


Important LLM Papers for the Week From 16/06 to 22/06
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers must stay informed about the latest progress.
This article summarizes some of the most important LLM papers published during the Third Week of June 2025. The papers cover various topics that shape the next generation of language models, including model optimization and scaling, reasoning, benchmarking, and performance enhancement.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Technical Reports
LLM Reasoning
Agents
Reinforcement Learning & Alignment
Retrieval-Augmented Generation (RAG)
Get All My Books, One Button Away With 40% Off

I have created a bundle for my books and roadmaps, so you can buy everything with just one button and for 40% less than the original price. The bundle features 8 eBooks, including:
1. LLM Progress & Technical Reports
1.1. MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
This paper introduces MiniMax-M1, a new, open-weight, large-scale reasoning model designed for high efficiency and extensive reasoning capabilities.
The model is built on a unique hybrid Mixture-of-Experts (MoE) and “lightning attention” architecture, which allows it to scale test-time compute (the amount of “thinking” it does during inference) far more efficiently than traditional transformer models.
Key features of MiniMax-M1 include a massive 1 million token context window and significantly lower computational cost (FLOPs) for long-sequence generation.
To train this model effectively, the authors also propose a novel reinforcement learning (RL) algorithm called CISPO, which is optimized for stable and efficient training of such architectures.
The paper demonstrates that MiniMax-M1 achieves performance comparable or superior to top open-weight models like DeepSeek-R1 and Qwen3–235B, particularly in complex, real-world tasks like software engineering, agentic tool use, and long-context understanding.
The Problem
State-of-the-art Large Reasoning Models (LRMs) achieve their impressive capabilities by “thinking” for longer during inference (i.e., scaling test-time compute).
However, this is computationally expensive and challenging for standard transformer architectures due to the quadratic complexity of their softmax attention mechanism.
This bottleneck limits the ability to process very long inputs and generate extensive reasoning chains, which are crucial for tackling complex, real-world problems. Furthermore, training such large models with reinforcement learning (RL) is notoriously unstable and inefficient.
The Solution: MiniMax-M1 and CISPO
The authors address these challenges with two main contributions:
1. The MiniMax-M1 Model Architecture:
Hybrid MoE and Lightning Attention: MiniMax-M1 combines a Mixture-of-Experts (MoE) design with “lightning attention,” a highly efficient linear attention mechanism. This hybrid architecture drastically reduces the computational cost of processing long sequences. For example, at a generation length of 100K tokens, M1 uses only 25% of the FLOPs of DeepSeek R1.
Massive Context Window: The model natively supports a 1 million token context length, which is 8 times larger than DeepSeek R1 and an order of magnitude larger than other open-weight models.
Large-Scale Training: The model is based on the 456-billion-parameter MiniMax-Text-01 and is trained using large-scale RL on a diverse set of complex problems, including math, coding, and real-world software engineering tasks in a sandboxed environment.
2. The CISPO Reinforcement Learning Algorithm:
Efficient and Stable RL: Traditional RL algorithms like PPO can be inefficient for training models with novel architectures because they often “clip” or discard important gradient updates from rare but crucial “reflective” tokens (e.g., “However,” “Wait”).
Clipped IS-weight Policy Optimization (CISPO): The authors propose CISPO, a new RL algorithm that avoids this issue. Instead of clipping the token updates, it clips the importance sampling weights. This ensures that all tokens contribute to the training process, leading to more stable and efficient learning, especially for long reasoning chains. CISPO achieved a 2x speedup compared to another advanced RL algorithm, DAPO, in experiments.
Key Results and Findings
Superior Efficiency: The lightning attention architecture makes MiniMax-M1 significantly more efficient. The theoretical FLOPs scale almost linearly with generation length, unlike the quadratic scaling of standard transformers.
Strong Performance on Complex Tasks: MiniMax-M1 is highly competitive with other top open-weight models. It shows particular strengths in:
- Software Engineering (SWE-bench): Achieving scores of 55.6% and 56.0%, surpassing most other open models.
- Agentic Tool Use (TAU-bench): Outperforming all open-weight models and even Gemini 2.5 Pro.
- Long-Context Understanding (OpenAI-MRCR): Leveraging its 1M context window to significantly outperform all other open-weight models, ranking second only to Gemini 2.5 Pro globally.Efficient and Effective RL Training: The combination of the efficient architecture and the CISPO algorithm allowed the full RL training of MiniMax-M1 to be completed in just three weeks on 512 H800 GPUs, a remarkable feat for a model of this scale.
Conclusion and Impact
MiniMax-M1 represents a significant step forward in creating powerful, open, and efficient large-scale reasoning models. Its unique architecture addresses the critical bottleneck of scaling test-time compute, making it uniquely suited for the next generation of AI agents that will need to process vast amounts of context and perform extensive reasoning to solve complex, real-world problems.
The public release of the model and the novel CISPO algorithm provides a strong foundation for future research and development in this area.
Important Resources:
1.2. MultiFinBen: A Multilingual, Multimodal, and Difficulty-Aware Benchmark for Financial LLM Evaluation
This paper introduces MULTIFINBEN, a comprehensive benchmark designed to evaluate Large Language Models (LLMs) on complex, real-world financial tasks.
The authors argue that existing financial benchmarks are too simplistic, focusing mainly on monolingual, text-only tasks, which fail to capture the multimodal and multilingual nature of the global financial industry. MULTIFINBEN is the first benchmark to systematically assess LLMs across text, vision, and audio modalities in multiple languages (English, Chinese, Japanese, Spanish, and Greek).
It introduces novel, challenging tasks, such as multilingual question-answering (PolyFiQA) and the first financial Optical Character Recognition (OCR) tasks. A key innovation is its “difficulty-aware” design, which selects and structures tasks to highlight model weaknesses rather than simply aggregating easy tasks.
Evaluations of 22 state-of-the-art models reveal that even the most powerful LLMs, like GPT-4o, struggle significantly with the benchmark’s complex cross-modal and cross-lingual reasoning demands, underscoring a critical gap in their current capabilities.
The Problem
While LLMs are making strides in finance, existing evaluation benchmarks have two major flaws:
They are Monomodal and Monolingual: Real-world finance involves analyzing diverse inputs like text reports, charts in presentations (vision), and earnings calls (audio), often across multiple languages. Current benchmarks almost exclusively test models on English text.
They Over-rely on Simple Tasks: Many benchmarks are composed of aggregated datasets that are often easy or repetitive. This leads to inflated performance scores that mask the true limitations of models when faced with the complex, nuanced reasoning required in high-stakes financial scenarios.
The Solution: The MULTIFINBEN Benchmark
MULTIFINBEN is designed to address these gaps with a more realistic and rigorous evaluation framework. Its main features are:
Multimodal: It is the first unified financial benchmark to include tasks across text, vision, and audio.
Multilingual: It evaluates models in monolingual, bilingual, and multilingual settings across five economically significant languages.
Novel and Challenging Tasks:
PolyFiQA (Easy & Expert): The first multilingual financial QA tasks that require a model to reason over a mix of financial reports and news articles in different languages to answer a single question.
EnglishOCR & SpanishOCR: The first financial tasks that challenge models to perform OCR on financial documents (like SEC filings) and extract structured information.
Difficulty-Aware Selection: Instead of just lumping datasets together, MULTIFINBEN uses a structured, dynamic approach. It evaluates the difficulty of each dataset (easy, medium, hard) and selects a balanced, compact set of tasks that are most effective at revealing the performance gaps between different models. This avoids over-weighting easy tasks and focuses evaluation on frontier challenges.
Key Findings
Even Top Models Struggle: The best-performing model, GPT-4o, only achieved a score of 50.67%, demonstrating that the benchmark is highly challenging and effectively exposes the limitations of current state-of-the-art LLMs.
Multimodality and Multilinguality are Critical: Models that are only monomodal or monolingual perform very poorly, highlighting the necessity for cross-modal and cross-lingual reasoning capabilities in real-world finance.
Cross-Lingual Reasoning is a Major Weakness: There is a significant performance drop (over 10 percentage points) when models are required to perform multilingual QA compared to monolingual QA, showing that current models struggle with cross-lingual generalization.
Difficulty-Awareness Reveals Steep Performance Drops: The structured difficulty design shows that model performance plummets on harder tasks, with accuracy dropping from 31.24% on easy tasks to just 6.63% on hard ones. The newly introduced PolyFiQA and OCR tasks were among the most difficult for all models.
Conclusion and Impact
MULTIFINBEN provides a more accurate, comprehensive, and challenging way to evaluate LLMs for financial applications. By systematically testing models on the types of multimodal and multilingual tasks they would encounter in the real world, it reveals critical weaknesses that simpler benchmarks miss. The public release of MULTIFINBEN aims to foster more transparent and reproducible research, guiding the development of the next generation of financial LLMs that are robust, inclusive, and capable of handling the true complexity of the global financial domain.
Important Resources:
1.3. DeepResearch Bench: A Comprehensive Benchmark for Deep Research Agents
This paper introduces DeepResearch Bench, the first comprehensive benchmark specifically designed to evaluate “Deep Research Agents” (DRAs) — LLM-based agents that autonomously conduct multi-step web searches and synthesize findings into detailed, citation-rich reports.
The authors argue that existing benchmarks are inadequate for this complex task, as they either test isolated skills (like web browsing) or lack a rigorous evaluation methodology.
To address this, DeepResearch Bench provides 100 PhD-level research tasks across 22 fields, curated based on real-world user queries. The paper also proposes two novel, human-aligned evaluation frameworks: RACE for assessing the quality of the generated reports and FACT for evaluating the accuracy and abundance of citations.
The results show that current agents have significant room for improvement, and the benchmark provides a crucial tool to guide their future development.
The Problem
Deep Research Agents (DRAs) are a powerful new category of AI agents that can automate hours of manual research. However, evaluating them is extremely difficult for two main reasons:
Complexity of the Task: The task is open-ended and complex. There is no single “ground truth” answer for a research query like “Analyze the feasibility of investing in EV charging.”
Lack of Specialized Benchmarks: Existing benchmarks don’t capture the full scope of a DRA’s capabilities. They might test web browsing or text generation in isolation, but not the end-to-end process of research, synthesis, and citation.
This makes it hard to measure progress, compare different agents, and identify specific areas for improvement.
The Solution: DeepResearch Bench and Evaluation Frameworks
The authors tackle this problem with a two-pronged approach:

1. The DeepResearch Bench Dataset:
A benchmark of 100 high-quality, PhD-level research tasks spanning 22 domains (e.g., finance, technology, health).
The task distribution is based on a statistical analysis of over 96,000 real-world user queries to ensure the benchmark reflects authentic research needs.
Each task is meticulously crafted and refined by domain experts to be challenging and realistic.
2. Two Novel Evaluation Frameworks:
RACE (Reference-based Adaptive Criteria-driven Evaluation): This framework evaluates the quality of the generated report. It uses an LLM-as-a-Judge approach but with key innovations:
Adaptive Criteria: Instead of a fixed checklist, it dynamically generates evaluation criteria and weights tailored to each specific research task.
Reference-Based Scoring: To avoid the “all scores are high” problem, it scores a target report relative to a high-quality reference report. This provides a more discriminative and reliable quality score.
FACT (Factual Abundance and Citation Trustworthiness): This framework evaluates the agent’s information retrieval and citation abilities. It works in two automated steps:
Statement-URL Extraction: It extracts every factual claim and its cited URL from the report.
Support Judgment: It then visits the URL to verify if the webpage content actually supports the claim, resulting in a binary “support” or “not support” judgment.
This allows for the calculation of key metrics like Citation Accuracy and Average Effective Citations.
Key Findings
Agent Performance Varies Significantly: The benchmark effectively distinguishes between different agents. For example, Gemini-2.5-Pro Deep Research performed best on report quality (RACE), while Perplexity Deep Research had the highest citation accuracy (FACT).
Report Quality (RACE): Gemini-2.5-Pro and OpenAI’s agents led in generating comprehensive and insightful reports. The RACE framework itself was shown to be highly consistent with human judgments, outperforming simpler evaluation methods.
Citation Quality (FACT): Gemini-2.5-Pro’s agent generated the most effective citations (111 per task), but Perplexity’s agent was the most accurate (90% of its citations were correct). This reveals a trade-off between the quantity and quality of retrieved information.
Human-Alignment: The RACE framework demonstrated strong alignment with human expert evaluations, confirming its reliability for assessing the nuanced quality of long-form research reports.
Conclusion and Impact
DeepResearch Bench is the first dedicated and comprehensive tool for rigorously evaluating the end-to-end capabilities of Deep Research Agents. By providing a challenging, realistic set of tasks and two novel, human-aligned evaluation frameworks (RACE and FACT), it allows developers to measure, compare, and diagnose their agents’ performance in a meaningful way.
This work paves the way for building more powerful, reliable, and human-centric AI agents that can truly accelerate research and knowledge discovery.
Important Resources:
1.4. LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming?
This paper presents LiveCodeBench Pro, a new, highly rigorous benchmark for evaluating the true algorithmic reasoning capabilities of Large Language Models (LLMs) in competitive programming.
The authors, a team including Olympiad medalists, argue that recent claims of LLMs outperforming elite human programmers are premature and based on flawed benchmarks.
LiveCodeBench Pro is built from live, contamination-free programming contests and, most importantly, features deep, expert-level annotation. The study reveals that even the best models have severe limitations: they excel at implementation-heavy tasks but struggle profoundly with problems requiring nuanced algorithmic insight or creative observation, failing on 100% of the hard issues.
The paper concludes that a significant gap remains between LLMs and top human experts, and performance is currently driven more by tool use and implementation precision than by genuine reasoning.
The Problem
Current benchmarks for evaluating LLM coding abilities are insufficient for several reasons:
Data Contamination: Many rely on static, historical problem sets that are likely part of the models’ training data, making it impossible to distinguish between memorization and true problem-solving.
Misleading Metrics: Simple pass/fail rates don’t account for problem difficulty. A model might get a high score by solving many easy problems while failing all hard ones.
Lack of Deep Analysis: They fail to diagnose why a model fails. Is it a flaw in the core algorithm (a conceptual error) or a simple bug in the code (an implementation error)?
Skewed Focus: They often test implementation skill rather than the creative, nuanced reasoning that defines elite human programmers.
The Solution: The LiveCodeBench Pro Benchmark
LiveCodeBench Pro is designed to overcome these limitations and serve as a “diagnostic microscope” for LLM reasoning. Its key features are:

Live and Contamination-Free: Problems are sourced in real-time from top-tier competitions (Codeforces, ICPC, IOI), ensuring they are new to the models and that no solutions are available online during evaluation.
Expert Annotation by Olympiad Medalists: A team of world-class human competitors annotates every problem and failed submission. This includes:
Cognitive-Focus Taxonomy: Problems are categorized as Knowledge-heavy (relying on known templates), Logic-heavy (requiring step-by-step derivation), or Observation-heavy (hinging on a creative “aha” moment).
Line-by-Line Failure Analysis: Experts diagnose the root cause of every failure, pinpointing whether it was a conceptual or implementation error.
3. Difficulty-Aware Elo Rating: Performance is measured using a Bayesian Elo rating system, which accounts for problem difficulty and allows for direct, meaningful comparison with the performance of human contestants.
Key Findings
LLMs Excel at Templates, Struggle with Insight: Models perform well on knowledge-heavy and logic-heavy problems (like data structures or dynamic programming) where solutions are structured and template-based. They perform very poorly on observation-heavy problems (like game theory or greedy algorithms) that require a novel insight.
Conceptual Errors Dominate Model Failures: Unlike humans, whose mistakes are often in implementation, LLMs’ failures are primarily due to flawed algorithmic logic. They are good at writing syntactically correct code, but often for the wrong algorithm. They even frequently fail on the provided sample inputs, a mistake humans rarely make.
Hard Problems are Unsolvable for Current LLMs: The best models achieved 0% pass@1 on “Hard” difficulty problems and only 53% on “Medium” ones without tool access. This highlights a stark gap compared to expert humans.
Reasoning is a Key Differentiator: “Reasoning” models (those using chain-of-thought) show massive performance gains over their non-reasoning counterparts, especially on logic-heavy tasks like combinatorics. However, even this enhanced reasoning is insufficient for tasks that rely heavily on observation.
Conclusion and Impact
LiveCodeBench Pro provides a much more sober and realistic assessment of LLM capabilities in competitive programming. It demonstrates that while LLMs are powerful tools for implementation, they are far from matching the creative and nuanced reasoning of top human experts.
The benchmark offers a crucial, fine-grained tool for the community to diagnose model weaknesses and guide future research toward building LLMs with more genuine algorithmic reasoning skills.
Important Resources:
2. LLM Reasoning
2.1. Scientists’ First Exam: Probing Cognitive Abilities of MLLM via Perception, Understanding, and Reasoning
This paper introduces a new, challenging benchmark called the Scientists’ First Exam (SFE), designed to rigorously evaluate the scientific cognitive abilities of Multimodal Large Language Models (MLLMs).
The authors argue that existing scientific benchmarks are inadequate because they often test general knowledge from textbooks rather than the complex, real-world skills scientists actually use.
SFE addresses this gap by assessing MLLMs across a three-level cognitive hierarchy — Perception, Understanding, and Reasoning — using tasks derived from native scientific data across five disciplines.
The benchmark reveals that even state-of-the-art models like GPT-03 struggle significantly, achieving only a 34.08% score, which highlights a major gap in their capabilities and points toward crucial areas for future improvement in AI-enhanced scientific discovery.
The Problem
While MLLMs show great promise for science, current methods for evaluating them are flawed. Existing benchmarks tend to:
Extract tasks from secondary sources like academic papers or textbooks, not from raw scientific data.
Focus primarily on knowledge understanding, neglecting the crucial cognitive skills of perception (e.g., interpreting a chart or spectrum) and reasoning (e.g., comparing multiple data sources).
Fail to provide a granular assessment of how a model solves a problem.
This results in an incomplete and often inflated view of an MLLM’s true potential for real-world scientific workflows.
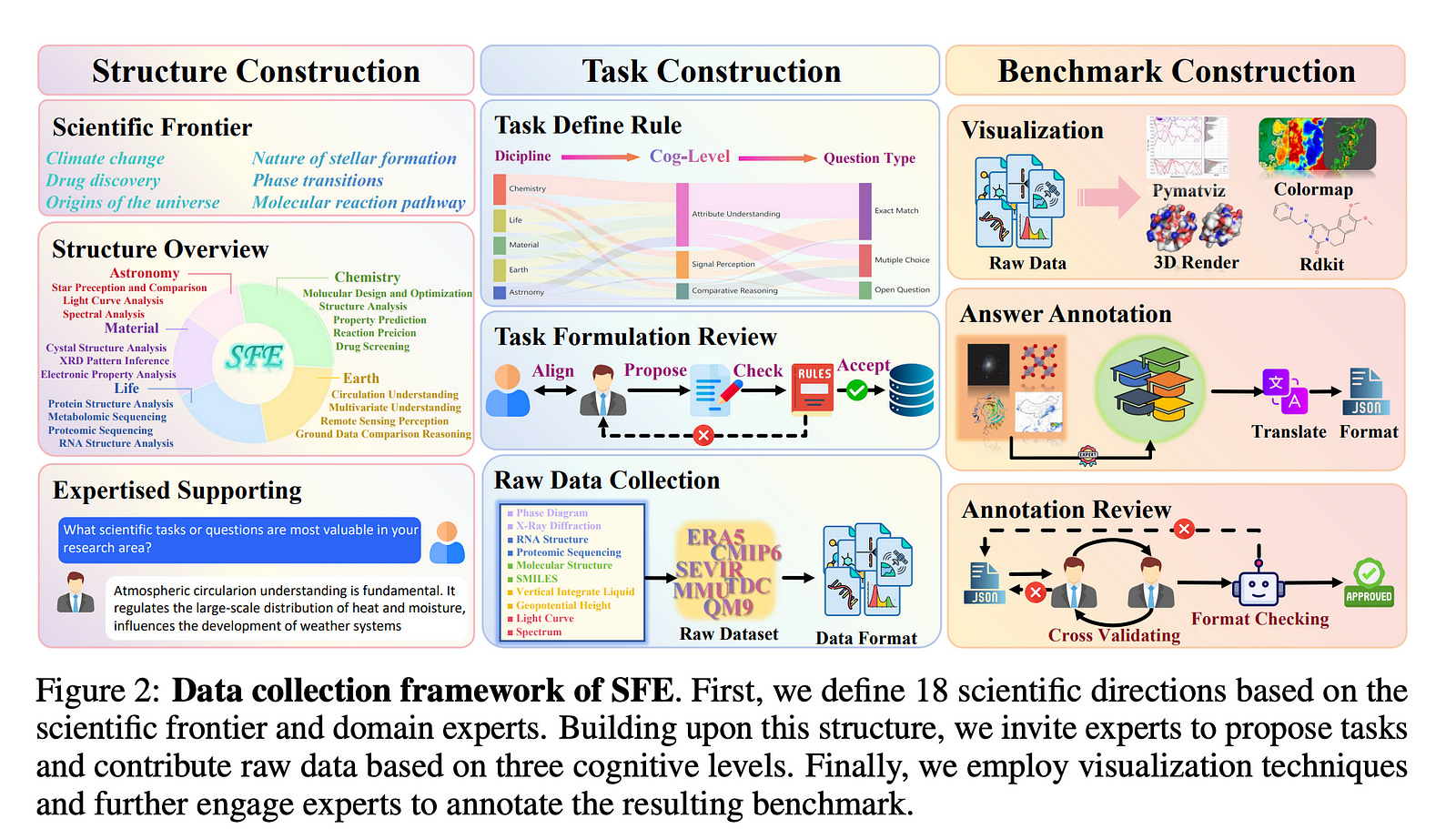
The Solution: The SFE Benchmark
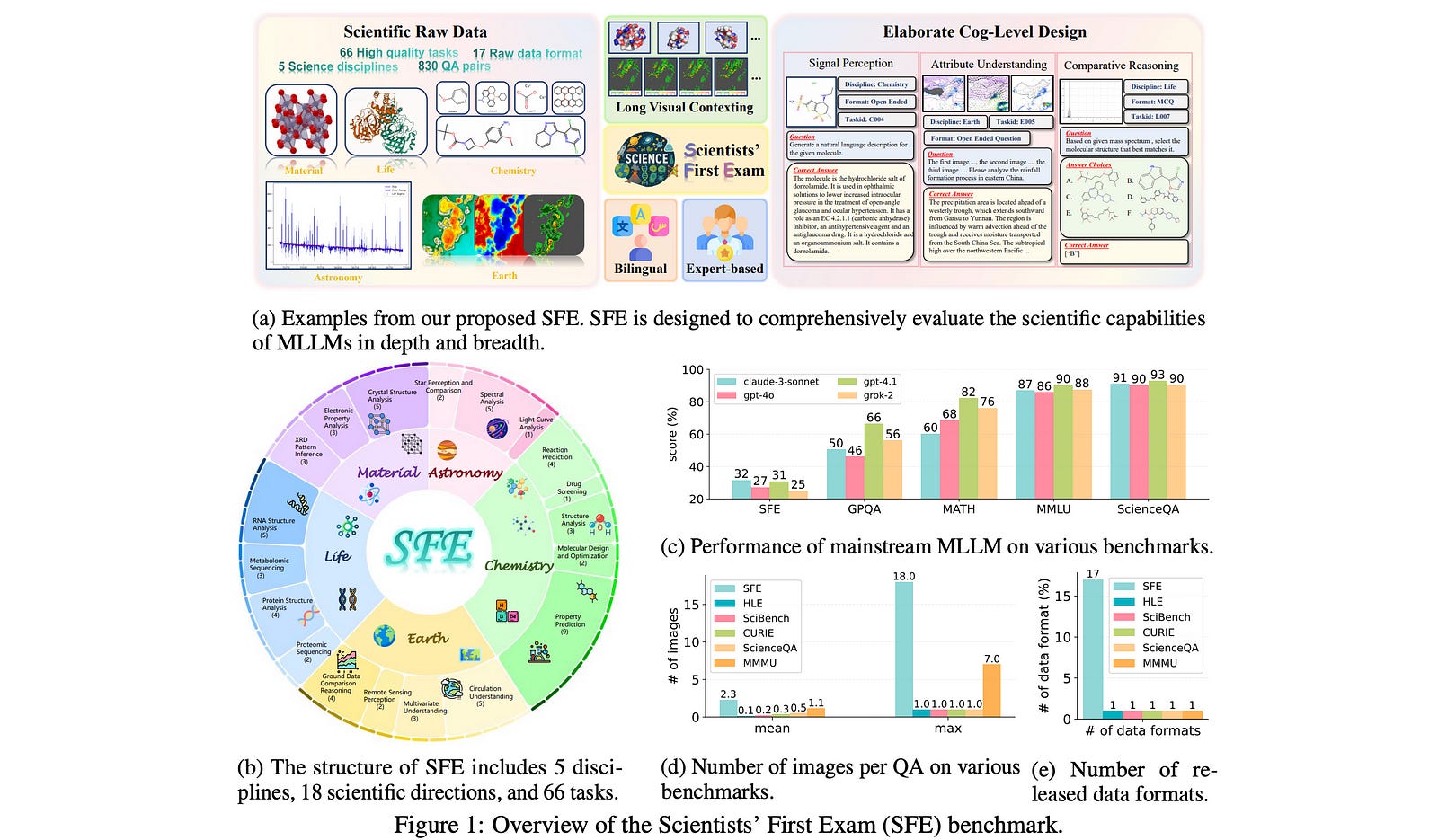
To solve this, the researchers created the Scientists’ First Exam (SFE), a benchmark built from the ground up with expert collaboration. Its key features are:
Three-Level Cognitive Taxonomy: SFE is structured to evaluate a hierarchy of scientific skills:
L1: Scientific Signal Perception: The ability to discern and identify critical components in scientific visualizations (e.g., “Count the carbon atoms in this molecule diagram”).
L2: Scientific Attribute Understanding: The ability to interpret data using domain knowledge (e.g., “Based on this spectrum, what is the star’s temperature?”).
L3: Scientific Comparative Reasoning: The ability to synthesize information and derive insights from multiple visual sources (e.g., “Compare these two weather charts and explain the differences”).
2. Authentic and Diverse Tasks: SFE consists of 830 expert-verified visual question-answering (VQA) pairs across 66 tasks in five key scientific disciplines: Astronomy, Chemistry, Earth, Life, and Materials Sciences.
3. Native Scientific Data: Unlike other benchmarks, SFE uses tasks constructed from real, native scientific data formats (e.g., molecular structures, XRD patterns, satellite imagery, RNA structures).
4. Bilingual and Expert-Curated: All tasks are bilingual (English and Chinese) and have been designed and validated by domain experts to ensure they are meaningful and challenging.
Key Findings
Current MLLMs Struggle Significantly: Even top-tier models perform poorly on SFE. The best-performing model, GPT-03, only scored 34.08%. This confirms that SFE is a challenging benchmark that effectively reveals the limitations of current models in real scientific tasks.
SFE Can Differentiate Model Capabilities: The benchmark clearly distinguishes between the performance of different models, showing a systematic gap between proprietary closed-weight models (like the GPT series) and open-source ones.
A Shift from Knowledge to Reasoning: The most interesting finding is that newer MLLMs show greater improvements on L3 (Reasoning) tasks than on L2 (Understanding) tasks. This suggests that recent advances in AI are more about enhancing reasoning processes (like Chain-of-Thought) rather than simply accumulating more knowledge.
Conclusion and Impact
The SFE benchmark provides a much-needed, granular, and realistic tool for measuring the true scientific reasoning capabilities of MLLMs. By moving beyond simple knowledge tests to probe the cognitive pipeline from perception to reasoning, it offers a clear path for diagnosing model weaknesses and guiding the development of more powerful and reliable AI assistants for scientific discovery.
Important Resources:
Keep reading with a 7-day free trial
Subscribe to To Data & Beyond to keep reading this post and get 7 days of free access to the full post archives.