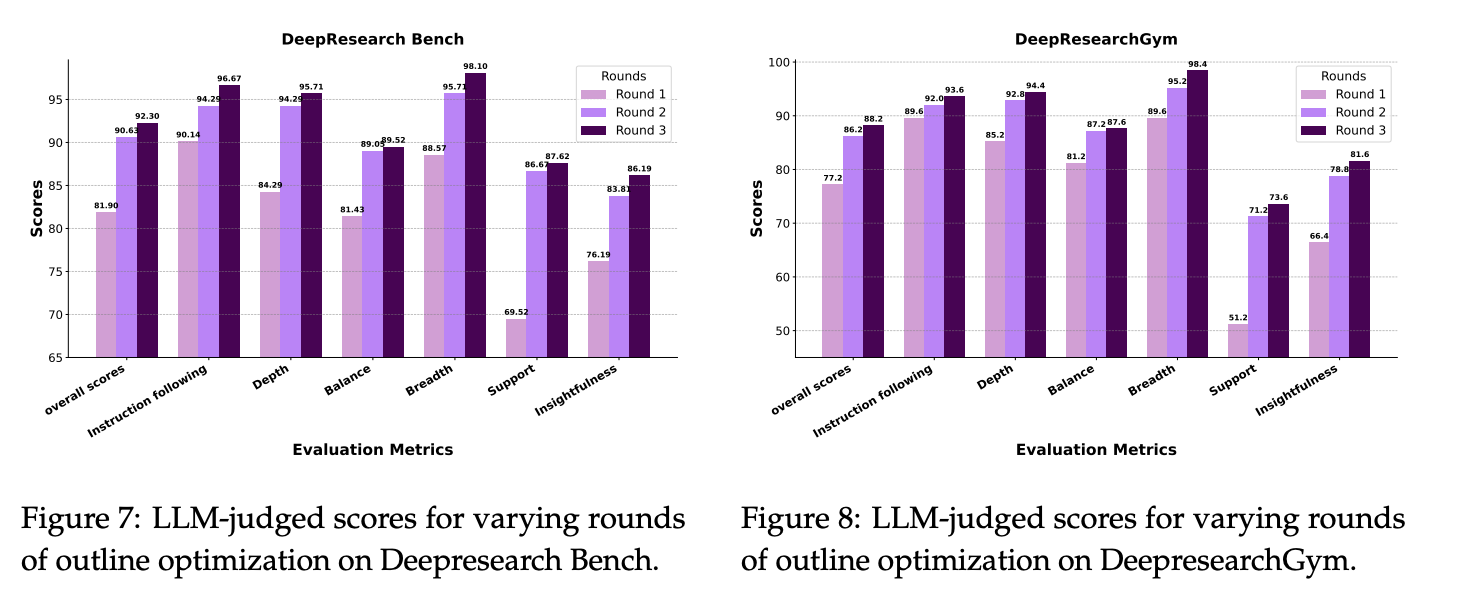
Iterative Planning is Essential: Ablation studies demonstrate that dynamic outline optimization is not a redundant step, but a critical mechanism. The quality, depth, and comprehensiveness of the final report improve monotonically with each round of outline refinement. Static, single-shot plans are fundamentally inferior.
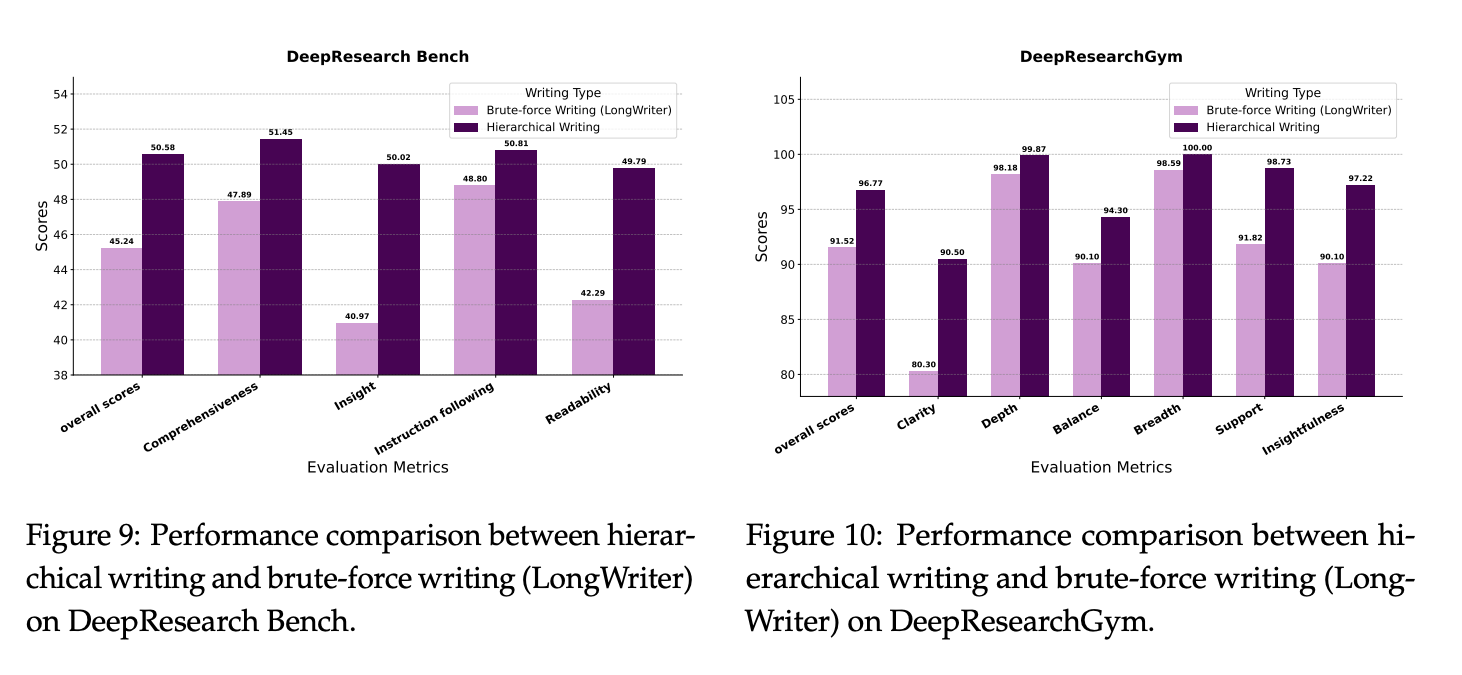
Hierarchical Writing Prevents Long-Context Failure: A direct comparison shows that WebWeaver’s section-by-section writing process dramatically outperforms a “brute-force” approach that feeds all evidence into the context at once. This confirms that the hierarchical method is essential for generating coherent, insightful, and reliably sourced long-form reports.
Agent Capabilities Can Be Distilled: The researchers used the framework to create a high-quality fine-tuning dataset (WebWeaver-3k). Training a smaller, 30B model on this data enabled it to achieve expert-level performance, most notably improving its citation accuracy from a nearly unusable 25% to a reliable 85.90%.
This figure provides an at-a-glance comparison of WebWeaver’s state-of-the-art performance against a wide range of other agents on all three benchmarks.
These charts are crucial as they directly measure the quality of the outline itself, showing how it becomes significantly deeper, broader, and better-supported with each iterative optimization round.
These two figures provide a direct, powerful comparison between WebWeaver’s hierarchical writing and a brute-force approach, clearly demonstrating the massive gains in quality and reliability from the hierarchical method.
Important Resources:
2. Vision Language Models
2.1. OmniWorld: A Multi-Domain and Multi-Modal Dataset for 4D World Modeling
This paper from Shanghai Artificial Intelligence Laboratory and ZJU introduces OmniWorld, a massive, multi-domain, and multi-modal dataset created to address the critical data bottleneck hindering the development of general-purpose 4D world models.
By creating a comprehensive data resource and a challenging new benchmark, the researchers demonstrate that fine-tuning existing state-of-the-art models on OmniWorld leads to significant performance gains in 4D reconstruction and video generation tasks.
Keep reading with a 7-day free trial
Subscribe to To Data & Beyond to keep reading this post and get 7 days of free access to the full post archives.