


Important LLM Papers for the Week from 31/03 to 04/06
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the First Week of April 2025. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Technical Reports
LLM Reasoning
LLM Training & Fine-Tuning
AI Agents
Vision Language Models
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. LLM Progress & Technical Reports
1.1. Efficient Model Selection for Time Series Forecasting via LLMs
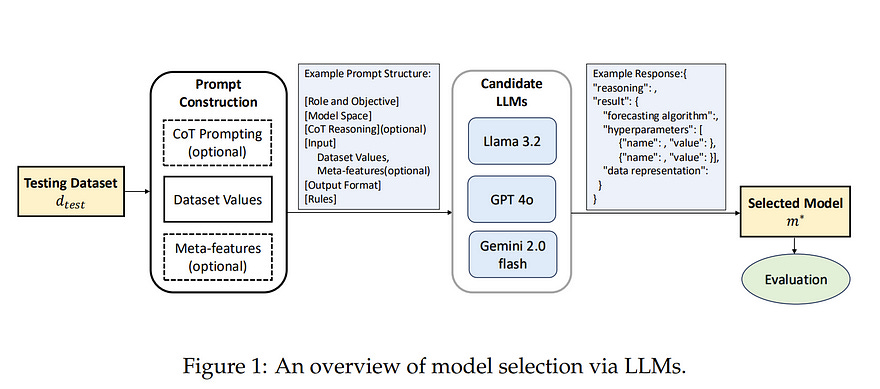
Model selection is a critical step in time series forecasting, traditionally requiring extensive performance evaluations across various datasets. Meta-learning approaches aim to automate this process, but they typically depend on pre-constructed performance matrices, which are costly to build.
In this work, we propose to leverage Large Language Models (LLMs) as a lightweight alternative for model selection. Our method eliminates the need for explicit performance matrices by utilizing the inherent knowledge and reasoning capabilities of LLMs.
Through extensive experiments with LLaMA, GPT, and Gemini, we demonstrate that our approach outperforms traditional meta-learning techniques and heuristic baselines, while significantly reducing computational overhead. These findings underscore the potential of LLMs in efficient model selection for time series forecasting.
1.2. ScholarCopilot: Training Large Language Models for Academic Writing with Accurate Citations

Academic writing requires both coherent text generation and precise citation of relevant literature. Although recent Retrieval-Augmented Generation (RAG) systems have significantly improved factual accuracy in general-purpose text generation, their capacity to adequately support professional academic writing remains limited.
In this work, we introduce ScholarCopilot, a unified framework designed to enhance existing large language models for generating professional academic articles with accurate and contextually relevant citations.
ScholarCopilot dynamically determines when to retrieve scholarly references by generating a retrieval token [RET], and then utilizes its representation to look up relevant citations from a database. The retrieved references are fed into the model to augment the generation process.
We jointly optimize both the generation and citation tasks within a single framework to increase efficiency. Trained on 500K papers from arXiv, our model achieves a top-1 retrieval accuracy of 40.1% on our evaluation dataset, outperforming baselines such as E5-Mistral-7B-Instruct (15.0%) and BM25 (9.8%).
On a dataset of 1,000 academic writing samples, ScholarCopilot scores 16.2/25 in generation quality (measured across relevance, coherence, academic rigor, completeness, and innovation), surpassing models with 10x more parameters such as Qwen-2.5 72 B-Instruct (15.8/25).
Human studies also confirm ScholarCopilot’s superior performance in citation recall, writing efficiency, and overall user experience, confirming the effectiveness of our approach.
1.3. Command A: An Enterprise-Ready Large Language Model

In this report, we describe the development of Command A, a powerful, large language model purpose-built to excel at real-world enterprise use cases.
Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top-of-the-range performance.
It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques.
We also include results for Command R7B, which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes.
This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
1.4. Open-Qwen2VL: Compute-Efficient Pre-Training of Fully-Open Multimodal LLMs on Academic Resources

The reproduction of state-of-the-art multimodal LLM pre-training faces barriers at every stage of the pipeline, including high-quality data filtering, multimodal data mixture strategies, sequence packing techniques, and training frameworks.
We introduce Open-Qwen2VL, a fully open-source 2B-parameter Multimodal Large Language Model pre-trained efficiently on 29M image-text pairs using only 442 A100–40G GPU hours.
Our approach employs low-to-high dynamic image resolution and multimodal sequence packing to significantly enhance pre-training efficiency.
The training dataset was carefully curated using both MLLM-based filtering techniques (e.g., MLM-Filter) and conventional CLIP-based filtering methods, substantially improving data quality and training efficiency.
The Open-Qwen2VL pre-training is conducted on academic level 8xA100–40G GPUs at UCSB on 5B packed multimodal tokens, which is 0.36\% of 1.4T multimodal pre-training tokens of Qwen2-VL.
The final instruction-tuned Open-Qwen2VL outperforms partially-open state-of-the-art MLLM Qwen2-VL-2B on various multimodal benchmarks of MMBench, SEEDBench, MMstar, and MathVista, indicating the remarkable training efficiency of Open-Qwen2VL.
We open-source all aspects of our work, including compute-efficient and data-efficient training details, data filtering methods, sequence packing scripts, pre-training data in WebDataset format, FSDP-based training codebase, and both base and instruction-tuned model checkpoints.
We redefine “fully open” for multimodal LLMs as the complete release of: 1) the training codebase, 2) detailed data filtering techniques, and 3) all pre-training and supervised fine-tuning data used to develop the model.
1.5. PaperBench: Evaluating AI’s Ability to Replicate AI Research

We introduce PaperBench, a benchmark evaluating the ability of AI agents to replicate state-of-the-art AI research. Agents must replicate 20 ICML 2024 Spotlight and Oral papers from scratch, including understanding paper contributions, developing a codebase, and successfully executing experiments.
For objective evaluation, we develop rubrics that hierarchically decompose each replication task into smaller sub-tasks with clear grading criteria. In total, PaperBench contains 8,316 individually gradable tasks. Rubrics are co-developed with the author(s) of each ICML paper for accuracy and realism.
To enable scalable evaluation, we also develop an LLM-based judge to automatically grade replication attempts against rubrics, and assess our judge’s performance by creating a separate benchmark for judges.
We evaluate several frontier models on PaperBench, finding that the best-performing tested agent, Claude 3.5 Sonnet (New) with open-source scaffolding, achieves an average replication score of 21.0\%.
2. LLM Reasoning
2.1. Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
We introduce Open-Reasoner-Zero, the first open source implementation of large-scale reasoning-oriented RL training focusing on scalability, simplicity, and accessibility.
Through extensive experiments, we demonstrate that a minimalist approach, vanilla PPO with GAE (lambda=1, gamma=1) and straightforward rule-based rewards, without any KL regularization, is sufficient to scale up both response length and benchmark performance, similar to the phenomenon observed in DeepSeek-R1-Zero.
Using the same base model as DeepSeek-R1-Zero-Qwen-32B, our implementation achieves superior performance on AIME2024, MATH500, and the GPQA Diamond benchmark while demonstrating remarkable efficiency, requiring only a tenth of the training steps, compared to the DeepSeek-R1-Zero pipeline.
In the spirit of open source, we release our source code, parameter settings, training data, and model weights across various sizes.
2.2. JudgeLRM: Large Reasoning Models as a Judge

The rise of Large Language Models (LLMs) as evaluators offers a scalable alternative to human annotation, yet existing Supervised Fine-Tuning (SFT) for judges approaches often fall short in domains requiring complex reasoning.
In this work, we investigate whether LLM judges truly benefit from enhanced reasoning capabilities. Through a detailed analysis of reasoning requirements across evaluation tasks, we reveal a negative correlation between SFT performance gains and the proportion of reasoning-demanding samples, highlighting the limitations of SFT in such scenarios.
To address this, we introduce JudgeLRM, a family of judgment-oriented LLMs trained using reinforcement learning (RL) with judge-wise, outcome-driven rewards.
JudgeLRM models consistently outperform both SFT-tuned and state-of-the-art reasoning models. Notably, JudgeLRM-3B surpasses GPT-4, and JudgeLRM-7B outperforms DeepSeek-R1 by 2.79% in F1 score, particularly excelling in judge tasks requiring deep reasoning.
2.3. Efficient Inference for Large Reasoning Models: A Survey

Large Reasoning Models (LRMs) significantly improve the reasoning ability of Large Language Models (LLMs) by learning to reason, exhibiting promising performance in complex task-solving.
However, their deliberative reasoning process leads to inefficiencies in token usage, memory consumption, and inference time. Thus, this survey provides a review of efficient inference methods designed specifically for LRMs, focusing on mitigating token inefficiency while preserving the reasoning quality.
First, we introduce a taxonomy to group the recent methods into two main categories: (a) explicit compact Chain-of-Thought (CoT), which reduces tokens while keeping the explicit reasoning structure, and (b) implicit latent CoT, which encodes reasoning steps within hidden representations instead of explicit tokens.
Meanwhile, we discuss their strengths and weaknesses. Then, we conduct empirical analyses on existing methods from performance and efficiency aspects.
Besides, we present open challenges in this field, including human-centric controllable reasoning, trade-off between interpretability and efficiency of reasoning, ensuring safety of efficient reasoning, and broader applications of efficient reasoning. In addition, we highlight key insights for enhancing LRMs’ inference efficiency via techniques such as model merging, new architectures, and agent routers.
2.4. What, How, Where, and How Well? A Survey on Test-Time Scaling in Large Language Models

As enthusiasm for scaling computation (data and parameters) in the pretraining era gradually diminished, test-time scaling (TTS), also referred to as ``test-time computing’’ has emerged as a prominent research focus.
Recent studies demonstrate that TTS can further elicit the problem-solving capabilities of large language models (LLMs), enabling significant breakthroughs not only in specialized reasoning tasks, such as mathematics and coding, but also in general tasks like open-ended Q&A.
However, despite the explosion of recent efforts in this area, there remains an urgent need for a comprehensive survey offering a systemic understanding.
To fill this gap, we propose a unified, multidimensional framework structured along four core dimensions of TTS research: what to scale, how to scale, where to scale, and how well to scale.
Building upon this taxonomy, we conduct an extensive review of methods, application scenarios, and assessment aspects, and present an organized decomposition that highlights the unique functional roles of individual techniques within the broader TTS landscape. From this analysis, we distill the major developmental trajectories of TTS to date and offer hands-on guidelines for practical deployment.
Furthermore, we identify several open challenges and offer insights into promising future directions, including further scaling, clarifying the functional essence of techniques, generalizing to more tasks, and more attributions.
2.5. Harnessing the Reasoning Economy: A Survey of Efficient Reasoning for Large Language Models

Recent advancements in Large Language Models (LLMs) have significantly enhanced their ability to perform complex reasoning tasks, transitioning from fast and intuitive thinking (System 1) to slow and deep reasoning (System 2).
While System 2 reasoning improves task accuracy, it often incurs substantial computational costs due to its slow thinking nature and inefficient or unnecessary reasoning behaviors. In contrast, System 1 reasoning is computationally efficient but leads to suboptimal performance.
Consequently, it is critical to balance the trade-off between performance (benefits) and computational costs (budgets), giving rise to the concept of reasoning economy.
In this survey, we provide a comprehensive analysis of reasoning economy in both the post-training and test-time inference stages of LLMs, encompassing i) the cause of reasoning inefficiency, ii) behavior analysis of different reasoning patterns, and iii) potential solutions to achieve reasoning economy.
By offering actionable insights and highlighting open challenges, we aim to shed light on strategies for improving the reasoning economy of LLMs, thereby serving as a valuable resource for advancing research in this evolving area. We also provide a public repository to continually track developments in this fast-evolving field.
2.6. Effectively Controlling Reasoning Models through Thinking Intervention

Reasoning-enhanced large language models (LLMs) explicitly generate intermediate reasoning steps prior to generating final answers, helping the model excel in complex problem-solving.
In this paper, we demonstrate that this emerging generation framework offers a unique opportunity for more fine-grained control over model behavior.
We propose Thinking Intervention, a novel paradigm designed to explicitly guide the internal reasoning processes of LLMs by strategically inserting or revising specific thinking tokens.
We conduct comprehensive evaluations across multiple tasks, including instruction following on IFEval, instruction hierarchy on SEP, and safety alignment on XSTest and SORRY-Bench.
Our results demonstrate that Thinking Intervention significantly outperforms baseline prompting approaches, achieving up to 6.7% accuracy gains in instruction-following scenarios, 15.4% improvements in reasoning about instruction hierarchies, and a 40.0% increase in refusal rates for unsafe prompts using open-source DeepSeek R1 models. Overall, our work opens a promising new research avenue for controlling reasoning LLMs.
2.7. Recitation over Reasoning: How Cutting-Edge Language Models Can Fail on Elementary School-Level Reasoning Problems?

The rapid escalation from elementary school-level to frontier problems of the difficulty for LLM benchmarks in recent years has woven a miracle for researchers that we are only inches away from surpassing human intelligence.
However, does the LLMs’ remarkable reasoning ability indeed come from true intelligence by human standards, or are they simply reciting solutions witnessed during training at an Internet level?
To study this problem, we propose RoR-Bench, a novel, multi-modal benchmark for detecting LLMs’ recitation behavior when asked simple reasoning problems but with conditions subtly shifted, and conduct empirical analysis on our benchmark.
Surprisingly, we found existing cutting-edge LLMs unanimously exhibit extremely severe recitation behavior; by changing one phrase in the condition, top models such as OpenAI-o1 and DeepSeek-R1 can suffer 60% performance loss on elementary school-level arithmetic and reasoning problems. Such findings are a wake-up call to the LLM community that compels us to re-evaluate the true intelligence level of cutting-edge LLMs.
2.8. Landscape of Thoughts: Visualizing the Reasoning Process of Large Language Models

Numerous applications of large language models (LLMs) rely on their ability to perform step-by-step reasoning. However, the reasoning behavior of LLMs remains poorly understood, posing challenges to research, development, and safety.
To address this gap, we introduce Landscape of thoughts-the first visualization tool for users to inspect the reasoning paths of chain-of-thought and its derivatives on any multi-choice dataset.
Specifically, we represent the states in a reasoning path as feature vectors that quantify their distances to all answer choices. These features are then visualized in two-dimensional plots using t-SNE.
Qualitative and quantitative analysis with the landscape of thoughts effectively distinguishes between strong and weak models, correct and incorrect answers, as well as different reasoning tasks.
It also uncovers undesirable reasoning patterns, such as low consistency and high uncertainty. Additionally, users can adapt our tool to a model that predicts the property they observe. We showcase this advantage by adapting our tool to a lightweight verifier that evaluates the correctness of reasoning paths.
2.9. CodeARC: Benchmarking Reasoning Capabilities of LLM Agents for Inductive Program Synthesis

Inductive program synthesis, or programming by example, requires synthesizing functions from input-output examples that generalize to unseen inputs. While large language model agents have shown promise in programming tasks guided by natural language, their ability to perform inductive program synthesis is underexplored.
Existing evaluation protocols rely on static sets of examples and held-out tests, offering no feedback when synthesized functions are incorrect and failing to reflect real-world scenarios such as reverse engineering.
We propose CodeARC, the Code Abstraction and Reasoning Challenge, a new evaluation framework where agents interact with a hidden target function by querying it with new inputs, synthesizing candidate functions, and iteratively refining their solutions using a differential testing oracle.
This interactive setting encourages agents to perform function calls and self-correction based on feedback. We construct the first large-scale benchmark for general-purpose inductive program synthesis, featuring 1114 functions.
Among 18 models evaluated, o3-mini performs best with a success rate of 52.7%, highlighting the difficulty of this task. Fine-tuning LLaMA-3.1–8B-Instruct on curated synthesis traces yields up to a 31% relative performance gain.
CodeARC provides a more realistic and challenging testbed for evaluating LLM-based program synthesis and inductive reasoning.
2.10. OThink-MR1: Stimulating multimodal generalized reasoning capabilities via dynamic reinforcement learning

Multimodal Large Language Models (MLLMs) have gained significant traction for their ability to process diverse input data types and generate coherent, contextually relevant outputs across various applications.
While supervised fine-tuning (SFT) has been the predominant approach to enhance MLLM capabilities in task-specific optimization, it often falls short in fostering crucial generalized reasoning abilities.
Although reinforcement learning (RL) holds great promise in overcoming these limitations, it encounters two significant challenges: (1) its generalized capacities in multimodal tasks remain largely unexplored, and (2) its training constraints, including the constant Kullback-Leibler divergence or the clamp strategy, often result in suboptimal bottlenecks.
To address these challenges, we propose OThink-MR1, an advanced MLLM equipped with profound comprehension and reasoning capabilities across multimodal tasks. Specifically, we introduce Group Relative Policy Optimization with a dynamic Kullback-Leibler strategy (GRPO-D), which markedly enhances reinforcement learning (RL) performance.
For Qwen2-VL-2B-Instruct, GRPO-D achieves a relative improvement of more than 5.72% over SFT and more than 13.59% over GRPO in the same-task evaluation on two adapted datasets.
Furthermore, GRPO-D demonstrates remarkable cross-task generalization capabilities, with an average relative improvement of more than 61.63% over SFT in cross-task evaluation.
These results highlight that the MLLM trained with GRPO-D on one multimodal task can be effectively transferred to another task, underscoring the superior generalized reasoning capabilities of our proposed OThink-MR1 model.
2.11. A Survey of Efficient Reasoning for Large Reasoning Models: Language, Multimodality, and Beyond
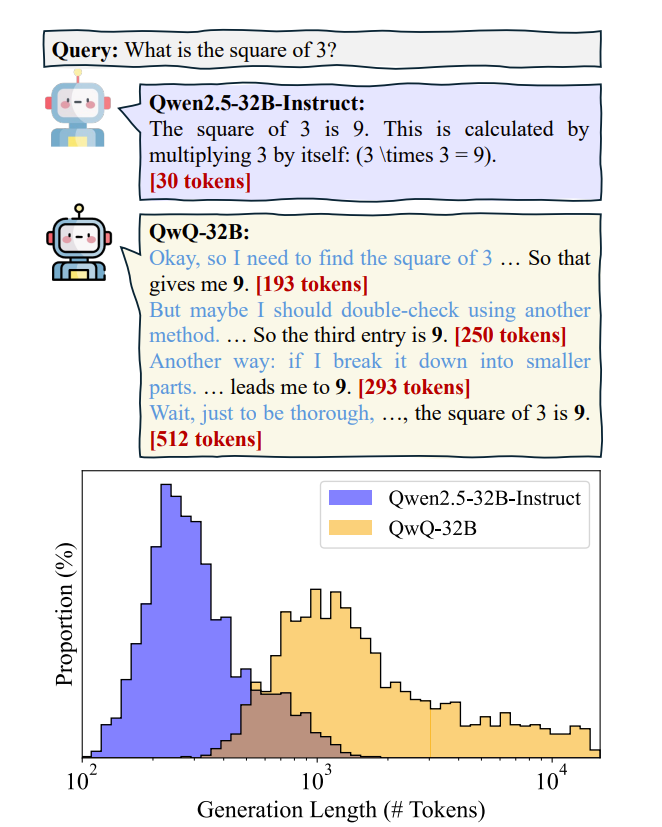
Recent Large Reasoning Models (LRMs), such as DeepSeek-R1 and OpenAI o1, have demonstrated strong performance gains by scaling up the length of Chain-of-Thought (CoT) reasoning during inference.
However, a growing concern lies in their tendency to produce excessively long reasoning traces, which are often filled with redundant content (e.g., repeated definitions), over-analysis of simple problems, and superficial exploration of multiple reasoning paths for harder tasks.
This inefficiency introduces significant challenges for training, inference, and real-world deployment (e.g., in agent-based systems), where token economy is critical. In this survey, we provide a comprehensive overview of recent efforts aimed at improving reasoning efficiency in LRMs, with a particular focus on the unique challenges that arise in this new paradigm.
We identify common patterns of inefficiency, examine methods proposed across the LRM lifecycle, i.e., from pretraining to inference, and discuss promising future directions for research.
To support ongoing development, we also maintain a real-time GitHub repository tracking recent progress in the field. We hope this survey serves as a foundation for further exploration and inspires innovation in this rapidly evolving area.
3. LLM Training & Fine-Tuning
3.1. ActionStudio: A Lightweight Framework for Data and Training of Large Action Models

Action models are essential for enabling autonomous agents to perform complex tasks. However, training large action models remains challenging due to the diversity of agent environments and the complexity of agentic data.
Despite growing interest, existing infrastructure provides limited support for scalable, agent-specific fine-tuning. We present ActionStudio, a lightweight and extensible data and training framework designed for large action models.
ActionStudio unifies heterogeneous agent trajectories through a standardized format, supports diverse training paradigms including LoRA, full fine-tuning, and distributed setups, and integrates robust preprocessing and verification tools.
We validate its effectiveness across both public and realistic industry benchmarks, demonstrating strong performance and practical scalability.
3.2. ZClip: Adaptive Spike Mitigation for LLM Pre-Training
Training large language models (LLMs) presents numerous challenges, including gradient instability and loss spikes. These phenomena can lead to catastrophic divergence, requiring costly checkpoint restoration and data batch skipping.
Traditional gradient clipping techniques, such as constant or norm-based methods, fail to address these issues effectively due to their reliance on fixed thresholds or heuristics, leading to inefficient learning and requiring frequent manual intervention.
In this work, we propose ZClip, an adaptive gradient clipping algorithm that dynamically adjusts the clipping threshold based on statistical properties of gradient norms over time.
Unlike prior reactive strategies, ZClip proactively adapts to training dynamics without making any prior assumptions on the scale and the temporal evolution of gradient norms.
At its core, it leverages z-score-based anomaly detection to identify and mitigate large gradient spikes, preventing malignant loss spikes while not interfering with convergence otherwise.
4. AI Agents
4.1. Advances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems

The advent of large language models (LLMs) has catalyzed a transformative shift in artificial intelligence, paving the way for advanced intelligent agents capable of sophisticated reasoning, robust perception, and versatile action across diverse domains.
As these agents increasingly drive AI research and practical applications, their design, evaluation, and continuous improvement present intricate, multifaceted challenges.
This survey provides a comprehensive overview, framing intelligent agents within a modular, brain-inspired architecture that integrates principles from cognitive science, neuroscience, and computational research. We structure our exploration into four interconnected parts.
First, we delve into the modular foundation of intelligent agents, systematically mapping their cognitive, perceptual, and operational modules onto analogous human brain functionalities, and elucidating core components such as memory, world modeling, reward processing, and emotion-like systems.
Second, we discuss self-enhancement and adaptive evolution mechanisms, exploring how agents autonomously refine their capabilities, adapt to dynamic environments, and achieve continual learning through automated optimization paradigms, including emerging AutoML and LLM-driven optimization strategies.
Third, we examine collaborative and evolutionary multi-agent systems, investigating the collective intelligence emerging from agent interactions, cooperation, and societal structures, highlighting parallels to human social dynamics.
Finally, we address the critical imperative of building safe, secure, and beneficial AI systems, emphasizing intrinsic and extrinsic security threats, ethical alignment, robustness, and practical mitigation strategies necessary for trustworthy real-world deployment.
5. Vision Language Models
5.1. TextCrafter: Accurately Rendering Multiple Texts in Complex Visual Scenes

This paper explores the task of Complex Visual Text Generation (CVTG), which centers on generating intricate textual content distributed across diverse regions within visual images.
In CVTG, image generation models often render distorted and blurred visual text or miss some visual text. To tackle these challenges, we propose TextCrafter, a novel multi-visual text rendering method. TextCrafter employs a progressive strategy to decompose complex visual text into distinct components while ensuring robust alignment between textual content and its visual carrier.
Additionally, it incorporates a token focus enhancement mechanism to amplify the prominence of visual text during the generation process. TextCrafter effectively addresses key challenges in CVTG tasks, such as text confusion, omissions, and blurriness.
Moreover, we present a new benchmark dataset, CVTG-2K, tailored to rigorously evaluate the performance of generative models on CVTG tasks. Extensive experiments demonstrate that our method surpasses state-of-the-art approaches.
5.2. Improved Visual-Spatial Reasoning via R1-Zero-Like Training

Increasing attention has been placed on improving the reasoning capacities of multi-modal large language models (MLLMs). As the cornerstone for AI agents that function in the physical realm, video-based visual-spatial intelligence (VSI) emerges as one of the most pivotal reasoning capabilities of MLLMs.
This work conducts a first, in-depth study on improving the visual-spatial reasoning of MLLMs via R1-Zero-like training. Technically, we first identify that the visual-spatial reasoning capacities of small- to medium-sized Qwen2-VL models cannot be activated via Chain of Thought (CoT) prompts.
We then incorporate GRPO training for improved visual-spatial reasoning, using the carefully curated VSI-100k dataset, following DeepSeek-R1-Zero. During the investigation, we identified the necessity to keep the KL penalty (even with a small value) in GRPO.
With just 120 GPU hours, our vsGRPO-2B model, fine-tuned from Qwen2-VL-2B, can outperform the base model by 12.1% and surpass GPT-4o. Moreover, our vsGRPO-7B model, fine-tuned from Qwen2-VL-7B, achieves performance comparable to that of the best open-source model LLaVA-NeXT-Video-72B.
Additionally, we compare vsGRPO to supervised fine-tuning and direct preference optimization baselines and observe strong performance superiority. The code and dataset will be available soon.
5.3. Envisioning Beyond the Pixels: Benchmarking Reasoning-Informed Visual Editing

Large Multi-modality Models (LMMs) have made significant progress in visual understanding and generation, but they still face challenges in General Visual Editing, particularly in following complex instructions, preserving appearance consistency, and supporting flexible input formats.
To address this gap, we introduce RISEBench, the first benchmark for evaluating Reasoning-Informed viSual Editing (RISE). RISEBench focuses on four key reasoning types: Temporal, Causal, Spatial, and Logical Reasoning.
We curate high-quality test cases for each category and propose an evaluation framework that assesses Instruction Reasoning, Appearance Consistency, and Visual Plausibility with both human judges and an LMM-as-a-judge approach.
Our experiments reveal that while GPT-4o-Native significantly outperforms other open-source and proprietary models, even this state-of-the-art system struggles with logical reasoning tasks, highlighting an area that remains underexplored.
As an initial effort, RISEBench aims to provide foundational insights into reasoning-aware visual editing and to catalyze future research. Though still in its early stages, we are committed to continuously expanding and refining the benchmark to support more comprehensive, reliable, and scalable evaluations of next-generation multimodal systems.
5.4. Rethinking RL Scaling for Vision Language Models: A Transparent, From-Scratch Framework and Comprehensive Evaluation Scheme
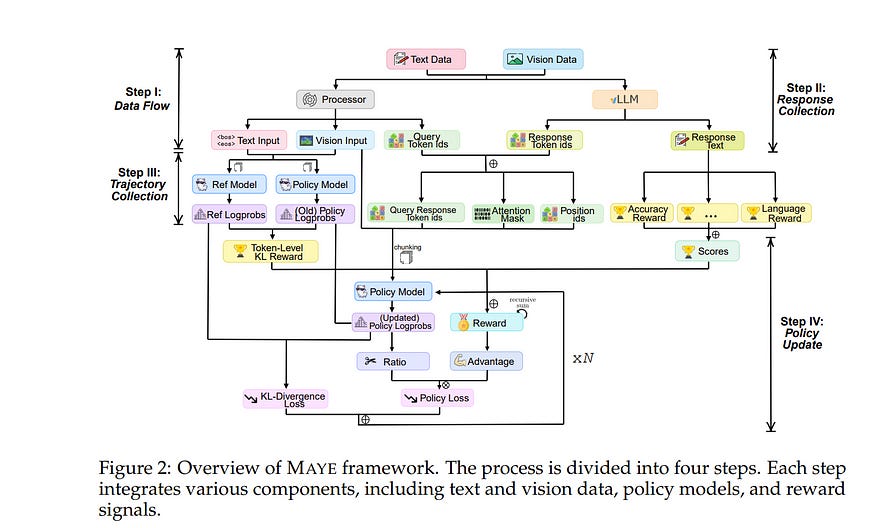
Reinforcement learning (RL) has recently shown strong potential in improving the reasoning capabilities of large language models and is now being actively extended to vision-language models (VLMs).
However, existing RL applications in VLMs often rely on heavily engineered frameworks that hinder reproducibility and accessibility, while lacking standardized evaluation protocols, making it difficult to compare results or interpret training dynamics.
This work introduces a transparent, from-scratch framework for RL in VLMs, offering a minimal yet functional four-step pipeline validated across multiple models and datasets. In addition, a standardized evaluation scheme is proposed to assess training dynamics and reflective behaviors.
Extensive experiments on visual reasoning tasks uncover key empirical findings: response length is sensitive to random seeds, reflection correlates with output length, and RL consistently outperforms supervised fine-tuning (SFT) in generalization, even with high-quality data.
These findings, together with the proposed framework, aim to establish a reproducible baseline and support broader engagement in RL-based VLM research.
Are you looking to start a career in data science and AI, but do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
