


Important LLM Papers for the Week from 29/07 to 04/08
Stay Updated with Recent LLMs Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Fifth Week of July 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Training, Evaluation & Inference
LLM Quantization & Optimization
LLM Safety & Alignment
Tokenizers
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. LLM Progress & Benchmarking
1.1. AppWorld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents

Autonomous agents that address day-to-day digital tasks (e.g., ordering groceries for a household), must not only operate multiple apps (e.g., notes, messaging, shopping app) via APIs but also generate rich code with complex control flow in an iterative manner based on their interaction with the environment.
However, existing benchmarks for tool use are inadequate, as they only cover tasks that require a simple sequence of API calls. To remedy this gap, we built AppWorld Engine, a high-quality execution environment (60K lines of code) of 9 day-to-day apps operable via 457 APIs and populated with realistic digital activities simulating the lives of ~100 fictitious users.
We then created AppWorld Benchmark (40K lines of code), a suite of 750 natural, diverse, and challenging autonomous agent tasks requiring rich and interactive code generation. It supports robust programmatic evaluation with state-based unit tests, allowing for different ways of completing a task while also checking for unexpected changes, i.e., collateral damage.
The state-of-the-art LLM, GPT-4o, solves only ~49% of our ‘normal’ tasks and ~30% of ‘challenge’ tasks, while other models solve at least 16% fewer. This highlights the benchmark’s difficulty and AppWorld’s potential to push the frontiers of interactive coding agents.
1.2. MMAU: A Holistic Benchmark of Agent Capabilities Across Diverse Domains

Recent advances in large language models (LLMs) have increased the demand for comprehensive benchmarks to evaluate their capabilities as human-like agents. Existing benchmarks, while useful, often focus on specific application scenarios, emphasizing task completion but failing to dissect the underlying skills that drive these outcomes.
This lack of granularity makes it difficult to deeply discern where failures stem from. Additionally, setting up these environments requires considerable effort, and issues of unreliability and reproducibility sometimes arise, especially in interactive tasks. To address these limitations, we introduce the Massive Multitask Agent Understanding (MMAU) benchmark, featuring comprehensive offline tasks that eliminate the need for complex environment setups.
It evaluates models across five domains, including teal{Tool-use}, teal{Directed Acyclic Graph (DAG) QA}, teal{Data Science and Machine Learning coding}, teal{Contest-level programming} and teal{Mathematics}, and covers five essential capabilities: orange{Understanding}, orange{Reasoning}, orange{Planning}, orange{Problem-solving}, and orange{Self-correction}.
With a total of 20 meticulously designed tasks encompassing over 3K distinct prompts, MMAU provides a comprehensive framework for evaluating the strengths and limitations of LLM agents. By testing 18 representative models on MMAU, we provide deep and insightful analyses.
Ultimately, MMAU not only sheds light on the capabilities and limitations of LLM agents but also enhances the interpretability of their performance.
1.3. A Large Encoder-Decoder Family of Foundation Models For Chemical Language

Large-scale pre-training methodologies for chemical language models represent a breakthrough in cheminformatics. These methods excel in tasks such as property prediction and molecule generation by learning contextualized representations of input tokens through self-supervised learning on large unlabeled corpora.
Typically, this involves pre-training on unlabeled data followed by fine-tuning specific tasks, reducing dependence on annotated datasets, and broadening chemical language representation understanding. This paper introduces a large encoder-decoder chemical foundation model pre-trained on a curated dataset of 91 million SMILES samples sourced from PubChem, which is equivalent to 4 billion molecular tokens.
The proposed foundation model supports different complex tasks, including quantum property prediction, and offers flexibility with two main variants (289M and 8 times289 M). Our experiments across multiple benchmark datasets validate the capacity of the proposed model to provide state-of-the-art results for different tasks.
We also provide a preliminary assessment of the compositionality of the embedding space as a prerequisite for the reasoning tasks. We demonstrate that the produced latent space is separable compared to the state-of-the-art with few-shot learning capabilities.
1.4. The Llama 3 Herd of Models

Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilingualism, coding, reasoning, and tool usage.
Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks.
We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety.
The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
1.5. Gemma 2: Improving Open Language Models at a Practical Size
In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters.
In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attention (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of the next token prediction.
The resulting models deliver the best performance for their size and even offer competitive alternatives to models that are 2–3 times bigger. We release all our models to the community.
1.6. Towards Achieving Human Parity on End-to-end Simultaneous Speech Translation via LLM Agent
In this paper, we present Cross Language Agent — Simultaneous Interpretation, CLASI, a high-quality and human-like Simultaneous Speech Translation (SiST) System.
Inspired by professional human interpreters, we utilize a novel data-driven read-write strategy to balance the translation quality and latency. To address the challenge of translating in-domain terminologies, CLASI employs a multi-modal retrieving module to obtain relevant information to augment the translation.
Supported by LLMs, our approach can generate error-tolerated translation by considering the input audio, historical context, and retrieved information. Experimental results show that our system outperforms other systems by significant margins.
Aligned with professional human interpreters, we evaluate CLASI with a better human evaluation metric, valid information proportion (VIP), which measures the amount of information that can be successfully conveyed to the listeners.
In real-world scenarios, where the speeches are often disfluent, informal, and unclear, CLASI achieves VIP of 81.3% and 78.0% for Chinese-to-English and English-to-Chinese translation directions, respectively.
In contrast, state-of-the-art commercial or open-source systems only achieve 35.4% and 41.6%. On the extremely hard dataset, where other systems achieve under 13% VIP, CLASI can still achieve 70% VIP.
1.7. SaulLM-54B & SaulLM-141B: Scaling Up Domain Adaptation for the Legal Domain
In this paper, we introduce SaulLM-54B and SaulLM-141B, two large language models (LLMs) tailored for the legal sector. These models, which feature architectures of 54 billion and 141 billion parameters, respectively, are based on the Mixtral architecture.
The development of SaulLM-54B and SaulLM-141B is guided by large-scale domain adaptation, divided into three strategies:
The exploitation of continued pretraining involving a base corpus that includes over 540 billion legal tokens
The implementation of a specialized legal instruction-following protocol
The alignment of model outputs with human preferences in legal interpretations.
The integration of synthetically generated data in the second and third steps enhances the models’ capabilities in interpreting and processing legal texts, effectively reaching state-of-the-art performance and outperforming previous open-source models on LegalBench-Instruct.
This work explores the trade-offs involved in domain-specific adaptation at this scale, offering insights that may inform future studies on domain adaptation using strong decoder models. Building upon SaulLM-7B, this study refines the approach to produce an LLM better equipped for legal tasks.
We are releasing base, instruct, and aligned versions on top of SaulLM-54B and SaulLM-141B under the MIT License to facilitate reuse and collaborative research.
1.8. Integrating Large Language Models into a Tri-Modal Architecture for Automated Depression Classification
Major Depressive Disorder (MDD) is a pervasive mental health condition that affects 300 million people worldwide. This work presents a novel, BiLSTM-based tri-modal model-level fusion architecture for the binary classification of depression from clinical interview recordings.
The proposed architecture incorporates Mel Frequency Cepstral Coefficients, and Facial Action Units, and uses a two-shot learning-based GPT-4 model to process text data. This is the first work to incorporate large language models into a multi-modal architecture for this task.
It achieves impressive results on the DAIC-WOZ AVEC 2016 Challenge cross-validation split and Leave-One-Subject-Out cross-validation split, surpassing all baseline models and multiple state-of-the-art models.
In Leave-One-Subject-Out testing, it achieves an accuracy of 91.01%, an F1-Score of 85.95%, a precision of 80%, and a recall of 92.86%.
1.9. ATHAR: A High-Quality and Diverse Dataset for Classical Arabic to English Translation
Classical Arabic represents a significant era, encompassing the golden age of Arab culture, philosophy, and scientific literature. With a broad consensus on the importance of translating this literature to enrich knowledge dissemination across communities, the advent of large language models (LLMs) and translation systems offers promising tools to facilitate this goal.
However, we have identified a scarcity of translation datasets in Classical Arabic, which are often limited in scope and topics, hindering the development of high-quality translation systems. In response, we present the ATHAR dataset, comprising 66,000 high-quality Classical Arabic-to-English translation samples that cover a wide array of subjects including science, culture, and philosophy.
Furthermore, we assess the performance of current state-of-the-art LLMs under various settings, concluding that there is a need for such datasets in current systems. Our findings highlight how models can benefit from fine-tuning or incorporating this dataset into their pretraining pipelines.
2. LLM Training, Evaluation & Inference
2.1. MoMa: Efficient Early-Fusion Pre-training with Mixture of Modality-Aware Experts

We introduce MoMa, a novel modality-aware mixture-of-experts (MoE) architecture designed for pre-training mixed-modal, early-fusion language models.
MoMa processes images and text in arbitrary sequences by dividing expert modules into modality-specific groups. These groups exclusively process designated tokens while employing learned routing within each group to maintain semantically informed adaptivity.
Our empirical results reveal substantial pre-training efficiency gains through this modality-specific parameter allocation. Under a 1-trillion-token training budget, the MoMa 1.4B model, featuring 4 text experts and 4 image experts, achieves impressive FLOPs savings: 3.7x overall, with 2.6x for text and 5.2x for image processing compared to a compute-equivalent dense baseline, measured by pre-training loss.
This outperforms the standard expert-choice MoE with 8 mixed-modal experts, which achieves 3x overall FLOPs savings (3x for text, 2.8x for image).
Combining MoMa with mixture-of-depths (MoD) further improves pre-training FLOPs savings to 4.2x overall (text: 3.4x, image: 5.3x), although this combination hurts performance in causal inference due to increased sensitivity to router accuracy.
These results demonstrate MoMa’s potential to significantly advance the efficiency of mixed-modal, early-fusion language model pre-training, paving the way for more resource-efficient and capable multimodal AI systems.
2.2. MM-Vet v2: A Challenging Benchmark to Evaluate Large Multimodal Models for Integrated Capabilities

MM-Vet, with open-ended vision-language questions targeting at evaluating integrated capabilities, has become one of the most popular benchmarks for large multimodal model evaluation.
MM-Vet assesses six core vision-language (VL) capabilities: recognition, knowledge, spatial awareness, language generation, OCR, and math. However, its question format is restricted to single image-text pairs, lacking the interleaved image and text sequences prevalent in real-world scenarios.
To address this limitation, we introduce MM-Vet v2, which includes a new VL capability called “image-text sequence understanding”, evaluating models’ ability to process VL sequences. Furthermore, we maintain the high quality of evaluation samples while further expanding the evaluation set size.
Using MM-Vet v2 to benchmark large multimodal models, we found that Claude 3.5 Sonnet is the best model with a score of 71.8, slightly outperforming GPT-4o which scored 71.0. Among open-weight models, InternVL2-Llama3–76B leads with a score of 68.4.
3. LLM Quantization & Optimization
3.1. ThinK: Thinner Key Cache by Query-Driven Pruning
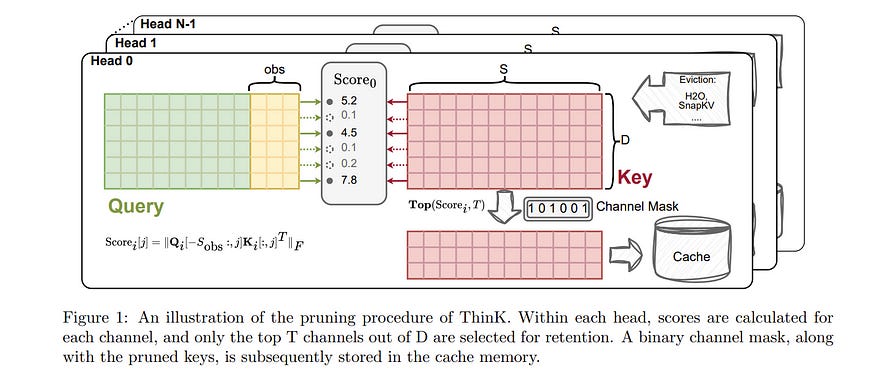
Large Language Models (LLMs) have revolutionized the field of natural language processing, achieving unprecedented performance across a variety of applications by leveraging increased model sizes and sequence lengths.
However, the associated rise in computational and memory costs poses significant challenges, particularly in managing long sequences due to the quadratic complexity of the transformer attention mechanism. This paper focuses on the long-context scenario, addressing the inefficiencies in KV cache memory consumption during inference.
Unlike existing approaches that optimize the memory based on the sequence lengths, we uncover that the channel dimension of the KV cache exhibits significant redundancy, characterized by unbalanced magnitude distribution and low-rank structure in attention weights.
Based on these observations, we propose ThinK, a novel query-dependent KV cache pruning method designed to minimize attention weight loss while selectively pruning the least significant channels.
Our approach not only maintains or enhances model accuracy but also achieves a reduction in memory costs by over 20% compared with vanilla KV cache eviction methods. Extensive evaluations on the LLaMA3 and Mistral models across various long-sequence datasets confirm the efficacy of ThinK, setting a new precedent for efficient LLM deployment without compromising performance.
We also outline the potential of extending our method to value cache pruning, demonstrating ThinK’s versatility and broad applicability in reducing both memory and computational overheads.
4. LLM Safety & Alignment
4.1. Meta-Rewarding Language Models: Self-Improving Alignment with LLM-as-a-Meta-Judge

Large Language Models (LLMs) are rapidly surpassing human knowledge in many domains. While improving these models traditionally relies on costly human data, recent self-rewarding mechanisms (Yuan et al., 2024) have shown that LLMs can improve by judging their own responses instead of relying on human labelers.
However, existing methods have primarily focused on improving model responses rather than judgment capabilities, resulting in rapid saturation during iterative training. To address this issue, we introduce a novel Meta-Rewarding step to the self-improvement process, where the model judges its own judgments and uses that feedback to refine its judgment skills.
Surprisingly, this unsupervised approach improves the model’s ability to judge {\em and} follow instructions, as demonstrated by a win rate improvement of Llama-3–8B-Instruct from 22.9% to 39.4% on AlpacaEval 2, and 20.6% to 29.1% on Arena-Hard. These results strongly suggest the potential for self-improving models without human supervision.
5. Tokenizers
5.1. Improving Text Embeddings for Smaller Language Models Using Contrastive Fine-tuning

While Large Language Models show remarkable performance in natural language understanding, their resource-intensive nature makes them less accessible.
In contrast, smaller language models such as MiniCPM offer more sustainable scalability but often underperform without specialized optimization. In this paper, we explore the enhancement of smaller language models through the improvement of their text embeddings. We select three language models, MiniCPM, Phi-2, and Gemma, to conduct contrastive fine-tuning on the NLI dataset.
Our results demonstrate that this fine-tuning method enhances the quality of text embeddings for all three models across various benchmarks, with MiniCPM showing the most significant improvements of an average 56.33\% performance gain.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
