
Important LLM Papers for the Week From 23/11 To 30/11
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers must stay informed about the latest progress.
This article summarizes some of the most important LLM papers published during the Last Week of November 2025. The papers cover various topics that shape the next generation of language models, including model optimization and scaling, reasoning, benchmarking, and performance enhancement.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Technical Reports
Vision Language Models
Agents
Get All My Books, One Button Away With 40% Off

I have created a bundle for my books and roadmaps, so you can buy everything with just one button and for 40% less than the original price. The bundle features 8 eBooks, including:
1. LLM Progress & Technical Reports
1.1. ROOT: Robust Orthogonalized Optimizer for Neural Network Training
This paper from Huawei Noah’s Ark Lab introduces ROOT, a new optimizer designed to stabilize and accelerate the training of Large Language Models (LLMs). While recent matrix-aware optimizers like Muon have improved upon standard AdamW by orthogonalizing weight updates, they suffer from fragility regarding matrix dimensions and sensitivity to gradient noise. ROOT addresses these issues by introducing a “dual robustness” mechanism, making it highly effective for large-scale model training.
Key Idea: Dual Robustness for Stable Optimization
The core philosophy behind ROOT is that a “one-size-fits-all” approach to matrix orthogonalization is flawed. Existing methods like Muon use fixed coefficients for the Newton-Schulz iteration regardless of whether a weight matrix is square or highly rectangular, leading to approximation errors.
Furthermore, large-scale training is plagued by gradient outliers that distort update directions. ROOT’s key idea is to achieve Algorithmic Robustness (by adapting to matrix shapes) and Optimization Robustness (by suppressing outliers) simultaneously, ensuring consistent updates across diverse network architectures.
Main Methodology: Adaptive Newton and Soft-Thresholding
ROOT modifies the standard momentum-based update loop with two primary innovations:
Adaptive Newton-Schulz Iteration (AdaNewton): Instead of using global, fixed constants to approximate orthogonality (as Muon does), ROOT learns fine-grained, dimension-specific coefficients. For every unique matrix size in the network (e.g., 2048×2048 vs. 2048×8192), ROOT calculates optimal coefficients that minimize the orthogonalization error for that specific spectral distribution. This ensures high-precision updates regardless of the layer’s shape.
Proximal Optimization via Soft-Thresholding: To handle “heavy-tailed” gradient noise, ROOT views the momentum matrix as a combination of a robust base component and sparse outliers. Before orthogonalization, it applies a soft-thresholding operator (derived from proximal optimization for the L1-norm). This effectively “clips” or suppresses extreme outlier values in the momentum matrix while preserving the meaningful gradient direction, preventing noise from exploding during the polynomial Newton-Schulz iterations.
This chart plots the “Relative Error” of orthogonalization against training steps. It visually demonstrates that ROOT (green/red lines) maintains significantly lower approximation error compared to the Muon baseline and Classic Newton-Schulz, proving that shape-specific coefficients provide superior fidelity.
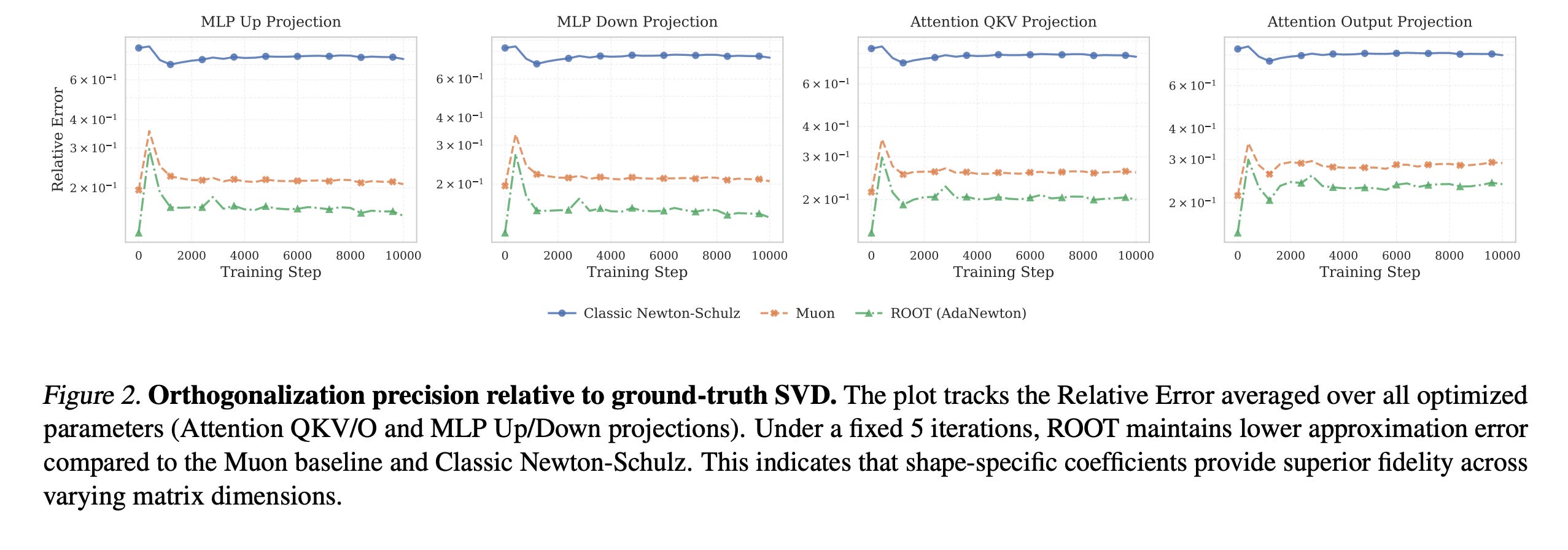
Most Important Findings
Superior Orthogonalization Precision: By using adaptive coefficients, ROOT reduces the mean squared error of orthogonalization by up to two orders of magnitude compared to fixed-coefficient methods, particularly for square matrices, which are notoriously difficult to orthogonalize precisely.
Faster Convergence: In pre-training experiments on a 1B parameter Transformer over 100 billion tokens, ROOT consistently achieved lower training loss compared to Muon and AdamW. The soft-thresholding mechanism alone provided stability, but the full ROOT optimizer yielded the best performance.
Zero-Shot Benchmark Dominance: When evaluating the trained models on downstream tasks (HellaSwag, PIQA, ARC, etc.), ROOT outperformed both AdamW and Muon across the board, achieving an average score of 60.12 compared to Muon’s 59.59 and AdamW’s 59.05.
Generalization to Vision: The benefits of ROOT are not limited to LLMs. In image classification tasks (training ViT on CIFAR-10), ROOT achieved higher top-1 accuracy (88.44%) compared to Muon (84.67%), proving that its robustness mechanisms transfer well to non-language modalities.
This figure displays the training loss curves for 10B token runs. It clearly shows ROOT converging faster and reaching a lower final loss than the Muon baseline, validating the effectiveness of the dual robustness strategy.
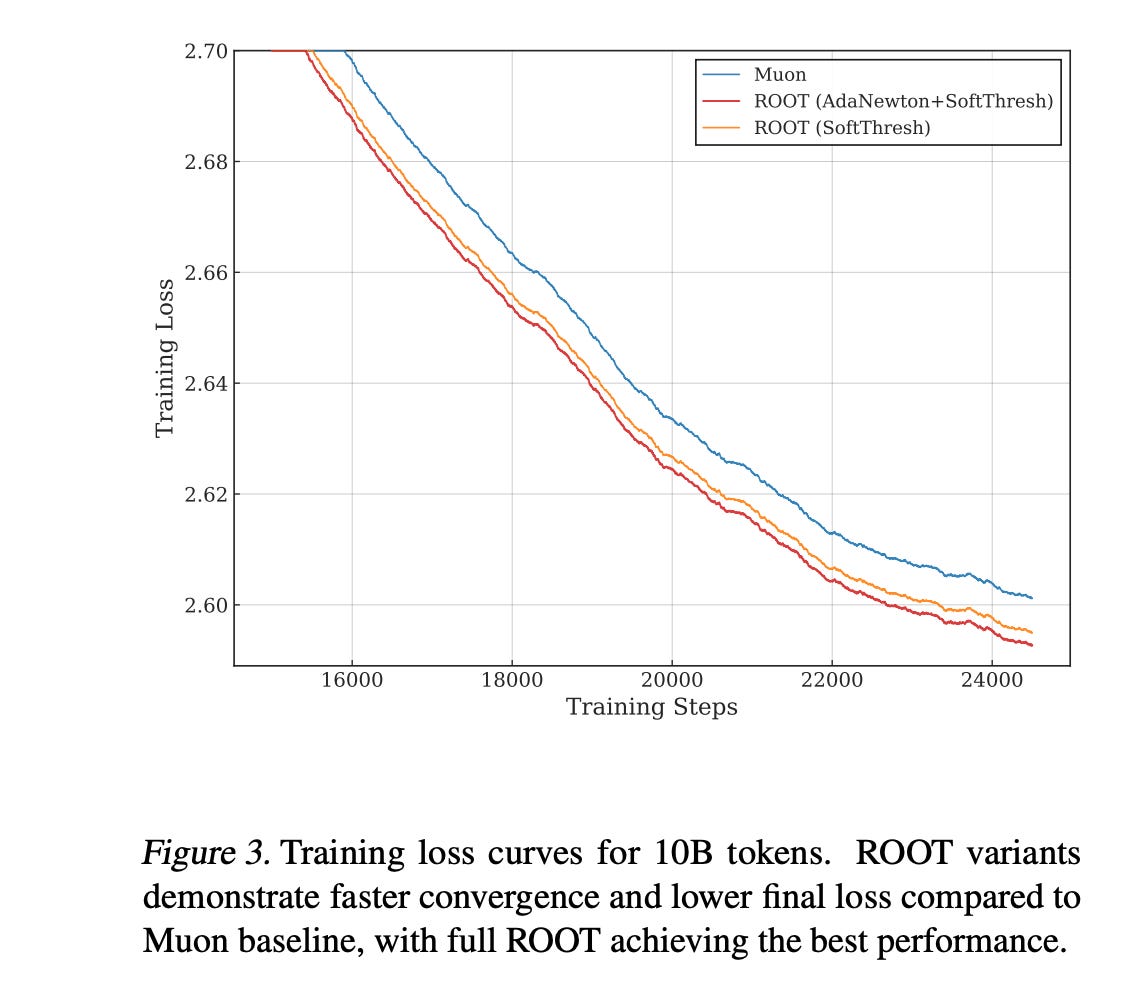
Paper Resources:
1.2. GigaEvo: An Open Source Optimization Framework Powered By LLMs And Evolution Algorithms
This paper from AIRI and Sber introduces GigaEvo, an open-source framework designed to replicate and extend the capabilities of AlphaEvolve (Novikov et al., 2025), a system that combines Large Language Models (LLMs) with evolutionary algorithms to solve complex mathematical and algorithmic problems.
Recognizing that the high-level descriptions in AlphaEvolve’s paper left many implementation details unspecified, GigaEvo provides a concrete, modular, and scalable codebase to democratize research in this emerging field.
Key Idea: Hybrid LLM-Evolution via Quality-Diversity
The core concept is to use LLMs not just as code generators, but as intelligent mutation operators within an evolutionary loop. Instead of random mutations, the system uses an LLM to rewrite code based on “insights” and “lineage analysis”—learning from what worked (or failed) in previous generations.
This is managed by a MAP-Elites algorithm, which maintains a diverse archive of high-performing solutions spread across a behavior space (e.g., fitness vs. complexity), ensuring that the system explores novel strategies rather than converging on a single local optimum.
Main Methodology: Modular Components and Asynchronous Pipeline
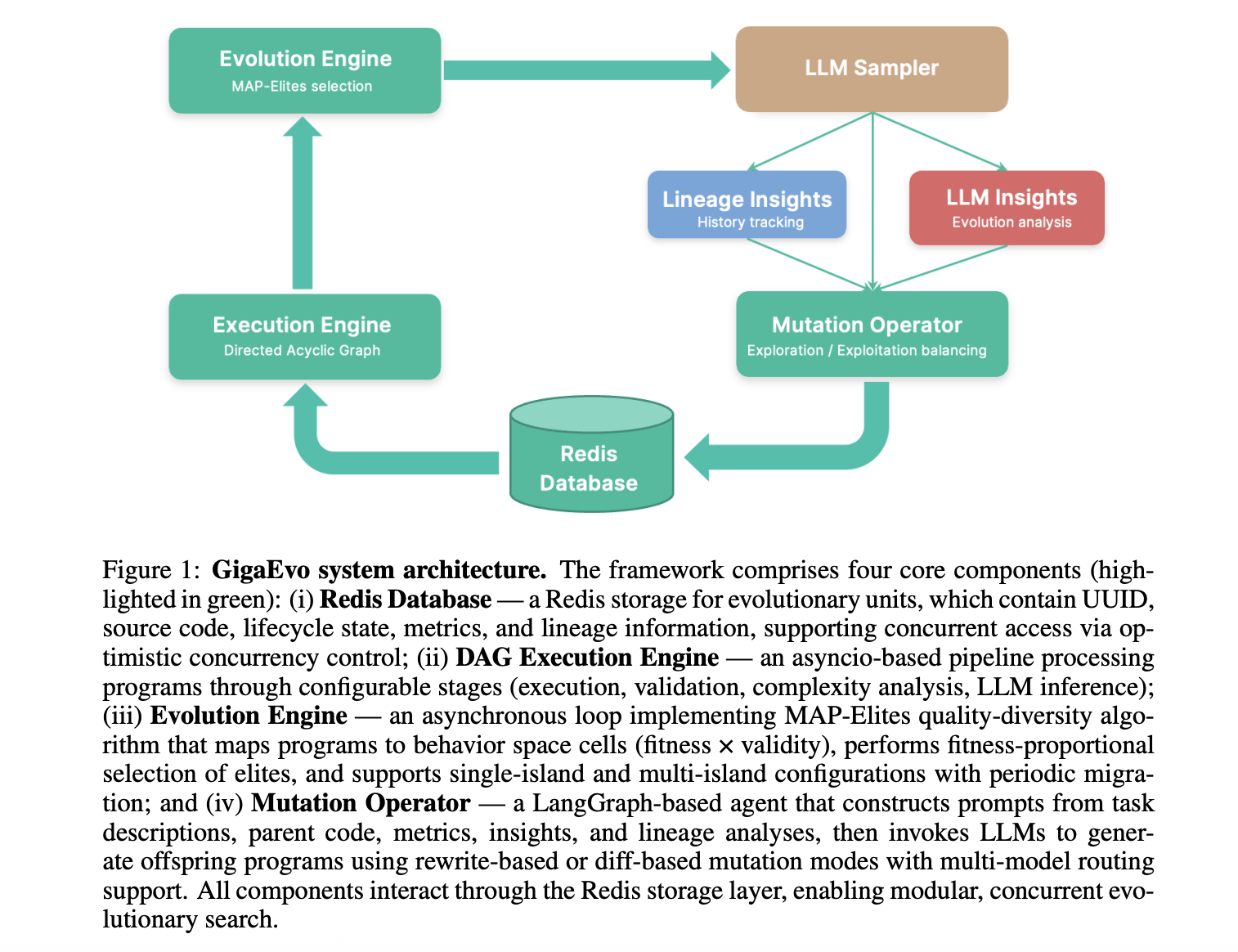
GigaEvo is built on four interacting components centered around a Redis database:
Evolution Engine: Runs the MAP-Elites algorithm, selecting elite programs for mutation and managing the population archive. It supports both single-island and multi-island (parallel populations with migration) configurations.
Mutation Operator: A LangGraph-based agent that constructs prompts for the LLM. It includes task descriptions, parent code, and crucial context like bidirectional lineage analysis (what changed from the parent, what improvements descendants made) to guide the LLM in generating better offspring.
DAG Execution Engine: An asynchronous pipeline that handles the heavy lifting of running code. It executes validation, computes fitness metrics, generates insights (using an LLM to analyze why a program failed or succeeded), and manages dependencies between these steps.
Redis Database: Acts as the central storage for programs, metrics, and lineage data, enabling concurrent access and scalability.
This architecture diagram visually explains how the Evolution Engine, Mutation Operator, and Execution Engine interact through the Redis database to form a closed-loop optimization system.
Most Important Findings
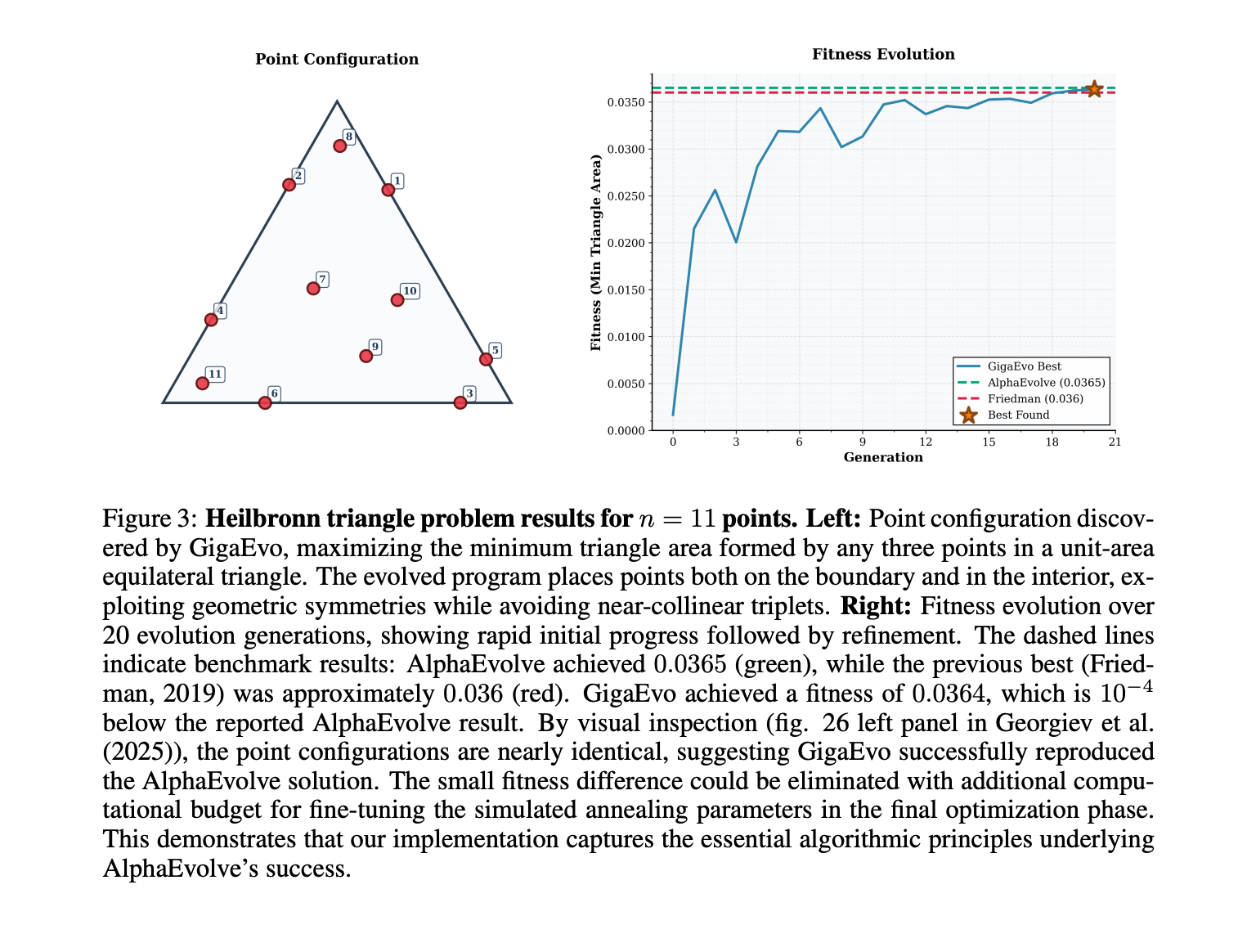
Reproducibility of AlphaEvolve: GigaEvo successfully reproduced the state-of-the-art results from the AlphaEvolve paper on the Heilbronn Triangle Problem. It found a point configuration with a minimum triangle area of 0.036354, nearly identical to AlphaEvolve’s 0.0365 and superior to the previous best of 0.036.
Improved Circle Packing: On the problem of packing variable-radius circles in a square, GigaEvo slightly surpassed the AlphaEvolve baseline for n=26 (2.636 vs 2.635) and achieved a score of 2.939 for n=32, noticeably beating the previous state-of-the-art of 2.937.
Generalization to Algorithms: Beyond geometry, the framework was tested on the “Bin Packing” problem. It not only replicated the SOTA for uniform distributions (matching FunSearch) but also established a new SOTA for Weibull distributions, reducing excess bin usage from 0.68% to 0.55%.
Prompt & Agent Evolution: In a Kaggle competition task (Jigsaw), GigaEvo evolved a prompt that improved the AUC score by 11.3 percentage points over the baseline. It further evolved an “agent” (multi-step reasoning script) that achieved even higher performance (0.803 AUC), demonstrating versatility beyond pure math problems.
This figure shows the visual result of the Heilbronn Triangle Problem (left) and the fitness evolution curve (right), demonstrating how GigaEvo rapidly improves upon the previous best known solution (red line) to match AlphaEvolve (green dashed line).
This visualizes the optimal circle packing configuration found by GigaEvo, showcasing its ability to handle complex geometric constraints and improve upon established mathematical bounds.

Paper Resources:
2. Vision Language Models
2.1. SAM 3: Segment Anything with Concepts
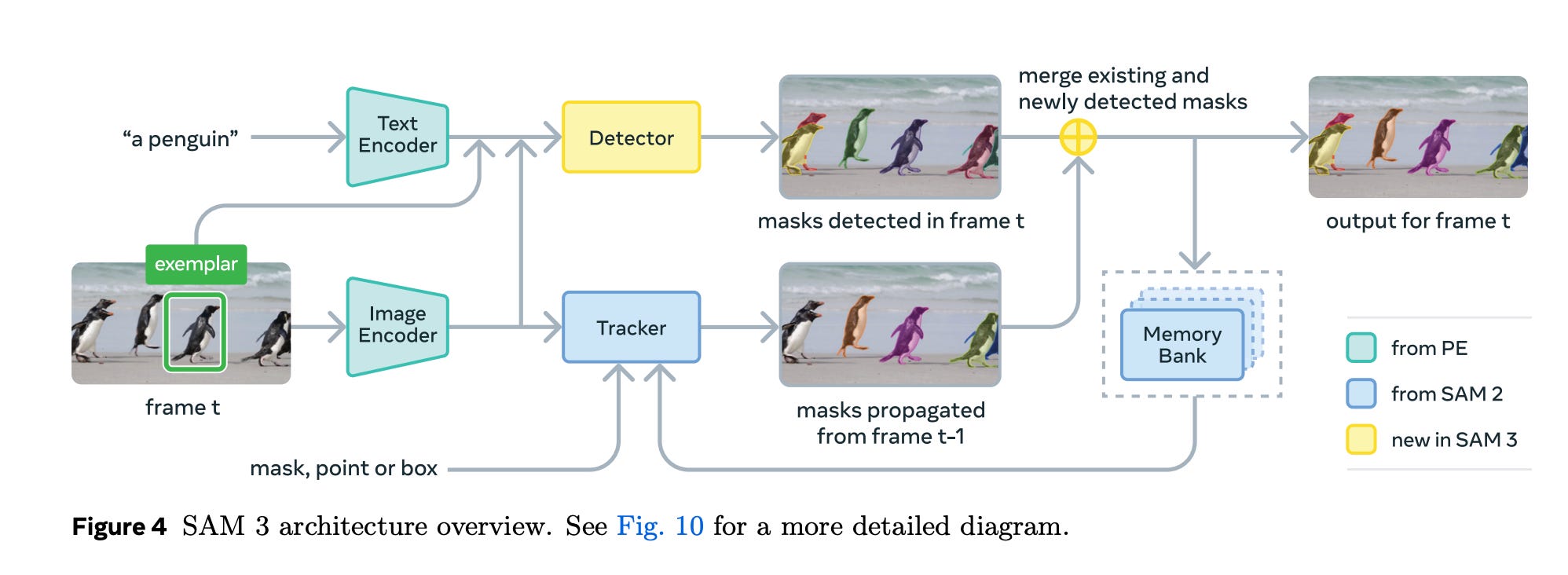
This paper from Meta Superintelligence Labs introduces SAM 3, a groundbreaking model that generalizes the “Segment Anything” paradigm from purely visual prompts (points, boxes) to semantic concepts.
While previous SAM models excelled at segmenting objects when explicitly pointed to, they lacked the ability to “find all cats” or “segment the red cars.” SAM 3 bridges this gap, enabling Promptable Concept Segmentation (PCS) in both images and videos, where users can prompt the model with text, image exemplars, or a combination of both to find and segment all matching instances.
Key Idea: Decoupled Recognition and Localization
The core innovation in SAM 3’s architecture is the separation of “what” an object is (recognition) from “where” it is (localization).
Presence Head: The authors introduce a learned global “presence token” that predicts whether a concept exists in the image at all. This decouples the classification task from the localization task carried out by object queries.
Hybrid Prompting: The model supports a mix of text and visual prompts. For example, a user can ask for “a striped cat” (text) and provide a bounding box of a specific cat (exemplar). SAM 3 uses this to find all striped cats in the image or video, unlike SAM 2, which would only segment that specific instance.
Memory-Based Tracking: For video, SAM 3 inherits SAM 2’s memory bank architecture but enhances it with a “masklet” logic that detects, tracks, and disambiguates multiple instances of a concept across frames, handling occlusions and reappearance robustly.
Main Methodology: Scalable Data Engine with AI Verifiers
To train SAM 3, the team built a massive data engine that generated a dataset (SA-Co) with 4 million unique concepts and 52 million masks.
Data Curation: They moved beyond standard web data, mining diverse media domains (medical, underwater, wildlife) and using an ontology to ensure broad concept coverage.
AI-Assisted Annotation: Instead of relying solely on humans, they fine-tuned LLaMA models to act as “AI Verifiers.” These AI models checked the quality and exhaustivity of masks generated by earlier versions of SAM 3. This “AI-in-the-loop” process doubled annotation throughput.
Hard Negatives: A crucial part of the training was mining “hard negatives”—concepts that aren’t in the image but are semantically similar to what is there (e.g., asking for a “tabby cat” when only a “Siamese cat” is present). This forces the model to be precise and avoid hallucinating objects.
This diagram illustrates the SAM 3 architecture, showing the dual encoder-decoder structure. It highlights the new “Presence Token” in the detector and how the detector feeds into the tracker/memory bank for video processing.
Most Important Findings
SOTA Performance: SAM 3 sets a new standard for open-vocabulary segmentation. On the LVIS benchmark, it achieves a zero-shot mask AP of 48.8, significantly beating the previous best of 38.5.
Doubled Accuracy: On the new SA-Co benchmark, SAM 3 achieves more than double the accuracy (cgF1 score) of the strongest baselines like OWLv2.
Video Capability: The model generalizes seamlessly to video. In zero-shot video segmentation benchmarks (like LVVIS and OVIS), it outperforms specialized video models, showing it can stably track concepts over time.
Efficiency: Despite its capabilities, SAM 3 remains fast. It can process an image with 100+ detected objects in just 30 ms on an H200 GPU and sustains near real-time performance for video tracking.
This figure visually demonstrates the leap from SAM 2 to SAM 3. While SAM 2 (left) segments single objects from clicks, SAM 3 (right) can take a prompt like “a round cell” or “a striped cat” and segment every instance of that §§concept across the entire image or video.

Paper Resources:
2.2. OpenMMReasoner: Pushing the Frontiers for Multimodal Reasoning with an Open and General Recipe
Keep reading with a 7-day free trial
Subscribe to To Data & Beyond to keep reading this post and get 7 days of free access to the full post archives.