


Important Computer Vision Papers for the Week from 30/09 to 06/10
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in various topics such as diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the First Week of October 2024, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models (VLMs)
Image Generation & Editing
Video Generation & Editing
My New E-Book: Prompt Engineering Best Practices for Instruction-Tuned LLM

I am happy to announce that I have published a new ebook Prompt Engineering Best Practices for Instruction-Tuned LLM. Prompt Engineering Best Practices for Instruction-Tuned LLM is a comprehensive guide designed to equip readers with the essential knowledge and tools to master the fine-tuning and prompt engineering of large language models (LLMs). The book covers everything from foundational concepts to advanced applications, making it an invaluable resource for anyone interested in leveraging the full potential of instruction-tuned models.
1. Diffusion Models
1.1. Image Copy Detection for Diffusion Models

Images produced by diffusion models are increasingly popular in digital artwork and visual marketing. However, such generated images might replicate content from existing ones and pose the challenge of content originality.
Existing Image Copy Detection (ICD) models, though accurate in detecting hand-crafted replicas, overlook the challenge of diffusion models. This motivates us to introduce ICDiff, the first ICD specialized for diffusion models.
To this end, we construct a Diffusion-Replication (D-Rep) dataset and correspondingly propose a novel deep embedding method. D-Rep uses a state-of-the-art diffusion model (Stable Diffusion V1.5) to generate 40, 000 image-replica pairs, which are manually annotated into 6 replication levels ranging from 0 (no replication) to 5 (total replication).
Our method, PDF embedding, transforms the replication level of each image-replica pair into a probability density function (PDF) as the supervision signal. The intuition is that the probability of neighboring replication levels should be continuous and smooth.
Experimental results show that PDF embedding surpasses protocol-driven methods and non-PDF choices on the D-Rep test set. Moreover, by utilizing PDF embedding, we find that the replication ratios of well-known diffusion models against an open-source gallery range from 10% to 20%.
2. Vision Language Models (VLMs)
2.1. LEOPARD: A Vision Language Model For Text-Rich Multi-Image Tasks

Text-rich images, where text serves as the central visual element guiding the overall understanding, are prevalent in real-world applications, such as presentation slides, scanned documents, and webpage snapshots.
Tasks involving multiple text-rich images are especially challenging, as they require not only understanding the content of individual images but reasoning about inter-relationships and logical flows across multiple visual inputs.
Despite the importance of these scenarios, current multimodal large language models (MLLMs) struggle to handle such tasks due to two key challenges: (1) the scarcity of high-quality instruction tuning datasets for text-rich multi-image scenarios, and (2) the difficulty in balancing image resolution with visual feature sequence length.
To address these challenges, we propose OurMethod, a MLLM designed specifically for handling vision-language tasks involving multiple text-rich images.
First, we curated about one million high-quality multimodal instruction-tuning data, tailored to text-rich, multi-image scenarios. Second, we developed an adaptive high-resolution multi-image encoding module to dynamically optimize the allocation of visual sequence length based on the original aspect ratios and resolutions of the input images.
Experiments across a wide range of benchmarks demonstrate our model’s superior capabilities in text-rich, multi-image evaluations and competitive performance in general domain evaluations.
2.2. CLIP-MoE: Towards Building Mixture of Experts for CLIP with Diversified Multiplet Upcycling
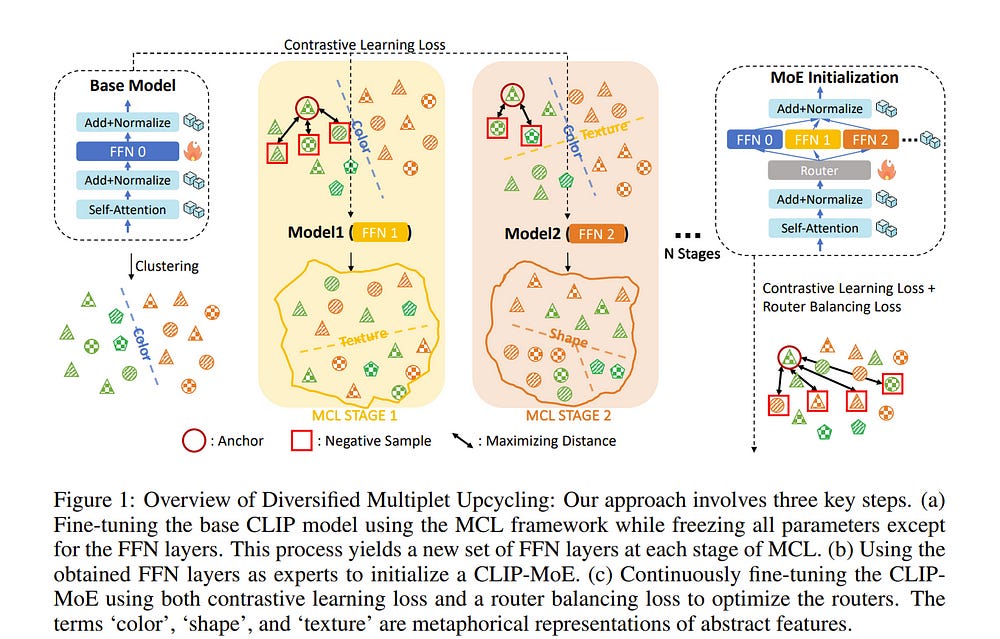
In recent years, Contrastive Language-Image Pre-training (CLIP) has become a cornerstone in multimodal intelligence. However, recent studies have identified that the information loss in the CLIP encoding process is substantial, and CLIP tends to capture only coarse-grained features from the input. This deficiency significantly limits the ability of a single CLIP model to handle images rich in visual detail.
In this work, we propose a simple yet effective model-agnostic strategy, Diversified Multiplet Upcycling (DMU), for CLIP. DMU efficiently fine-tunes a series of CLIP models that capture different feature spaces, from a dense pre-trained CLIP checkpoint, sharing parameters except for the Feed-Forward Network (FFN).
These models can then be transformed into a CLIP-MoE with a larger model capacity, leading to significantly enhanced performance with minimal computational overhead. To the best of our knowledge, Diversified Multiplet Upcycling is the first approach to introduce sparsely activated MoE into CLIP foundation models.
Extensive experiments demonstrate the significant performance of CLIP-MoE across various zero-shot retrieval, zero-shot image classification tasks, and downstream Multimodal Large Language Model (MLLM) benchmarks by serving as a vision encoder.
Furthermore, Diversified Multiplet Upcycling enables the conversion of any dense CLIP model into CLIP-MoEs, which can seamlessly replace CLIP in a plug-and-play manner without requiring further adaptation in downstream frameworks.
Through Diversified Multiplet Upcycling, we aim to provide valuable insights for future research on developing more efficient and effective multimodal learning systems.
3. Image Generation & Editing
3.1. Robin3D: Improving 3D Large Language Model via Robust Instruction Tuning
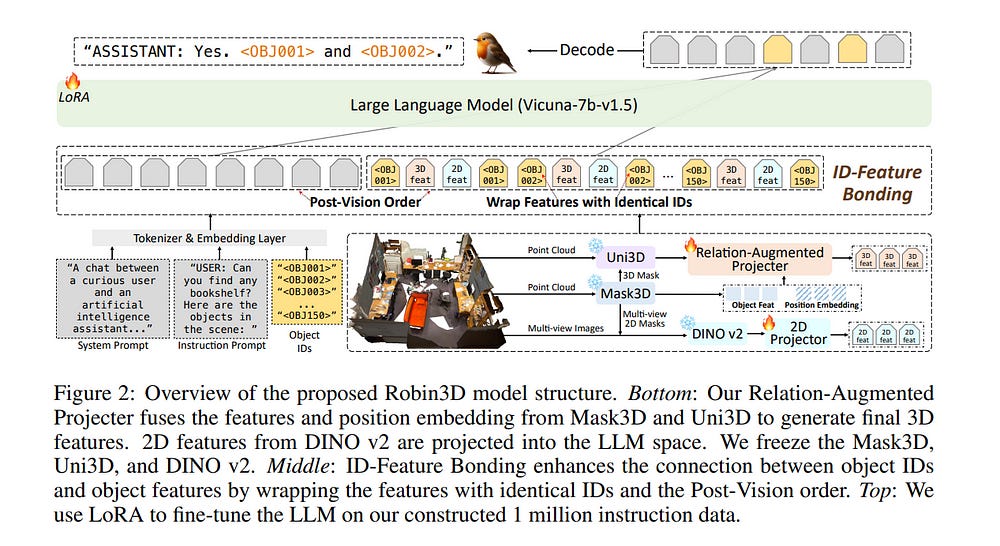
Recent advancements in 3D Large Language Models (3DLLMs) have highlighted their potential in building general-purpose agents in the 3D real world, yet challenges remain due to the lack of high-quality robust instruction-following data, leading to limited discriminative power and generalization of 3DLLMs.
In this paper, we introduce Robin3D, a powerful 3DLLM trained on large-scale instruction-following data generated by our novel data engine, the Robust Instruction Generation (RIG) engine.
RIG generates two key instruction data: 1) the Adversarial Instruction-following data, which features mixed negative and positive samples to enhance the model’s discriminative understanding. 2) the Diverse Instruction-following data, which contains various instruction styles to enhance the model’s generalization.
As a result, we construct 1 million instruction-following data, consisting of 344K Adversarial samples, 508K Diverse samples, and 165K benchmark training set samples.
To better handle these complex instructions, Robin3D first incorporates a Relation-Augmented Projector to enhance spatial understanding and then strengthens the object referring and grounding ability through ID-Feature Bonding.
Robin3D consistently outperforms previous methods across five widely-used 3D multimodal learning benchmarks, without the need for task-specific fine-tuning. Notably, we achieve a 7.8\% improvement in the grounding task (Multi3DRefer) and a 6.9\% improvement in the captioning task (Scan2Cap).
4. Video Understanding, Generation & Editing
4.1. One Token to Seg Them All: Language-Instructed Reasoning Segmentation in Videos

We introduce VideoLISA, a video-based multimodal large language model designed to tackle the problem of language-instructed reasoning segmentation in videos. Leveraging the reasoning capabilities and world knowledge of large language models, and augmented by the Segment Anything Model, VideoLISA generates temporally consistent segmentation masks in videos based on language instructions.
Existing image-based methods, such as LISA, struggle with video tasks due to the additional temporal dimension, which requires temporal dynamic understanding and consistent segmentation across frames. VideoLISA addresses these challenges by integrating a Sparse Dense Sampling strategy into the video-LLM, which balances temporal context and spatial detail within computational constraints.
Additionally, we propose a One-Token-Seg-All approach using a specially designed <TRK> token, enabling the model to segment and track objects across multiple frames.
Extensive evaluations on diverse benchmarks, including our newly introduced ReasonVOS benchmark, demonstrate VideoLISA’s superior performance in video object segmentation tasks involving complex reasoning, temporal understanding, and object tracking.
While optimized for videos, VideoLISA also shows promising generalization to image segmentation, revealing its potential as a unified foundation model for language-instructed object segmentation.
4.2. Loong: Generating Minute-level Long Videos with Autoregressive Language Models

It is desirable but challenging to generate content-rich long videos in the scale of minutes. Autoregressive large language models (LLMs) have achieved great success in generating coherent and long sequences of tokens in the domain of natural language processing, while the exploration of autoregressive LLMs for video generation is limited to generating short videos of several seconds.
In this work, we conduct a deep analysis of the challenges that prevent autoregressive LLM-based video generators from generating long videos. Based on the observations and analysis, we propose Loong, a new autoregressive LLM-based video generator that can generate minute-long videos.
Specifically, we model the text tokens and video tokens as a unified sequence for autoregressive LLMs and train the model from scratch. We propose progressive short-to-long training with a loss loss-weighting scheme to mitigate the loss imbalance problem for long video training.
We further investigate inference strategies, including video token re-encoding and sampling strategies, to diminish error accumulation during inference.
Our proposed Loong can be trained on 10-second videos and be extended to generate minute-level long videos conditioned on text prompts, as demonstrated by the results.
4.3. Video Instruction Tuning With Synthetic

The development of video large multimodal models (LMMs) has been hindered by the difficulty of curating large amounts of high-quality raw data from the web.
To address this, we propose an alternative approach by creating a high-quality synthetic dataset specifically for video instruction-following, namely LLaVA-Video-178K. This dataset includes key tasks such as detailed captioning, open-ended question-answering (QA), and multiple-choice QA.
By training on this dataset, in combination with existing visual instruction tuning data, we introduce LLaVA-Video, a new video LMM. Our experiments demonstrate that LLaVA-Video achieves strong performance across various video benchmarks, highlighting the effectiveness of our dataset. We plan to release the dataset, its generation pipeline, and the model checkpoints.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
