


Important LLM Papers for the Week From 14/04 to 20/04
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Third Week of April 2025. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Technical Reports
LLM Reasoning
LLM Training & Fine-Tuning
AI Agents
Vision Language Models
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. LLM Progress & Technical Reports
1.1. BitNet b1.58 2B4T Technical Report

We introduce BitNet b1.58 2B4T, the first open-source, native 1-bit Large Language Model (LLM) at the 2-billion parameter scale. Trained on a corpus of 4 trillion tokens, the model has been rigorously evaluated across benchmarks covering language understanding, mathematical reasoning, coding proficiency, and conversational ability.
Our results demonstrate that BitNet b1.58 2B4T achieves performance on par with leading open-weight, full-precision LLMs of similar size, while offering significant advantages in computational efficiency, including substantially reduced memory footprint, energy consumption, and decoding latency.
To facilitate further research and adoption, the model weights are released via Hugging Face along with open-source inference implementations for both GPU and CPU architectures.
1.2. TextArena

TextArena is an open-source collection of competitive text-based games for training and evaluation of agentic behavior in Large Language Models (LLMs).
It spans 57+ unique environments (including single-player, two-player, and multi-player setups) and allows for easy evaluation of model capabilities via an online-play system (against humans and other submitted models) with real-time TrueSkill scores.
Traditional benchmarks rarely assess dynamic social skills such as negotiation, theory of mind, and deception, creating a gap that TextArena addresses. Designed with research, community, and extensibility in mind, TextArena emphasizes ease of adding new games, adapting the framework, testing models, playing against the models, and training models.
1.3. Seedream 3.0 Technical Report

We present Seedream 3.0, a high-performance Chinese-English bilingual image generation foundation model. We develop several technical improvements to address existing challenges in Seedream 2.0, including alignment with complicated prompts, fine-grained typography generation, suboptimal visual aesthetics and fidelity, and limited image resolutions.
Specifically, the advancements of Seedream 3.0 stem from improvements across the entire pipeline, from data construction to model deployment. At the data stratum, we double the dataset using a defect-aware training paradigm and a dual-axis collaborative data-sampling framework.
Furthermore, we adopt several effective techniques such as mixed-resolution training, cross-modality RoPE, representation alignment loss, and resolution-aware timestep sampling in the pre-training phase.
During the post-training stage, we utilize diversified aesthetic captions in SFT, and a VLM-based reward model with scaling, thereby achieving outputs that well align with human preferences.
Furthermore, Seedream 3.0 pioneers a novel acceleration paradigm. By employing consistent noise expectation and importance-aware timestep sampling, we achieve a 4 to 8 times speedup while maintaining image quality.
Seedream 3.0 demonstrates significant improvements over Seedream 2.0: it enhances overall capabilities, particularly for text-rendering in complicated Chinese characters, which is important to professional typography generation. In addition, it provides native high-resolution output (up to 2K), allowing it to generate images with high visual quality.
1.4. S1-Bench: A Simple Benchmark for Evaluating System 1 Thinking Capability of Large Reasoning Models
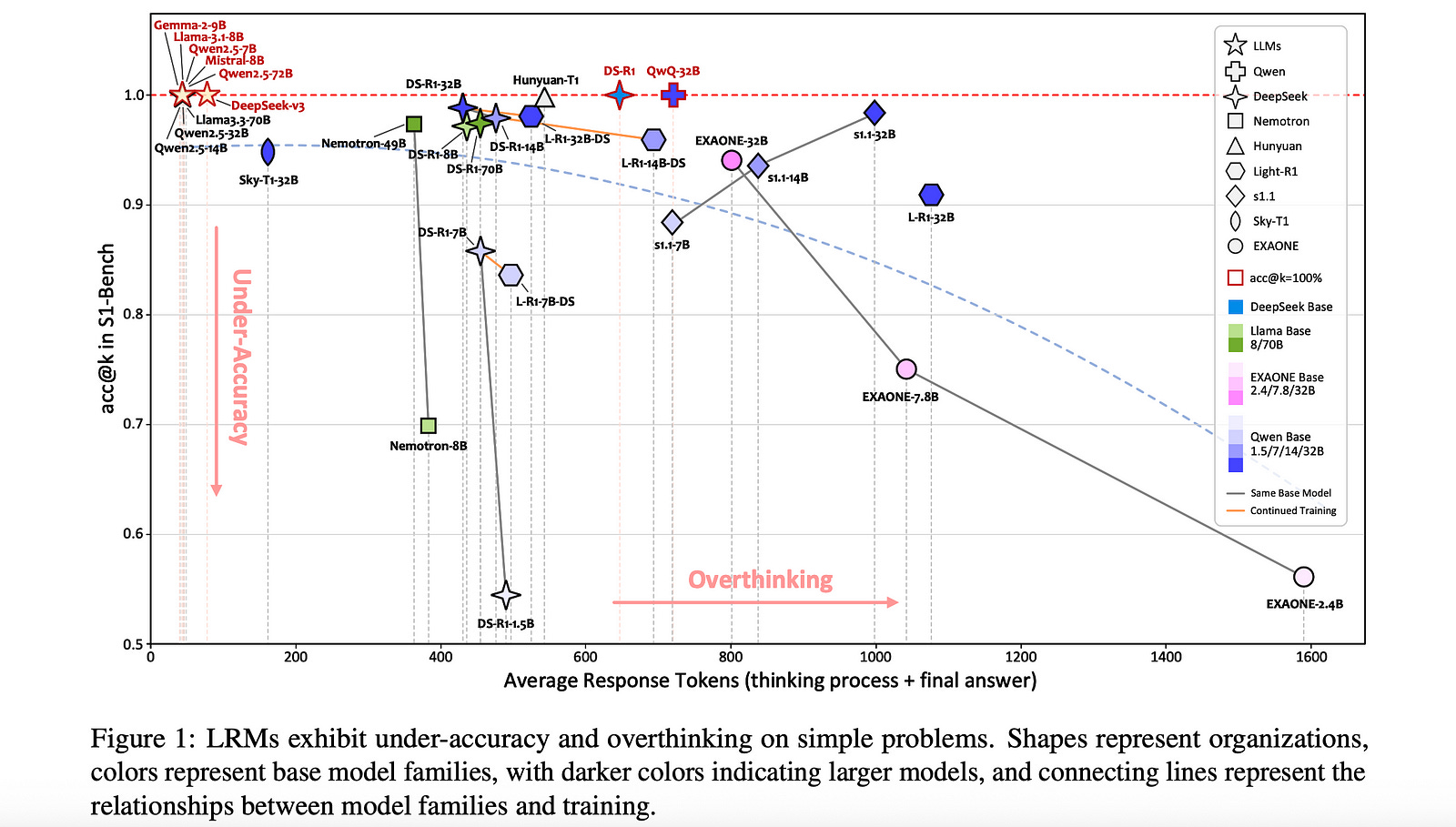
We introduce S1-Bench, a novel benchmark designed to evaluate Large Reasoning Models’ (LRMs) performance on simple tasks that favor intuitive system 1 thinking rather than deliberative system 2 reasoning.
While LRMs have achieved significant breakthroughs in complex reasoning tasks through explicit chains of thought, their reliance on deep analytical thinking may limit their system 1 thinking capabilities.
Moreover, a lack of benchmarks currently exists to evaluate LRMs’ performance in tasks that require such capabilities. To fill this gap, S1-Bench presents a set of simple, diverse, and naturally clear questions across multiple domains and languages, specifically designed to assess LRMs’ performance in such tasks.
Our comprehensive evaluation of 22 LRMs reveals significantly lower efficiency tendencies, with outputs averaging 15.5 times longer than those of traditional small LLMs. Additionally, LRMs often identify correct answers early but continue unnecessary deliberation, with some models even producing numerous errors.
These findings highlight the rigid reasoning patterns of current LRMs and underscore the substantial development needed to achieve balanced dual-system thinking capabilities that can adapt appropriately to task complexity.
1.5. ChartQAPro: A More Diverse and Challenging Benchmark for Chart Question Answering

Charts are ubiquitous, as people often use them to analyze data, answer questions, and discover critical insights. However, performing complex analytical tasks with charts requires significant perceptual and cognitive effort.
Chart Question Answering (CQA) systems automate this process by enabling models to interpret and reason with visual representations of data. However, existing benchmarks like ChartQA lack real-world diversity and have recently shown performance saturation with modern large vision-language models (LVLMs).
To address these limitations, we introduce ChartQAPro, a new benchmark that includes 1,341 charts from 157 diverse sources, spanning various chart types, including infographics and dashboards, and featuring 1,948 questions in various types, such as multiple-choice, conversational, hypothetical, and unanswerable questions, to reflect real-world challenges better.
Our evaluations with 21 models show a substantial performance drop for LVLMs on ChartQAPro; e.g., Claude Sonnet 3.5 scores 90.5% on ChartQA but only 55.81% on ChartQAPro, underscoring the complexity of chart reasoning. We complement our findings with detailed error analyses and ablation studies, identifying key challenges and opportunities for advancing LVLMs in chart understanding and reasoning.
2. LLM Reasoning
2.1. Efficient Reasoning Models: A Survey

Reasoning models have demonstrated remarkable progress in solving complex and logic-intensive tasks by generating extended Chain-of-Thoughts (CoTs) prior to arriving at a final answer.
Yet, the emergence of this “slow-thinking” paradigm, with numerous tokens generated in sequence, inevitably introduces substantial computational overhead. To this end, it highlights an urgent need for effective acceleration.
This survey aims to provide a comprehensive overview of recent advances in efficient reasoning. It categorizes existing works into three key directions:
Shorter — compressing lengthy CoTs into a concise yet effective reasoning chain.
Smaller — developing compact language models with strong reasoning capabilities through techniques such as knowledge distillation, other model compression techniques, and reinforcement learning
Faster — designing efficient decoding strategies to accelerate inference. A curated collection of papers discussed in this survey is available in our GitHub repository.
2.2. How Instruction and Reasoning Data Shape Post-Training: Data Quality through the Lens of Layer-wise Gradients
As the post-training of large language models (LLMs) advances from instruction-following to complex reasoning tasks, understanding how different data affects finetuning dynamics remains largely unexplored.
In this paper, we present a spectral analysis of layer-wise gradients induced by low/high-quality instruction and reasoning data for LLM post-training. Our analysis reveals that widely-studied metrics for data evaluation, e.g., IFD, InsTag, Difficulty, and Reward, can be explained and unified by spectral properties computed from gradients’ singular value decomposition (SVD).
Specifically, higher-quality data are usually associated with lower nuclear norms and higher effective ranks. Notably, effective rank exhibits better robustness and resolution than nuclear norm in capturing subtle quality differences.
For example, reasoning data achieves substantially higher effective ranks than instruction data, implying richer gradient structures on more complex tasks. Our experiments also highlight that models within the same family share similar gradient patterns regardless of their sizes, whereas different model families diverge significantly.
Providing a unified view on the effects of data quality across instruction and reasoning data, this work illuminates the interplay between data quality and training stability, shedding novel insights into developing better data exploration strategies for post-training.
2.3. xVerify: Efficient Answer Verifier for Reasoning Model Evaluations

With the release of the O1 model by OpenAI, reasoning models adopting slow thinking strategies have gradually emerged. As the responses generated by such models often include complex reasoning, intermediate steps, and self-reflection, existing evaluation methods are often inadequate.
They struggle to determine whether the LLM output is truly equivalent to the reference answer, and also have difficulty identifying and extracting the final answer from long, complex responses.
To address this issue, we propose xVerify, an efficient answer verifier for reasoning model evaluations. xVerify demonstrates strong capability in equivalence judgment, enabling it to effectively determine whether the answers produced by reasoning models are equivalent to reference answers across various types of objective questions.
To train and evaluate xVerify, we construct the VAR dataset by collecting question-answer pairs generated by multiple LLMs across various datasets, leveraging multiple reasoning models and challenging evaluation sets designed specifically for reasoning model assessment.
A multi-round annotation process is employed to ensure label accuracy. Based on the VAR dataset, we train multiple xVerify models of different scales. In evaluation experiments conducted on both the test set and generalization set, all xVerify models achieve overall F1 scores and accuracy exceeding 95%.
Notably, the smallest variant, xVerify-0.5B-I, outperforms all evaluation methods except GPT-4o, while xVerify-3B-Ib surpasses GPT-4o in overall performance. These results validate the effectiveness and generalizability of xVerify.
2.4. Genius: A Generalizable and Purely Unsupervised Self-Training Framework For Advanced Reasoning

Advancing LLM reasoning skills has captivated wide interest. However, current post-training techniques rely heavily on supervisory signals, such as outcome supervision or auxiliary reward models, which face the problem of scalability and high annotation costs.
This motivates us to enhance LLM reasoning without the need for external supervision. We introduce a generalizable and purely unsupervised self-training framework, named Genius.
Without an external auxiliary, Genius requires seeking the optimal response sequence in a stepwise manner and optimizing the LLM. To explore the potential steps and exploit the optimal ones, Genius introduces a stepwise foresight re-sampling strategy to sample and estimate the step value by simulating future outcomes.
Further, we recognize that the unsupervised setting inevitably induces the intrinsic noise and uncertainty. To provide a robust optimization, we propose an advantage-calibrated optimization (ACO) loss function to mitigate estimation inconsistencies.
Combining these techniques together, Genius provides an advanced initial step towards self-improving LLM reasoning with general queries and without supervision, revolutionizing reasoning scaling laws given the vast availability of general queries.
3. LLM Training & Fine-Tuning
3.1. PRIMA.CPP: Speeding Up 70B Scale LLM Inference on Low-Resource Everyday Home Clusters

Emergence of DeepSeek R1 and QwQ 32B has broken through performance barriers for running large language models (LLMs) on home devices. While consumer hardware is getting stronger and model quantization is improving, existing end-side solutions still demand GPU clusters, large RAM/VRAM, and high bandwidth, far beyond what a common home cluster can handle.
This paper introduces prima.cpp, a distributed inference system that runs 70 B-scale models on everyday home devices using a mix of CPU/GPU, low RAM/VRAM, Wi-Fi, and cross-platform support. It uses mmap to manage model weights and introduces piped-ring parallelism with prefetching to hide disk loading.
By modeling heterogeneity in computation, communication, disk, memory (and its management behavior), and OS, it optimally assigns model layers to each device’s CPU and GPU, further reducing token latency.
An elegant algorithm named Halda is proposed to solve this NP-hard assignment problem. We evaluate prima.cpp on a common four-node home cluster. It outperforms llama.cpp, exo, and dllama on 30B+ models while keeping memory pressure below 6%.
This brings frontier 30B-70B models, such as Llama 3, DeepSeek R1, Qwen 2.5, and QwQ to home assistants, making advanced AI truly accessible to individuals. The code is open source and available at https://github.com/Lizonghang/prima.cpp.
3.2. AlayaDB: The Data Foundation for Efficient and Effective Long-context LLM Inference

AlayaDB is a cutting-edge vector database system natively architected for efficient and effective long-context inference for Large Language Models (LLMs) at AlayaDB AI.
Specifically, it decouples the KV cache and attention computation from the LLM inference systems and encapsulates them into a novel vector database system. For the Model as a Service providers (MaaS), AlayaDB consumes fewer hardware resources and offers higher generation quality for various workloads with different kinds of Service Level Objectives (SLOs), when compared with the existing alternative solutions (e.g., KV cache disaggregation, retrieval-based sparse attention).
The crux of AlayaDB is that it abstracts the attention computation and cache management for LLM inference into a query processing procedure, and optimizes the performance via a native query optimizer.
In this work, we demonstrate the effectiveness of AlayaDB via (i) three use cases from our industry partners, and (ii) extensive experimental results on LLM inference benchmarks.
3.3. Seaweed-7B: Cost-Effective Training of Video Generation Foundation Model

This technical report presents a cost-efficient strategy for training a video generation foundation model. We present a mid-sized research model with approximately 7 billion parameters (7B) called Seaweed-7B trained from scratch using 665,000 H100 GPU hours.
Despite being trained with moderate computational resources, Seaweed-7B demonstrates highly competitive performance compared to contemporary video generation models of much larger size. Design choices are especially crucial in a resource-constrained setting.
This technical report highlights the key design decisions that enhance the performance of the medium-sized diffusion model. Empirically, we make two observations:
Seaweed-7B achieves performance comparable to, or even surpasses, larger models trained on substantially greater GPU resources
Our model, which exhibits strong generalization ability, can be effectively adapted across a wide range of downstream applications either by lightweight fine-tuning or continuous training.
3.4. Iterative Self-Training for Code Generation via Reinforced Re-Ranking

Generating high-quality code that solves complex programming tasks is challenging, especially with current decoder-based models that produce highly stochastic outputs.
In code generation, even minor errors can easily break the entire solution. Leveraging multiple sampled solutions can significantly improve the overall output quality. One effective way to enhance code generation is by pairing a code generation model with a reranker model, which selects the best solution from the generated samples.
We propose a novel iterative self-training approach for self-training reranker models using Proximal Policy Optimization (PPO), aimed at improving both reranking accuracy and the overall code generation process.
Unlike traditional PPO approaches, where the focus is on optimizing a generative model with a reward model, our approach emphasizes the development of a robust reward/reranking model.
This model improves the quality of generated code through reranking and addresses problems and errors that the reward model might overlook during PPO alignment with the reranker.
Our method iteratively refines the training dataset by re-evaluating outputs, identifying high-scoring negative examples, and incorporating them into the training loop, which boosts model performance.
Our evaluation on the MultiPL-E dataset demonstrates that our 13.4B parameter model outperforms a 33B model in code generation quality while being three times faster. Moreover, it achieves performance comparable to GPT-4 and surpasses it in one programming language.
4. Multimodal Language Models
4.1. InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models

We introduce InternVL3, a significant advancement in the InternVL series featuring a native multimodal pre-training paradigm. Rather than adapting a text-only large language model (LLM) into a multimodal large language model (MLLM) that supports visual inputs, InternVL3 jointly acquires multimodal and linguistic capabilities from both diverse multimodal data and pure-text corpora during a single pre-training stage.
This unified training paradigm effectively addresses the complexities and alignment challenges commonly encountered in conventional post-hoc training pipelines for MLLMs.
To further improve performance and scalability, InternVL3 incorporates variable visual position encoding (V2PE) to support extended multimodal contexts, employs advanced post-training techniques such as supervised fine-tuning (SFT) and mixed preference optimization (MPO), and adopts test-time scaling strategies alongside an optimized training infrastructure. Extensive empirical evaluations demonstrate that InternVL3 delivers superior performance across a wide range of multimodal tasks.
In particular, InternVL3–78B achieves a score of 72.2 on the MMMU benchmark, setting a new state-of-the-art among open-source MLLMs. Its capabilities remain highly competitive with leading proprietary models, including ChatGPT-4o, Claude 3.5 Sonnet, and Gemini 2.5 Pro, while also maintaining strong pure-language proficiency. In pursuit of open-science principles, we will publicly release both the training data and model weights to foster further research and development in next-generation MLLMs.
4.2. SFT or RL? An Early Investigation into Training R1-Like Reasoning Large Vision-Language Models

This work revisits the dominant supervised fine-tuning (SFT) then reinforcement learning (RL) paradigm for training Large Vision-Language Models (LVLMs), and reveals a key finding: SFT can significantly undermine subsequent RL by inducing ``pseudo reasoning paths’’ imitated from expert models.
While these paths may resemble the native reasoning paths of RL models, they often involve prolonged, hesitant, less informative steps and incorrect reasoning.
To systematically study this effect, we introduce VLAA-Thinking, a new multimodal dataset designed to support reasoning in LVLMs. Constructed via a six-step pipeline involving captioning, reasoning distillation, answer rewrite, and verification, VLAA-Thinking comprises high-quality, step-by-step visual reasoning traces for SFT, along with a more challenging RL split from the same data source. Using this dataset, we conduct extensive experiments comparing SFT, RL, and their combinations.
Results show that while SFT helps models learn reasoning formats, it often locks aligned models into imitative, rigid reasoning modes that impede further learning.
In contrast, building on the Group Relative Policy Optimization (GRPO) with a novel mixed reward module integrating both perception and cognition signals, our RL approach fosters more genuine, adaptive reasoning behavior.
Notably, our model VLAA-Thinker, based on Qwen2.5VL 3B, achieves top-1 performance on the Open LMM Reasoning Leaderboard among 4B scale LVLMs, surpassing the previous state-of-the-art by 1.8%. We hope our findings provide valuable insights for developing reasoning-capable LVLMs and can inform future research in this area.
4.3. Generate, but Verify: Reducing Hallucination in Vision-Language Models with Retrospective Resampling

Vision-Language Models (VLMs) excel at visual understanding but often suffer from visual hallucinations, where they generate descriptions of nonexistent objects, actions, or concepts, posing significant risks in safety-critical applications.
Existing hallucination mitigation methods typically follow one of two paradigms: generation adjustment, which modifies decoding behavior to align text with visual inputs, and post-hoc verification, where external models assess and correct outputs.
While effective, generation adjustment methods often rely on heuristics and lack correction mechanisms, while post-hoc verification is complicated, typically requiring multiple models and tending to reject outputs rather than refine them.
In this work, we introduce REVERSE, a unified framework that integrates hallucination-aware training with on-the-fly self-verification. By leveraging a new hallucination-verification dataset containing over 1.3M semi-synthetic samples, along with a novel inference-time retrospective resampling technique, our approach enables VLMs to both detect hallucinations during generation and dynamically revise those hallucinations.
Our evaluations show that REVERSE achieves state-of-the-art hallucination reduction, outperforming the best existing methods by up to 12% on CHAIR-MSCOCO and 28% on HaloQuest.
4.4. FUSION: Fully Integrated Vision-Language Representations for Deep Cross-Modal Understanding
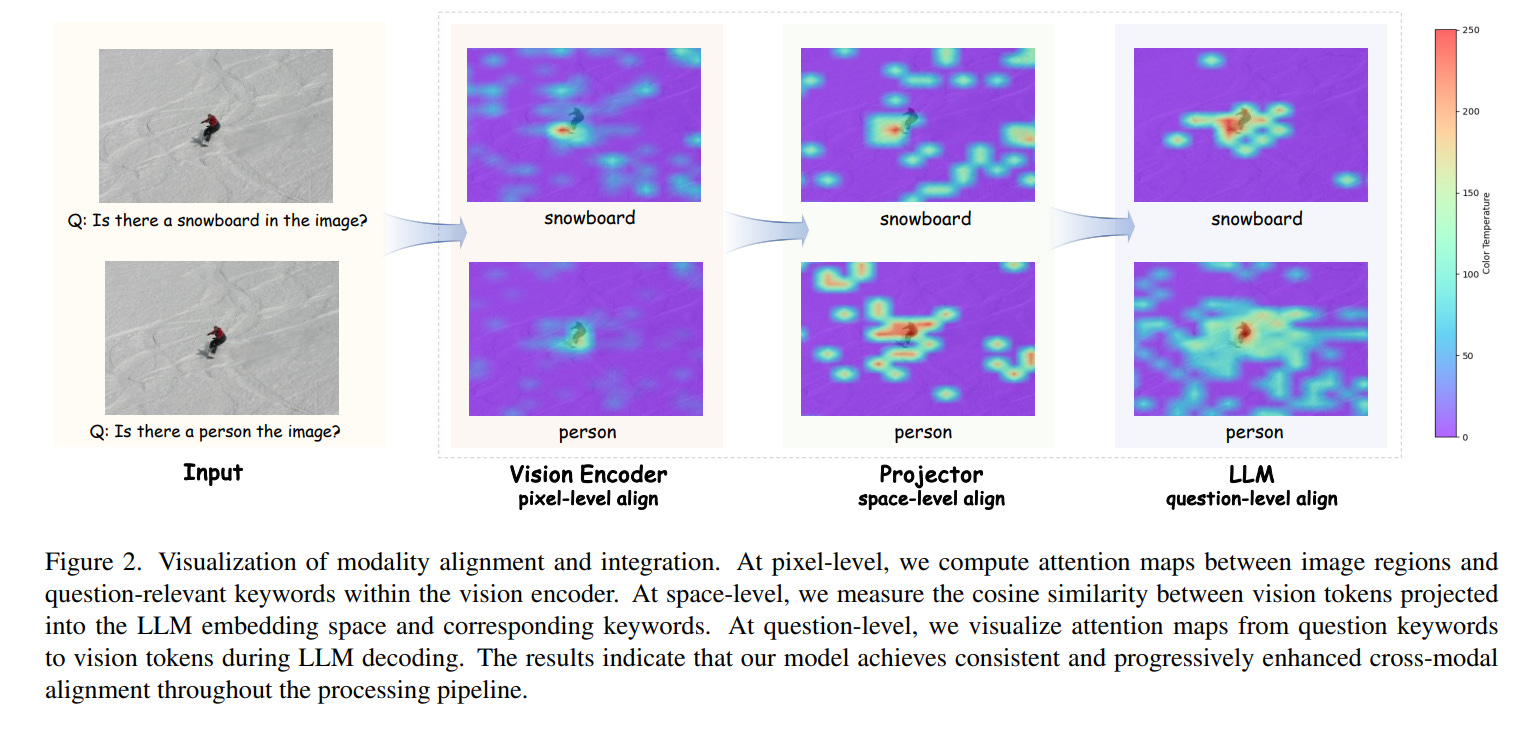
We introduce FUSION, a family of multimodal large language models (MLLMs) with a fully vision-language alignment and integration paradigm. Unlike existing methods that primarily rely on late-stage modality interaction during LLM decoding, our approach achieves deep, dynamic integration throughout the entire processing pipeline.
To this end, we propose Text-Guided Unified Vision Encoding, incorporating textual information in vision encoding to achieve pixel-level integration.
We further design Context-Aware Recursive Alignment Decoding that recursively aggregates visual features conditioned on textual context during decoding, enabling fine-grained, question-level semantic integration. To guide feature mapping and mitigate modality discrepancies, we develop a Dual-Supervised Semantic Mapping Loss.
Additionally, we construct a Synthesized Language-Driven Question-Answer (QA) dataset through a new data synthesis method, prioritizing high-quality QA pairs to optimize text-guided feature integration.
Building on these foundations, we train FUSION at two scales-3B, 8B-and demonstrate that our full-modality integration approach significantly outperforms existing methods with only 630 vision tokens.
Notably, FUSION 3B surpasses Cambrian-1 8B and Florence-VL 8B on most benchmarks. FUSION 3B continues to outperform Cambrian-1 8B even when limited to 300 vision tokens.
Our ablation studies show that FUSION outperforms LLaVA-NeXT on over half of the benchmarks under the same configuration without dynamic resolution, highlighting the effectiveness of our approach.
Are you looking to start a career in data science and AI, but do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
