


Important LLM Papers for the Week from 24/03 to 30/03
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Last Week of March 2025. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Technical Reports
LLM Reasoning
LLM Training & Fine-Tuning
AI Agents
Multimodal LLMs
LLM Safety & Alignment
New E-Book: A Beginner to Upper Intermediate Data Science Roadmap

I am happy to announce that I have published a new E-Book: A Beginner to Upper Intermediate Data Science Roadmap. Over the past 14 weeks, I published a series of weekly articles on this topic that will guide learners to start their journey to data science.
1. LLM Progress & Technical Reports
1.1. Qwen2.5-Omni Technical Report

In this report, we present Qwen2.5-Omni, an end-to-end multimodal model designed to perceive diverse modalities, including text, images, audio, and video, while simultaneously generating text and natural speech responses in a streaming manner. To enable the streaming of multimodal information inputs, both audio and visual encoders utilize a block-wise processing approach.
To synchronize the timestamps of video inputs with audio, we organize the audio and video sequentially in an interleaved manner and propose a novel position embedding approach, named TMRoPE(Time-aligned Multimodal RoPE).
To concurrently generate text and speech while avoiding interference between the two modalities, we propose the Thinker-Talker architecture. In this framework, Thinker functions as a large language model tasked with text generation, while Talker is a dual-track autoregressive model that directly utilizes the hidden representations from the Thinker to produce audio tokens as output.
Both the Thinker and Talker models are designed to be trained and inferred in an end-to-end manner. For decoding audio tokens in a streaming manner, we introduce a sliding-window DiT that restricts the receptive field, aiming to reduce the initial package delay.
Qwen2.5-Omni is comparable with the similarly sized Qwen2.5-VL and outperforms Qwen2-Audio. Furthermore, Qwen2.5-Omni achieves state-of-the-art performance on multimodal benchmarks like Omni-Bench.
Notably, Qwen2.5-Omni’s performance in end-to-end speech instruction following is comparable to its capabilities with text inputs, as evidenced by benchmarks such as MMLU and GSM8K.
As for speech generation, Qwen2.5-Omni’s streaming Talker outperforms most existing streaming and non-streaming alternatives in robustness and naturalness.
1.2. Gemma 3 Technical Report

We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages, and longer context, at least 128K tokens.
We also changed the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short.
The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction-finetuned versions.
In particular, our novel post-training recipe significantly improves the math, chat, instruction-following, and multilingual abilities, making Gemma3-4–4B–IT competitive with Gemma2–27 B–IT and Gemma3–27 B–IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
1.3. A Comprehensive Survey on Long Context Language Modeling

Efficient processing of long contexts has been a persistent pursuit in Natural Language Processing. With the growing number of long documents, dialogues, and other textual data, it is important to develop Long Context Language Models (LCLMs) that can process and analyze extensive inputs in an effective and efficient way.
In this paper, we present a comprehensive survey on recent advances in long-context modeling for large language models. Our survey is structured around three key aspects: how to obtain effective and efficient LCLMs, how to train and deploy LCLMs efficiently, and how to evaluate and analyze LCLMs comprehensively.
For the first aspect, we discuss data strategies, architectural designs, and workflow approaches oriented toward long context processing. For the second aspect, we provide a detailed examination of the infrastructure required for LCLM training and inference.
For the third aspect, we present evaluation paradigms for long-context comprehension and long-form generation, as well as behavioral analysis and mechanism interpretability of LCLMs.
Beyond these three key aspects, we thoroughly explore the diverse application scenarios where existing LCLMs have been deployed and outline promising future development directions.
This survey provides an up-to-date review of the literature on long-context LLMs, which we wish to serve as a valuable resource for both researchers and engineers.
2. LLM Reasoning
2.1. I Have Covered All the Bases Here: Interpreting Reasoning Features in Large Language Models via Sparse Autoencoders

Large Language Models (LLMs) have achieved remarkable success in natural language processing. Recent advances have led to the development of a new class of reasoning LLMs; for example, open-source DeepSeek-R1 has achieved state-of-the-art performance by integrating deep thinking and complex reasoning.
Despite these impressive capabilities, the internal reasoning mechanisms of such models remain unexplored. In this work, we employ Sparse Autoencoders (SAEs), a method to learn a sparse decomposition of latent representations of a neural network into interpretable features, to identify features that drive reasoning in the DeepSeek-R1 series of models.
First, we propose an approach to extract candidate ‘’reasoning features’’ from SAE representations. We validate these features through empirical analysis and interpretability methods, demonstrating their direct correlation with the model’s reasoning abilities.
Crucially, we demonstrate that steering these features systematically enhances reasoning performance, offering the first mechanistic account of reasoning in LLMs. Code available at https://github.com/AIRI-Institute/SAE-Reasoning.
2.2. Video-R1: Reinforcing Video Reasoning in MLLMs

Inspired by DeepSeek-R1’s success in eliciting reasoning abilities through rule-based reinforcement learning (RL), we introduce Video-R1 as the first attempt to systematically explore the R1 paradigm for eliciting video reasoning within multimodal large language models (MLLMs).
However, directly applying RL training with the GRPO algorithm to video reasoning presents two primary challenges: (i) a lack of temporal modeling for video reasoning, and (ii) the scarcity of high-quality video-reasoning data. To address these issues, we first propose the T-GRPO algorithm, which encourages models to utilize temporal information in videos for reasoning.
Additionally, instead of relying solely on video data, we incorporate high-quality image-reasoning data into the training process. We have constructed two datasets: Video-R1-COT-165k for SFT cold start and Video–R1–260k for RL training, both comprising image and video data.
Experimental results demonstrate that Video-R1 achieves significant improvements on video reasoning benchmarks such as VideoMMMU and VSI-Bench, as well as on general video benchmarks, including MVBench and TempCompass, etc.
Notably, Video-R1-7 7B attains a 35.8% accuracy on the video spatial reasoning benchmark VSI-bench, surpassing the commercial proprietary model GPT-4o. All codes, models, and data are released.
2.3. ReaRAG: Knowledge-guided Reasoning Enhances Factuality of Large Reasoning Models with Iterative Retrieval Augmented Generation

Large Reasoning Models (LRMs) exhibit remarkable reasoning abilities but rely primarily on parametric knowledge, limiting factual accuracy. While recent works equip reinforcement learning (RL)-based LRMs with retrieval capabilities, they suffer from overthinking and lack robustness in reasoning, reducing their effectiveness in question answering (QA) tasks.
To address this, we propose ReaRAG, a factuality-enhanced reasoning model that explores diverse queries without excessive iterations. Our solution includes a novel data construction framework with an upper bound on the reasoning chain length.
Specifically, we first leverage an LRM to generate deliberate thinking, then select an action from a predefined action space (Search and Finish). For the Search action, a query is executed against the RAG engine, where the result is returned as an observation to guide reasoning steps later.
This process iterates until a Finish action is chosen. Benefiting from ReaRAG’s strong reasoning capabilities, our approach outperforms existing baselines on multi-hop QA.
Further analysis highlights its strong reflective ability to recognize errors and refine its reasoning trajectory. Our study enhances LRMs’ factuality while effectively integrating robust reasoning for Retrieval-Augmented Generation (RAG).
2.4. Think Twice: Enhancing LLM Reasoning by Scaling Multi-round Test-time Thinking

Recent advances in large language models (LLMs), such as OpenAI-o1 and DeepSeek-R1, have demonstrated the effectiveness of test-time scaling, where extended reasoning processes substantially enhance model performance.
Despite this, current models are constrained by limitations in handling long texts and reinforcement learning (RL) training efficiency. To address these issues, we propose a simple yet effective test-time scaling approach, Multi-round Thinking.
This method iteratively refines model reasoning by leveraging previous answers as prompts for subsequent rounds. Extensive experiments across multiple models, including QwQ-32B and DeepSeek-R1, consistently show performance improvements on various benchmarks such as AIME 2024, MATH-500, GPQA-diamond, and LiveCodeBench.
For instance, the accuracy of QwQ-32B improved from 80.3% (Round 1) to 82.1% (Round 2) on the AIME 2024 dataset, while DeepSeek-R1 showed a similar increase from 79.7% to 82.0%.
These results confirm that Multi-round Thinking is a broadly applicable, straightforward approach to achieving stable enhancements in model performance, underscoring its potential for future developments in test-time scaling techniques.
The key prompt: {Original question prompt} The assistant’s previous answer is: <answer> {last round answer} </answer>, and please re-answer.
2.5. Open Deep Search: Democratizing Search with Open-source Reasoning Agents

We introduce Open Deep Search (ODS) to close the increasing gap between the proprietary search AI solutions, such as Perplexity’s Sonar Reasoning Pro and OpenAI’s GPT-4o Search Preview, and their open-source counterparts.
The main innovation introduced in ODS is to augment the reasoning capabilities of the latest open-source LLMs with reasoning agents that can judiciously use web search tools to answer queries. Concretely, ODS consists of two components that work with a base LLM chosen by the user: Open Search Tool and Open Reasoning Agent.
Open Reasoning Agent interprets the given task and completes it by orchestrating a sequence of actions that includes calling tools, one of which is the Open Search Tool. Open Search Tool is a novel web search tool that outperforms proprietary counterparts.
Together with powerful open-source reasoning LLMs, such as DeepSeek-R1, ODS nearly matches and sometimes surpasses the existing state-of-the-art baselines on two benchmarks: SimpleQA and FRAMES.
For example, on the FRAMES evaluation benchmark, ODS improves the best existing baseline of the recently released GPT-4o Search Preview by 9.7% in accuracy.
ODS is a general framework for seamlessly augmenting any LLMs — for example, DeepSeek-R1 that achieves 82.4% on SimpleQA and 30.1% on FRAMES — with search and reasoning capabilities to achieve state-of-the-art performance: 88.3% on SimpleQA and 75.3% on FRAMES.
2.6. Challenging the Boundaries of Reasoning: An Olympiad-Level Math Benchmark for Large Language Models

In recent years, the rapid development of large reasoning models has resulted in the saturation of existing benchmarks for evaluating mathematical reasoning, highlighting the urgent need for more challenging and rigorous evaluation frameworks.
To address this gap, we introduce OlymMATH, a novel Olympiad-level mathematical benchmark, designed to rigorously test the complex reasoning capabilities of LLMs. OlymMATH features 200 meticulously curated problems, each manually verified and available in parallel English and Chinese versions.
The problems are systematically organized into two distinct difficulty tiers: (1) AIME-level problems (easy) that establish a baseline for mathematical reasoning assessment, and (2) significantly more challenging problems (hard) designed to push the boundaries of current state-of-the-art models. In our benchmark, these problems span four core mathematical fields, each including a verifiable numerical solution to enable objective, rule-based evaluation.
Empirical results underscore the significant challenge presented by OlymMATH, with state-of-the-art models including DeepSeek-R1 and OpenAI’s o3-mini demonstrating notably limited accuracy on the hard subset.
Furthermore, the benchmark facilitates comprehensive bilingual assessment of mathematical reasoning abilities critical dimension that remains largely unaddressed in mainstream mathematical reasoning benchmarks.
2.7. LEGO-Puzzles: How Good Are MLLMs at Multi-Step Spatial Reasoning?

Multi-step spatial reasoning entails understanding and reasoning about spatial relationships across multiple sequential steps, which is crucial for tackling complex real-world applications, such as robotic manipulation, autonomous navigation, and automated assembly.
To assess how well current Multimodal Large Language Models (MLLMs) have acquired this fundamental capability, we introduce LEGO-Puzzles, a scalable benchmark designed to evaluate both spatial understanding and sequential reasoning in MLLMs through LEGO-based tasks.
LEGO-Puzzles consists of 1,100 carefully curated visual question-answering (VQA) samples spanning 11 distinct tasks, ranging from basic spatial understanding to complex multi-step reasoning.
Based on LEGO-Puzzles, we conduct a comprehensive evaluation of state-of-the-art MLLMs and uncover significant limitations in their spatial reasoning capabilities: even the most powerful MLLMs can answer only about half of the test cases, whereas human participants achieve over 90% accuracy.
In addition to VQA tasks, we evaluate MLLMs’ abilities to generate LEGO images following assembly illustrations. Our experiments show that only Gemini-2.0-Flash and GPT-4o exhibit a limited ability to follow these instructions, while other MLLMs either replicate the input image or generate completely irrelevant outputs.
Overall, LEGO-Puzzles exposes critical deficiencies in existing MLLMs’ spatial understanding and sequential reasoning capabilities, and underscores the need for further advancements in multimodal spatial reasoning.
3. LLM Training & Fine-Tuning
3.1. Modifying Large Language Model Post-Training for Diverse Creative Writing
As creative writing tasks do not have singular correct answers, large language models (LLMs) trained to perform these tasks should be able to generate diverse valid outputs.
However, LLM post-training often focuses on improving generation quality but neglects to facilitate output diversity. Hence, in creative writing generation, we investigate post-training approaches to promote both output diversity and quality.
Our core idea is to include deviation — the degree of difference between a training sample and all other samples with the same prompt — in the training objective to facilitate learning from rare high-quality instances.
By adopting our approach to direct preference optimization (DPO) and odds ratio preference optimization (ORPO), we demonstrate that we can promote the output diversity of trained models while minimally decreasing quality.
Our best model with 8B parameters could achieve on-par diversity as a human-created dataset while having output quality similar to the best instruction-tuned models we examined, GPT-4o and DeepSeek-R1.
We further validate our approaches with a human evaluation, an ablation, and a comparison to an existing diversification approach, DivPO.
4. AI Agents
4.1. Large Language Model Agent: A Survey on Methodology, Applications and Challenges

Multimodal scientific problems (MSPs) involve complex issues that require the integration of multiple modalities, such as text and diagrams, presenting a significant challenge in artificial intelligence.
While progress has been made in addressing traditional scientific problems, MSPs still face two primary issues: the challenge of multi-modal comprehensive reasoning in scientific problem-solving and the lack of reflective and rethinking capabilities.
To address these issues, we introduce a Multi-Agent framework based on the Big Seven Personality and Socratic guidance (MAPS). This framework employs seven distinct agents that leverage feedback mechanisms and the Socratic method to guide the resolution of MSPs.
To tackle the first issue, we propose a progressive four-agent solving strategy, where each agent focuses on a specific stage of the problem-solving process. For the second issue, we introduce a Critic agent, inspired by Socratic questioning, which prompts critical thinking and stimulates autonomous learning.
We conduct extensive experiments on the EMMA, Olympiad, and MathVista datasets, achieving promising results that outperform the current SOTA model by 15.84% across all tasks. Meanwhile, the additional analytical experiments also verify the model’s progress as well as its generalization ability.
5. Multimodal LLMs
5.1. Exploring Hallucination of Large Multimodal Models in Video Understanding: Benchmark, Analysis and Mitigation

The hallucination of large multimodal models (LMMs), providing responses that appear correct but are actually incorrect, limits their reliability and applicability.
This paper aims to study the hallucination problem of LMMs in video modality, which is dynamic and more challenging compared to static modalities like images and text.
From this motivation, we first present a comprehensive benchmark termed HAVEN for evaluating hallucinations of LMMs in video understanding tasks. It is built upon three dimensions, i.e., hallucination causes, hallucination aspects, and question formats, resulting in 6K questions.
Then, we quantitatively study 7 influential factors on hallucinations, e.g., duration time of videos, model sizes, and model reasoning, via experiments of 16 LMMs on the presented benchmark.
In addition, inspired by recent thinking models like OpenAI o1, we propose a video-thinking model to mitigate the hallucinations of LMMs via supervised reasoning fine-tuning (SRFT) and direct preference optimization (TDPO) — where SRFT enhances reasoning capabilities while TDPO reduces hallucinations in the thinking process.
Extensive experiments and analyses demonstrate the effectiveness. Remarkably, it improves the baseline by 7.65% in accuracy on hallucination evaluation and reduces the bias score by 4.5%.
5.2. Judge Anything: MLLM as a Judge Across Any Modality

Evaluating generative foundation models on open-ended multimodal understanding (MMU) and generation (MMG) tasks across diverse modalities (e.g., images, audio, video) poses significant challenges due to the complexity of cross-modal interactions.
To this end, the idea of utilizing Multimodal LLMs (MLLMs) as automated judges has emerged, with encouraging results in assessing vision-language understanding tasks.
Moving further, this paper extends MLLM-as-a-Judge across modalities to a unified manner by introducing two benchmarks, TaskAnything and JudgeAnything, to respectively evaluate the overall performance and judging capabilities of MLLMs across any-to-any modality tasks.
Specifically, TaskAnything evaluates the MMU and MMG capabilities across 15 any-to-any modality categories, employing 1,500 queries curated from well-established benchmarks.
Furthermore, JudgeAnything evaluates the judging capabilities of 5 advanced (e.g., GPT-4o and Gemini-2.0-Flash) from the perspectives of Pair Comparison and Score Evaluation, providing a standardized testbed that incorporates human judgments and detailed rubrics.
Our extensive experiments reveal that while these MLLMs show promise in assessing MMU (i.e., achieving an average of 66.55% in Pair Comparison setting and 42.79% in Score Evaluation setting), they encounter significant challenges with MMG tasks (i.e., averaging only 53.37% in Pair Comparison setting and 30.05% in Score Evaluation setting), exposing cross-modality biases and hallucination issues.
To address this, we present OmniArena, an automated platform for evaluating omni-models and multimodal reward models. Our work highlights the need for fairer evaluation protocols and stronger alignment with human preferences.
5.3. CoMP: Continual Multimodal Pre-training for Vision Foundation Models

Pre-trained Vision Foundation Models (VFMs) provide strong visual representations for a wide range of applications. In this paper, we continually pre-train prevailing VFMs in a multimodal manner such that they can effortlessly process visual inputs of varying sizes and produce visual representations that are more aligned with language representations, regardless of their original pre-training process.
To this end, we introduce CoMP, a carefully designed multimodal pre-training pipeline. CoMP uses a continuous rotating position embedding to support native resolution continual pre-training and an alignment loss between visual and textual features through language prototypes to align multimodal representations.
By three-stage training, our VFMs achieve remarkable improvements not only in multimodal understanding but also in other downstream tasks such as classification and segmentation.
Remarkably, CoMP-SigLIP achieves scores of 66.7 on ChartQA and 75.9 on DocVQA with a 0.5B LLM, while maintaining an 87.4% accuracy on ImageNet-1K and a 49.5 mIoU on ADE20K under frozen chunk evaluation.
6. LLM Safety & Alignment
6.1. Defeating Prompt Injections by Design
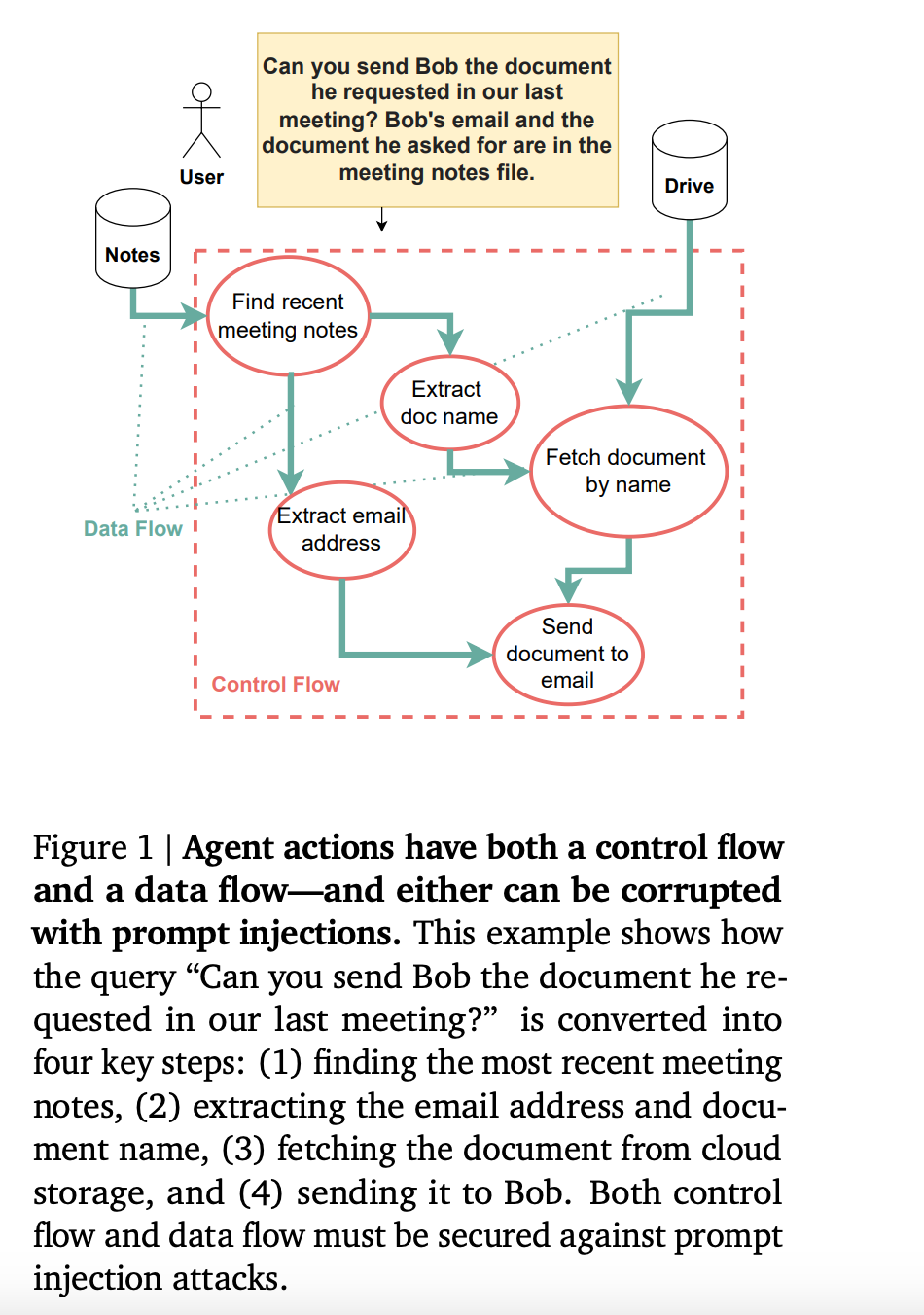
Large Language Models (LLMs) are increasingly deployed in agentic systems that interact with an external environment. However, LLM agents are vulnerable to prompt injection attacks when handling untrusted data.
In this paper, we propose CaMeL, a robust defense that creates a protective system layer around the LLM, securing it even when underlying models may be susceptible to attacks.
To operate, CaMeL explicitly extracts the control and data flows from the (trusted) query; therefore, the untrusted data retrieved by the LLM can never impact the program flow.
To further improve security, CaMeL relies on the capability to prevent the exfiltration of private data over unauthorized data flows. We demonstrate the effectiveness of CaMeL by solving 67% of tasks with provable security in AgentDojo [NeurIPS 2024], a recent agentic security benchmark.
Are you looking to start a career in data science and AI, and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
