


Important Computer Vision Papers for the Week from 11/11 to 17/11
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in various topics such as diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the Second Week of November 2024, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Image Generation & Editing
Vision Language Models
Video Generation & Editing
Image Segmentation
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. Diffusion Models
1.1.Add-it: Training-Free Object Insertion in Images With Pretrained Diffusion Models

Adding Objects into images based on text instructions is a challenging task in semantic image editing, requiring a balance between preserving the original scene and seamlessly integrating the new object in a fitting location.
Despite extensive efforts, existing models often struggle with this balance, particularly with finding a natural location for adding an object in complex scenes.
We introduce Add-it, a training-free approach that extends diffusion models’ attention mechanisms to incorporate information from three key sources: the scene image, the text prompt, and the generated image itself.
Our weighted extended-attention mechanism maintains structural consistency and fine details while ensuring natural object placement. Without task-specific fine-tuning, Add-it achieves state-of-the-art results on both real and generated image insertion benchmarks, including our newly constructed “Additing Affordance Benchmark” for evaluating object placement plausibility, outperforming supervised methods.
Human evaluations show that Add-it is preferred in over 80% of cases, and it also demonstrates improvements in various automated metrics.
1.2. Edify Image: High-Quality Image Generation with Pixel Space Laplacian Diffusion Models

We introduce Edify Image, a family of diffusion models capable of generating photorealistic image content with pixel-perfect accuracy. Edify Image utilizes cascaded pixel-space diffusion models trained using a novel Laplacian diffusion process, in which image signals at different frequency bands are attenuated at varying rates.
Edify Image supports a wide range of applications, including text-to-image synthesis, 4K upsampling, ControlNets, 360 HDR panorama generation, and finetuning for image customization.
2. Image Generation & Editing
2.1. MagicQuill: An Intelligent Interactive Image Editing System

Image editing involves a variety of complex tasks and requires efficient and precise manipulation techniques. In this paper, we present MagicQuill, an integrated image editing system that enables the swift actualization of creative ideas.
Our system features a streamlined yet functionally robust interface, allowing for the articulation of editing operations (e.g., inserting elements, erasing objects, altering color) with minimal input. These interactions are monitored by a multimodal large language model (MLLM) to anticipate editing intentions in real-time, bypassing the need for explicit prompt entry.
Finally, we apply a powerful diffusion prior, enhanced by a carefully learned two-branch plug-in module, to process editing requests with precise control. Experimental results demonstrate the effectiveness of MagicQuill in achieving high-quality image edits.
2.2. OmniEdit: Building Image Editing Generalist Models Through Specialist Supervision

Instruction-guided image editing methods have demonstrated significant potential by training diffusion models on automatically synthesized or manually annotated image editing pairs.
However, these methods remain far from practical, real-life applications. We identify three primary challenges contributing to this gap. Firstly, existing models have limited editing skills due to the biased synthesis process. Secondly, these methods are trained with datasets with a high volume of noise and artifacts.
This is due to the application of simple filtering methods like CLIP-score. Thirdly, all these datasets are restricted to a single low resolution and fixed aspect ratio, limiting the versatility to handle real-world use cases.
In this paper, we present \omniedit, which is an omnipotent editor to handles seven different image editing tasks with any aspect ratio seamlessly.
Our contribution is in four folds:
Omniedit is trained by utilizing supervision from seven different specialist models to ensure task coverage.
We utilize importance sampling based on the scores provided by large multimodal models (like GPT-4o) instead of CLIP-score to improve the data quality.
We propose a new editing architecture called EditNet to greatly boost the editing success rate.
We provide images with different aspect ratios to ensure that our model can handle any image in the wild.
We have curated a test set containing images of different aspect ratios, accompanied by diverse instructions to cover different tasks. Both automatic evaluation and human evaluations demonstrate that \omniedit can significantly outperform all the existing models.
3. Vision Language Models
3.1. LLM2CLIP: Powerful Language Model Unlock Richer Visual Representation
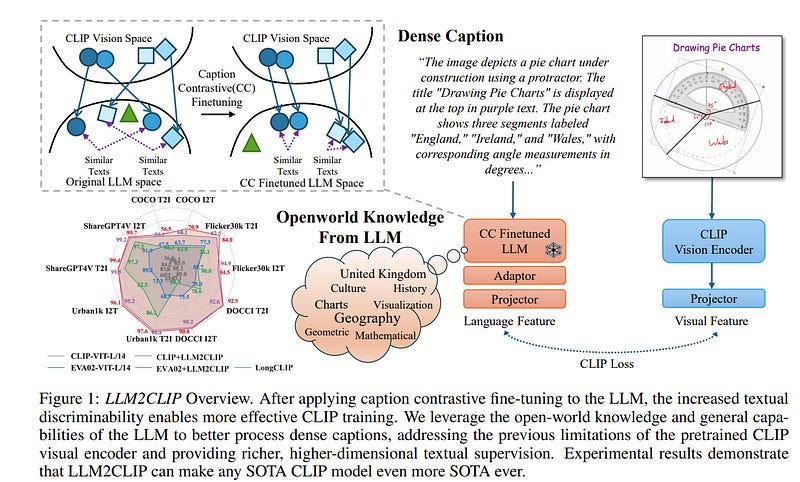
CLIP is one of the most important multimodal foundational models today. What powers CLIP’s capabilities? The rich supervision signals provided by natural language, the carrier of human knowledge, shape a powerful cross-modal representation space.
However, with the rapid advancements in large language models LLMs like GPT-4 and LLaMA, the boundaries of language comprehension and generation are continually being pushed.
This raises an intriguing question: can the capabilities of LLMs be harnessed to further improve multimodal representation learning? The potential benefits of incorporating LLMs into CLIP are clear.
LLMs’ strong textual understanding can fundamentally improve CLIP’s ability to handle image captions, drastically enhancing its ability to process long and complex texts, a well-known limitation of vanilla CLIP.
Moreover, LLMs are trained on a vast corpus of text, possessing open-world knowledge. This allows them to expand on caption information during training, increasing the efficiency of the learning process. In this paper, we propose LLM2CLIP, a novel approach that embraces the power of LLMs to unlock CLIP’s potential.
By fine-tuning the LLM in the caption space with contrastive learning, we extract its textual capabilities into the output embeddings, significantly improving the output layer’s textual discriminability. We then design an efficient training process where the fine-tuned LLM acts as a powerful teacher for CLIP’s visual encoder.
Thanks to the LLM’s presence, we can now incorporate longer and more complex captions without being restricted by vanilla CLIP’s text encoder’s context window and ability limitations. Our experiments demonstrate that this approach brings substantial improvements in cross-modal tasks.
4. Video Generation & Editing
4.1. EgoVid-5M: A Large-Scale Video-Action Dataset for Egocentric Video Generation
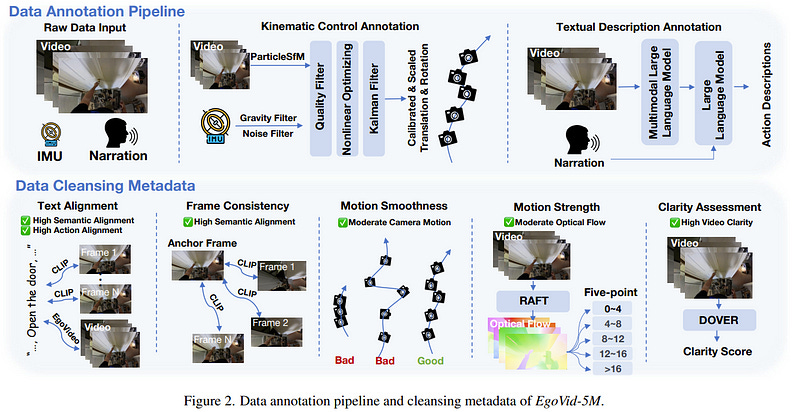
Video generation has emerged as a promising tool for world simulation, leveraging visual data to replicate real-world environments. Within this context, egocentric video generation, which centers on the human perspective, holds significant potential for enhancing applications in virtual reality, augmented reality, and gaming.
However, the generation of egocentric videos presents substantial challenges due to the dynamic nature of egocentric viewpoints, the intricate diversity of actions, and the complex variety of scenes encountered.
Existing datasets are inadequate for addressing these challenges effectively. To bridge this gap, we present EgoVid-5M, the first high-quality dataset specifically curated for egocentric video generation.
EgoVid-5M encompasses 5 million egocentric video clips and is enriched with detailed action annotations, including fine-grained kinematic control and high-level textual descriptions.
To ensure the integrity and usability of the dataset, we implement a sophisticated data-cleaning pipeline designed to maintain frame consistency, action coherence, and motion smoothness under egocentric conditions.
Furthermore, we introduce EgoDreamer, which is capable of generating egocentric videos driven simultaneously by action descriptions and kinematic control signals.
The EgoVid-5M dataset, associated action annotations, and all data cleansing metadata will be released for the advancement of research in egocentric video generation.
5. Image Segmentation
5.1. SAMPart3D: Segment Any Part in 3D Objects

3D part segmentation is a crucial and challenging task in 3D perception, playing a vital role in applications such as robotics, 3D generation, and 3D editing. Recent methods harness the powerful Vision Language Models (VLMs) for 2D-to-3D knowledge distillation, achieving zero-shot 3D part segmentation.
However, these methods are limited by their reliance on text prompts, which restricts the scalability to large-scale unlabeled datasets and the flexibility in handling part ambiguities.
In this work, we introduce SAMPart3D, a scalable zero-shot 3D part segmentation framework that segments any 3D object into semantic parts at multiple granularities, without requiring predefined part label sets as text prompts.
For scalability, we use text-agnostic vision foundation models to distill a 3D feature extraction backbone, allowing scaling to large unlabeled 3D datasets to learn rich 3D priors.
For flexibility, we distill scale-conditioned part-aware 3D features for 3D part segmentation at multiple granularities. Once the segmented parts are obtained from the scale-conditioned part-aware 3D features, we use VLMs to assign semantic labels to each part based on the multi-view renderings.
Compared to previous methods, our SAMPart3D can scale to the recent large-scale 3D object dataset Objaverse and handle complex, non-ordinary objects.
Additionally, we contribute a new 3D part segmentation benchmark to address the lack of diversity and complexity of objects and parts in existing benchmarks.
Experiments show that our SAMPart3D significantly outperforms existing zero-shot 3D part segmentation methods, and can facilitate various applications such as part-level editing and interactive segmentation.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
