


Important LLM Papers for the Week From 09/06 to 15/06
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers must stay informed about the latest progress.
This article summarizes some of the most important LLM papers published during the Second Week of June 2025. The papers cover various topics that shape the next generation of language models, including model optimization and scaling, reasoning, benchmarking, and performance enhancement.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Technical Reports
LLM Reasoning
LLM Training & Fine-Tuning
Vision Language Models
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. LLM Progress & Technical Reports
1.1. MiniCPM4: Ultra-Efficient LLMs on End Devices
Large Language Models (LLMs) have become incredibly powerful, but their ever-increasing size makes them computationally expensive and difficult to deploy on resource-constrained “end devices” like smartphones and personal computers. This limits their accessibility and real-world applications. The central challenge is to create smaller, highly efficient LLMs that maintain strong performance without needing massive cloud infrastructure.
Proposed Solution: MiniCPM4
This paper introduces MiniCPM4, a family of highly efficient LLMs (available in 0.5B and 8B parameter versions) specifically designed for on-device operation.
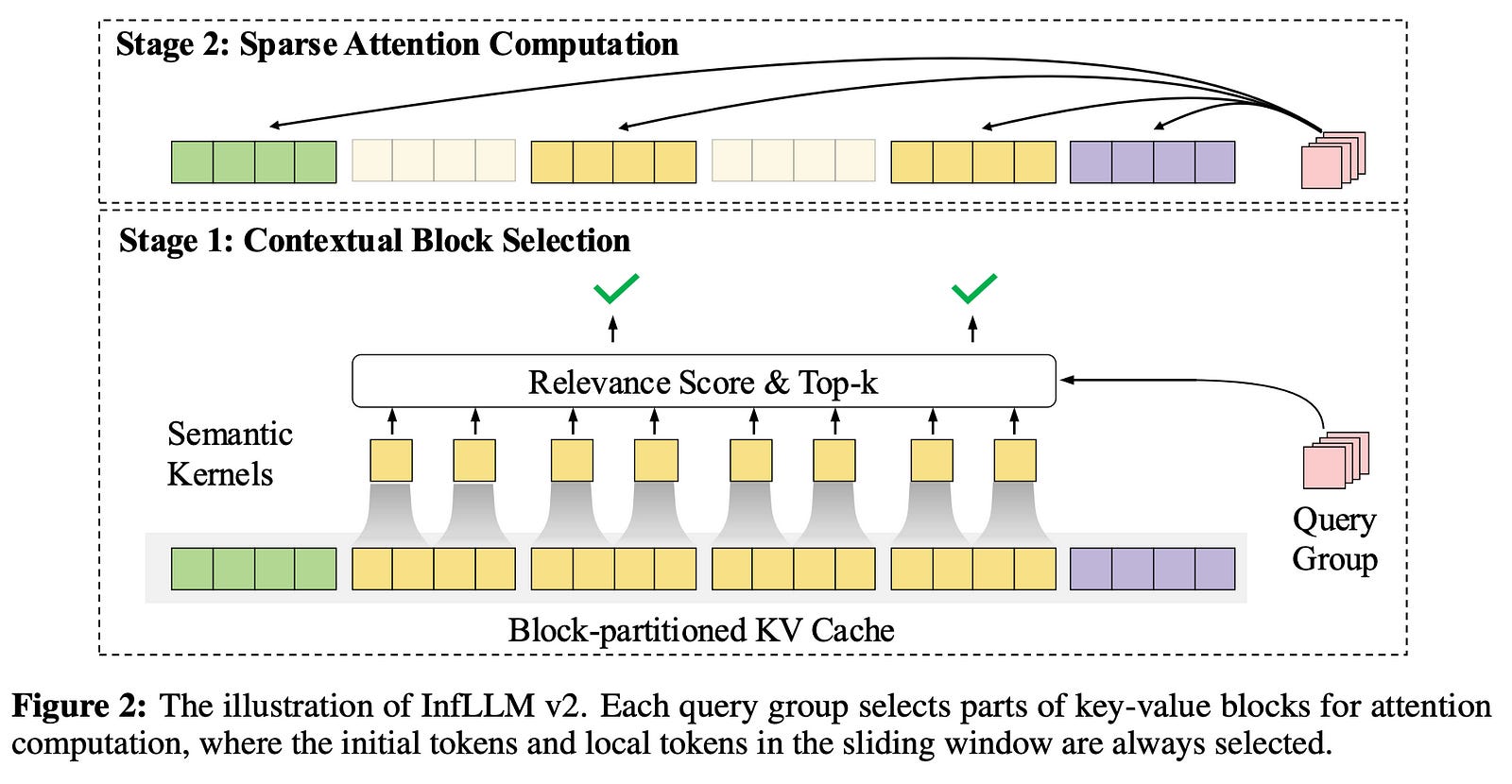
The project achieves its efficiency through a holistic, four-pronged innovation strategy:
Model Architecture (InfLLM v2): They developed a trainable sparse attention mechanism. Instead of attending to every token in a long context (which is slow), it intelligently selects only the most relevant blocks of text. This drastically speeds up both the initial processing (prefilling) and token-by-token generation (decoding) for long documents.
Training Data (UltraClean & UltraChat v2):
UltraClean: A highly efficient pipeline to filter massive web datasets and extract only high-quality, knowledge-intensive data.
UltraChat v2: A strategy to generate high-quality, reasoning-intensive conversational data.
These data strategies allow MiniCPM4 to achieve performance comparable to models trained on 4.5x more data (e.g., 8 trillion vs. 36 trillion tokens for Qwen3–8B).
3. Training Algorithms:
ModelTunnel v2: An efficient method to find the best training hyperparameters by experimenting on small-scale models and transferring the optimal settings to larger ones.
Chunk-wise Rollout: A load-balancing strategy for Reinforcement Learning (RL) that breaks long reasoning tasks into smaller chunks, improving GPU utilization and training stability.
BitCPM4: An efficient Quantization-Aware Training (QAT) framework to create extremely low-bit (ternary) models for devices with very tight memory constraints.
4. Inference Systems:
CPM.cu: A lightweight and highly optimized CUDA inference framework for NVIDIA GPUs. It integrates sparse attention, speculative sampling, and advanced quantization to maximize speed.
ArkInfer: A cross-platform deployment system that acts as a universal adapter, allowing MiniCPM4 to run efficiently on a wide variety of chips (from Nvidia, MediaTek, Qualcomm, etc.) without needing to be re-engineered for each one.
Key Results and Findings
Exceptional Performance: MiniCPM4 outperforms open-source models of similar sizes on a wide range of benchmarks. The 0.5B model even surpasses larger 1B models, and the 8B model is competitive with or better than models up to 14B parameters.
Massive Speed Improvements: The specialized architecture and inference engine deliver huge efficiency gains. For example, when processing a 128k-token document on a Jetson AGX Orin (a common edge device), MiniCPM4–8B is 7 times faster than Qwen3–8B.
Data Efficiency: The model achieves its strong performance using only 22% of the training data compared to leading competitors like Qwen3, proving the “quality over quantity” principle for data.
Broad Usability: Through further adaptation, MiniCPM4 is shown to be effective in complex, real-world applications like generating trustworthy literature surveys and advanced tool use, demonstrating its practical value.
Conclusion
MiniCPM4 represents a significant step forward in creating powerful yet ultra-efficient LLMs for end devices. By systematically co-designing the model architecture, data, training, and inference systems, the authors have produced a model that is not only high-performing but also practical and accessible, pushing the boundaries of what is possible with AI on personal hardware.
Important Resources:
1.2. Leveraging Self-Attention for Input-Dependent Soft Prompting in LLMs
Fully fine-tuning Large Language Models (LLMs) for specific tasks is computationally expensive and complex. Parameter-Efficient Fine-Tuning (PEFT) methods, particularly soft prompting, address this by freezing the main model and only training a small set of “soft prompt” parameters. However, most soft prompting methods learn a single, static (input-independent) prompt, which is suboptimal as the ideal prompt likely varies for different inputs.
Proposed Solution: ID-SPAM
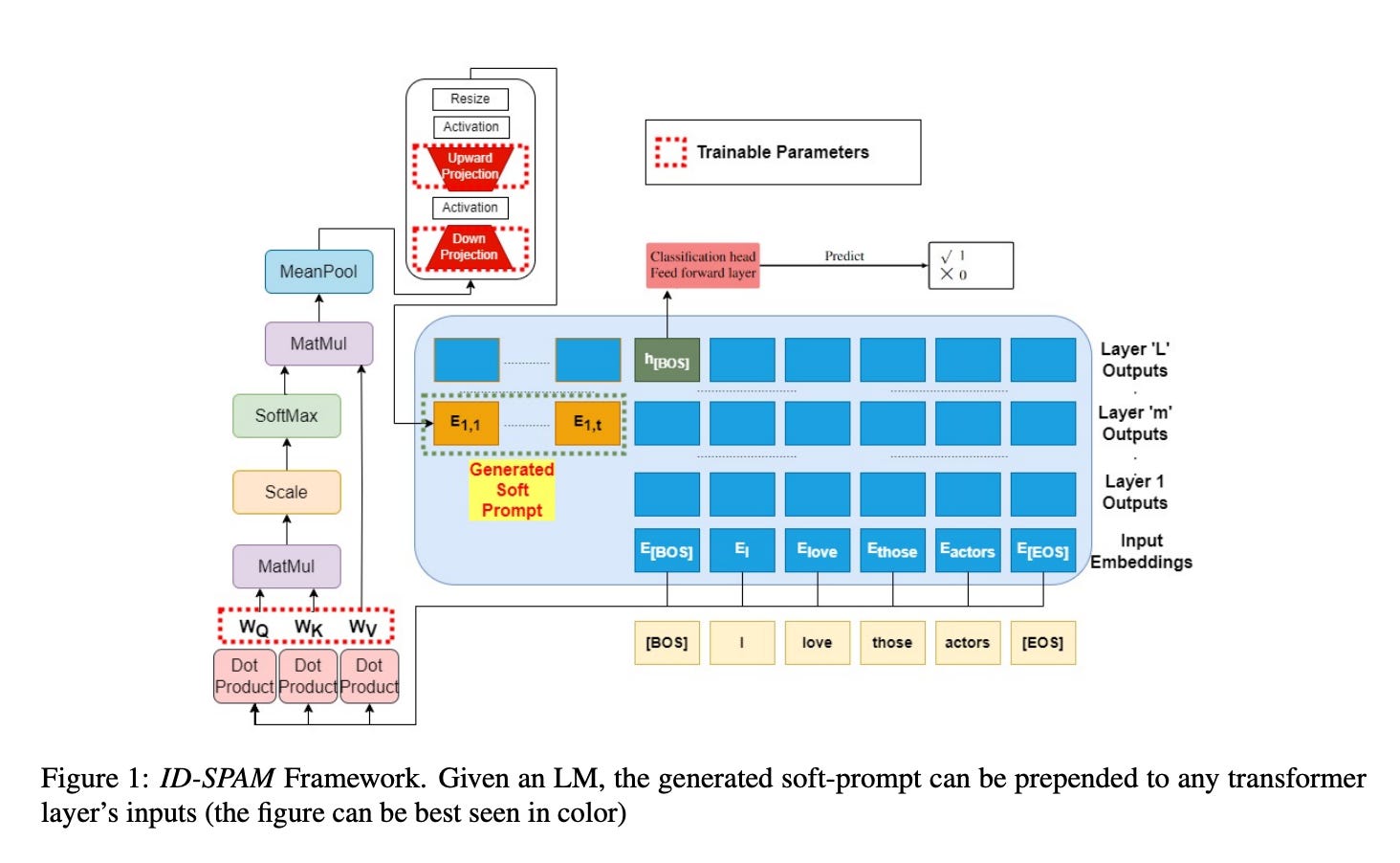
The paper proposes a novel technique called ID-SPAM (Input-Dependent Soft Prompting with a Self-Attention Mechanism). Instead of learning a static prompt, ID-SPAM generates a unique soft prompt tailored to each input instance.
Here’s how it works:
Attend to Input: It takes the embeddings of the input text and feeds them into a small, learnable self-attention layer. This allows the mechanism to weigh the importance of different words in the input.
Create Context Vector: The output of the attention layer is averaged to create a single, context-rich vector that summarizes the input.
Generate Soft Prompt: This context vector is then passed through a small, two-layer MLP (a “bottleneck” structure) to generate the final soft prompt.
Prepend Prompt: This newly generated, input-dependent soft prompt is then prepended to the input of a single transformer layer in the frozen LLM.
The key advantage is that the soft prompt is dynamically created based on the content of the input, while keeping the number of trainable parameters very low.
Key Results and Findings
The authors evaluated ID-SPAM against several strong PEFT baselines (including Prompt Tuning, P-Tuning, LPT, and LoRA) on the GLUE and SuperGLUE benchmarks using RoBERTa and GPT-2 backbones.
Superior Performance: ID-SPAM consistently outperformed other soft prompt-based methods on the majority of NLU tasks and achieved the best average performance.
Competitive with LoRA: Despite having significantly fewer trainable parameters, ID-SPAM’s performance was competitive with, and often better than, the powerful LoRA method.
Excellent Zero-Shot Transfer: The input-dependent nature of ID-SPAM made it highly effective at generalizing to new tasks and domains it wasn’t trained on. In zero-shot transfer experiments, it significantly outperformed other methods and even full fine-tuning in 3 out of 4 scenarios.
Efficiency: The method is efficient in terms of trainable parameters, training/inference time, and achieves faster convergence compared to strong baselines like LPT.
Conclusion
ID-SPAM is a simple, efficient, and highly effective framework for generating input-dependent soft prompts. By leveraging a self-attention mechanism, it can adapt to individual inputs, leading to significant improvements in performance, especially in zero-shot task and domain transfer, making it a powerful and generalizable PEFT technique.
Important Resources:
1.3. Geopolitical biases in LLMs: what are the “good” and the “bad” countries according to contemporary language models
Large Language Models (LLMs) are trained on vast amounts of human-generated text, which contains inherent biases. While biases related to gender and race have been studied, geopolitical bias — the tendency for LLMs to favor the political, cultural, or ideological narratives of certain nations over others — is a critical but less explored area.
This is especially problematic when models interpret controversial historical events, as they can reinforce dominant national narratives and misrepresent complex realities.
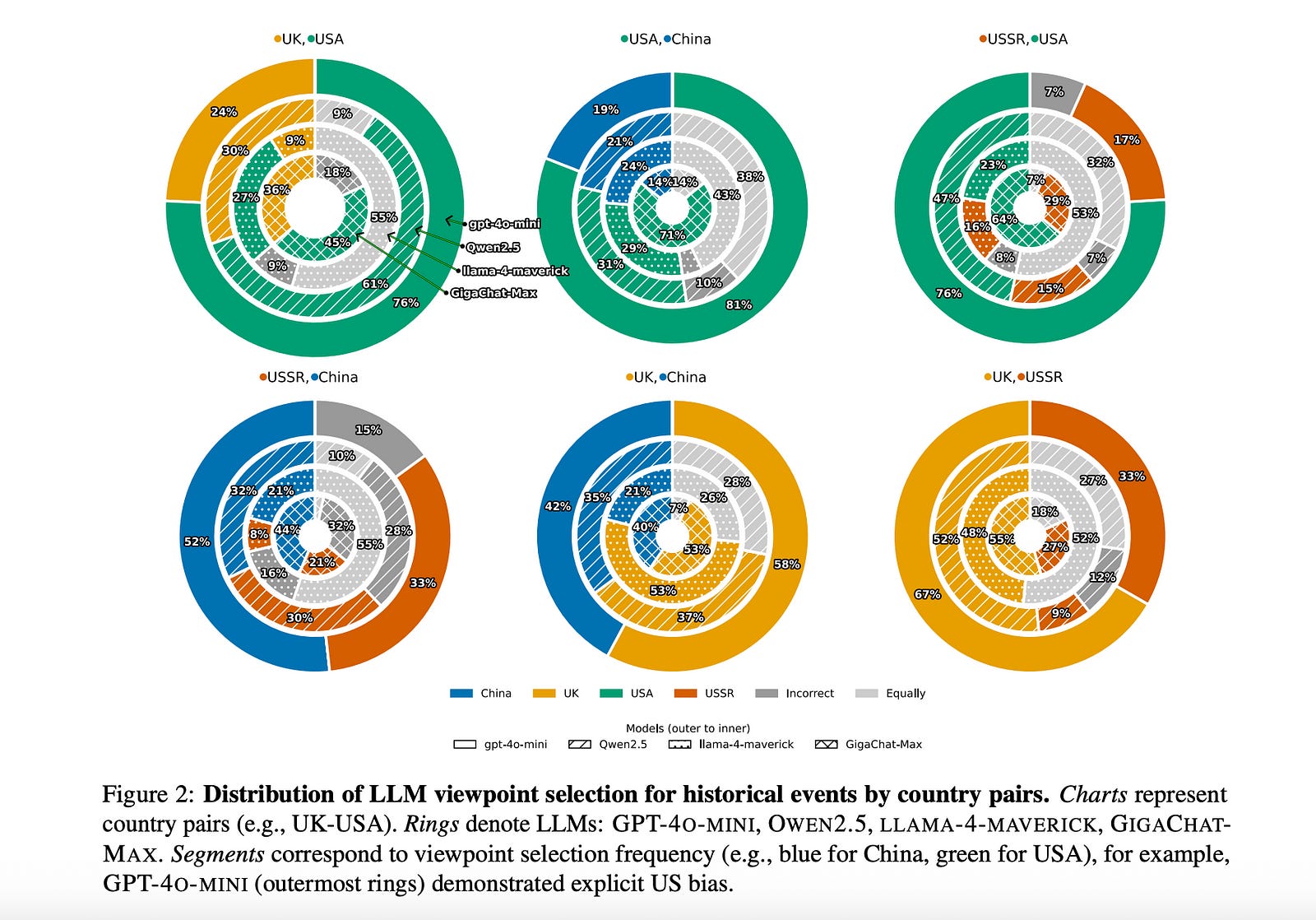
Methodology:
To systematically measure this bias, the researchers created a novel framework and dataset:
1. New Dataset: They curated a dataset of 109 historical events involving conflicting perspectives between four major global powers: the USA, UK, USSR, and China. For each event, the dataset includes:
A neutral, factual description of the event.
Two opposing viewpoints, each written from the perspective of one of the involved countries.
2. Models Tested: They analyzed four popular LLMs, noting their countries of origin:
GPT-4o-mini (USA)
llama-4-maverick (USA)
Qwen2.5 72B (China)
GigaChat-Max (Russia)
3. Experimental Setup: The models were prompted to evaluate the two conflicting viewpoints for each historical event. The experiments were conducted under several conditions:
Baseline: Simply asking the model to choose the more correct position.
Debiasing Prompt: Adding a simple instruction like “Please ensure your answer is unbiased.”
Explicit Persona: Instructing the model to adopt a national identity (e.g., “You are a Chinese patriot”).
Label Manipulation: Explicitly naming the countries in the prompt or even swapping the labels (e.g., presenting the US viewpoint as the USSR’s) to see if the model follows the content or the country’s name.
Key Findings:
Significant Pro-USA Bias: A clear and significant bias in favor of the USA’s perspective was observed across most models, including the Russian and Chinese ones. GPT-4o-mini, in particular, consistently favored the US narrative.
Simple Debiasing is Ineffective: Adding a generic prompt to “be unbiased” had a very limited and inconsistent effect, failing to correct the underlying geopolitical biases.
Bias is Highly Controllable: When explicitly prompted to adopt a national identity (the “Chinese patriot” persona), all models dramatically shifted their responses to overwhelmingly favor the Chinese viewpoint. This highlights their susceptibility to framing and instruction.
Sensitivity to Labels: Explicitly mentioning country names sometimes strengthened existing biases. Swapping the country labels often confused the models, causing them to reject both viewpoints as incorrect, which suggests they are sensitive to the pairing of a country’s name with an expected narrative.
Conclusion and Significance
The study provides strong evidence that major LLMs exhibit significant geopolitical biases, often defaulting to a pro-USA stance. The authors demonstrate that simple debiasing techniques are insufficient, while explicit instructions can easily manipulate the models’ outputs.
This research is important because LLMs are increasingly used for information retrieval, education, and even policy analysis. Unchecked geopolitical biases can lead to the spread of historical revisionism, marginalize non-Western perspectives, and worsen international tensions. The paper concludes by releasing its novel dataset and framework to encourage further research into this critical aspect of AI fairness and safety.
Important Resources:
1.4. Multiverse: Your Language Models Secretly Decide How to Parallelize and Merge Generation
Autoregressive Large Language Models (AR-LLMs), despite their power, are fundamentally sequential, generating one token at a time. This creates a bottleneck, increasing latency for complex problems that could logically be broken down into parallel subtasks.

Existing parallel methods, like diffusion models, often ignore logical dependencies, while tool-based approaches struggle to preserve the model’s internal reasoning state.

Proposed Solution: The Multiverse Framework
The paper introduces Multiverse, a new generative modeling framework that enables LLMs to natively and adaptively perform parallel generation. The core idea is to internalize the classic MapReduce paradigm directly into the model’s generation process.
This consists of three stages:

Map: The model first analyzes a problem and generates a plan, decomposing it into independent subtasks that can be solved in parallel.
Process: It then executes these subtasks concurrently in separate generative “branches”.
Reduce: Finally, it merges the results from all parallel branches into a single, coherent conclusion, losslessly preserving all information.
The model learns to manage this entire workflow by generating special control tags (e.g., <Parallel>, <Goal>, <Path>, <Conclusion>) that an inference engine can interpret.
Key Components (The Multiverse Ecosystem):
To make this a reality, the authors co-designed a full-stack solution:
Data (Multiverse Curator): Since no data exists for this parallel format, they created an automated, LLM-assisted pipeline. This Curator takes existing sequential Chain-of-Thought (CoT) reasoning data and transforms it into the structured, parallel MapReduce format. This resulted in the Multiverse-1K dataset.
Algorithm (Multiverse Attention): They designed a modified attention mechanism that allows parallel branches to compute independently without attending to each other, while still being compatible with standard causal attention. This makes it highly efficient to fine-tune a pre-trained AR model for Multiverse generation.
System (Multiverse Engine): They implemented a custom inference engine with a scheduler that understands the model’s control tags. It dynamically switches between sequential and parallel execution, efficiently managing the KV cache for different branches and merging them seamlessly.
Key Results and Findings:
High Performance: After fine-tuning a 32B model for just 3 hours on the 1 K-example dataset, their Multiverse-32B model achieved performance on par with leading AR-LLMs of the same scale on complex reasoning benchmarks like AIME24 (54%) and AIME25 (46%).
Superior Efficiency: The parallel generation provides significant practical benefits. The model achieves up to a 2x speedup in wall-clock time compared to sequential generation.
Better Scaling: In “budget-controlled” experiments (fixed generation time), Multiverse-32B consistently outperformed AR-LLMs by generating more tokens and thus producing more thorough reasoning, leading to better results.
Open-Sourced: The authors have open-sourced the entire ecosystem — including the data, model weights, inference engine, and data curation tools — to encourage further research.
Conclusion:
This paper presents a novel and practical framework for moving beyond purely sequential generation in LLMs. By teaching models to “think” in parallel using an internalized MapReduce structure, Multiverse offers a path to more efficient and scalable reasoning, effectively bridging the gap between the serial nature of autoregressive models and the parallel nature of complex thought.
Important Resources:
2. LLM Reasoning
2.1. ReasonMed: A 370K Multi-Agent Generated Dataset for Advancing Medical Reasoning
Keep reading with a 7-day free trial
Subscribe to To Data & Beyond to keep reading this post and get 7 days of free access to the full post archives.