


Important LLM Papers for the Week from 05/08 to 11/08
Stay Updated with Recent LLMs Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the First Week of August 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Training, Evaluation & Inference
LLM Quantization
LLM Safety & Alignment
LLM Agents
Retrieval Augmented Generation (RAG)
Tokenizers
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. LLM Progress & Benchmarking
1.1. MiniCPM-V: A GPT-4V Level MLLM on Your Phone
The recent surge of Multimodal Large Language Models (MLLMs) has fundamentally reshaped the landscape of AI research and industry, shedding light on a promising path toward the next AI milestone. However, significant challenges remain preventing MLLMs from being practical in real-world applications.
The most notable challenge comes from the huge cost of running an MLLM with a massive number of parameters and extensive computation. As a result, most MLLMs need to be deployed on high-performing cloud servers, which greatly limits their application scopes such as mobile, offline, energy-sensitive, and privacy-protective scenarios.
In this work, we present MiniCPM-V, a series of efficient MLLMs deployable on end-side devices. By integrating the latest MLLM techniques in architecture, pertaining, and alignment, the latest MiniCPM-Llama3-V 2.5 has several notable features:
Strong performance, outperforming GPT-4V-1106, Gemini Pro, and Claude 3 on OpenCompass, a comprehensive evaluation over 11 popular benchmarks.
Strong OCR capability and 1.8M pixel high-resolution image perception at any aspect ratio.
Trustworthy behavior with low hallucination rates.
Multilingual support for 30+ languages
Efficient deployment on mobile phones.
More importantly, MiniCPM-V can be viewed as a representative example of a promising trend: The model sizes for achieving usable (e.g., GPT-4V) level performance are rapidly decreasing, along with the fast growth of end-side computation capacity.
This jointly shows that GPT-4V level MLLMs deployed on end devices are becoming increasingly possible, unlocking a wider spectrum of real-world AI applications in the near future.
1.2. Language Model Can Listen While Speaking

Dialogue serves as the most natural manner of human-computer interaction (HCI). Recent advancements in speech-language models (SLM) have significantly enhanced speech-based conversational AI.
However, these models are limited to turn-based conversation, lacking the ability to interact with humans in real-time spoken scenarios, for example, being interrupted when the generated content is not satisfactory.
To address these limitations, we explore full duplex modeling (FDM) in interactive speech language models (iSLM), focusing on enhancing real-time interaction and, more explicitly, exploring the quintessential ability of interruption. We introduce a novel model design, namely the listening-while-speaking language model (LSLM), an end-to-end system equipped with both listening and speaking channels.
Our LSLM employs a token-based decoder-only TTS for speech generation and a streaming self-supervised learning (SSL) encoder for real-time audio input. LSLM fuses both channels for autoregressive generation and detects turn-taking in real-time.
Three fusion strategies — early fusion, middle fusion, and late fusion — are explored, with middle fusion achieving an optimal balance between speech generation and real-time interaction. Two experimental settings, command-based FDM and voice-based FDM, demonstrate LSLM’s robustness to noise and sensitivity to diverse instructions.
Our results highlight LSLM’s capability to achieve duplex communication with minimal impact on existing systems. This study aims to advance the development of interactive speech dialogue systems, enhancing their applicability in real-world contexts.
1.3. Transformer Explainer: Interactive Learning of Text-Generative Models

Transformers have revolutionized machine learning, yet their inner workings remain opaque to many. We present Transformer Explainer, an interactive visualization tool designed for non-experts to learn about Transformers through the GPT-2 model.
Our tool helps users understand complex Transformer concepts by integrating a model overview and enabling smooth transitions across abstraction levels of mathematical operations and model structures.
It runs a live GPT-2 instance locally in the user’s browser, empowering users to experiment with their own input and observe in real time how the internal components and parameters of the Transformer work together to predict the next tokens.
Our tool requires no installation or special hardware, broadening the public’s education access to modern generative AI techniques.
2. LLM Training, Evaluation & Inference
2.1. Self-Taught Evaluators

Model-based evaluation is at the heart of successful model development — as a reward model for training, and as a replacement for human evaluation. To train such evaluators, the standard approach is to collect a large number of human preference judgments over model responses, which is costly and the data becomes stale as models improve.
In this work, we present an approach that aims to improve evaluators without human annotations, using synthetic training data only. Starting from unlabeled instructions, our iterative self-improvement scheme generates contrasting model outputs and trains an LLM-as-a-Judge to produce reasoning traces and final judgments, repeating this training at each new iteration using the improved predictions.
Without any labeled preference data, our Self-Taught Evaluator can improve a strong LLM (Llama3–70B-Instruct) from 75.4 to 88.3 (88.7 with majority vote) on RewardBench. This outperforms commonly used LLM judges such as GPT-4 and matches the performance of the top-performing reward models trained with labeled examples.
2.2. The Impact of Hyperparameters on Large Language Model Inference Performance: An Evaluation of vLLM and HuggingFace Pipelines

The recent surge of open-source large language models (LLMs) enables developers to create AI-based solutions while maintaining control over aspects such as privacy and compliance, thereby providing governance and ownership of the model deployment process. To utilize these LLMs, inference engines are needed.
These engines load the model’s weights onto available resources, such as GPUs, and process queries to generate responses. The speed of inference, or performance, of the LLM, is critical for real-time applications, as it computes millions or billions of floating point operations per inference.
Recently, advanced inference engines such as vLLM have emerged, incorporating novel mechanisms such as efficient memory management to achieve state-of-the-art performance.
In this paper, we analyze the performance, particularly the throughput (tokens generated per unit of time), of 20 LLMs using two inference libraries: vLLM and HuggingFace’s pipelines. We investigate how various hyperparameters, which developers must configure, influence inference performance.
Our results reveal that throughput landscapes are irregular, with distinct peaks, highlighting the importance of hyperparameter optimization to achieve maximum performance.
We also show that applying hyperparameter optimization when upgrading or downgrading the GPU model used for inference can improve throughput from HuggingFace pipelines by an average of 9.16% and 13.7%, respectively.
2.3. WalledEval: A Comprehensive Safety Evaluation Toolkit for Large Language Models

WalledEval is a comprehensive AI safety testing toolkit designed to evaluate large language models (LLMs). It accommodates a diverse range of models, including both open-weight and API-based ones, and features over 35 safety benchmarks covering areas such as multilingual safety, exaggerated safety, and prompt injections.
The framework supports both LLM and judge benchmarking and incorporates custom mutators to test safety against various text-style mutations such as future tense and paraphrasing.
Additionally, WalledEval introduces WalledGuard, a new, small, and performant content moderation tool, and SGXSTest, a benchmark for assessing exaggerated safety in cultural contexts.
3. LLM Quantization & Optimization
3.1. Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters

Enabling LLMs to improve their outputs by using more test-time computation is a critical step towards building generally self-improving agents that can operate on open-ended natural language.
In this paper, we study the scaling of inference-time computation in LLMs, with a focus on answering the question: if an LLM is allowed to use a fixed but non-trivial amount of inference-time computes, how much can it improve its performance on a challenging prompt?
Answering this question has implications not only on the achievable performance of LLMs but also on the future of LLM pretraining and how one should trade off inference-time and pre-training compute. Despite its importance, little research attempted to understand the scaling behaviors of various test-time inference methods.
Moreover, current work largely provides negative results for a number of these strategies. In this work, we analyze two primary mechanisms to scale test-time computation: (1) searching against dense, process-based verifier reward models; and (2) updating the model’s distribution over a response adaptively, given the prompt at test time.
We find that in both cases, the effectiveness of different approaches to scaling test-time computing critically varies depending on the difficulty of the prompt. This observation motivates applying a “compute-optimal” scaling strategy, which acts to most effectively allocate test-time compute adaptively per prompt.
Using this compute-optimal strategy, we can improve the efficiency of test-time compute scaling by more than 4x compared to a best-of-N baseline. Additionally, in a FLOPs-matched evaluation, we find that on problems where a smaller base model attains somewhat non-trivial success rates, test-time computing can be used to outperform a 14x larger model.
4. LLM Safety & Alignment
4.1. Better Alignment with Instruction Back-and-Forth Translation

We propose a new method, instruction back-and-forth translation, to construct high-quality synthetic data grounded in world knowledge for aligning large language models (LLMs).
Given documents from a web corpus, we generate and curate synthetic instructions using the backtranslation approach proposed by Li et al.(2023a), and rewrite the responses to improve their quality further based on the initial documents.
Fine-tuning with the resulting (back-translated instruction, rewritten response) pairs yields higher win rates on AlpacaEval than using other common instruction datasets such as Humpback, ShareGPT, Open Orca, Alpaca-GPT4 and Self-instruct.
We also demonstrate that rewriting the responses with an LLM outperforms direct distillation, and the two generated text distributions exhibit significant distinctions in embedding space.
Further analysis shows that our back-translated instructions are of higher quality than other sources of synthetic instructions, while our responses are more diverse and complex than those obtained from distillation.
Overall we find that instruction back-and-forth translation combines the best of both worlds — making use of the information diversity and quantity found on the web while ensuring the quality of the responses which is necessary for effective alignment.
5. LLM Agents
5.1. Optimus-1: Hybrid Multimodal Memory-Empowered Agents Excel in Long-Horizon Tasks
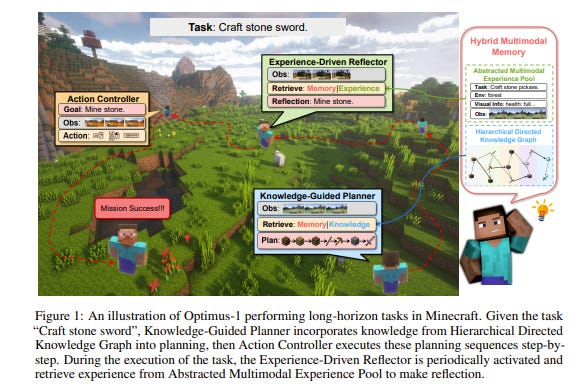
Building a general-purpose agent is a long-standing vision in the field of artificial intelligence. Existing agents have made remarkable progress in many domains, yet they still struggle to complete long-horizon tasks in an open world. We attribute this to the lack of necessary world knowledge and multimodal experience that can guide agents through a variety of long-horizon tasks.
In this paper, we propose a Hybrid Multimodal Memory module to address the above challenges. It 1) transforms knowledge into a Hierarchical Directed Knowledge Graph that allows agents to explicitly represent and learn world knowledge, and 2) summarises historical information into an Abstracted Multimodal Experience Pool that provides agents with rich references for in-context learning.
On top of the Hybrid Multimodal Memory module, a multimodal agent, Optimus-1, is constructed with a dedicated Knowledge-guided Planner and Experience-Driven Reflector, contributing to better planning and reflection in the face of long-horizon tasks in Minecraft.
Extensive experimental results show that Optimus-1 significantly outperforms all existing agents on challenging long-horizon task benchmarks, and exhibits near-human-level performance on many tasks. In addition, we introduce various Multimodal Large Language Models (MLLMs) as the backbone of Optimus-1.
Experimental results show that Optimus-1 exhibits strong generalization with the help of the Hybrid Multimodal Memory module, outperforming the GPT-4V baseline on many tasks.
6. Retrieval Augmented Generation (RAG)
6.1. ReLiK: Retrieve and LinK, Fast and Accurate Entity Linking and Relation Extraction on an Academic Budget

Entity Linking (EL) and Relation Extraction (RE) are fundamental tasks in Natural Language Processing, serving as critical components in a wide range of applications.
In this paper, we propose ReLiK, a Retriever-Reader architecture for both EL and RE, where, given an input text, the Retriever module undertakes the identification of candidate entities or relations that could potentially appear within the text.
Subsequently, the Reader module is tasked to discern the pertinent retrieved entities or relations and establish their alignment with the corresponding textual spans.
Notably, we put forward an innovative input representation that incorporates the candidate entities or relations alongside the text, making it possible to link entities or extract relations in a single forward pass and to fully leverage pre-trained language models contextualization capabilities, in contrast with previous Retriever-Reader-based methods, which require a forward pass for each candidate.
Our formulation of EL and RE achieves state-of-the-art performance in both in-domain and out-of-domain benchmarks while using academic budget training and with up to 40x inference speed compared to competitors.
Finally, we show how our architecture can be used seamlessly for Information Extraction (cIE), i.e. EL + RE, and setting a new state of the art by employing a shared Reader that simultaneously extracts entities and relations.
6.2. RAG Foundry: A Framework for Enhancing LLMs for Retrieval Augmented Generation

Implementing Retrieval-Augmented Generation (RAG) systems is inherently complex, requiring a deep understanding of data, use cases, and intricate design decisions.
Additionally, evaluating these systems presents significant challenges, necessitating assessment of both retrieval accuracy and generative quality through a multi-faceted approach.
We introduce RAG Foundry, an open-source framework for augmenting large language models for RAG use cases. RAG Foundry integrates data creation, training, inference, and evaluation into a single workflow, facilitating the creation of data-augmented datasets for training and evaluating large language models in RAG settings.
This integration enables rapid prototyping and experimentation with various RAG techniques, allowing users to easily generate datasets and train RAG models using internal or specialized knowledge sources.
We demonstrate the framework's effectiveness by augmenting and fine-tuning Llama-3 and Phi-3 models with diverse RAG configurations, showcasing consistent improvements across three knowledge-intensive datasets.
7. Tokenizers
7.1. Trans-Tokenization and Cross-lingual Vocabulary Transfers: Language Adaptation of LLMs for Low-Resource NLP

The development of monolingual language models for low and mid-resource languages continues to be hindered by the difficulty in sourcing high-quality training data.
In this study, we present a novel cross-lingual vocabulary transfer strategy, trans-tokenization, designed to tackle this challenge and enable more efficient language adaptation.
Our approach focuses on adapting a high-resource monolingual LLM to an unseen target language by initializing the token embeddings of the target language using a weighted average of semantically similar token embeddings from the source language.
For this, we leverage a translation resource covering both the source and target languages. We validate our method with the Tweeties, a series of trans-tokenized LLMs, and demonstrate their competitive performance on various downstream tasks across a small but diverse set of languages.
Additionally, we introduce Hydra LLMs, models with multiple swappable language modeling heads and embedding tables, which further extend the capabilities of our trans-tokenization strategy.
By designing a Hydra LLM based on the multilingual model TowerInstruct, we developed a state-of-the-art machine translation model for Tatar, in a zero-shot manner, completely bypassing the need for high-quality parallel data.
This breakthrough is particularly significant for low-resource languages like Tatar, where high-quality parallel data is hard to come by. By lowering the data and time requirements for training high-quality models, our trans-tokenization strategy allows for the development of LLMs for a wider range of languages, especially those with limited resources.
We hope that our work will inspire further research and collaboration in the field of cross-lingual vocabulary transfer and contribute to the empowerment of languages on a global scale.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
