
Important LLM Papers for the Week From 01/09 To 06/09
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers must stay informed about the latest progress.
This article summarizes some of the most important LLM papers published during the First Week of September 2025. The papers cover various topics that shape the next generation of language models, including model optimization and scaling, reasoning, benchmarking, and performance enhancement.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Technical Reports
Vision Language Models
LLM Reasoning
Post Training & RL
Get All My Books, One Button Away With 40% Off

I have created a bundle for my books and roadmaps, so you can buy everything with just one button and for 40% less than the original price. The bundle features 8 eBooks, including:
1. LLM Progress & Technical Reports
1.1. DeepResearch Arena: The First Exam of LLMs’ Research Abilities via Seminar-Grounded Tasks
A new benchmark, DeepResearch Arena, has been introduced to rigorously evaluate the research capabilities of large language models (LLMs).
Grounded in the rich discourse of over 200 academic seminars across 12 disciplines, the benchmark aims to assess “deep research” agents in a more realistic and less leak-prone environment than existing methods.
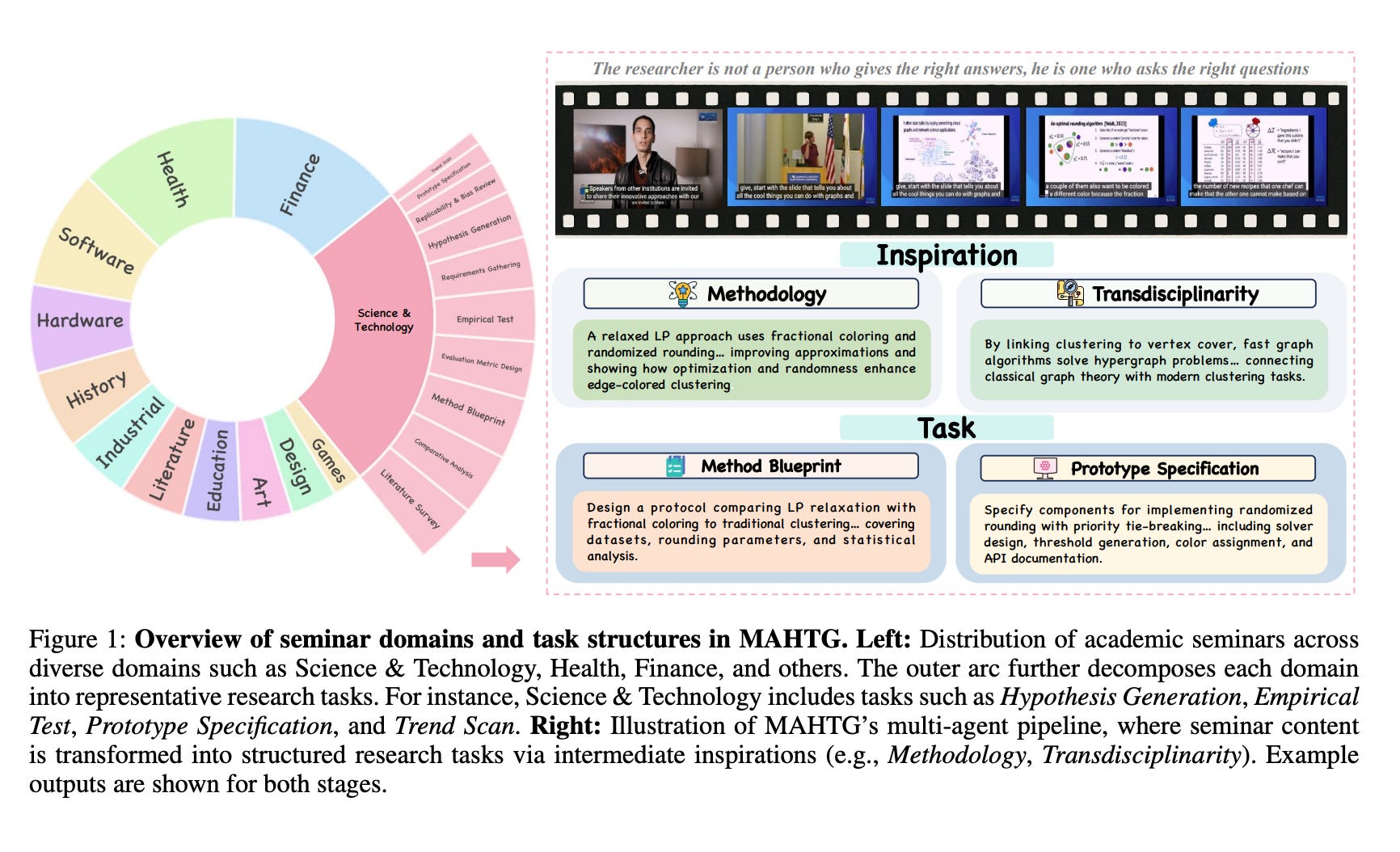
The creators of DeepResearch Arena argue that current benchmarks for evaluating LLMs on research tasks are flawed. Those derived from static sources like academic papers risk “data leakage,” as the content may already be part of the models’ training data.
On the other hand, manually curated benchmarks by experts, while high-quality, are difficult to scale and may lack the spontaneous and diverse nature of real-world research inquiry.
To overcome these limitations, DeepResearch Arena is built upon a novel Multi-Agent Hierarchical Task Generation (MAHTG) system. This system automatically processes transcripts from academic seminars to:
Extract Research-Worthy Inspirations: A multi-agent pipeline identifies novel, challenging, and verifiable research ideas from the expert discussions.
Generate Structured Research Tasks: These inspirations are then systematically transformed into over 10,000 high-quality, open-ended research tasks that reflect authentic academic challenges. The tasks are designed to be traceable and are filtered to remove noise.
Implement a Hybrid Evaluation Framework: The benchmark employs a two-pronged evaluation approach:
Keypoint-Aligned Evaluation (KAE): This metric quantifies the factual accuracy and alignment of a model’s response against key points extracted from relevant sources.
Adaptively-generated Checklist Evaluation (ACE): This uses another LLM to generate a dynamic, rubric-based checklist to assess the quality of open-ended reasoning in a more nuanced way.
The paper presents an extensive evaluation of current state-of-the-art deep research agents using this new benchmark. The results reveal clear performance gaps between different models, highlighting the significant challenges that remain in developing truly capable AI research assistants.
DeepResearch Arena is positioned as the “first exam” for these agents, offering a more faithful and rigorous assessment of their abilities.
Important Resources:
1.2. A.S.E: A Repository-Level Benchmark for Evaluating Security in AI-Generated Code
Researchers have introduced A.S.E (AI Code Generation Security Evaluation), a new benchmark designed to rigorously assess the security of code generated by LLMs at a full repository level. The benchmark addresses critical shortcomings in existing evaluation methods, which often focus on isolated code snippets and lack reproducibility.
As LLMs become increasingly integrated into software development, ensuring the security of the code they produce has become a primary concern.
However, previous benchmarks have failed to capture the complexity of real-world software projects. A.S.E bridges this gap by constructing tasks from actual open-source repositories with documented Common Vulnerabilities and Exposures (CVEs).
This approach preserves the full context of a project, including its build systems and cross-file dependencies, forcing LLMs to reason about security in a more realistic environment.
The A.S.E framework is built to be reproducible and auditable. It uses a containerized (Dockerized) environment and expert-defined rules to provide stable and reliable security assessments, moving beyond subjective LLM-based judgments.
The evaluation is multi-faceted, measuring not only the security of the generated code but also its build quality (whether it compiles and integrates correctly) and generation stability (consistency across repeated attempts).
In an extensive evaluation of 26 leading proprietary and open-source LLMs, the study revealed several key findings:
Top Overall Performance: Claude-3.7-Sonnet from Anthropic achieved the best overall score on the benchmark.
Narrowing Security Gap: The performance gap between proprietary and open-source models in terms of security is surprisingly small. In fact, an open-source model, Qwen3–235B-A22B-Instruct, attained the highest individual security score.
“Fast-Thinking” Wins for Security: Concise, direct decoding strategies (“fast-thinking”) consistently outperformed more complex, multi-step reasoning approaches (“slow-thinking”) when it came to security patching. This suggests that for security fixes, a more direct approach is currently more effective.
The A.S.E benchmark provides a much-needed, realistic tool for the industry to better understand and improve the security of AI-generated code, highlighting current limitations and providing a clear path for future development.
Important Resources:
1.3. A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Keep reading with a 7-day free trial
Subscribe to To Data & Beyond to keep reading this post and get 7 days of free access to the full post archives.