


Important LLM Papers for the Week From 07/04 to 14/04
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Second Week of April 2025. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Technical Reports
LLM Reasoning
LLM Training & Fine-Tuning
AI Agents
Vision Language Models
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. LLM Progress & Technical Reports
1.1. Kimi-VL Technical Report

We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities — all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B).
Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models.
Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding.
In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma–3–12B–IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and clearly perceiving them.
With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc.
Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking.
Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities.
It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models.
1.2. Multi-SWE-bench: A Multilingual Benchmark for Issue Resolving
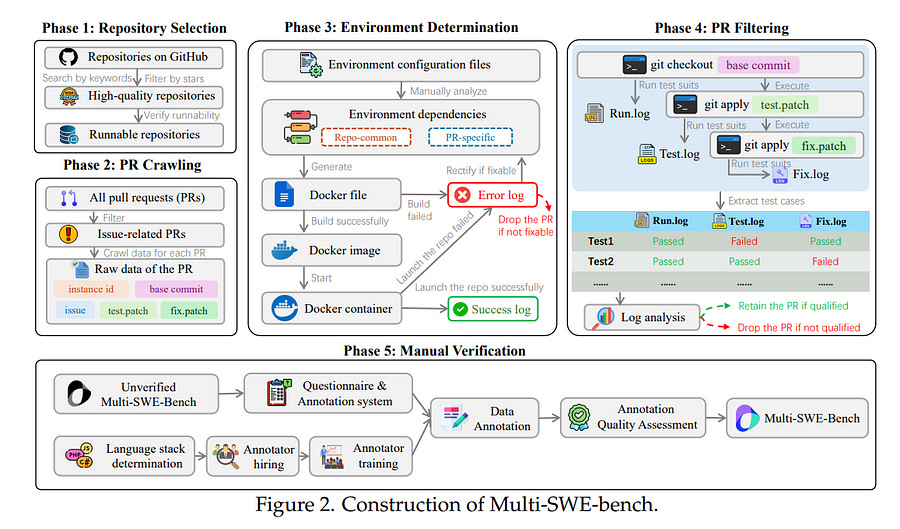
The task of issue resolving is to modify a codebase to generate a patch that addresses a given issue. However, existing benchmarks, such as SWE-bench, focus almost exclusively on Python, making them insufficient for evaluating Large Language Models (LLMs) across diverse software ecosystems.
To address this, we introduce a multilingual issue-resolving benchmark, called Multi-SWE-bench, covering Java, TypeScript, JavaScript, Go, Rust, C, and C++. It includes a total of 1,632 high-quality instances, which were carefully annotated from 2,456 candidates by 68 expert annotators, ensuring that the benchmark can provide an accurate and reliable evaluation.
Based on Multi-SWE-bench, we evaluate a series of state-of-the-art models using three representative methods (Agentless, SWE-agent, and OpenHands) and present a comprehensive analysis with key empirical insights.
In addition, we launch a Multi-SWE-RL open-source community, aimed at building large-scale reinforcement learning (RL) training datasets for issue-resolving tasks. As an initial contribution, we release a set of 4,723 well-structured instances spanning seven programming languages, laying a solid foundation for RL research in this domain.
More importantly, we open-source our entire data production pipeline, along with detailed tutorials, encouraging the open-source community to continuously contribute and expand the dataset.
We envision our Multi-SWE-bench and the ever-growing Multi-SWE-RL community as catalysts for advancing RL toward its full potential, bringing us one step closer to the dawn of AGI.
2. LLM Reasoning
2.1. DeepSeek-R1 Thoughtology: Let’s <think> about LLM Reasoning

Large Reasoning Models like DeepSeek-R1 mark a fundamental shift in how LLMs approach complex problems. Instead of directly producing an answer for a given input, DeepSeek-R1 creates detailed multi-step reasoning chains, seemingly “thinking” about a problem before providing an answer.
This reasoning process is publicly available to the user, creating endless opportunities for studying the reasoning behaviour of the model and opening up the field of Thoughtology.
Starting from a taxonomy of DeepSeek-R1’s basic building blocks of reasoning, our analyses on DeepSeek-R1 investigate the impact and controllability of thought length, management of long or confusing contexts, cultural and safety concerns, and the status of DeepSeek-R1 vis-à-vis cognitive phenomena, such as human-like language processing and world modelling.
Our findings paint a nuanced picture. Notably, we show DeepSeek-R1 has a ‘sweet spot’ of reasoning, where extra inference time can impair model performance.
Furthermore, we find a tendency for DeepSeek-R1 to persistently ruminate on previously explored problem formulations, obstructing further exploration. We also note the strong safety vulnerabilities of DeepSeek-R1 compared to its non-reasoning counterpart, which can compromise safety-aligned LLMs.
2.2. Quantization Hurts Reasoning? An Empirical Study on Quantized Reasoning Models

Recent advancements in reasoning language models have demonstrated remarkable performance in complex tasks, but their extended chain-of-thought reasoning process increases inference overhead.
While quantization has been widely adopted to reduce the inference cost of large language models, its impact on reasoning models remains understudied. In this study, we conduct the first systematic study on quantized reasoning models, evaluating the open-sourced DeepSeek-R1-
Distilled Qwen and LLaMA families ranging from 1.5B to 70B parameters, and QwQ-32B. Our investigation covers weight, KV cache, and activation quantization using state-of-the-art algorithms at varying bit-widths, with extensive evaluation across mathematical (AIME, MATH-500), scientific (GPQA), and programming (LiveCodeBench) reasoning benchmarks.
Our findings reveal that while lossless quantization can be achieved with W8A8 or W4A16 quantization, lower bit-widths introduce significant accuracy risks.
We further identify model size, model origin, and task difficulty as critical determinants of performance. Contrary to expectations, quantized models do not exhibit increased output lengths. In addition, strategically scaling the model sizes or reasoning steps can effectively enhance the performance.
3. LLM Training & Fine-Tuning
3.1. Rethinking Reflection in Pre-Training

A language model’s ability to reflect on its reasoning provides a key advantage for solving complex problems. While most recent research has focused on how this ability develops during reinforcement learning, we show that it begins to emerge much earlier, during the model’s pre-training.
To study this, we introduce deliberate errors into chains of thought and test whether the model can still arrive at the correct answer by recognizing and correcting these mistakes.
By tracking performance across different stages of pre-training, we observe that this self-correcting ability appears early and improves steadily over time. For instance, an OLMo2–7B model pre-trained on 4 trillion tokens displays self-correction on our six self-reflection tasks.
3.2. Hogwild! Inference: Parallel LLM Generation via Concurrent Attention

Large Language Models (LLMs) have demonstrated the ability to tackle increasingly complex tasks through advanced reasoning, long-form content generation, and tool use.
Solving these tasks often involves long inference-time computations. In human problem solving, a common strategy to expedite work is collaboration: by dividing the problem into sub-tasks, exploring different strategies concurrently, etc.
Recent research has shown that LLMs can also operate in parallel by implementing explicit cooperation frameworks, such as voting mechanisms or the explicit creation of independent sub-tasks that can be executed in parallel.
However, each of these frameworks may not be suitable for all types of tasks, which can hinder their applicability. In this work, we propose a different design approach: we run LLM “workers” in parallel, allowing them to synchronize via a concurrently updated attention cache and prompt these workers to decide how best to collaborate.
Our approach allows the instances to come up with their own collaboration strategy for the problem at hand, all the while “seeing” each other’s partial progress in the concurrent cache.
We implement this approach via Hogwild! Inference: a parallel LLM inference engine where multiple instances of the same LLM run in parallel with the same attention cache, with “instant” access to each other’s generated tokens.
Hogwild! inference takes advantage of Rotary Position Embeddings (RoPE) to avoid recomputation while improving parallel hardware utilization. We find that modern reasoning-capable LLMs can perform inference with shared Key-Value cache out of the box, without additional fine-tuning.
3.3. OLMoTrace: Tracing Language Model Outputs Back to Trillions of Training Tokens

We present OLMoTrace, the first system that traces the outputs of language models back to their full, multi-trillion-token training data in real time. OLMoTrace finds and shows verbatim matches between segments of language model output and documents in the training text corpora.
Powered by an extended version of infini-gram (Liu et al., 2024), our system returns tracing results within a few seconds. OLMoTrace can help users understand the behavior of language models through the lens of their training data.
We showcase how it can be used to explore fact-checking, hallucination, and the creativity of language models. OLMoTrace is publicly available and fully open-source.
4. LLM Inference
4.1. Are You Getting What You Pay For? Auditing Model Substitution in LLM APIs
The proliferation of Large Language Models (LLMs) accessed via black-box APIs introduces a significant trust challenge: users pay for services based on advertised model capabilities (e.g., size, performance), but providers may covertly substitute the specified model with a cheaper, lower-quality alternative to reduce operational costs.
This lack of transparency undermines fairness, erodes trust, and complicates reliable benchmarking. Detecting such substitutions is difficult due to the black-box nature, typically limiting interaction to input-output queries. This paper formalizes the problem of model substitution detection in LLM APIs.
We systematically evaluate existing verification techniques, including output-based statistical tests, benchmark evaluations, and log probability analysis, under various realistic attack scenarios like model quantization, randomized substitution, and benchmark evasion.
Our findings reveal the limitations of methods relying solely on text outputs, especially against subtle or adaptive attacks. While log probability analysis offers stronger guarantees when available, its accessibility is often limited.
We conclude by discussing the potential of hardware-based solutions like Trusted Execution Environments (TEEs) as a pathway towards provable model integrity, highlighting the trade-offs between security, performance, and provider adoption.
5. AI Agents
5.1. SynWorld: Virtual Scenario Synthesis for Agentic Action Knowledge Refinement

In the interaction between agents and their environments, agents expand their capabilities by planning and executing actions. However, LLM-based agents face substantial challenges when deployed in novel environments or required to navigate unconventional action spaces.
To empower agents to autonomously explore environments, optimize workflows, and enhance their understanding of actions, we propose SynWorld, a framework that allows agents to synthesize possible scenarios with multi-step action invocation within the action space and perform Monte Carlo Tree Search (MCTS) exploration to effectively refine their action knowledge in the current environment.
Our experiments demonstrate that SynWorld is an effective and general approach to learning action knowledge in new environments.
5.2. ShieldAgent: Shielding Agents via Verifiable Safety Policy Reasoning

Autonomous agents powered by foundation models have seen widespread adoption across various real-world applications. However, they remain highly vulnerable to malicious instructions and attacks, which can result in severe consequences such as privacy breaches and financial losses.
More critically, existing guardrails for LLMs are not applicable due to the complex and dynamic nature of agents. To tackle these challenges, we propose ShieldAgent, the first guardrail agent designed to enforce explicit safety policy compliance for the action trajectory of other protected agents through logical reasoning.
Specifically, ShieldAgent first constructs a safety policy model by extracting verifiable rules from policy documents and structuring them into a set of action-based probabilistic rule circuits.
Given the action trajectory of the protected agent, ShieldAgent retrieves relevant rule circuits and generates a shielding plan, leveraging its comprehensive tool library and executable code for formal verification.
In addition, given the lack of guardrail benchmarks for agents, we introduce ShieldAgent-Bench, a dataset with 3K safety-related pairs of agent instructions and action trajectories, collected via SOTA attacks across 6 web environments and 7 risk categories.
Experiments show that ShieldAgent achieves SOTA on ShieldAgent-Bench and three existing benchmarks, outperforming prior methods by 11.3% on average with a high recall of 90.1%. Additionally, ShieldAgent reduces API queries by 64.7% and inference time by 58.2%, demonstrating its high precision and efficiency in safeguarding agents.
6. Multimodal Language Models
6.1. SmolVLM: Redefining small and efficient multimodal models

Large Vision-Language Models (VLMs) deliver exceptional performance but require significant computational resources, limiting their deployment on mobile and edge devices.
Smaller VLMs typically mirror design choices of larger models, such as extensive image tokenization, leading to inefficient GPU memory usage and constrained practicality for on-device applications.
We introduce SmolVLM, a series of compact multimodal models specifically engineered for resource-efficient inference. We systematically explore architectural configurations, tokenization strategies, and data curation optimized for low computational overhead.
Through this, we identify key design choices that yield substantial performance gains on image and video tasks with minimal memory footprints. Our smallest model, SmolVLM-256M, uses less than 1GB of GPU memory during inference and outperforms the 300-times larger Idefics-80B model, despite an 18-month development gap.
Our largest model, at 2.2B parameters, rivals state-of-the-art VLMs consuming twice the GPU memory. SmolVLM models extend beyond static images, demonstrating robust video comprehension capabilities.
Our results emphasize that strategic architectural optimizations, aggressive yet efficient tokenization, and carefully curated training data significantly enhance multimodal performance, facilitating practical, energy-efficient deployments at significantly smaller scales.
6.2. Skywork R1V: Pioneering Multimodal Reasoning with Chain-of-Thought

We introduce Skywork R1V, a multimodal reasoning model extending the R1-series Large language models (LLMs) to visual modalities via an efficient multimodal transfer method. Leveraging a lightweight visual projector, Skywork R1V facilitates seamless multimodal adaptation without necessitating retraining of either the foundational language model or the vision encoder.
To strengthen visual-text alignment, we propose a hybrid optimization strategy that combines Iterative Supervised Fine-Tuning (SFT) with Group Relative Policy Optimization (GRPO), significantly enhancing cross-modal integration efficiency.
Additionally, we introduce an adaptive-length Chain-of-Thought distillation approach for reasoning data generation. This approach dynamically optimizes reasoning chain lengths, thereby enhancing inference efficiency and preventing excessive reasoning overthinking.
Empirical evaluations demonstrate that Skywork R1V, with only 38B parameters, delivers competitive performance, achieving a score of 69.0 on the MMMU benchmark and 67.5 on MathVista.
Meanwhile, it maintains robust textual reasoning performance, evidenced by impressive scores of 72.0 on AIME and 94.0 on MATH500. The Skywork R1V model weights have been publicly released to promote openness and reproducibility.
6.3. Caption Anything in Video: Fine-grained Object-centric Captioning via Spatiotemporal Multimodal Prompting

We present CAT-V (Caption AnyThing in Video), a training-free framework for fine-grained object-centric video captioning that enables detailed descriptions of user-selected objects through time.
CAT-V integrates three key components: a Segmenter based on SAMURAI for precise object segmentation across frames, a Temporal Analyzer powered by TRACE-Uni for accurate event boundary detection and temporal analysis, and a Captioner using InternVL-2.5 for generating detailed object-centric descriptions.
Through spatiotemporal visual prompts and chain-of-thought reasoning, our framework generates detailed, temporally-aware descriptions of objects’ attributes, actions, statuses, interactions, and environmental contexts without requiring additional training data.
CAT-V supports flexible user interactions through various visual prompts (points, bounding boxes, and irregular regions) and maintains temporal sensitivity by tracking object states and interactions across different time segments.
Our approach addresses limitations of existing video captioning methods, which either produce overly abstract descriptions or lack object-level precision, enabling fine-grained, object-specific descriptions while maintaining temporal coherence and spatial accuracy.
6.4. Scaling Laws for Native Multimodal Models Scaling Laws for Native Multimodal Models
Building general-purpose models that can effectively perceive the world through multimodal signals has been a long-standing goal. Current approaches involve integrating separately pre-trained components, such as connecting vision encoders to LLMs and continuing multimodal training.
While such approaches exhibit remarkable sample efficiency, it remains an open question whether such late-fusion architectures are inherently superior.
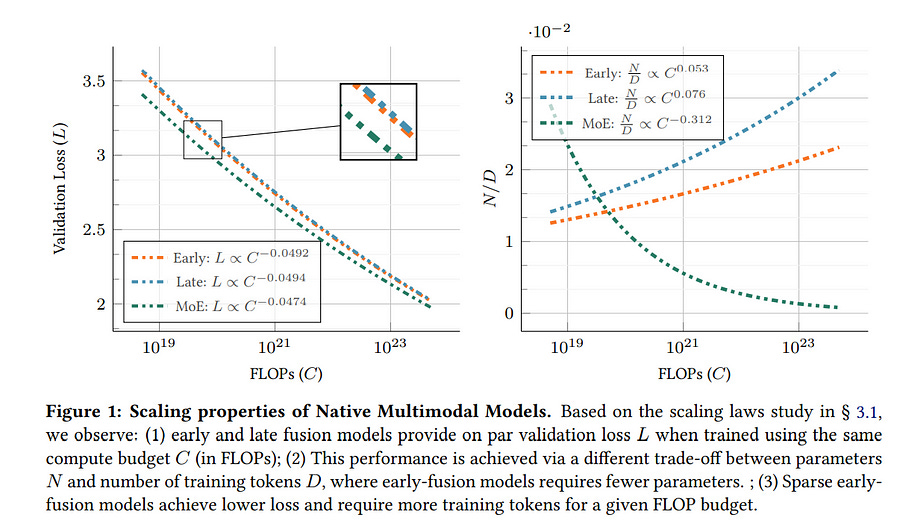
In this work, we revisit the architectural design of native multimodal models (NMMs) — those trained from the ground up on all modalities — and conduct an extensive scaling laws study, spanning 457 trained models with different architectures and training mixtures.
Our investigation reveals no inherent advantage to late-fusion architectures over early-fusion ones, which do not rely on image encoders. On the contrary, early-fusion exhibits stronger performance at lower parameter counts, is more efficient to train, and is easier to deploy.
Motivated by the strong performance of the early-fusion architectures, we show that incorporating Mixture of Experts (MoEs) allows for models that learn modality-specific weights, significantly enhancing performance.
6.5. MM-IFEngine: Towards Multimodal Instruction Following
The Instruction Following (IF) ability measures how well Multi-modal Large Language Models (MLLMs) understand exactly what users are telling them and whether they are doing it right.
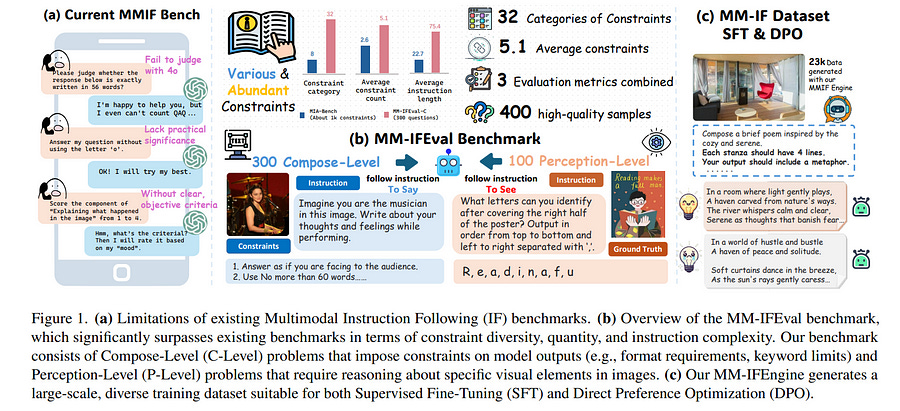
Existing multimodal instruction following training data is scarce, the benchmarks are simple with atomic instructions, and the evaluation strategies are imprecise for tasks demanding exact output constraints. To address this, we present MM-IFEngine, an effective pipeline to generate high-quality image-instruction pairs.
Our MM-IFEngine pipeline yields large-scale, diverse, and high-quality training data MM-IFInstruct-23k, which is suitable for Supervised Fine-Tuning (SFT) and extended as MM-IFDPO-23k for Direct Preference Optimization (DPO).
We further introduce MM-IFEval, a challenging and diverse multi-modal instruction-following benchmark that includes (1) both compose-level constraints for output responses and perception-level constraints tied to the input images, and (2) a comprehensive evaluation pipeline incorporating both rule-based assessment and a judge model.
We conduct SFT and DPO experiments and demonstrate that fine-tuning MLLMs on MM-IFInstruct-23k and MM-IFDPO-23k achieves notable gains on various IF benchmarks, such as MM-IFEval (+10.2%), MIA (+7.6%), and IFEval (+12.3%).
Are you looking to start a career in data science and AI, but do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
